- The paper demonstrates that classical QPP methods, particularly lightweight pre-retrieval predictors, enhance query variant selection for effective generative answer synthesis.
- It reveals a misalignment between traditional retrieval ranking metrics and generative answer utility, underscoring the need for generation-aware evaluation frameworks.
- Empirical results on TREC-RAG benchmarks show that basic IDF and SCQ measures can improve nugget-based answer metrics by 45–66% compared to the original queries.
Motivation and Background
Retrieval-Augmented Generation (RAG) architectures have shifted information retrieval from pure ranking tasks to complex pipelines where LLMs synthesize answers conditioned on evidential retrieval [lewis2020retrieval, gao2023retrieval]. Query reformulation, especially via LLMs, has become pivotal for maximizing recall and contextualizing answer synthesis [killingback2025benchmarking, dhole2024genqrensemble, ye2023enhancing]. Over-generation of semantically equivalent query variants is standard practice, with subsequent selection of optimal variants for answer synthesis; however, running retrieval and answer generation for every variant is computationally impractical at scale.
Query Performance Prediction (QPP) offers a mechanism for candidate pruning at the query variant level, potentially enabling upstream filtering of ineffective queries before incurring downstream latency and monetary cost. While QPP has traditionally been used for retrieval-centric tasks—predicting absolute or relative difficulty of queries without access to relevance judgments [carmel2010estimating, arabzadeh2024query]—its utility in intra-topic, variant-level selection for RAG systems is underexplored.
This work systematically examines whether QPP can function as an effective selection mechanism for LLM-generated query variants under both sparse and dense retrieval paradigms, measuring impact on end-to-end RAG utility and benchmarking the alignment between retrieval and generation targets.
Experimental Design
The study leverages the TREC-RAG 2024 benchmark, using 56 information needs over MS MARCO v2.1, each expanded to 30 LLM-based query variants via diverse reformulation strategies (GenQR, GenQR-Ensemble, MuGI, QA-Expand, Query2Doc, Query2Exp) [bigdeli2025querygym]. For each variant, retrieval quality is measured using standard sparse (BM25) and dense (Cohere) retrievers, with RAG utility assessed by nugget-based metrics evaluating answer coverage and fidelity.
A comprehensive battery of QPP methods is contrasted, including:
- Pre-retrieval predictors: Term specificity/statistics (IDF, ICTF, SCQ, SCS), neural embedding-based approaches (DM, QSD), and supervised transformers [faggioli2023query, bigdeli2025query].
- Post-retrieval predictors: Score-distribution models (Clarity, WIG, NQC, SMV), reference list analysis, neural models (BERT-QPP), and retrieval score variance estimators.
- Oracle selectors: Idealized upper bounds selecting the variant with maximum true performance per metric.
Selection accuracy is assessed with both correlation-based and decision-based (actual utility improvement by variant selection) measures.
Key Findings
Classical QPP is weakly aligned with RAG objectives: strong predictors for retrieval quality (e.g., nDCG@5) fail to consistently select query variants optimizing answer synthesis. Notably, lightweight pre-retrieval statistics (e.g., IDF-based aggregators) often match or outperform sophisticated post-retrieval predictors in actual end-to-end answer gains, especially when evaluated on nugget utility metrics.
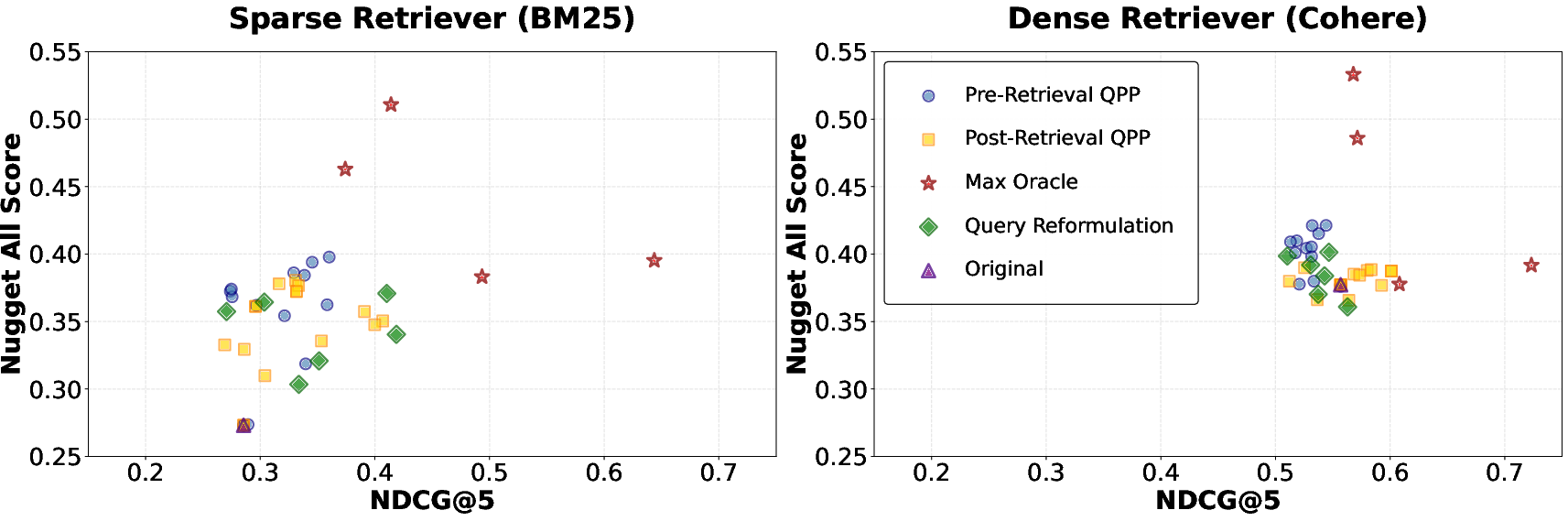
Figure 1: Relationship between retrieval effectiveness (nDCG@5) and end-to-end RAG utility (Nugget-All) under sparse and dense retrieval. Each point corresponds to a query variant selected by different QPP strategies, a single reformulation, the original query, or oracles.
The figure demonstrates a systematic decoupling: query variants with improved ranking do not necessarily induce gains in generative answer utility, and vice versa. This “utility gap” reveals a fundamental misalignment between retrieval- and generation-optimized selection. For instance, variants that maximize nDCG@5 may yield sub-optimal coverage of answer nuggets (key facts/aspects), while variants with lower retrieval scores can exhibit superior support for vital answer elements.
Empirically, pre-retrieval QPP methods, particularly aggregations over IDF and SCQ, yield the highest relative improvements in RAG performance over the original query, with gains of up to 45–66% on strict and lenient nugget metrics (BM25, IDF_max). Post-retrieval QPP provides marginal added value for answer quality despite stronger gains for classic ranking metrics, indicating limited marginal benefit when the system’s objective is end-to-end generation.
Crucially, even perfect prediction of retrieval effectiveness does not close the gap to oracle upper bounds for answer utility. Oracle analyses confirm that the best-performing query variant for retrieval is typically not the best for answer generation, demonstrating that variant selection must target generation-aware metrics.
Theoretical and Practical Implications
The study has multiple ramifications:
- Reframing QPP for RAG: QPP must be tailored for intra-topic decision-making and evaluated on generation utility, rather than on inter-topic retrieval-difficulty correlations or global ranking agreement.
- Efficiency: Pre-retrieval predictors—computationally cheap and model-agnostic—are sufficient for robust variant pruning, yielding significant latency and cost benefits in RAG pipelines.
- Divergence of objectives: The weak alignment between retrieval and generative utility underscores the need for generation-aware QPP tailored to anticipated answer infidelity or nugget coverage loss, not just retrieval confidence.
- Evaluation methodology: Correlation with ranking metrics is inadequate for variant selection; direct end-to-end evaluation and selection-accuracy metrics are essential.
Practically, RAG systems should avoid naively optimizing upstream QPP signals for retrieval metrics when answer fidelity is critical. Instead, lightweight, selection-oriented QPP can attain robust improvements with negligible computational overhead, but further methodological advances are needed to approach oracle ceilings.
Prospects for Future Research
Future research should focus on the development of coupled retriever-generator performance predictors, directly modeling passage-answer support relations and LLM context sensitivity to passage composition. Hybrid approaches utilizing weak supervision from generative answer metrics, utility-annotated variant pools, or reinforcement learning for variant selection may be promising.
Additionally, adversarial analysis of variant pools, robustness to out-of-distribution queries, and domain-specific adaptation of QPP merit investigation. Finally, extension to real-time, user-facing scenarios with budgeted variant execution will require new trade-offs between efficiency, robustness, and answer faithfulness.
Conclusion
This study rigorously demonstrates that QPP can reliably select LLM-generated query variants for RAG pipelines, improving over both original queries and fixed reformulation baselines. However, optimizing for retrieval effectiveness alone is insufficient, and the gap to oracle answer utility highlights the necessity for generation-aware prediction and evaluation frameworks. Efficient pre-retrieval QPP offers a practical route for robust, budget-conscious RAG execution, but future work must address the structural misalignment unveiled between retrieval and answer optimization targets.
Reference: "Can QPP Choose the Right Query Variant? Evaluating Query Variant Selection for RAG Pipelines" (2604.22661)