- The paper proposes automated failure attribution methods to identify which agent causes task failures and when, substantiated by detailed experiments.
- It introduces the Who{content}When dataset with 127 multi-agent failure logs, offering a benchmark for evaluating attribution methodologies.
- Three methods—All-at-Once, Step-by-Step, and Binary Search—are compared, revealing trade-offs between accuracy and computational efficiency.
Automated Failure Attribution of LLM Multi-Agent Systems
This essay provides an in-depth analysis of the paper titled "Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems" (2505.00212). The paper explores the challenges and methodologies related to automating the process of identifying failure-responsible agents and decisive error steps in multi-agent systems powered by LLMs. This research fills an important gap in AI method development by streamlining debugging processes while emphasizing the need for automated tools to handle the complex interactions within agentic systems.
Introduction to Failure Attribution
Failure attribution in multi-agent systems involves pinpointing which component or agent within the system is responsible for a task's failure. The process, while critical for debugging and system improvement, has traditionally required significant human expertise and manual effort, making it inefficient and error-prone.
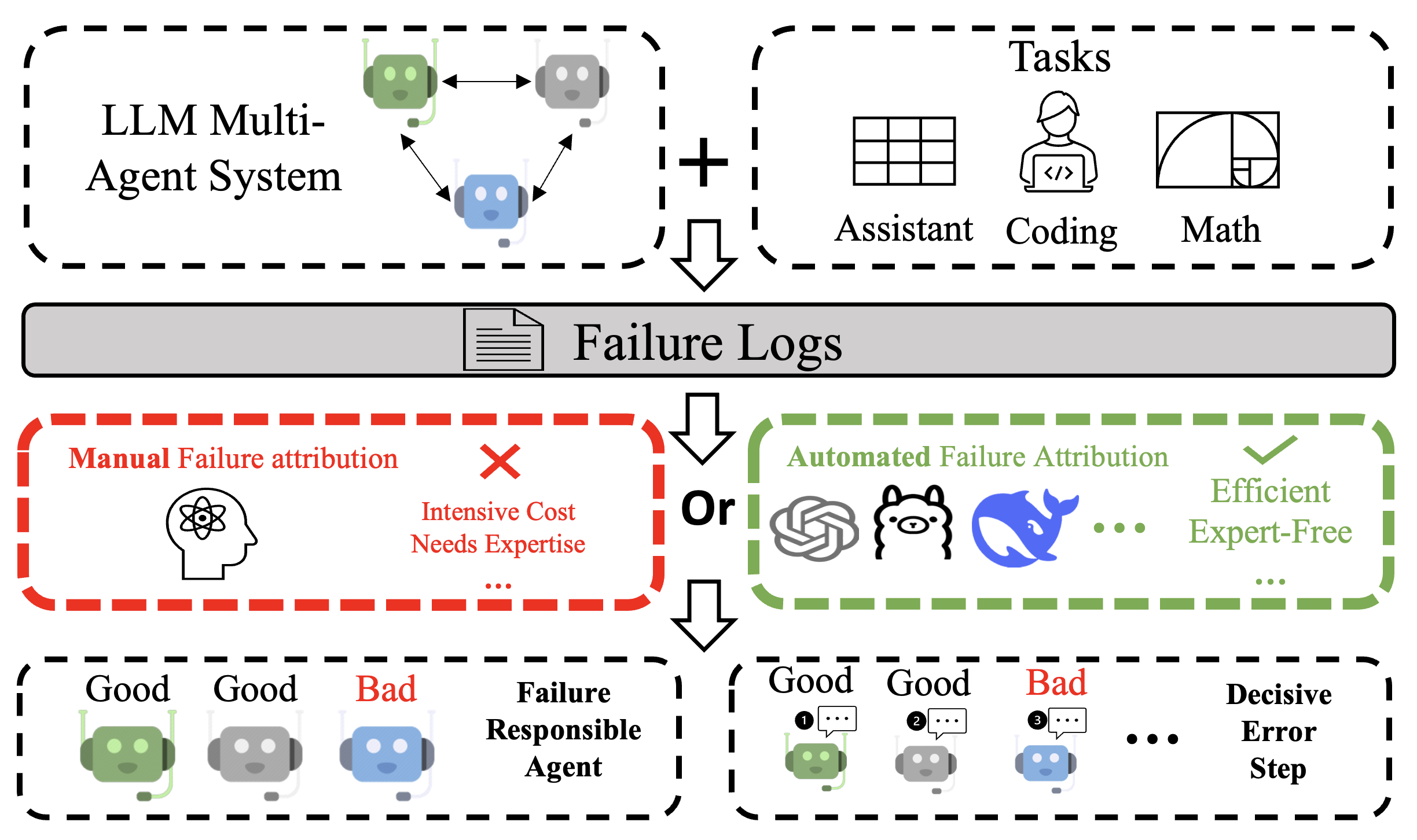
Figure 1: When developing LLMs-powered multi-agent systems, failure attribution—identifying system components responsible for task failures based on evaluation results—has received limited attention in existing research. This process is typically performed manually, demanding substantial labor and specialized expertise. In this study, we explore the potential for automating this process.
The Who{content}When Dataset
The Who{content}When dataset introduced in the paper is a meticulously annotated collection of failure logs from 127 multi-agent systems, designed to support the development of failure attribution methodologies. The dataset includes detailed annotations linking specific agents and steps within each failure, and it serves as a benchmark to evaluate the performance of proposed failure attribution methods.
Dataset Analysis and Challenges
The annotation process itself is labor-intensive, highlighting the necessity for automation. Statistical analyses of the dataset reveal the difficulties in achieving agreement among human annotators due to complex multi-agent interactions, as illustrated in the annotation disagreement rates (Figure 2). These findings emphasize the dataset's utility in driving automated methods that aim to reduce human labor investment in the debugging process.
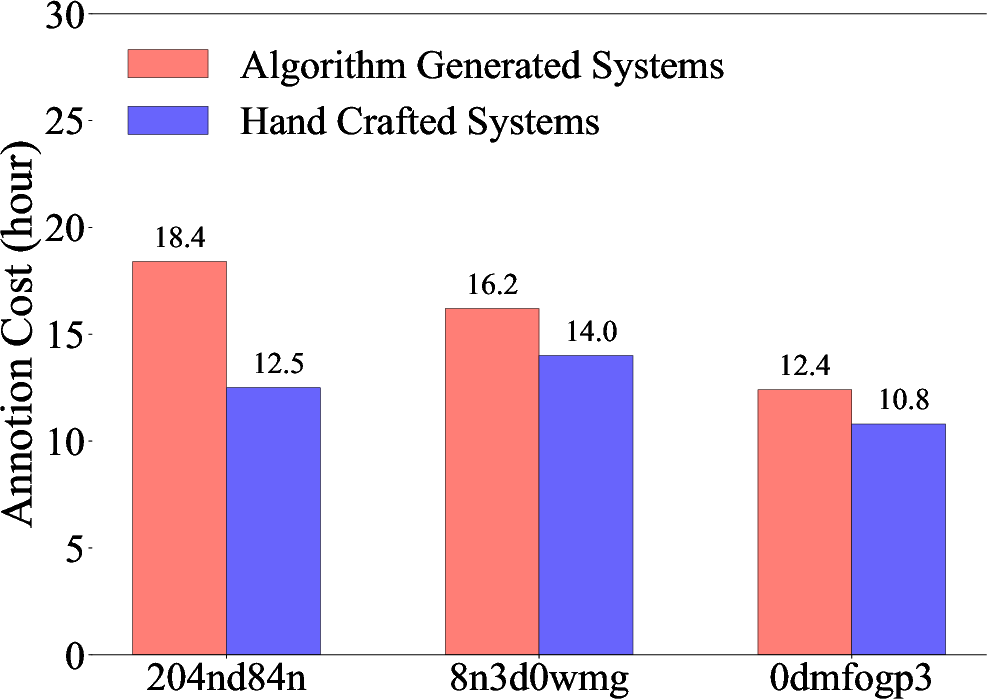
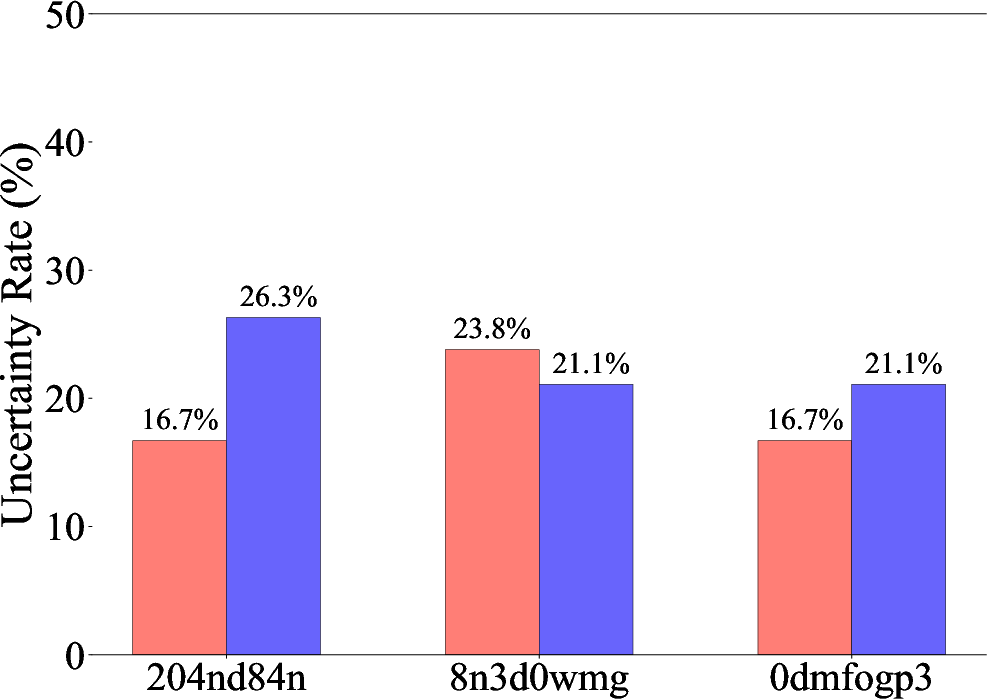
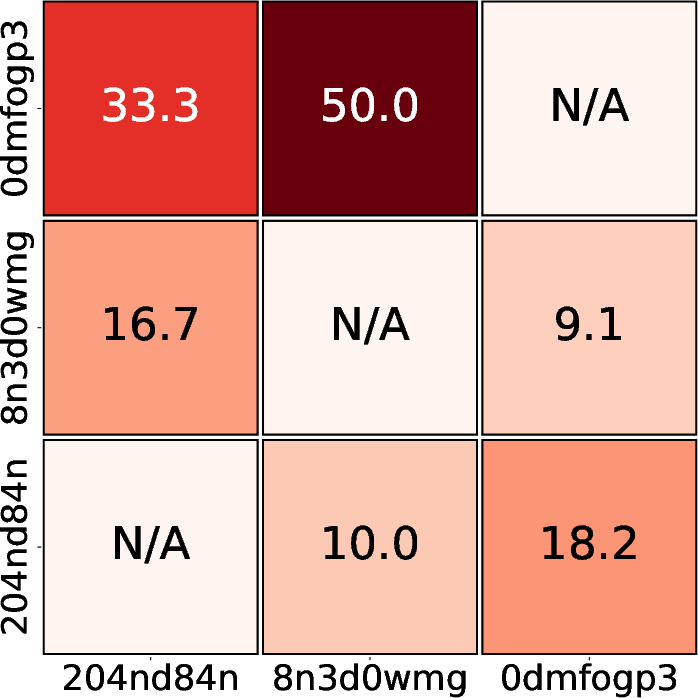
Figure 2: Statistical analysis of the annotation process: (1) Total labor cost for annotations in human hours. (2) The proportion of uncertain annotations to total annotations during the second round. (3) Initial disagreement rates between annotators (note that we make sure to reach a consensus through a careful discussion and voting process afterwards). These results highlight the challenges involved in performing manual failure attribution.
Automated Failure Attribution Methods
Three principal methods for automated failure attribution are explored in the paper: All-at-Once, Step-by-Step, and Binary Search. Each method offers a unique approach to breaking down the conversation logs recorded during tasks and identifying critical errors.
All-at-Once Method
This method processes the entire failure log in one pass, allowing for a broad overview that is particularly useful for identifying failure-responsible agents. It benefits from comprehensive context but often struggles with pinpointing the specific error steps within a lengthy log.
Step-by-Step Execution
By incrementally evaluating each step in the log, the Step-by-Step method facilitates precise error identification. It excels in step-level accuracy due to its fine-grained analysis, although it may incur higher computational costs.
Binary Search
Binary Search takes a middle ground by dividing the log into segments, reducing the search space iteratively. It provides a balance between computational efficiency and the ability to locate errors effectively across varying log lengths.
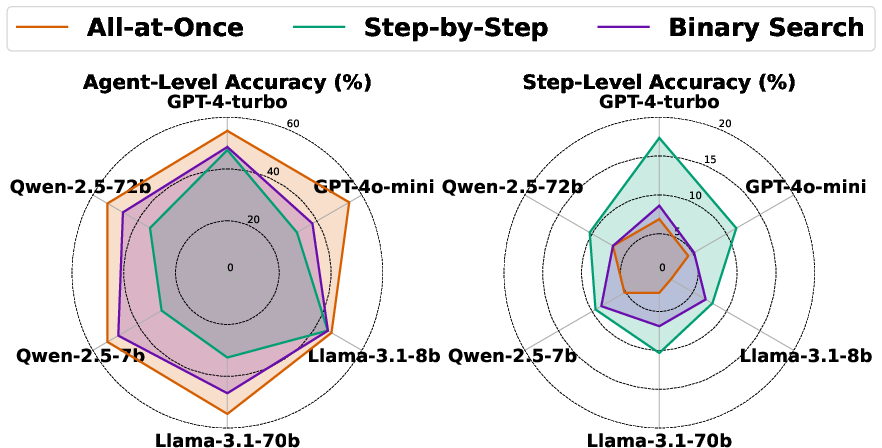
Figure 3: Performance comparison of three failure attribution methods on different models in both two metrics. We found the conclusion is mostly consistent with Table~{ref:table-comparison}.
Experimental Results
Extensive experiments conducted across various LLMs highlight the respective strengths and weaknesses of each method under different conditions, such as the availability of ground truth and varying log lengths. Interesting observations include the enhanced performance of all-at-once when identifying failure-responsible agents, while step-by-step remains superior in determining precise error steps.
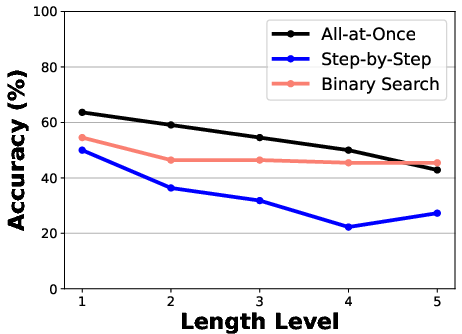
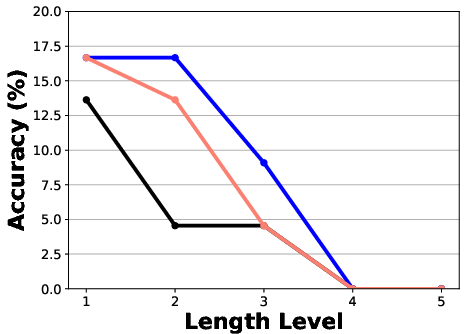
Figure 4: Comparison of three failure attribution methods applied to all failure logs from the hand-crafted systems in the Who{additional_guidance}When, evaluated under varying failure log lengths across both metrics.
Conclusion
This study addresses a critical gap in the development of LLM multi-agent systems by proposing robust methodologies for failure attribution. The insights validate the complexity of deploying automated solutions in real-world AI systems and underscore the importance of Who{content}When as a benchmark for future research in this domain. Continued advancements in this area promise to reduce labor costs and improve the reliability and efficiency of AI systems operating in diverse environments.

