- The paper introduces temporal difference learning using n-step updates to combine immediate and future rewards for smoother feedback in LLM reinforcement learning.
- Experiments show up to a 23.7% improvement in inference performance and comparable results with only 2.5k training samples versus over 50k in baseline models.
- The integration of process-based and rule-based rewards enhances reward signal stability, leading to improved efficiency and decision-making in RL.
TDRM: Smooth Reward Models with Temporal Difference for LLM RL and Inference
Introduction
The paper "TDRM: Smooth Reward Models with Temporal Difference for LLM RL and Inference" introduces a novel method for improving reward models in reinforcement learning (RL) with LLMs. The key innovation is the use of temporal difference (TD) learning to achieve smoother, more reliable reward signals, addressing the lack of temporal consistency in existing reward models that leads to sparse guidance and instability during training.
Reward Models (RMs) are integral to RL systems, providing feedback not just at the end of the reasoning process but throughout it. Current models, including Process Reward Models (PRMs) and Outcome Reward Models (ORMs), offer distinct advantages but struggle with continuity over long reasoning chains, often degrading training signals and inference efficiency.
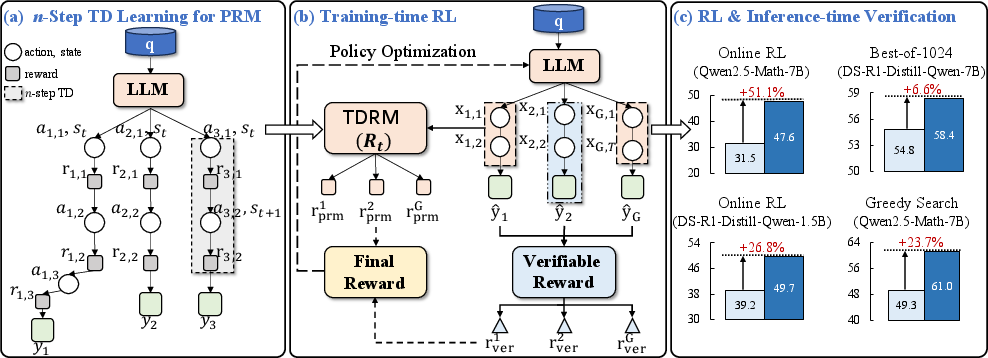
Figure 1: Overall framework of TDRM with temporal difference learning to enhance reward model smoothness.
Methodology
Temporal Difference Learning
TDRM leverages temporal difference learning to address the shortcomings of existing reward models. By introducing n-step TD updates, the paper combines immediate reward signals with estimates of future value, ensuring that intermediate reasoning steps are rewarded dynamically, improving the alignment with long-term objectives.
This approach refines the state value estimates, where the reward function dynamically updates based on a combination of immediate and future rewards. The n-step TD algorithm computes cumulative rewards over n subsequent states and uses these to bootstrap intermediate state values.
Reward Modeling and Smoothness
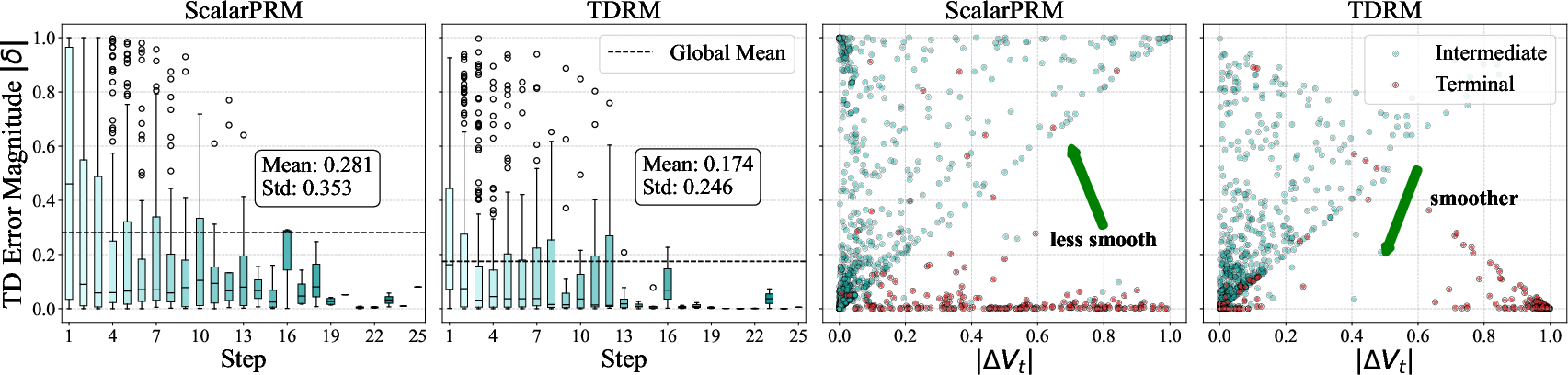
Reward smoothness is crucial for effective LLM reasoning. By minimizing TD error and controlling reward volatility, the TDRM method achieves temporally consistent feedback, critical for both intermediate and final reasoning steps.
Integration with RL
The integration of TDRM within RL is achieved through a linear combination of the process-based rewards from the PRM and rule-based verifiable rewards. This balance enhances feedback density and improves training efficiency, critical to achieving superior performance with minimal data.
Experiments
Settings and Benchmarks
TDRM's performance was evaluated in two key scenarios: inference-time verification (using Best-of-N sampling and greedy search) and training-time reinforcement learning. Experiments highlight TDRM's advantage in smooth reward distribution and enhanced RL outcomes.
Results
The experimental results demonstrate TDRM's edge in achieving higher accuracy and smoother transitions in reward landscapes compared to conventional models:
- Inference-Time Verification: Best-of-N sampling results showed up to a 6.6% gain for N=128 and 23.7% for tree-search strategies when employing TDRM over baseline PRMs.
- Training-Time RL Performance: In RL applications, TDRM-trained models consistently outperform leading RL frameworks in accuracy and data efficiency, achieving comparable success with only 2.5k data samples where others require over 50k.
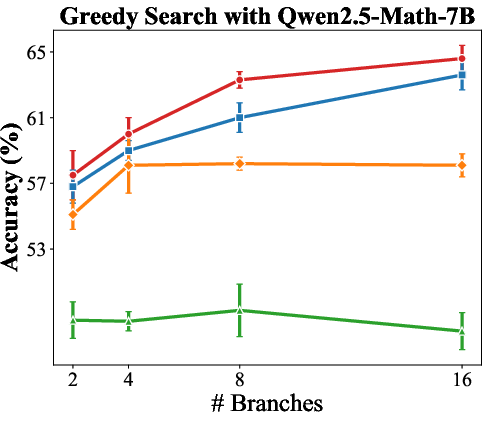
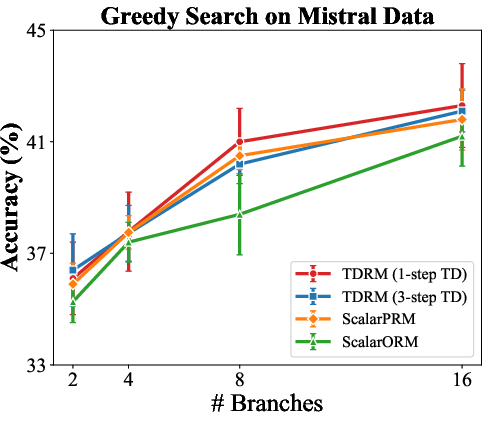
Figure 3: Results of greedy search highlighting enhanced PRM performance with TDRM.
Conclusion
TDRM establishes itself as a reliable technique for reinforcing temporal consistency in reward modeling, particularly within RL and inference applications involving LLMs. By stabilizing reward signals and enhancing feedback density, TDRM addresses a critical bottleneck in current systems, paving the way for improved RL efficiency and reasoning quality in AI models.
Future work can explore more diverse applications for TDRM outside mathematical reasoning, potentially extending its impact across AI research domains simulating complex decision-making processes. The release of code alongside this research aims to promote further exploration and innovation in this area.