- The paper introduces a residual passage compression technique that condenses passages into single embeddings while preserving semantic signals via a residual connection.
- It replaces autoregressive ranking with cosine similarity scoring using causal self-attention, significantly reducing inference tokens and latency.
- Joint end-to-end training with a dual-stage SFT regime aligns retrieval contrastive and listwise RankNet losses, achieving state-of-the-art performance on BEIR and TREC DL benchmarks.
ResRank: End-to-End Listwise Reranking via Residual Passage Compression
Motivation and Context
LLM-based listwise reranking achieves superior IR quality but suffers from prohibitive inference overheads, primarily due to (1) the "lost in the middle" effect when feeding long sequences to LLMs, which impairs central passage salience, and (2) latency incurred by autoregressive sequence generation of rankings. Existing mitigation strategies—sliding windows, long-context LLMs, compressed token inputs—remain fundamentally limited either by context-length barriers, coupled alignment complexity, or residual generation costs.
Architecture and Methodological Innovations
ResRank introduces three core architectural and algorithmic solutions for efficient, effective reranking:
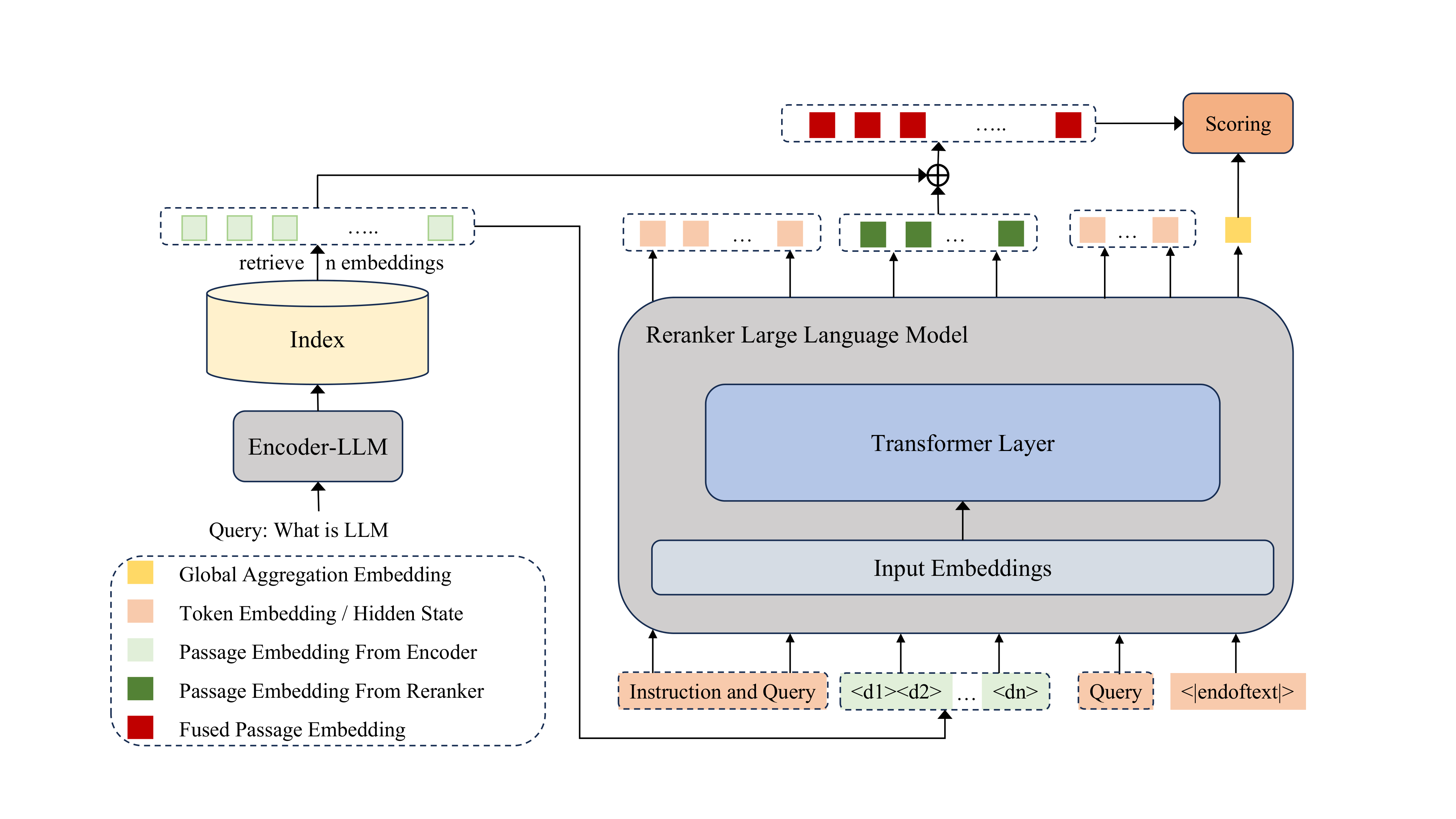
Figure 1: Overview of ResRank—passages are compressed into single embeddings, combined via causal attention, and reranked by cosine similarity, eliminating autoregressive decoding.
Residual Passage Compression
Candidate passages are independently compressed by an Encoder-LLM (Qwen3-Embedding-4B) to produce a single dense vector per passage. This yields a strict reduction in input sequence length—one token per passage—enabling reranker input scalability irrespective of full passage text lengths. Critically, ResRank leverages architectural compatibility between Qwen3-Embedding-4B and Qwen3-4B (the Reranker-LLM), obviating the need for interposing projection modules.
To mitigate the loss of passage-level semantic signals during single-embedding compression, ResRank introduces a residual connection. The reranker’s hidden state for each passage embedding is added to the original encoder embedding to form the passage’s contextual representation: ri=hip+ei. This combination provides gradient shortcuts and maximizes preservation and contextualization of passage semantics.
Listwise Contextualization and Cosine Similarity Scoring
All passage embeddings and the tokenized query are fed to the Reranker-LLM, which applies causal self-attention to produce context-aware passage representations. Instead of autoregressive ranking output, ResRank produces a global aggregation embedding at the EOS ([EOS]) position that encodes the holistic input context. Final relevance scores for each passage are calculated via cosine similarity between this EOS embedding and the corresponding fused passage representations. Thus, the entire generation phase is replaced by a single-step, parallelizable scoring operation.
Dual-Stage, Multi-Task End-to-End Joint Training
ResRank’s Encoder and Reranker LLMs are trained jointly with a two-stage SFT regime:
- Stage 1 (Coarse-Grained): Alignment of compressed representations and reranking behavior using a large, diverse training set.
- Stage 2 (Fine-Grained): Enhanced discrimination among near-relevance candidates using high-quality annotated triplets.
Objective-wise, a retrieval contrastive loss (InfoNCE) preserves encoder retrieval performance, while a listwise RankNet loss aligns reranker training to final ranking quality. The joint loss ensures the learned representations are effective for both retrieval and downstream listwise reranking.
Experimental Analysis
Effectiveness and Efficiency
Across eight BEIR datasets and TREC DL 2019/2020, ResRank sets new efficiency-effectiveness Pareto frontiers among all compressed-token rerankers, outperforming prior compressed embedding approaches such as PE-Rank by up to 5 nDCG@10 points and achieving results competitive with or superior to large, full-text rerankers and zero-shot GPT-4 baselines.
For inference on 100 passages, ResRank processes just 100 tokens (fixed one per passage) and generates zero output tokens, while previous models required up to 104 tokens or 103 output steps. This efficiency is realized without compromising ranking effectiveness.
End-to-End Retrieval-Reranking Alignment
In a unified retrieval-reranking pipeline, the jointly trained encoder not only achieves strong first-stage recall but exhibits synergies with the reranker, leading to best-in-class overall results when dense and sparse retrieval outputs are fused (reciprocal rank fusion with BM25).
Ablation Findings
Removing residual connections, end-to-end joint training, or either SFT stage degrades both BEIR and TREC DL performance, underlining the necessity of each component. Discarding the encoder’s auxiliary retrieval loss leaves reranker quality unchanged but destroys first-stage retrieval capacity—a critical practical liability.
Order Sensitivity
ResRank, like sequence-based causal models, exhibits significant input order sensitivity; inverted candidate lists yield marked drops in performance due to unidirectional attention and position bias. The effect is consistent with other LLM-based rerankers and motivates future architectural research in position-agnostic or bidirectional reranking.
Theoretical and Practical Implications
ResRank’s methodology fundamentally reframes the LLM reranking task as compressed listwise reranking, relegating full-text input to pre-inference and collapsing listwise permutation generation to vector similarity search. This creates new avenues for scaling listwise reranking into industrial settings constrained by latency and context length while simultaneously enabling joint pipelines unifying retrieval and reranking.
The empirical evidence supports the claim that the end-to-end, multi-task, compression-based approach not only eliminates throughput barriers to LLM reranking, but also achieves superior or equivalent relevance ranking compared to heavy-weight, autoregressive, or unconstrained architectures.
Future Directions
Further investigation into position-robust listwise rerankers is imperative. Extensions to multimodal retrieval tasks (e.g., table/image-embedded passages) are immediate, leveraging the architecture's origins in multimodal compression. Finally, alignment via RLHF or direct preference optimization may further align compressed semantics with human preferences, especially for specialized or domain-specific IR scenarios.
Conclusion
ResRank offers an effective, scalable template for LLM-based listwise passage reranking by integrating residual passage compression, similarity-based scoring, and end-to-end joint learning. This paradigm delivers state-of-the-art effectiveness under stringent efficiency constraints and enables practical unified pipelines. The demonstrated alignment of retrieval and reranking signals, combined with robust ablation analysis, establishes ResRank as a foundational model for future research and deployment in high-throughput IR systems.