- The paper introduces DMQR-RAG, a framework integrating four distinct query rewriting strategies to boost document retrieval in RAG systems.
- It employs adaptive strategy selection using lightweight prompting and few-shot learning to optimize rewriting efficiency without compromising precision.
- Experimental results on AmbigNQ, HotpotQA, and FreshQA demonstrate significant improvements in retrieval metrics, highlighting its practical efficacy.
DMQR-RAG: Diverse Multi-Query Rewriting for RAG
Introduction
The DMQR-RAG framework addresses critical challenges in LLMs regarding static knowledge and hallucinations by integrating RAG techniques. Implementing diverse multi-query rewriting within RAG systems seeks to enhance document retrieval and response accuracy. This paper explores the creation of diversified query rewrites to broaden the spectrum of retrieved documents, leveraging four distinct strategies that operate at different information levels. Furthermore, adaptive strategy selection aims to minimize unnecessary rewrites, optimizing performance without degrading retrieval results.
Diverse Multi-Query Rewriting Framework
DMQR-RAG innovates upon current methods by expanding query rewriting into a multi-query framework that intensifies document diversity in retrieval tasks. The four primary rewriting strategies include:
- General Query Rewriting (GQR): Denoising while preserving informative elements, this strategy aligns with prior research approaches to remove irrelevant data without losing context, thus improving precision.
- Keyword Rewriting (KWR): Extracting keywords focuses the retriever's efforts, aiding in precise alignment with user queries and exploiting search engine optimization.
- Pseudo-Answer Rewriting (PAR): Enriching initial queries with pseudo-answers derived from LLMs, significantly enhancing semantic frameworks and document retrieval, particularly relevant when factual discrepancies arise due to hallucinations.
- Core Content Extraction (CCE): Reducing extraneous detail by focusing on essential elements to align retrieval efforts with user intent, thereby reducing the cognitive load across subsequent processing stages.
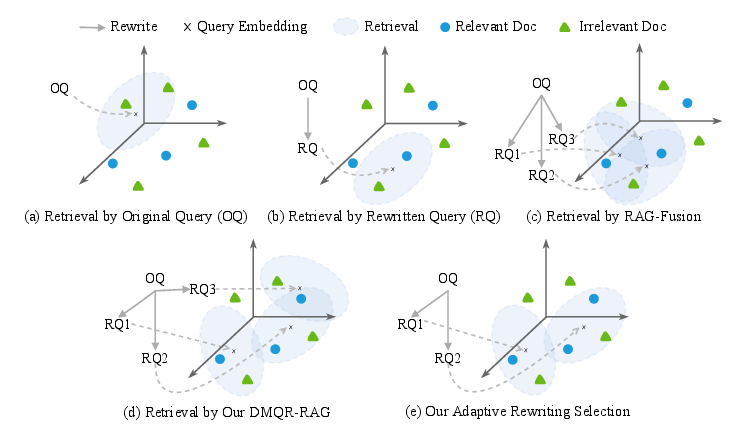
Figure 1: The motivation of DMQR-RAG, illustrating diverse rewriting strategy benefits and adaptive selection.
Adaptive Strategy Selection
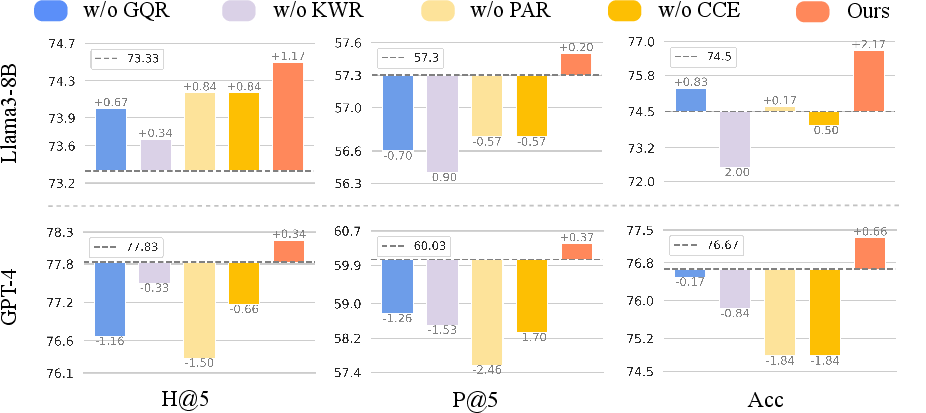
Adaptive rewriting strategy selection capitalizes on query characteristics, employing lightweight prompting and few-shot learning to dynamically choose appropriate strategies. Such selection enhances efficiency, reducing noise by minimizing unnecessary rewrites, as evidenced through a Gaussian distribution of rewrites in experimental settings.
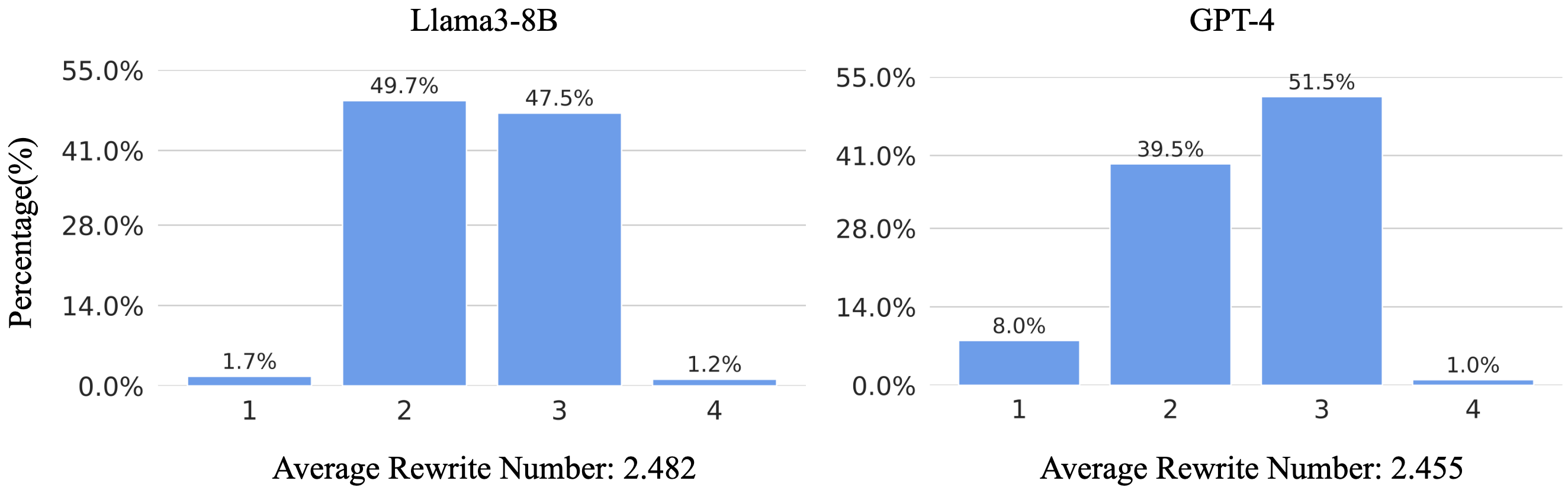
Figure 2: The results of adaptive rewriting selection show a Gaussian distribution of the rewriting number, demonstrating effective strategy adaptation.
Experimental Evaluation
Results from both academic and industry scenarios underline the advantages of DMQR-RAG over traditional single-query methods and vanilla multi-query approaches like RAG-Fusion. The robustness of DMQR-RAG is apparent across diverse datasets:
The framework's adaptability is further exemplified in real-world applications, demonstrating superior retrieval metrics and enhanced response precision.
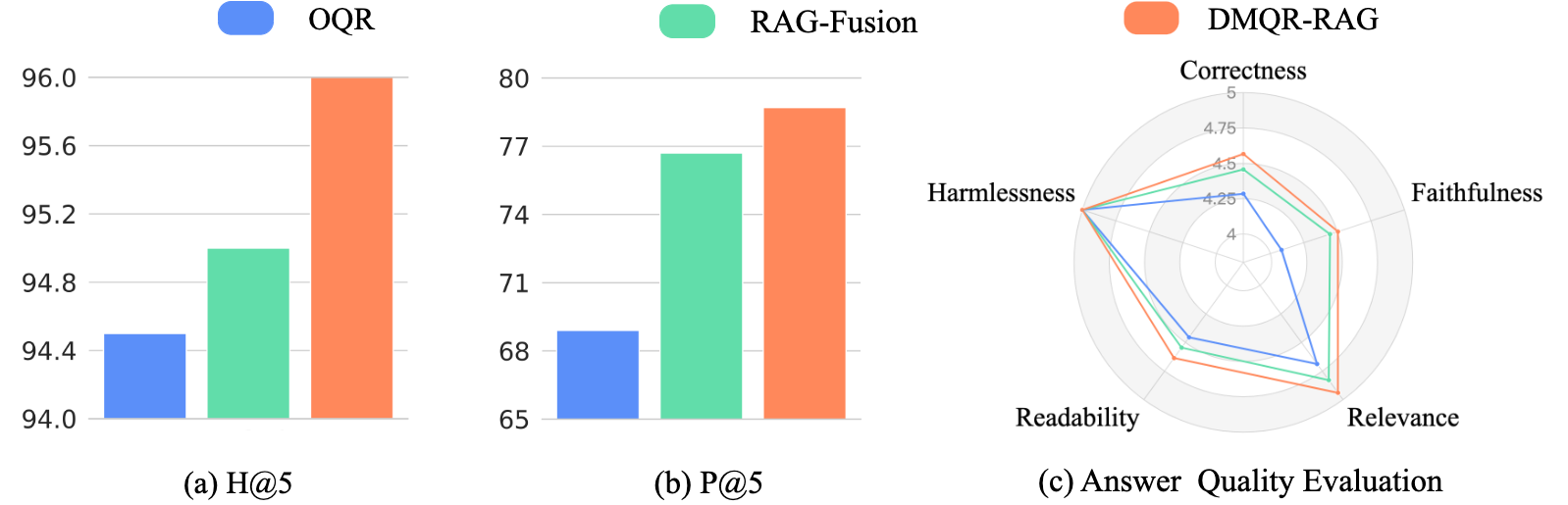
Figure 4: Deployment in industry scenarios shows marked performance improvements in retrieval metrics and responsiveness to user queries.
Conclusion
DMQR-RAG offers a versatile and potent enhancement to RAG systems, addressing the static nature of LLMs and diminishing hallucination risks through diverse query rewriting strategies. Adaptive strategy selection further refines efficiency, tailored to query-specific needs. Future research will focus on expanding the strategy pool and refining adaptive selection methods, ensuring comprehensive applicability and effectiveness across broader contexts.