- The paper demonstrates a two-stage training framework that integrates supervised fine-tuning with reinforcement learning to significantly improve reasoning-intensive passage ranking.
- The paper introduces an automated data synthesis method across complex domains, producing 13K high-quality samples annotated with reasoning chains and gold ranking lists.
- The paper shows ReasonRank’s efficiency and SOTA performance, outperforming baselines with improvements of 5 NDCG@10 points on BRIGHT and 4 points on R2MED benchmarks.
ReasonRank: Advancing Passage Ranking with Explicit Reasoning
Introduction
The ReasonRank framework addresses the challenge of passage reranking in information retrieval (IR) by explicitly incorporating strong reasoning capabilities into LLM-based listwise rerankers. While LLMs have demonstrated notable performance in ranking tasks, their effectiveness in complex, reasoning-intensive scenarios has been limited by the scarcity of high-quality, reasoning-rich training data and the lack of specialized training strategies. ReasonRank introduces a comprehensive solution by synthesizing diverse, high-quality reasoning-intensive data and employing a two-stage training pipeline that combines supervised fine-tuning (SFT) with reinforcement learning (RL) using a novel multi-view ranking reward. The result is a reranker that achieves state-of-the-art (SOTA) performance on challenging IR benchmarks while maintaining superior efficiency.
Automated Reasoning-Intensive Data Synthesis
A central bottleneck in training reasoning-intensive rerankers is the lack of suitable training data. ReasonRank addresses this by proposing an automated data synthesis framework that generates high-quality, diverse training samples across four domains: complex QA, coding, math, and web search. The process leverages DeepSeek-R1, a strong reasoning LLM, to mine positive and hard negative passages and to generate both reasoning chains and gold ranking lists as supervision signals. A self-consistency filtering mechanism, based on NDCG@10 computed from pointwise and listwise labels, ensures the quality of the synthesized data.
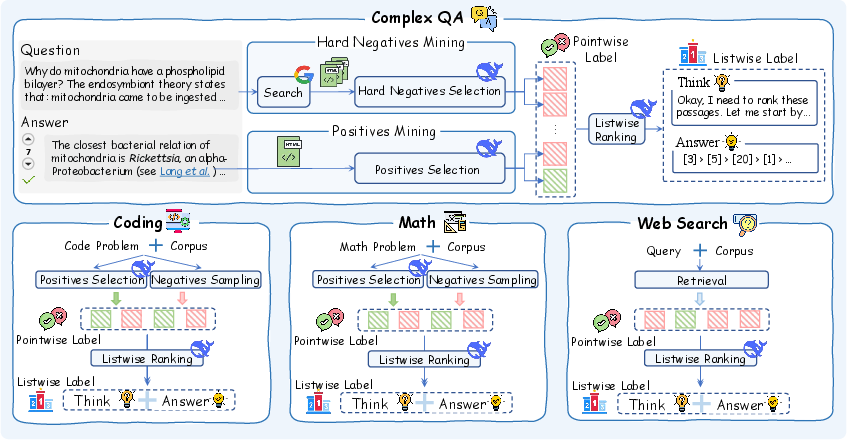
Figure 1: An overview of reasoning-intensive ranking data synthesis on four domains.
This approach yields a dataset of 13K high-quality samples, each annotated with both pointwise and listwise labels, enabling the training of models that can generalize to complex, real-world IR scenarios. The data synthesis pipeline is fully automated, eliminating the need for costly human annotation and ensuring scalability across domains.
Two-Stage Training Framework
To fully exploit the synthesized data, ReasonRank employs a two-stage training strategy:
- Cold-Start Supervised Fine-Tuning (SFT): The backbone LLM is first fine-tuned using the listwise labels, which include both the reasoning chain and the gold ranking list. This stage enables the model to learn explicit reasoning patterns and the structure of high-quality ranking outputs.
- Multi-View Ranking Reward Reinforcement Learning (RL): Building on the SFT model, RL is applied to further enhance ranking ability. Unlike prior work that uses only single-turn NDCG-based rewards, ReasonRank introduces a multi-view ranking reward that combines NDCG@10, Recall@10, and rank-biased overlap (RBO), capturing both single-turn and multi-turn (sliding window) ranking performance. Additional format rewards ensure output consistency.
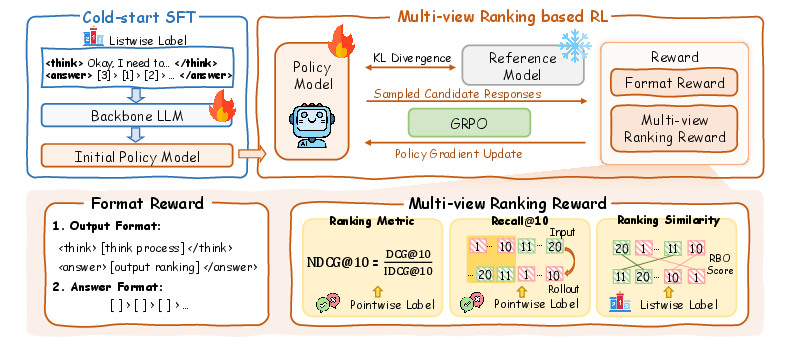
Figure 2: An overview of the two-stage training framework, combining SFT and RL with multi-view ranking rewards.
The RL stage uses the GRPO algorithm, optimizing the model to maximize the multi-view reward while maintaining output structure. This approach is specifically tailored to the sliding window strategy commonly used in listwise ranking with LLMs.
Experimental Results and Analysis
ReasonRank is evaluated on two reasoning-intensive IR benchmarks: BRIGHT and R2MED. The results demonstrate that ReasonRank (7B and 32B) consistently outperforms all baselines, including both non-reasoning and reasoning rerankers. Notably, ReasonRank (32B) surpasses the best prior model by approximately 5 NDCG@10 points on BRIGHT and 4 points on R2MED. Even the 7B model outperforms 32B-scale baselines, highlighting the effectiveness of the data synthesis and training pipeline.
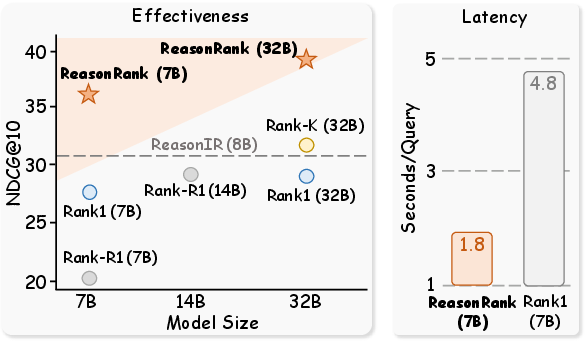
Figure 3: Left: Average NDCG@10 on BRIGHT by reranking ReasonIR-retrieved top-100 passages. Right: Ranking latency comparison between ReasonRank (7B) and Rank1 (7B) on Earth Science dataset.
Ablation studies confirm the necessity of each component: removing reasoning-intensive data, self-consistency filtering, SFT, RL, or the multi-view reward all result in significant performance drops. The model's performance scales with backbone size, and the explicit reasoning component is shown to be critical for high effectiveness.
Efficiency and Practical Considerations
Despite the additional reasoning steps, ReasonRank achieves superior efficiency compared to pointwise rerankers such as Rank1. This is attributed to the listwise approach, which processes multiple passages per reasoning chain, reducing the number of output tokens and overall latency.
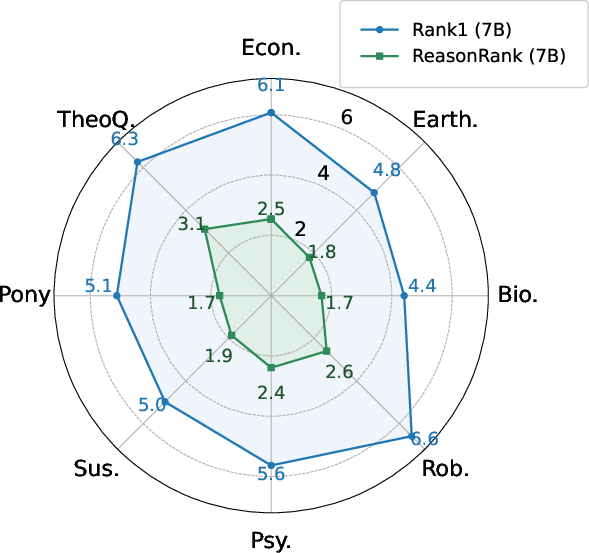
Figure 4: Ranking latency (seconds per query) of Rank1 (7B) and ReasonRank (7B) across eight datasets.
The model is implemented using Qwen2.5-7B/32B-Instruct backbones, with LoRA adapters for efficient fine-tuning. Training leverages DeepSpeed and FlashAttention2 for scalability. The framework is compatible with standard LLM serving infrastructures (e.g., vLLM), facilitating deployment in production IR systems.
Reasoning Behavior and Case Studies
Analysis of the reasoning length across datasets reveals that tasks involving coding and mathematical theorems require longer reasoning chains, reflecting their higher complexity.
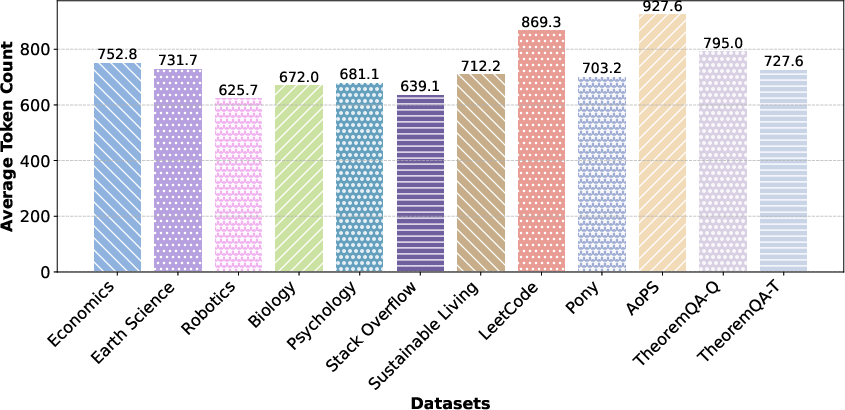
Figure 5: The reasoning length of ReasonRank (7B) on BRIGHT.
Case studies demonstrate that ReasonRank produces structured, step-by-step reasoning traces that align with human expectations for complex queries, supporting interpretability and trustworthiness in high-stakes applications.
Implications and Future Directions
ReasonRank establishes a new standard for reasoning-intensive passage reranking, demonstrating that explicit reasoning, when combined with high-quality synthetic data and tailored RL objectives, yields substantial gains in both effectiveness and efficiency. The approach is generalizable across domains and can be extended to other LLM backbones and full-list ranking strategies as context lengths increase.
Future work may focus on integrating non-reasoning data for adaptive reasoning modes, exploring alternative backbone models (e.g., Llama 3.1, Qwen3), and transitioning from sliding window to full-list ranking as LLM context windows expand. Additionally, further research into reward design and data synthesis for other complex IR tasks is warranted.
Conclusion
ReasonRank demonstrates that explicit reasoning, supported by automated data synthesis and a two-stage training pipeline, can significantly advance the state of passage reranking in information retrieval. The framework achieves SOTA performance on challenging benchmarks, offers superior efficiency, and provides interpretable outputs, marking a substantial step forward in the development of reasoning-aware IR systems.

