- The paper demonstrates that autoregressive ranking overcomes dual encoders' expressivity limits by generating document IDs token-by-token.
- It introduces the SToICaL loss to embed rank-aware supervision at both item and token levels, significantly improving nDCG and recall metrics.
- Empirical results on WordNet and ESCI show ARR matching cross encoder performance while offering enhanced computational efficiency.
Introduction and Motivation
Information retrieval (IR) tasks rely critically on ranking algorithms that score and order candidate documents with respect to a query. Historically, two-stage retrieval pipelines have dominated this field. These pipelines implement a first-stage retrieval with Dual Encoders (DEs) for efficient, large-scale approximate nearest neighbor (ANN) matching, followed by reranking with computationally intensive Cross Encoders (CEs) to capture fine-grained interactions at the cost of scalability. Recent progress in the capabilities of LLMs has reignited interest in unifying retrieval and ranking within a single, generative paradigm—specifically, autoregressive ranking (ARR), in which the model generates document identifiers (docIDs) token-by-token, facilitating ranking via decoding strategies such as beam search.
This paper presents substantive contributions along two axes: (1) a formal analysis of ARR's representational capacity, demonstrating its strictly superior expressivity compared to DEs, and (2) the introduction of SToICaL (Simple Token-Item Calibrated Loss), a rank-aware training loss that enables the ARR framework to exploit ranking supervision more effectively at both item and token levels (2601.05588).
Architectural Overview: Dual Encoder, Cross Encoder, and Autoregressive Ranking
Three major architectural approaches are compared: DE, CE, and ARR. While DEs pairwise compute embeddings for queries and documents followed by similarity evaluation (typically inner product or cosine), CEs exploit cross-attention over the query-document pair, incurring a computational penalty but offering superior expressiveness. ARR instead treats ranking as a generative process, autoregressively producing document ids as sequences of tokens, using the conditional probability outputs of causal LLMs. The architectural distinctions are visually depicted as follows:
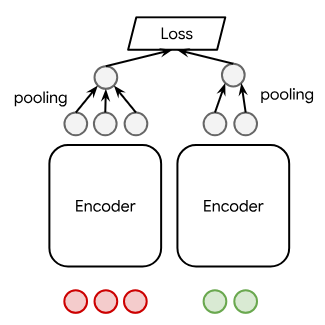
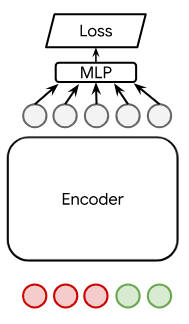
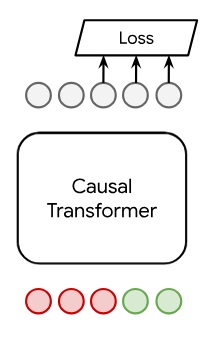
Figure 1: An overview of DE, CE, and Autoregressive Ranking architectures, capturing the efficiency-expressivity trade-offs and the unified potential of ARR.
Theoretical Analysis: Expressivity of DEs vs. ARR
The core analysis formalizes the limitations of DEs in ranking tasks. The key result is that for a DE to perfectly rank all permutations of k documents, its embedding dimension n must scale linearly with k: n<2lnklnk!. This sharply contrasts with ARR, where the capacity to score and distinguish between arbitrary document orderings is theoretically unbounded by embedding dimension, provided the token embedding matrix E meets the so-called "softmax bottleneck" condition (rank(E)=∣V∣, where V is the set of docID tokens).
This analysis reveals that while DEs are efficient, their representational bottleneck renders them fundamentally limited for general ranking tasks in large-scale corpora. ARR, leveraging the sequential modeling capability of causal LLMs, does not suffer from this dimensionality restriction, enabling it to subsume the representational power of both DEs and CEs for ranking.
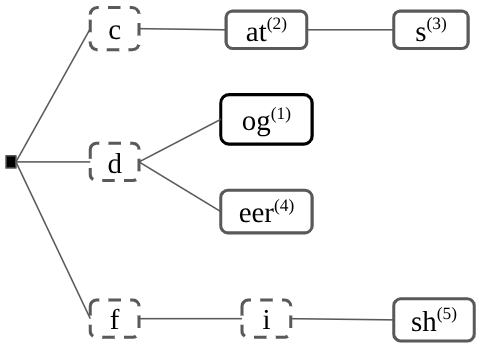
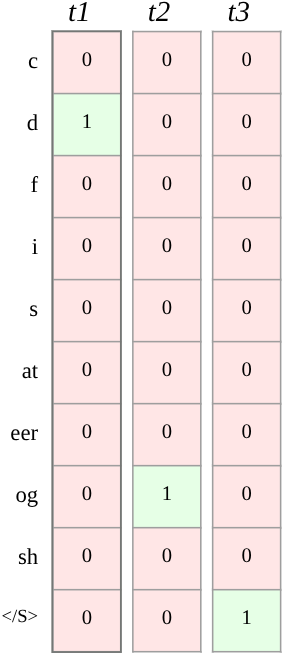
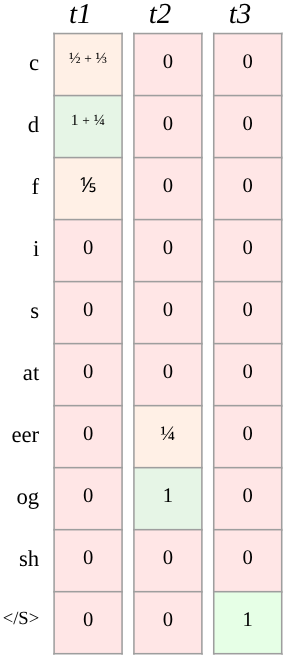
Figure 2: A prefix tree (trie) structure is used in ARR for distributing and marginalizing rank-aware probability mass across valid docID continuations, enabling efficient and flexible supervision.
SToICaL: Rank-aware Loss for Pointwise Generative Ranking
Conventional ARR deployments—such as instruction tuning or next-token prediction—use a pointwise loss that is inherently "rank-agnostic": each docID is scored independently, neglecting their relative ordering. To address this, SToICaL generalizes the next-token prediction loss to incorporate rank-awareness via two mechanisms:
- Item-level reweighting: The per-sample loss is weighted by a rank-dependent function λ(r) (e.g., rα1), upweighting higher-ranked (more relevant) items.
- Token-level prefix-tree marginalization: Using a trie over the ranked docIDs, the target distribution at each generation step distributes probability mass among all valid continuations, weighted according to their positions in the ranking.
This facilitates explicit modeling of the ranked list during training (without requiring the LLM to generate the entire list in output), aligning the learning objective with the end-goal of ranking via autoregressive decoding.
Experimental Analysis
Empirical validation spans two datasets: WordNet (taxonomic hypernyms) and ESCI (shopping queries with product titles). The generation models are based on Mistral-7B-v0.3-it, using in-context ranking where candidate docID sets are explicitly given at prompt time. Evaluation metrics include constraint violation rate (CVR), nDCG, and recall-at-K (R@K).
The item-level reweighting with λ(r)=rα1 (for suitable α) yields strong rank-aware improvements, drastically suppressing probability assigned to negative or invalid docIDs (CVR down to 0.0%), and improving nDCG and R@K across the board, especially at higher K. Trie-based marginalization provides further efficiency in capturing rank-related supervision at individual token steps, particularly beneficial in data-rich, long-list settings such as ESCI.
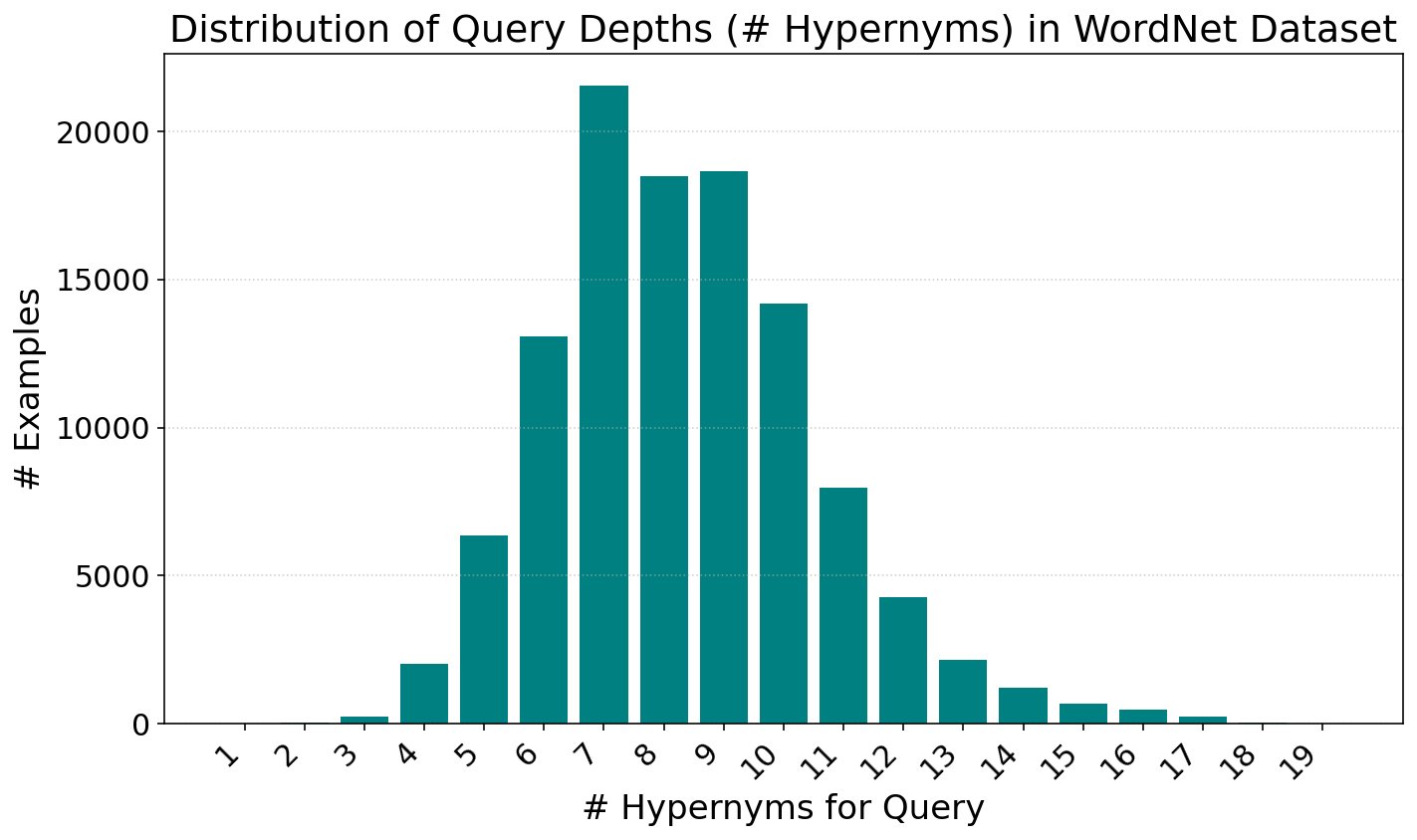
Figure 3: Distribution of the number of hypernyms per query in the WordNet dataset, illustrating ranking depth for empirical evaluation.
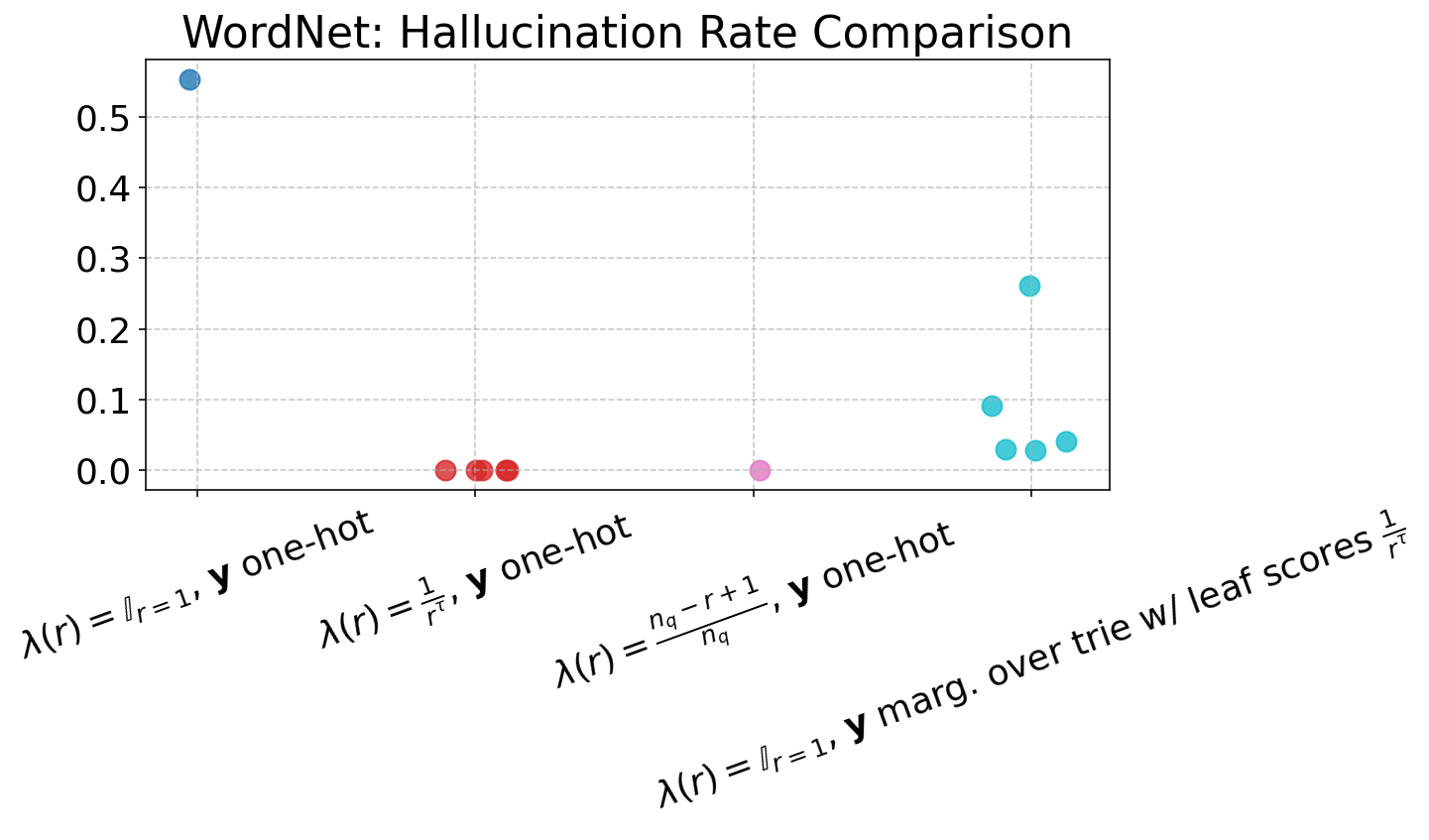
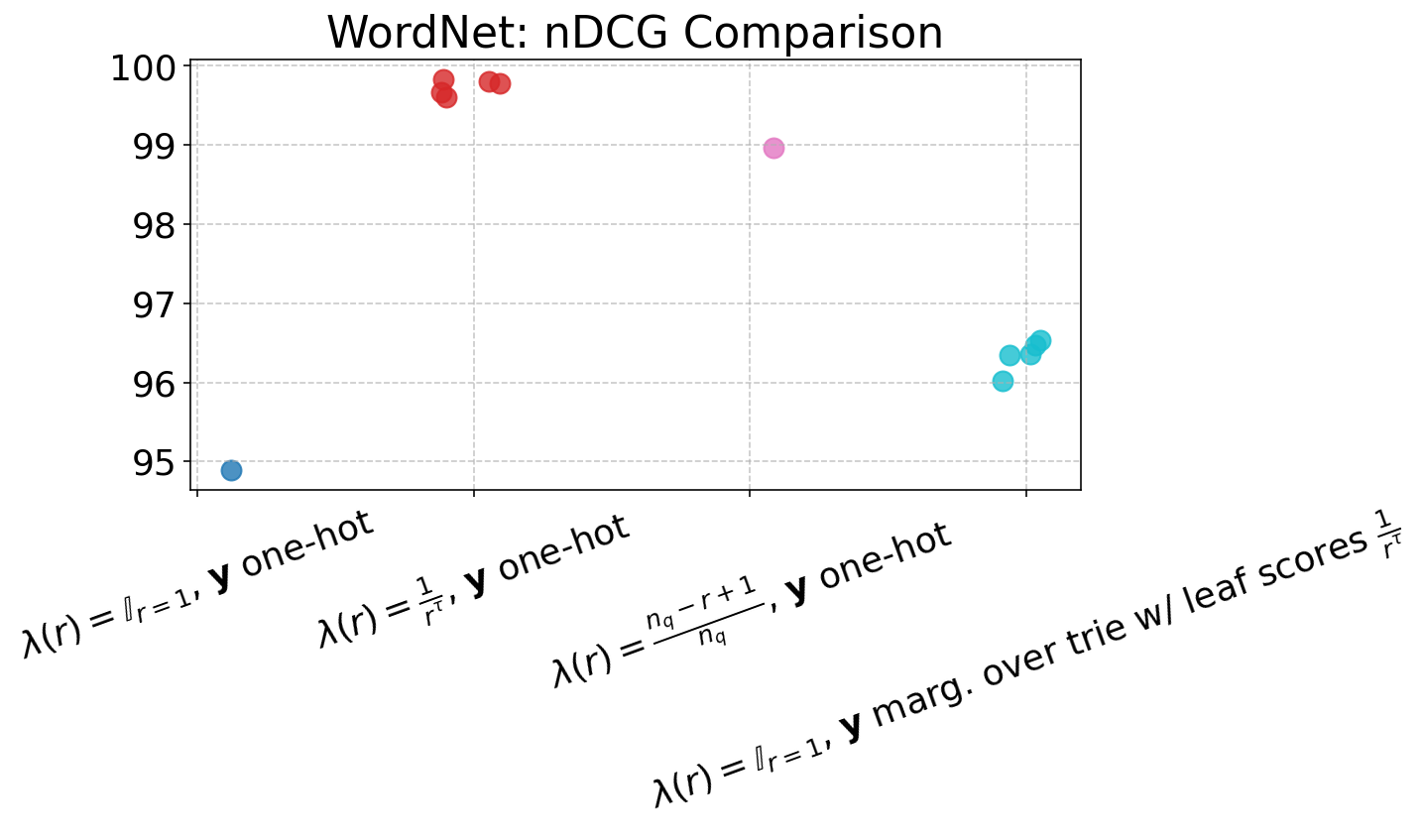
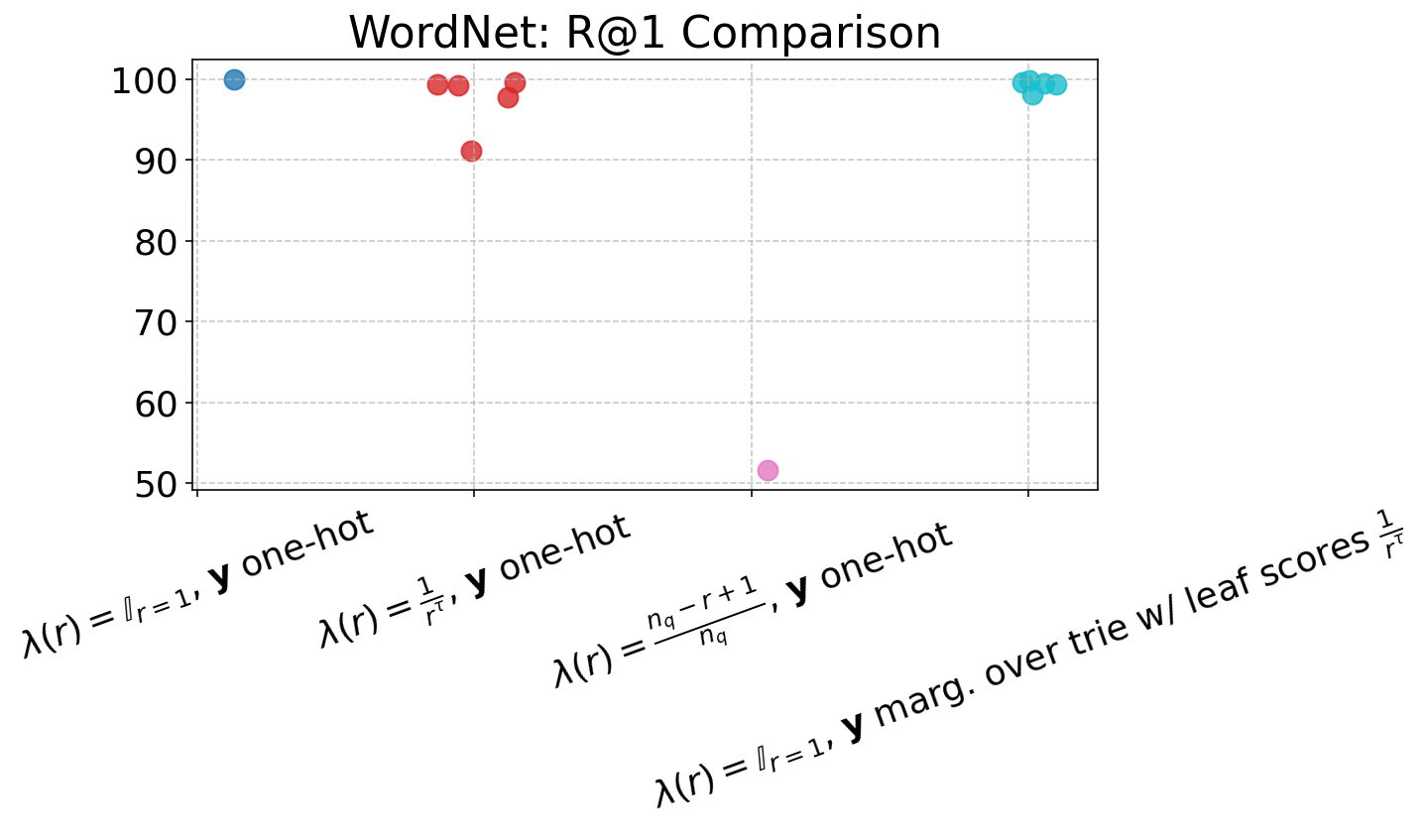
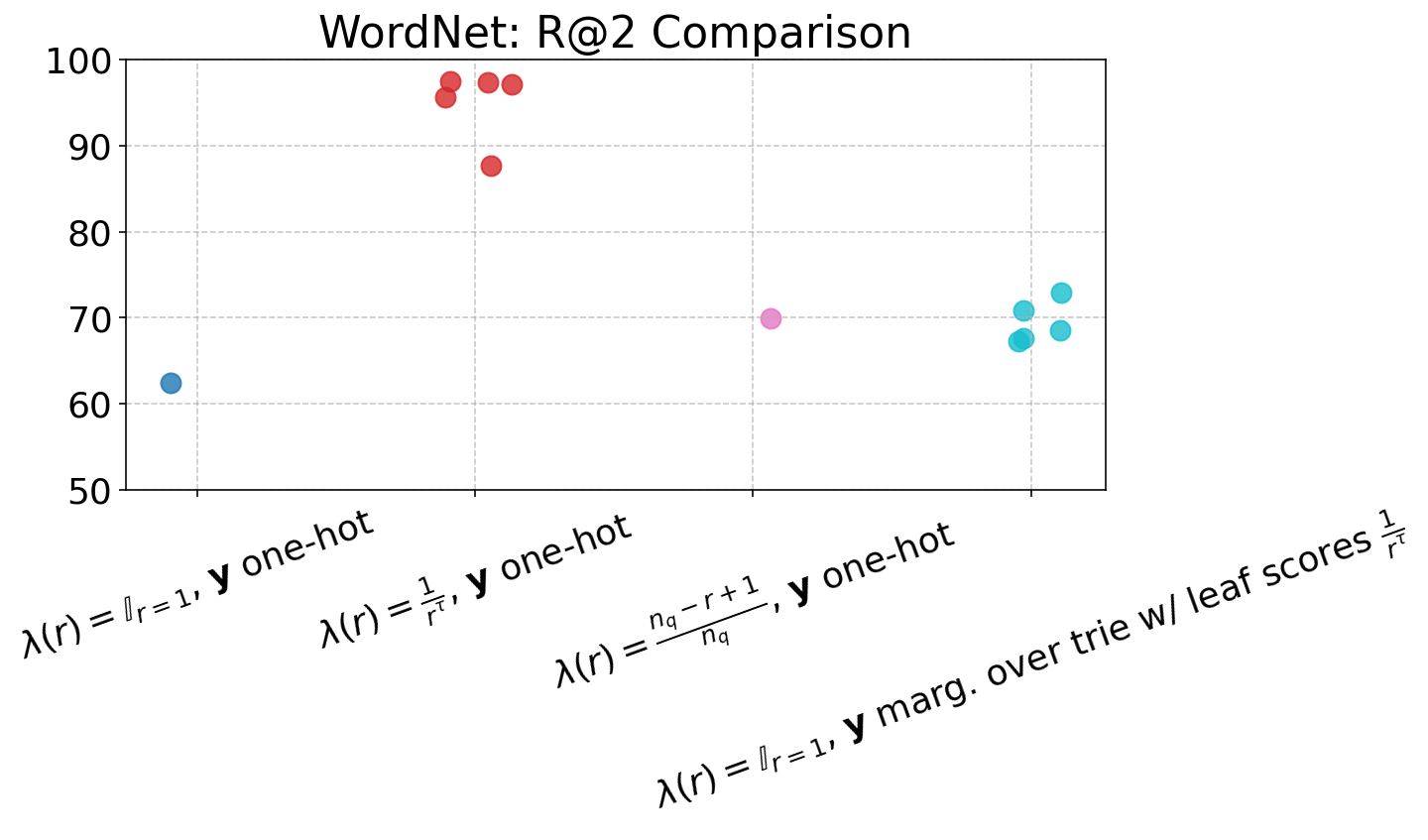
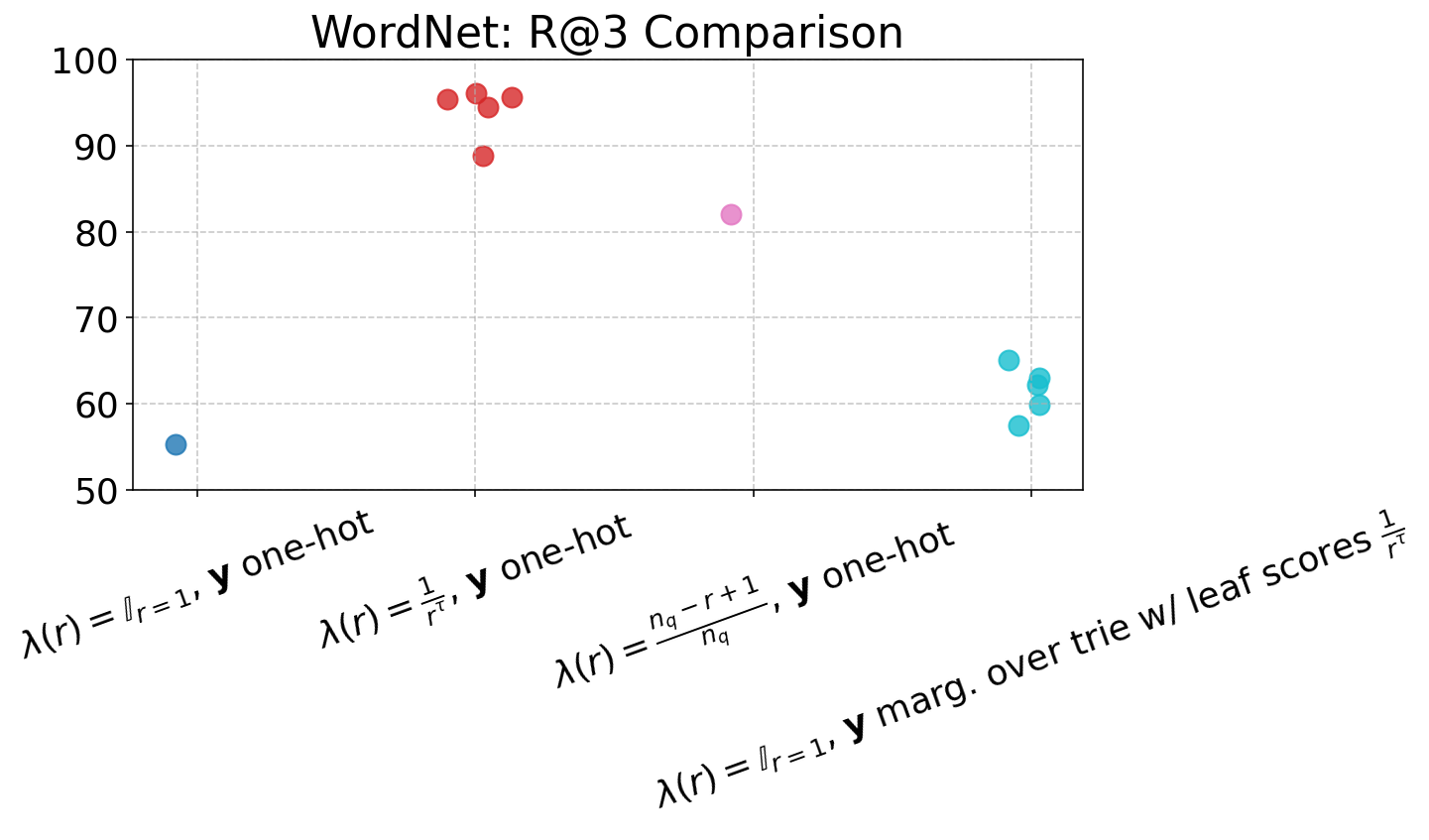
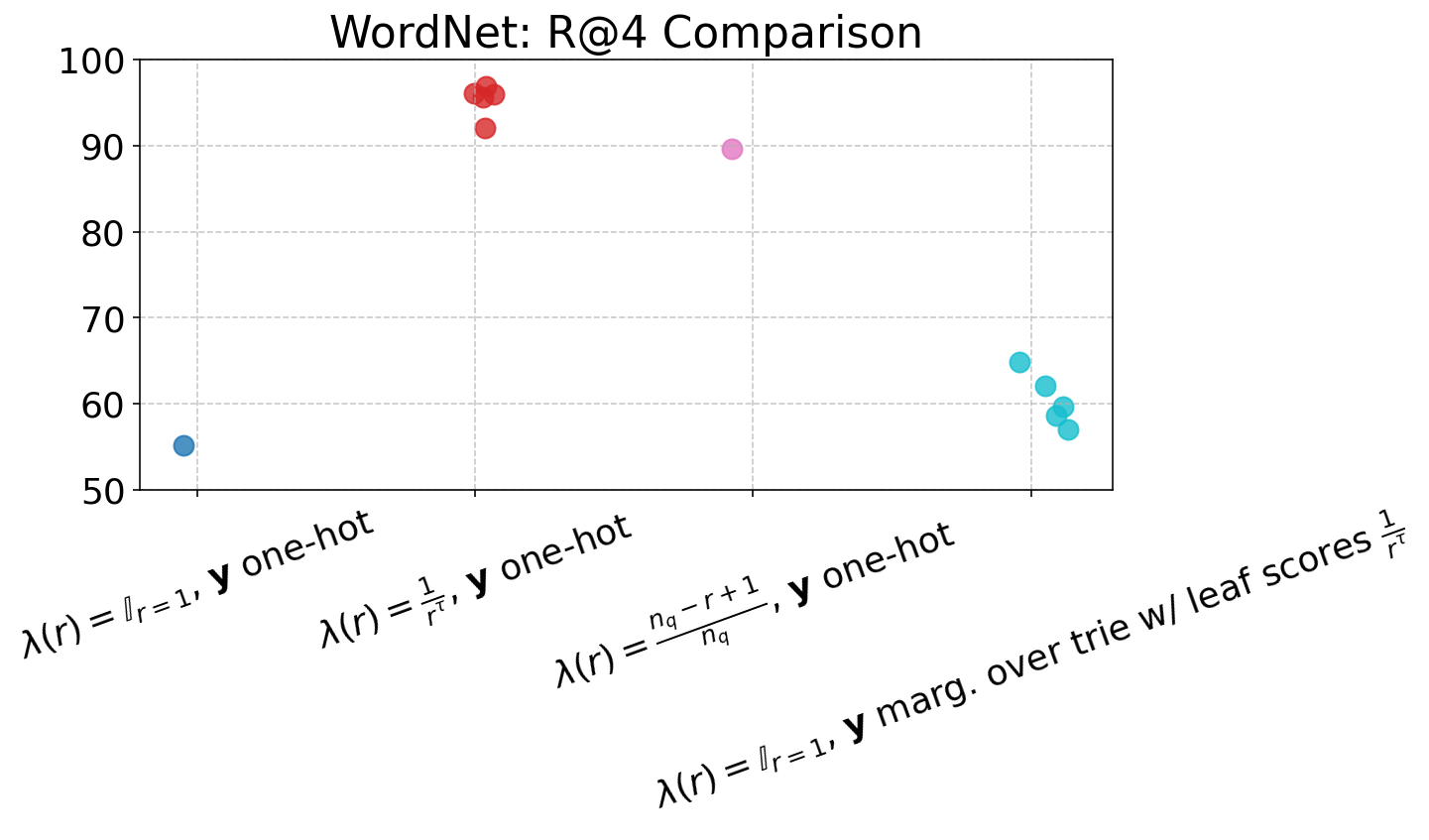
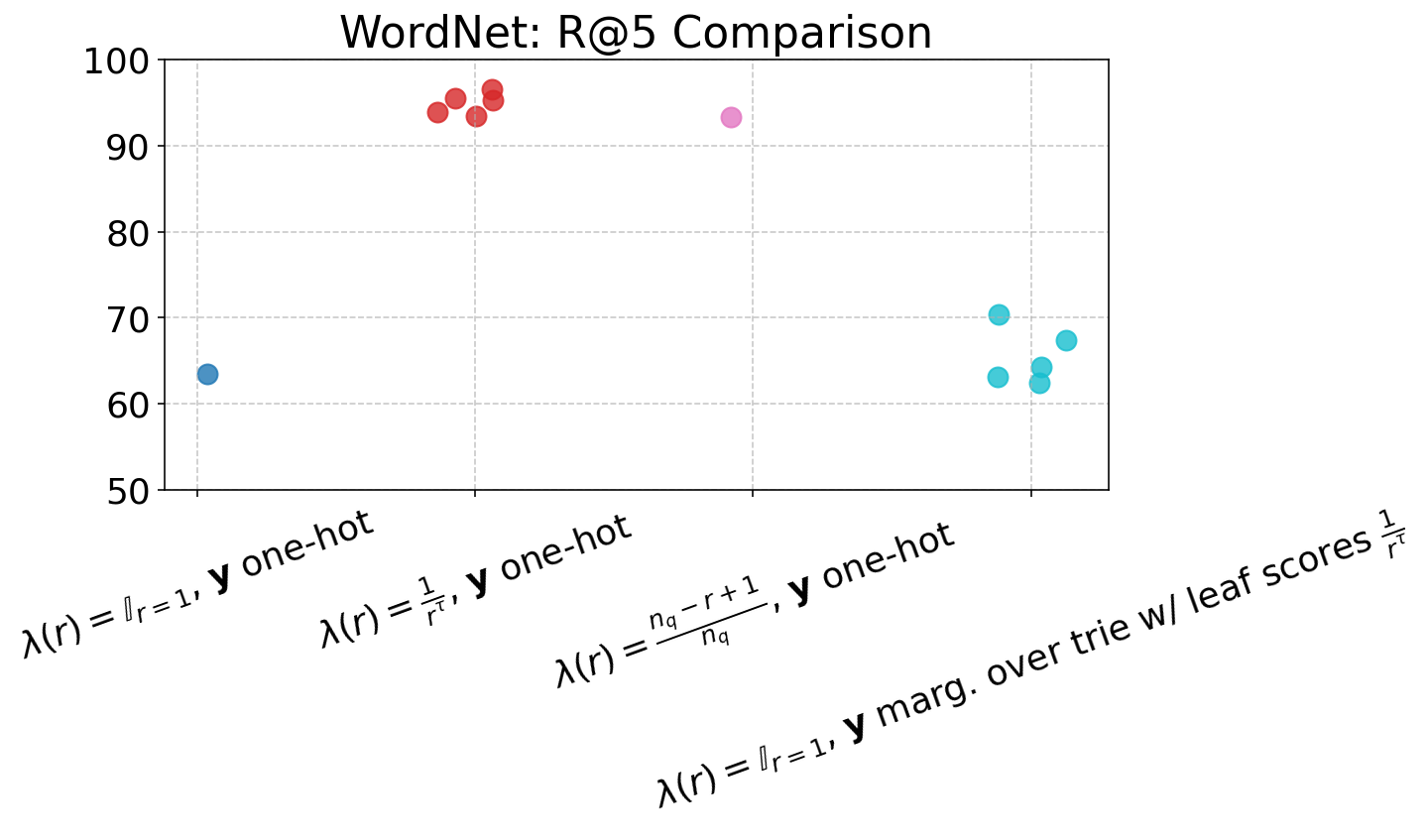
Figure 4: Performance of ARR models across varying loss settings, visualized in terms of nDCG and R@1 to R@5 metrics, demonstrating gains from rank-aware supervision.
Direct comparison with DE and CE baselines on the WordNet reranking task shows that ARR models fine-tuned with SToICaL exhibit performance on par with CEs and substantially outperform DEs, even when DE embedding dimension is increased. ARR achieves this while maintaining computational efficiencies through in-context and beam search generation, obviating the need for expensive large-scale ANN indices.
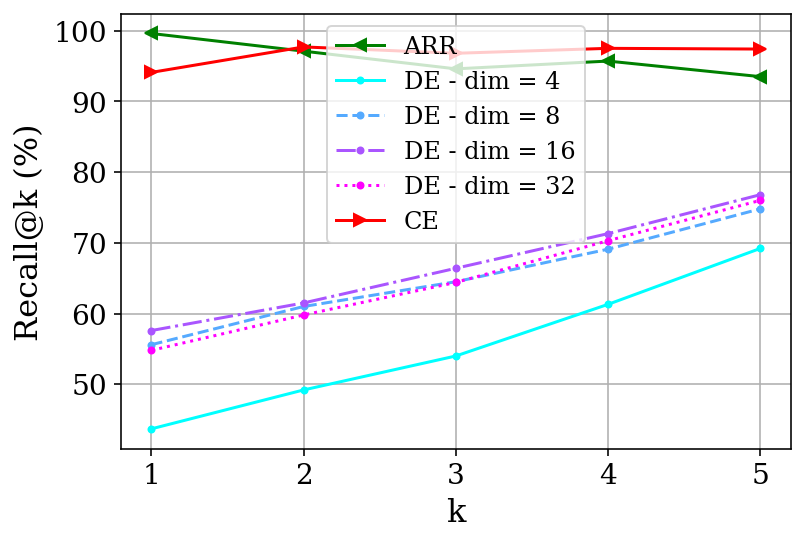
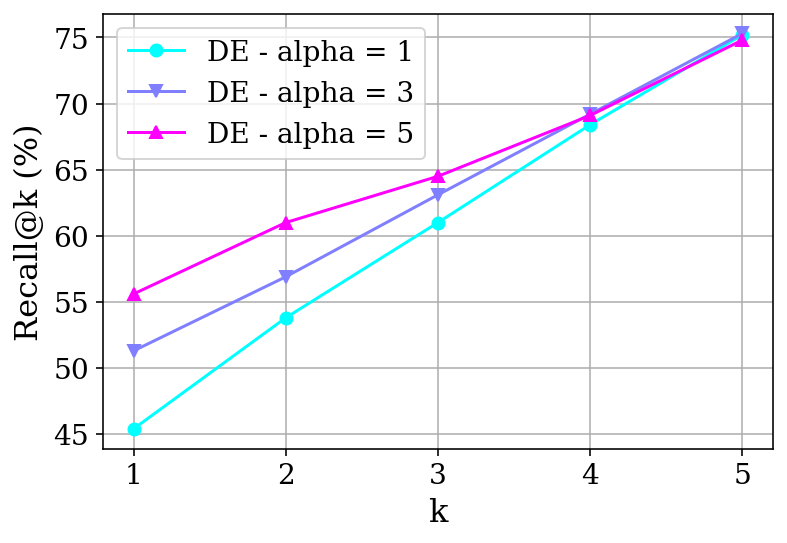
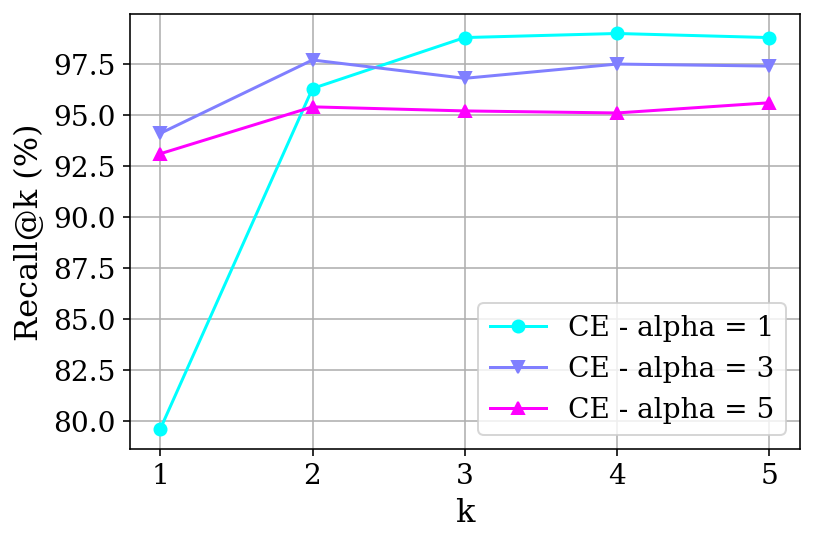
Figure 5: Comparative analysis of DE, CE, and ARR architectures, highlighting ARR's expressivity advantage while matching CE performance.
Practical and Theoretical Implications
The established theoretical bounds conclusively demonstrate that ARR subsumes the ranking capacity of DE and CE architectures, with practical benefits in model unification and simplification of IR system pipelines. The introduction of SToICaL rectifies a critical deficiency in LLM-based generative ranking by efficiently encoding ranking order information into the loss landscape at both the item and token levels, which is vital for accurate and reliable IR performance under beam search.
These findings suggest several future research directions:
- Optimal design and learning of docID tokenizations to further synergize with trie-based, rank-aware targets.
- Efficient scalable implementations of beam or constrained decoding in LLMs for large-scale IR.
- Incorporation of ranking-aware generation into general-purpose LLM architectures to enable direct replacement of two-stage retrieval pipelines without retraining for downstream tasks.
Conclusion
This work demonstrates, both formally and empirically, that autoregressive ranking with causal LLMs closes the expressivity gap between dual and cross encoders, and that principled training via the SToICaL loss enables LLMs to exploit rank-awareness effectively, yielding strong IR performance. The practical and theoretical results motivate a shift toward unified, LLM-driven, end-to-end ranking systems, with architectural and algorithmic innovations that further improve scalability and ranking performance in IR and related domains.

