- The paper presents Temporally Coherent Reward Modeling (TCRM) that reinterprets reward models as value functions using lookahead consistency and smoothness regularizers.
- It achieves up to 88.9% middle-token pairwise accuracy and streamlines RLHF by unifying reward and value modeling without additional architectural changes.
- The approach enables fine-grained error detection and process-level feedback from outcome-only data, reducing training costs and improving interpretability.
Temporally Coherent Reward Modeling: Reward Models as Value Functions
Motivation and Theoretical Foundations
Standard reward models (RMs) in RLHF operate by providing scalar-valued evaluations of final responses, typically by supervising only the output at the EOS token using a Bradley-Terry pairwise preference loss. This practice discards the rich signal residing in intermediate tokens, resulting in incoherent, noisy, and often uninterpretable token-level predictions throughout the response trajectory. The central hypothesis advanced in "Reward Models Are Secretly Value Functions: Temporally Coherent Reward Modeling" (2604.22981) is that RM outputs at each token should capture the conditional expectation of the final reward, reflecting evolving response quality at every generation step.
Temporally Coherent Reward Modeling (TCRM) introduces two regularization terms atop the conventional Bradley-Terry loss: lookahead consistency (an MSE penalty aligning intermediate outputs with the final RM prediction) and smoothness (an MSE penalty enforcing local consistency across adjacent tokens). Both regularizers have explicit theoretical correspondence with classical value learning objectives: the former structurally mirrors Monte Carlo return regression, while the latter aligns with one-step temporal-difference bootstrapping, as found in value-based RL. This connection stipulates that an RM trained under TCRM losses is, in fact, a value function, with formal conditional expectation minimizers established via measure-theoretic martingale arguments (see Lemmas 1 and 2 in the text).
The direct implication is that the decoder-based RM, utilizing causal masking (Figure 1), naturally conditions intermediate outputs on past tokens, thus supporting proper construction of conditional expectations throughout a sequence.
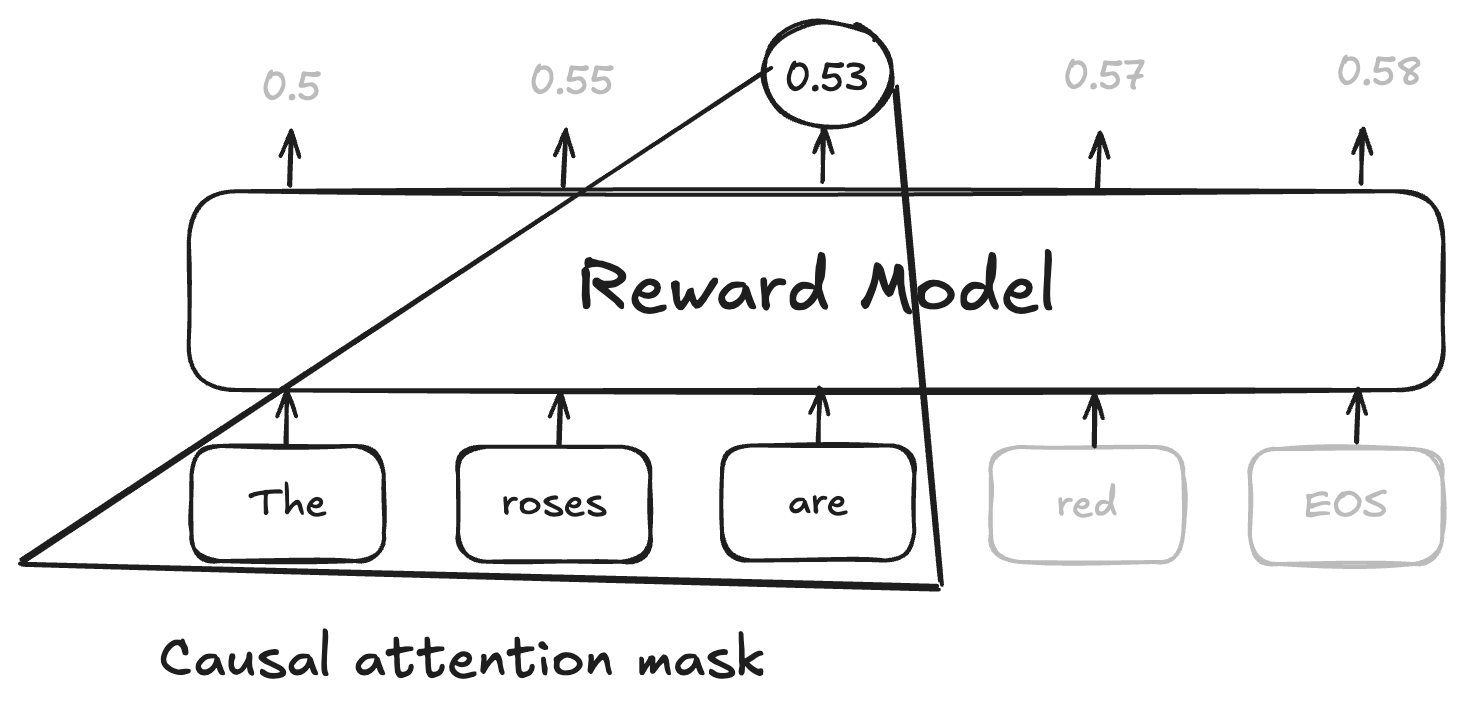
Figure 1: Causal attention mask of a decoder-based reward model, ensuring outputs at each token condition only on prior tokens.
Practical Implementation and Loss Construction
TCRM does not alter the underlying transformer architecture, training data, or inference procedures. Its core innovation is in the loss:
- Lookahead Consistency: For each intermediate prefix y0..k, enforce r(x,y0..k)≈r(x,y) via LLA=k∑(r(x,y0..k)−SG[r(x,y)])2, where the stop-gradient stabilizes optimization by preventing leak back from the target.
- Smoothness: Enforce step-wise continuity with Lsm=k∑(r(x,y0..k−1)−SG[r(x,y0..k)])2, shaping the reward trajectory into a martingale with respect to the filtered token sequence.
The combined objective aggregates Bradley-Terry, smoothness, and lookahead penalties, with regularization coefficients chosen empirically to balance improvement in token-wise coherence without degrading terminal accuracy.
Experimental Findings
TCRM yields interpretable and predictive token-level reward trajectories. Empirically, middle-token pairwise preference accuracy—a proxy for how reliably the RM discriminates between preferable continuations given only partial prefixes—increases dramatically from near-random (∼50%) for baseline models to up to 88.9% for TCRM without loss in final-token accuracy. Diagnostic visualizations (see below) corroborate that TCRM RM outputs exhibit smooth, high-resolution reward signals that are sharply sensitive to decisive tokens.
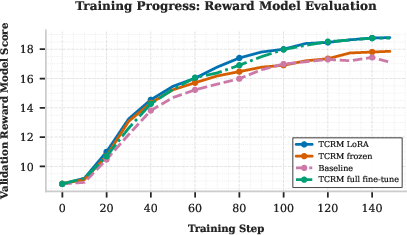
Figure 3: Validation reward model scores for PPO training run with different value model setups—TCRM delivers consistent high-quality signals across setups.
For a concrete illustration, token-level reward trajectories in tasks such as numerical sequence generation and math problem solving indicate that errors are localized and penalized in real-time, and the reward subsequently recovers if later content corrects the error.

Figure 2: Step-wise reward model scores for the correct solution in multi-step mathematical reasoning.
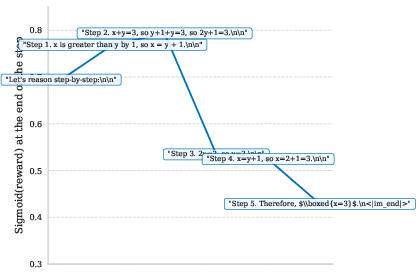
Figure 6: Step-wise reward model scores for the wrong solution, with a sharp drop at the error step, indicating fine-grained error attribution.
Process Reward Modeling from Outcome-Only Data
TCRM outperforms prior outcome-only token-level methods on ProcessBench, achieving 44.9% average F1 without access to explicit step annotations—making it the strongest PRM trained strictly on outcome data. Notably, while full step-labeled PRMs still yield higher F1s, the practical advantage is that TCRM obviates the need for stepwise supervision, which is expensive and often infeasible at scale.
Unified Reward/Value Modeling for RLHF
Crucially, the value-learning property of TCRM enables the same model to serve natively as both reward and value model in PPO, streamlining RLHF pipelines. Several deployment strategies are validated:
- Fully frozen TCRM: The trained RM is used directly as the value function without any further fine-tuning, resulting in a 27% reduction in peak GPU memory usage and a 19% decrease in step time—without measurable loss in policy quality or reward model validation scores.
- LoRA adapter value models: Train lightweight adapters atop TCRM, optimizing compute/memory efficiency over conventional duplication.
- Warm-start fine-tuning: Initialize the value model with TCRM, yielding accurate value estimates from the outset and shortening or entirely avoiding value-model "bootstrapping" periods that can otherwise introduce reward misalignment risks.
Notably, empirical RLHF training curves show matched or improved sample efficiency and reward model scores with TCRM-based PPO regimes compared to baseline, even in the presence of policy distribution shifts during RL.
Theoretical and Practical Implications
Reconceptualizing reward models as value functions offers several important consequences:
- It enables fine-grained, temporally consistent credit assignment and supports debugging, safety attribution, and knowledge tracing through token-level reward decomposition.
- It brings process-level feedback—formerly requiring human- or model-generated fine-grained labels—into reach for settings with only outcome supervision, broadening applicability to long-form, multi-step tasks.
- The resource and engineering gains for RLHF are compelling: by collapsing reward and value modeling into a single, theoretically justified head, training and inference cost for production-grade LLM alignment can be substantially reduced.
A comparison of baseline and TCRM token-wise rewards on realistic LLM outputs illustrates the interpretability and critical localization of faults with TCRM—errors are rapidly detected in the reward trajectory, and the signal is resilient to subsequent correct information, as illustrated in Figures 7–10. These results underscore the non-trivial practical differences in model diagnostics, with TCRM supporting introspective analysis at the token level.
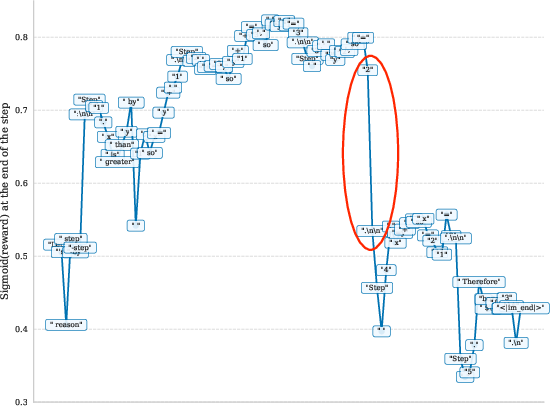
Figure 8: Token-wise reward model scores for the wrong solution, demonstrating precise localization of reward penalties at erroneous tokens.
Additional figures show that TCRM reward trajectories are smooth, monotonic except at genuine error points, and display diversity in how prefix or suffix information is evaluated, corresponding to intuitive human preference patterns.
Limitations and Future Directions
Despite substantial coherence, RM token outputs under TCRM are not perfectly calibrated conditional expectations; residual biases and predictive errors decline with longer prefixes but do not vanish entirely. Open challenges include:
- Improving calibration of token-level conditional expectations, potentially via entropy- or uncertainty-aware smoothing;
- Further studying sensitivity to policy distribution shift in online RL settings, and adapting TCRM to actively recalibrate as policy evolves;
- Exploring dense reward trajectories for real-time error correction, more powerful safety interventions, and credit assignment in online RLHF loops.
Conclusion
"Reward Models Are Secretly Value Functions" demonstrates that enforcing temporal coherence in reward modeling—implemented through simple, theoretically-motivated regularizers—enables RMs to function as token-wise value functions. This not only delivers improved interpretability, process-level supervision from outcome-only data, and substantial efficiency improvements in RLHF, but also provides a solid foundation for future advances in fine-grained, resource-efficient LLM alignment and evaluation within large-scale language modeling systems.

