- The paper formulates LLM failure analysis as a contrastive attribution problem using AttnLRP, revealing token-level failure patterns such as URT and OIT.
- It introduces a GPU-efficient attribution-graph construction that scales to long-context inputs and tracks relevance shifts during model scaling and training.
- The study demonstrates that practical interventions, like prompt tuning and model scaling, can adjust late-layer biases, providing actionable insights for LLM optimization.
Contrastive Attribution for Failure Analysis of LLMs: An Empirical Study on Realistic Benchmarks
Problem Statement and Motivation
Recent advances in LLM interpretability have not led to systematic diagnostic tools for realistic, real-benchmark-induced failures in LLMs. Most prior analysis has been constrained to synthetic data, toy tasks, or restrictive short-prompt settings, lacking generalization to long-context, complex benchmarks. This paper proposes a practical interpretability methodology—contrastive LRP-based token-level attribution—for analyzing why LLMs select incorrect tokens during naturalistic benchmarks, and rigorously evaluates its utility and limits across tasks, model scales, and training phases (2604.17761).
Methodological Advances
The key technical contribution is formalizing LLM failure analysis as a contrastive attribution problem using Layer-wise Relevance Propagation (LRP): given a misprediction, the contrastive logit difference (incorrect token vs. correct alternative) is decomposed via LRP (specifically AttnLRP) into additive attributions on input tokens and internal states across layers. The authors introduce a GPU-efficient extension for bulk construction of cross-layer attribution graphs suitable for long-context inputs, leveraging batch-packed gradient∗input computations. This enables both scalar input-level heatmaps and explicit propagation graphs of relevance flows in large models.
Experimental Protocol and Dataset Coverage
Benchmarks include GAIA2 (agentic/long-context), IFEval (instruction following), MATH (formal math reasoning), and EvalPlus (code generation), covering broad LLM application spectra and context lengths up to 12k tokens. Analyses are run on Qwen3 models of varying sizes (0.6B–8B), and the evolution of attribution is tracked through the Olmo-3-7B-Think checkpoints. A rigorous semi-automated pipeline localizes error tokens and assigns contrast tokens, using LLM/human agreement for reliability. Only cases where a strong alternative actually recovers the correct trajectory are retained for high-confidence attribution.
Empirical Findings
Attribution Outcome Distributions
In all but the MATH domain, most failures can be explained at the input-token attribution level (M-IA), with heatmaps indicating underweighting of key tokens (URT) or overweighting of irrelevant ones (OIT):
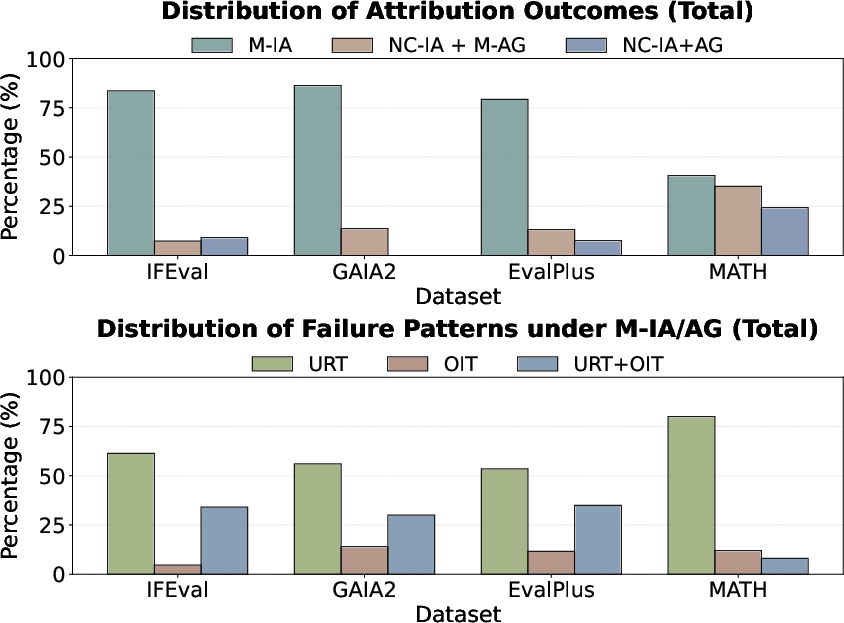
Figure 1: Attribution outcome statistics and failure patterns across benchmarks reveal input attributions suffice for most failures except in the MATH domain.

Figure 2: Examples of attribution heatmaps: (a) URT—critical instruction token "commas" is insufficiently weighted; (b) OIT—irrelevant token "(a" receives excessive attribution; (c) NC-IA—input attribution is uninformative, motivating graph-level analysis.
In MATH, many failures remain unexplained even after attribution graph analysis, implicating hidden, internal, possibly neuron-level phenomena.
Attribution Graphs for NC-IA Cases
For cases not explained by input attributions (NC-IA), cross-layer attribution graphs expose subtler interactions, e.g., complex competition between relevant and spurious tokens in mid-to-late layers:
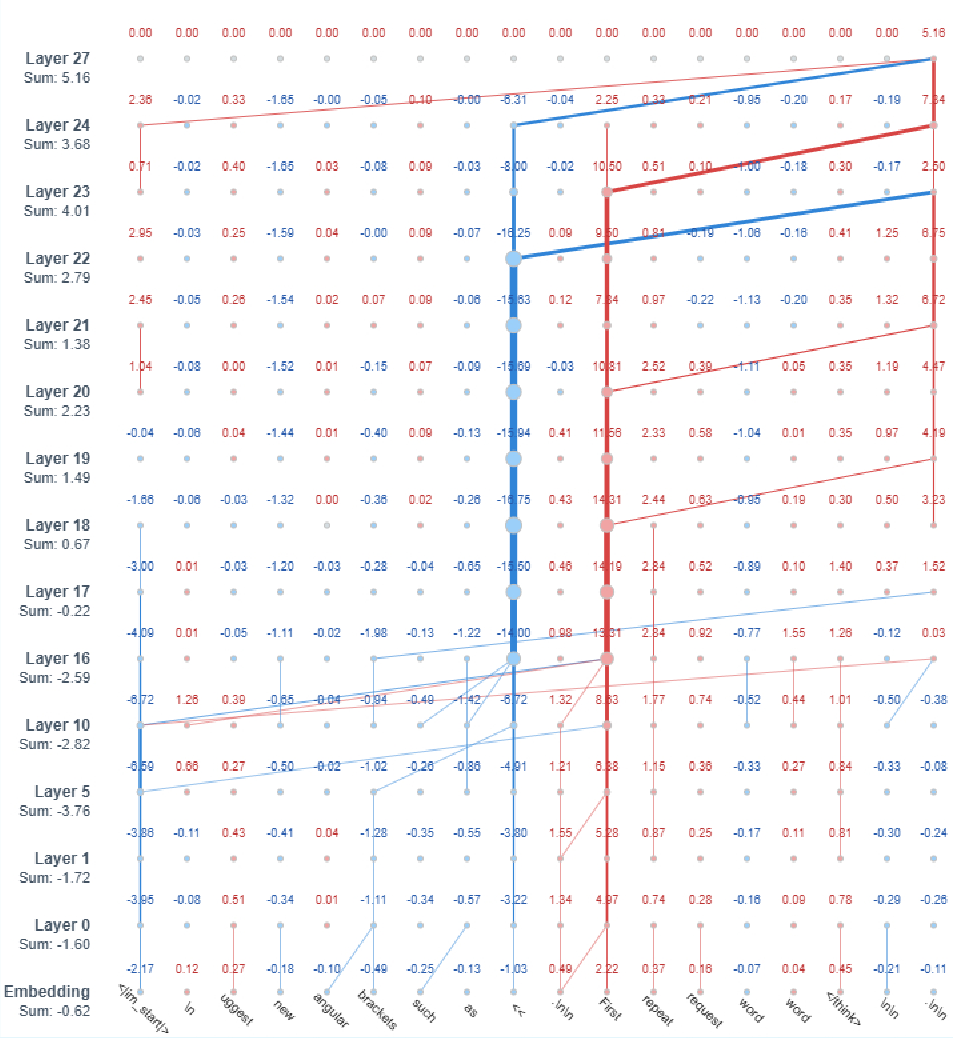
Figure 3: Ablated cross-layer attribution graph captures layer-wise relevance propagation in a failure case only explainable beyond input attributions.
These graphs show critical transitions in later transformer layers where the decisive bias toward the incorrect outcome accumulates.
Model Scaling Effects
Scaling Qwen3 models from 0.6B to 4B/8B parameters corrects a majority of initial failures in IFEval, as per negative shifts in logit differences for error-corrected cases:
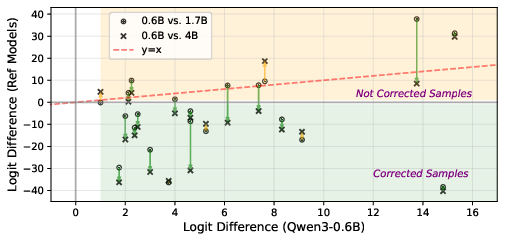
Figure 4: Model scaling yields systematic correction of erroneous logit preferences in failure cases; green points reflect successful fixes.
Attribution relevance shifts coincide with these improvements: corrected samples show a distinct pattern—relevance on the instruction, query, and answer sections becomes more negative, indicating greater sensitivity to task constraints and less to superficial continuations.
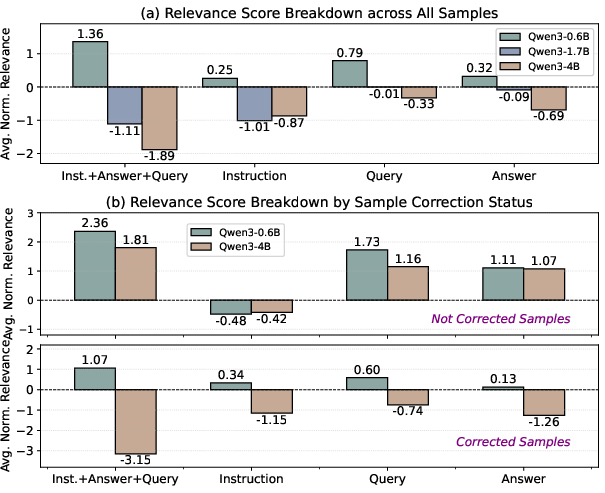
Figure 5: Larger models show increased negative attributions on constraint/requirement segments, further separating corrected from uncorrected cases.
Training Dynamics
Assessing Olmo-3-7B-Think checkpoints, the evolution of logit difference and segment-wise relevance is consistent with early SFT and DPO phases resolving the majority of errors, especially through attribution shift away from answer-superficiality to task-constraint tokens.
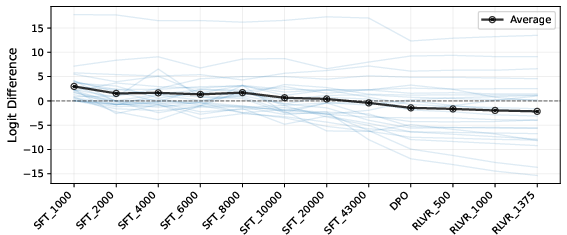
Figure 6: Training checkpoints show consistent reduction in erroneous logit differences; major attribution shifts occur in early SFT.
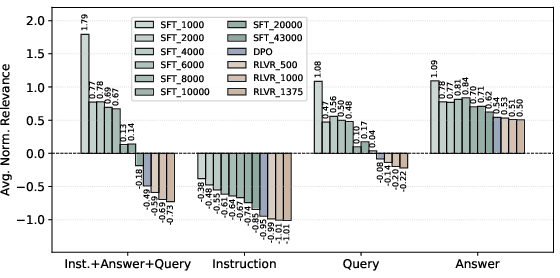
Figure 7: Relevance magnitudes over checkpoints reveal most attribution corrections are concentrated in the SFT and DPO stages.
Attribution Decomposition and Functional Specialization
Statistical analysis across all failure cases reveals strong regularities:
- Early layers are bias/self-dominated; mid layers confer most context integration; BOS/token biases accumulate in later layers.
- The critical layers for decisive attribution transitions are always late (L20–L27 in Qwen3-0.6B).
- Attribution profile clustering and decomposition structure are largely orthogonal; failure taxonomies cannot be meaningfully built from a single decomposition axis, indicating the inherent multidimensionality of LLM errors.
Implications and Future Directions
Practical: Token-level attributions offer actionable signals for prompt tuning, as masking top contributors as few as two tokens can often correct erroneous outputs. Attribution trajectory analysis enables diagnoses during model scaling and training stages, and informs targeted intervention (e.g., attention head pruning, activation surgery) to modify late-layer bias or enhance context integration.
Theoretical: The results highlight that current token-level contrastive attributions suffice for many classes of LLM failures but fail to capture more structured, multi-step or nonlocal error mechanisms, especially in math reasoning, motivating advances toward phrase-level, step-level, and neuron-level attribution. The transition from input-level to internal, circuit-level analysis using large-scale attribution graphs and mechanistic methods is needed for full mechanistic debugging.
Conclusion
This work demonstrates that contrastive, LRP-based attribution—especially as instantiated in AttnLRP with efficient attribution-graph construction—scales to realistic LLM benchmarks, reveals mechanistically interpretable signals for a majority of failure cases, and tracks both error correction via scaling and behavioral shifts during model training. However, it also demonstrates the technique’s inherent limits in, e.g., math reasoning failures where errors are embedded in diffuse, internal structures not recoverable at token or state aggregation levels. Robust diagnostic interpretability in next-generation LLMs will require the joint development of scalable, expressive, and multi-level attribution tools capable of bridging from input factors to latent circuit motifs.

