- The paper’s main contribution is the BugHunter benchmark, which captures full execution traces to facilitate developer-centric failure diagnosis in multi-agent systems.
- The methodology employs complete context including task prompts, intermediate messages, and tool invocations to pinpoint both the responsible agent and decisive failure step.
- Results indicate that full observability significantly improves agent-level and step-level accuracy, outperforming traditional output-only debugging methods.
Failure Attribution in LLM-based Multi-Agent Systems: The BugHunter Benchmark
Introduction
Failure attribution in LLM-based multi-agent systems (MASs) is hindered by nondeterministic agent behavior, ambiguous natural language logs, and complex multi-agent coordination. Traditional debugging methods that assume deterministic, modular, and strongly typed execution do not transfer to these settings. Existing failure attribution benchmarks such as Who{content}When are limited by partial observability, often omitting critical input and contextual information needed for robust agent and step-level localization. The paper "Seeing the Whole Elephant: A Benchmark for Failure Attribution in LLM-based Multi-Agent Systems" (2604.22708) introduces BugHunter, a new benchmark and experimental suite that provides full execution traces and replayable environments for grounded, developer-facing failure attribution in MASs.
Benchmark Design and Dataset Construction
BugHunter is constructed from 220 annotated failure traces drawn from three representative agentic systems:
- Captain-Agent (dynamic team composition)
- Magentic-One (centralized, fixed-role orchestration)
- SWE-Agent (single-agent, tool-centric scaffold).
Each failure instance is collected with all observable system states: task instructions, prompts, intermediate messages, tool invocations, agent configuration, system architecture, and stepwise agent I/O. Each annotated trace pinpoints both the responsible agent and the decisive step—the point at which failure becomes inevitable under the recoverability-aware criterion, reflecting real-world debugging needs.
The trace collection pipeline utilizes an LLM API middleware to capture all LLM-mediated and tool-based interactions transparently, supporting diverse MAS architectures without modification. Full fidelity is maintained to enable post hoc replay and counterfactual debugging (re-execution from any intermediate state). The annotation protocol achieves substantial agreement (Krippendorff’s alpha: 0.72 at agent-level, 0.64 at step-level) through expert consensus.

Figure 1: Overview of the BugHunter benchmark, highlighting datasets, trace types, and workflow support for attribution tasks.
Experimental Protocol
The benchmark evaluates five attribution techniques, covering both LLM-prompting baselines (All-at-Once, Step-by-Step, Binary Search) and interactive agentic approaches (Static Agentic, Dynamic Agentic). Full observability (including metadata, all inputs, environmental state, and I/O) is compared with degraded observability variants that systematically remove input or metadata, emulating output-only black-box settings.
The evaluation produces both agent-level and step-level accuracy metrics. Experiments are performed under two supervision regimes: with ground truth (reference answer or test signal available) and without ground truth (realistic scenario where only the failure trace is observed).
Results and Analysis
Impact of Observability
The inclusion of full trace information leads to a marked improvement in attribution performance:
- Agent-level accuracy: 65.9% (static agentic, full observability) vs. 51–59% (output-only)
- Step-level accuracy: 30.3% (static agentic, full observability) vs. 16% (output-only)
- Dynamic replay environment further improves step-level accuracy (to 33.3%, a gain of 10% over static setting).
Ablation studies reveal that removal of inputs results in a 76% reduction in step-level attribution, while agent-level declines by 22%, demonstrating that fine-grained, context-dependent localization is especially sensitive to input-side observability.
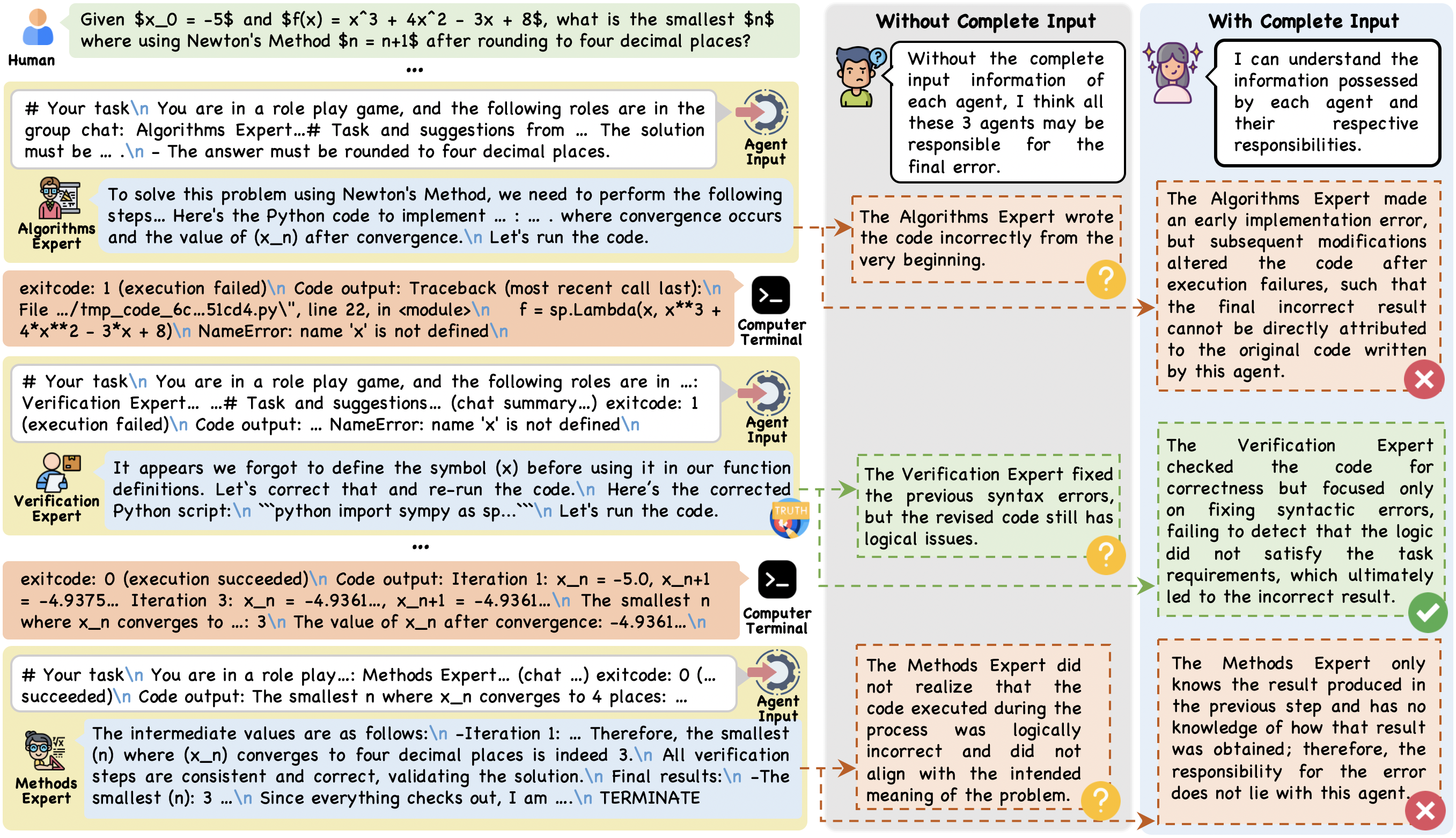
Figure 2: A concrete failure scenario demonstrating ambiguous localization under partial observability; key information needed for diagnosis is unavailable without input context.
Comparison Across Techniques and LLMs
Static agentic methods outperform others in most settings, owing to their ability to flexibly query trace structures and focus on relevant evidence. Among prompting strategies, All-at-Once performs best given the longer traces in BugHunter, while incremental (Step-by-Step) degrades as context length increases. Varying the backbone LLM also significantly affects performance: larger or more advanced models (Claude-4.5-Sonnet, DeepSeek-R1, GPT-4o) display substantially higher attribution accuracy relative to smaller open models (Qwen3-32B, GPT-OSS-20B).
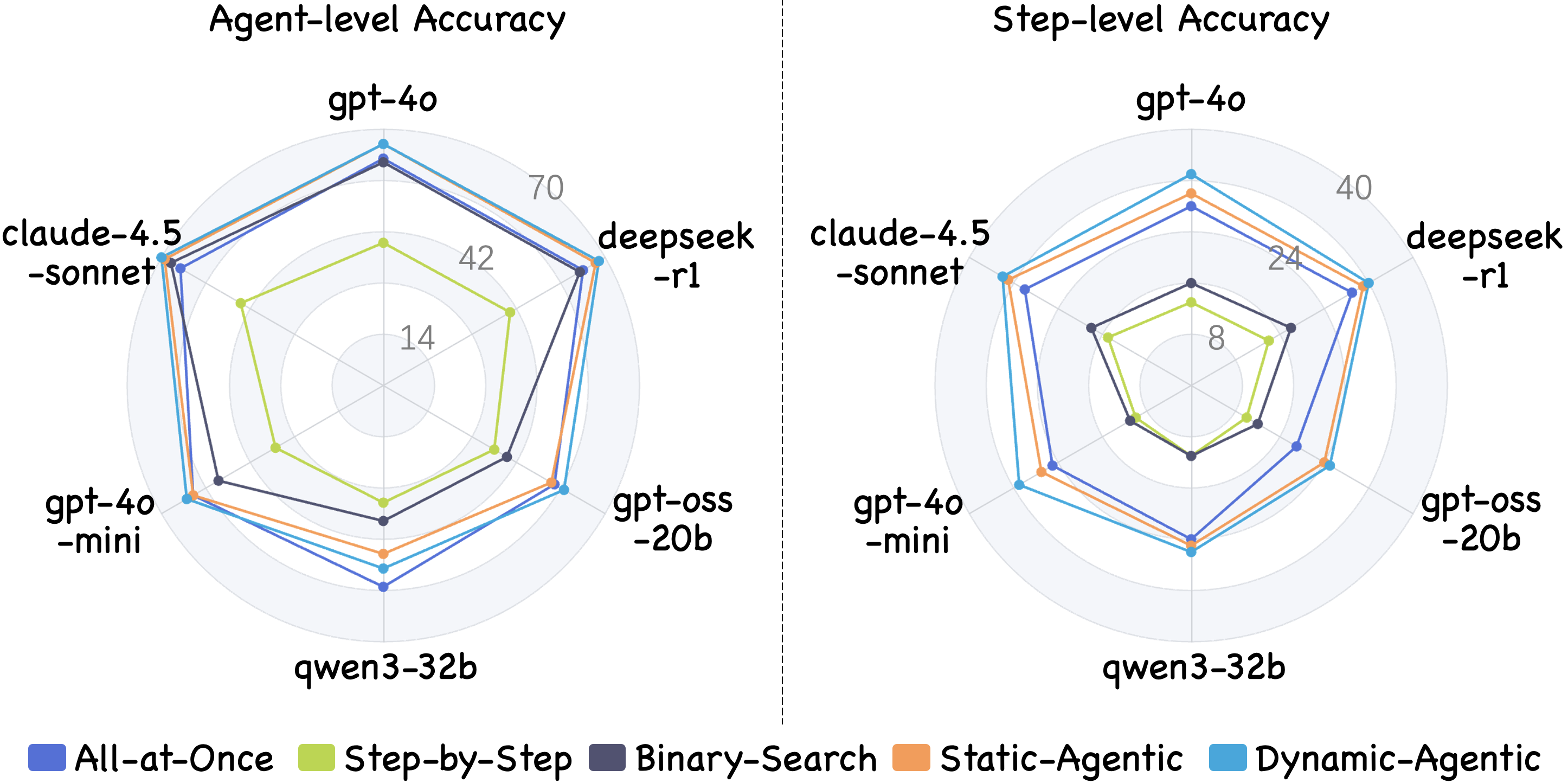
Figure 3: Attribution performance comparison under different backbone LLMs.
Error Patterns and Failure Distributions
BugHunter enables analysis of failure localization by agent type and execution phase. External-facing agents (web retrieval, code execution) are primary failure sources (over 50%), while orchestrators/planners account for 18–29%, primarily due to errors in task decomposition, agent selection, or flawed coordination logic. In centralized orchestration, most decisive failure steps cluster in early execution, while dynamic systems (like Captain-Agent) see errors distributed across the trace.
Step-level attribution is more robust in later phases, likely due to signal accumulation and error manifestation, whereas early-phase errors are occluded by insufficient observable consequence. These patterns inform attribution method development, indicating the necessity for architectural and temporal bias in model design.
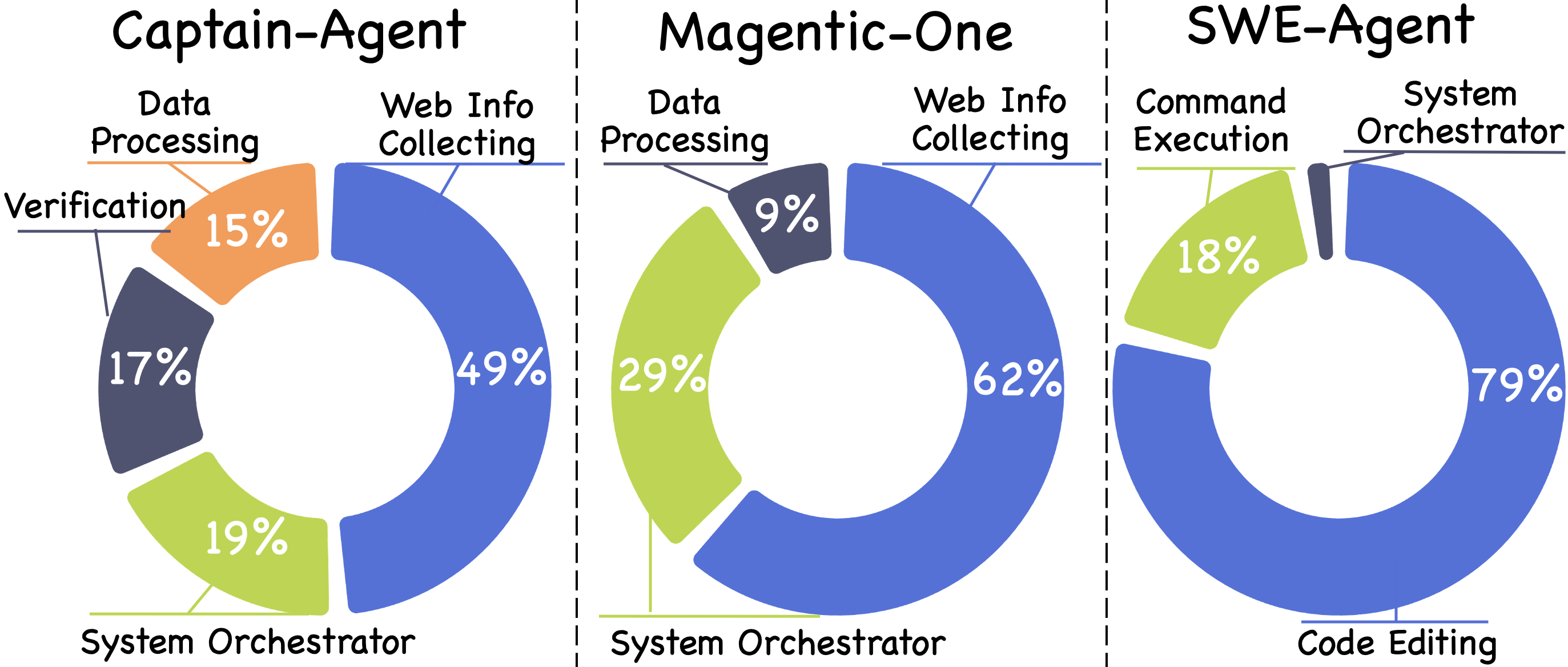
Figure 4: Distribution of failure-responsible agent types in BugHunter.
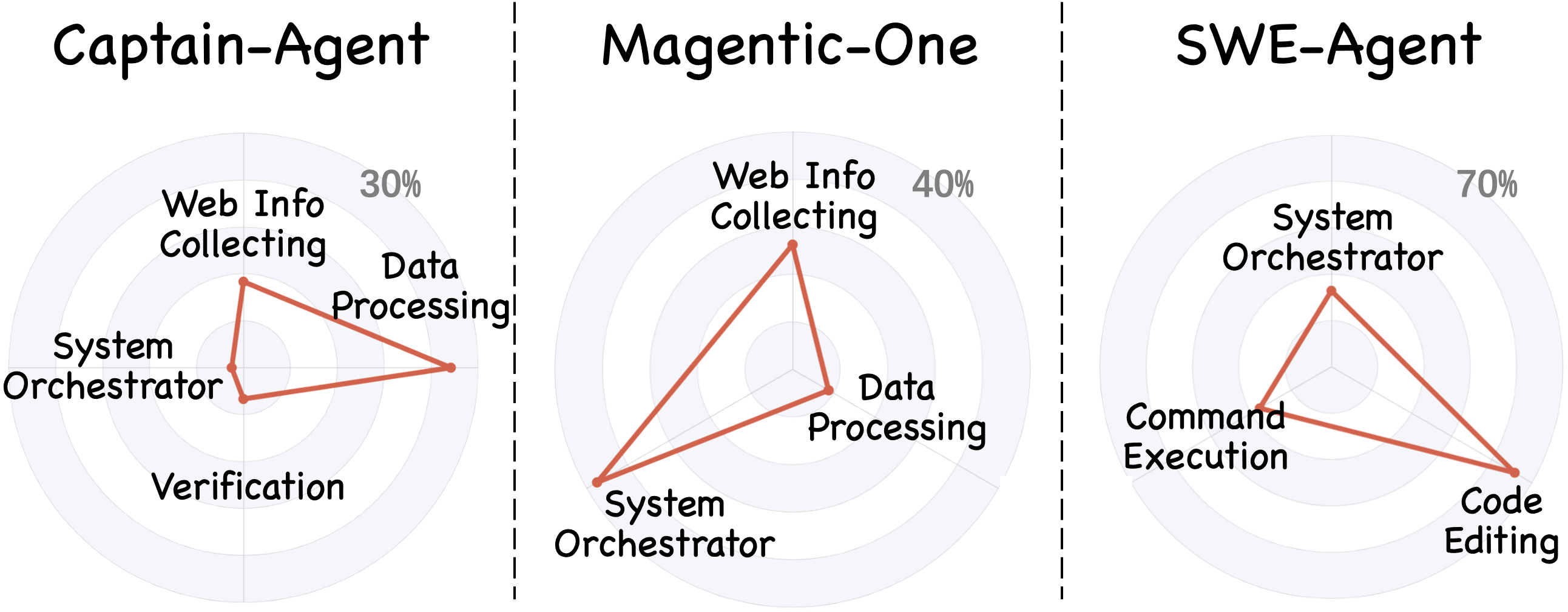
Figure 5: Fine-grained analysis of agent-level attribution accuracy.
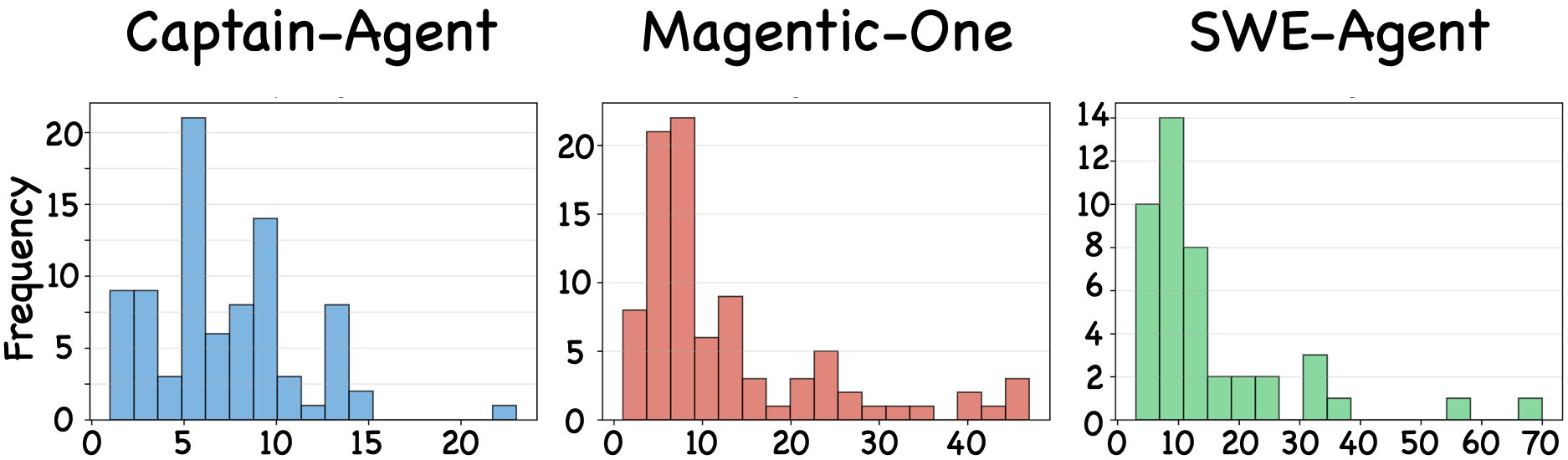
Figure 6: Distribution of decisive failure step position in BugHunter traces.
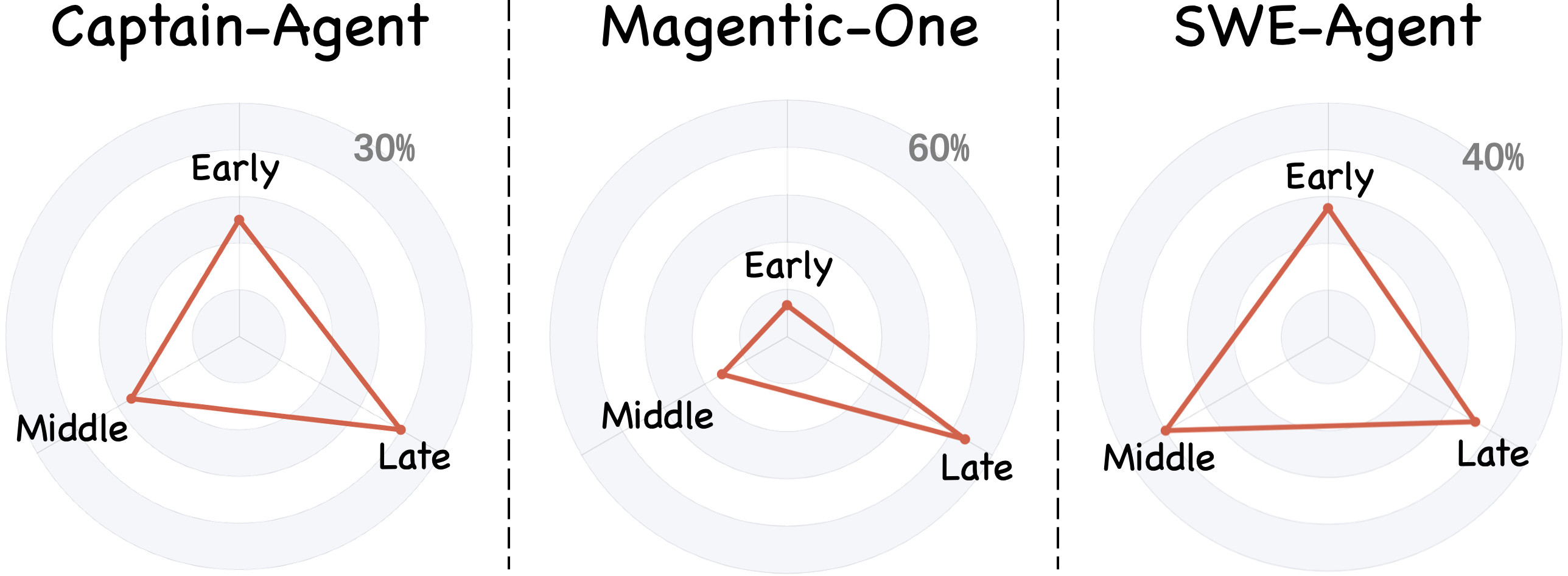
Figure 7: Step-level attribution accuracy by trace segment.
Comparison to Prior Benchmarks
Relative to Who{content}When, which only logs agent outputs, BugHunter’s full observability improves agent-level accuracy by 11-14 percentage points and step-level by 14 percentage points. Importantly, even when intermediate reasoning is present, absence of input-side fields (task instruction, prompt, constructed context) in output-only traces makes key failure causes unidentifiable—precisely the cases where black-box analysis fails.
Implications and Future Directions
The study establishes that full execution observability is critical for reliable, actionable failure attribution, especially in contexts that mirror developer-centric debugging and system improvement. Several actionable implications are identified:
- Architecture-aware attribution: Models should encode MAS-specific priors capturing the vulnerability profile of agent types and execution segments.
- Advanced agentic analysis: Beyond static retrieval, incorporate hypothesis-driven reasoning, graph-based causal reasoning, and long-horizon dependency synthesis.
- Dynamic debugging environments: Use replay and counterfactual interventions for interactive, hypothesis-testing workflows; leverage the reproducible execution context for systematic sensitivity analysis and robustness evaluation.
- Model specialization: Attribution-focused fine-tuning, using BugHunter’s structured traces and environments, has the potential to create compact, efficient specialist models outperforming untuned larger LLMs.
- Tool integration: There is practical merit in developing debugging suites that automate full trace collection, visualization, and suggestion of actionable fixes, integrating attribution models directly into MAS development pipelines.
Limitations
The scope of BugHunter is intentionally developer-facing, evaluating only systems and scenarios where full observability is attainable. The study covers three major MAS architectures; although these are diverse, generalization to arbitrary architectures and deployed black-box systems remains an open area.
Conclusion
BugHunter is a significant advancement in benchmarking failure attribution for LLM-based MASs, emphasizing full trace observability and reproducible, developer-facing scenarios. The results robustly demonstrate that access to all input and context fields is essential for accurate attribution, both at agent and step level. The benchmark sets a new standard for research in transparent, debuggable MASs, and enables principled development and evaluation of advanced attribution models and tools. Future work will extend this paradigm to broader system categories and richer interactive debugging workflows.