- The paper presents GICC, a GPU-driven runtime that eliminates host intervention to enable device-side synchronization and communication in distributed HPC systems.
- It leverages pre-staged NIC work for OFI fabrics and direct RDMA on InfiniBand, achieving up to 229× lower coordination latency compared to host-driven approaches.
- GICC demonstrates practical benefits with reduced communication time in stencil computations and improved weak-scaling efficiency over traditional MPI implementations.
Introduction and Motivation
The transition toward exascale high-performance computing (HPC) has rendered distributed heterogeneous GPU clusters the dominant architecture for many domains. While hardware advances have delivered immense computational throughput, distributed GPU applications have struggled to efficiently exploit cross-node coordination due to persistent architectural and runtime constraints. Notably, GPU-initiated coordination remains underdeveloped, especially on OFI-based interconnects like HPE Slingshot, which serve as the backbone for the leading Top500 systems. Existing communication paradigms, including MPI and SHMEM derivatives, impose excessive latency and synchronize kernels at host intervention points, impeding fine-grained compute–communication overlap.
GICC (GPU-Initiated Communication and Coordination) directly addresses these deficiencies by introducing a GPU-driven, resource-resilient runtime that enables device-side distributed synchronization and communication, decoupled from host control. GICC is explicitly engineered for both InfiniBand and OFI-based fabrics, with special treatment of Slingshot/CXI NICs, whose resource limitations and provider semantics had previously precluded sustained GPU-driven coordination.
Structural Analysis of Host-Driven Coordination
Existing approaches are rooted in host-initiated orchestrations. The typical workflow involves kernels handing off at boundaries to host CPUs, which then invoke collectives and enforce progress. Such models, when applied to workloads with high coordination frequency or numerous kernel phases (e.g., iterative solvers, stencil computations), incur prohibitive overhead, with empirical results showing up to 32% of the execution time spent in coordination for a 200-phase workload.
The triggering path for communication can be categorized as follows:
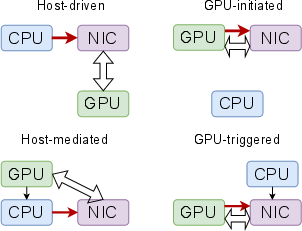
Figure 1: Four common communication modes between GPU and NIC, illustrating host-driven, host-mediated, GPU-initiated, and GPU-triggered workflows.
Host-driven and host-mediated modes, which typify NVSHMEM and MPI implementations on Slingshot, are inherently incapable of device-side coordination autonomy. In contrast, InfiniBand enables direct GPU-initiated communication. However, even on InfiniBand, inefficiencies due to locking and API design remain non-trivial constraints.
Quantitative microbenchmarks confirm that as the number of phase boundaries N increases, the fraction of host-driven coordination time dominates total runtime:
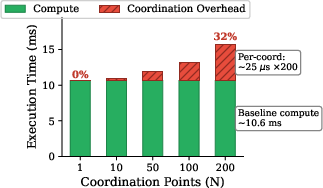
Figure 2: Execution time breakdown evidencing coordination overhead scalability as a function of increasing phase count N.
The GICC Runtime: Design Principles and Execution Model
GICC is built around three tenets: (1) permitting device-side coordination initiation within GPU kernels, (2) minimizing both latency and CPU involvement on the critical path, and (3) bounding NIC-resident state usage to ensure liveness and progress under finite resources.
On InfiniBand, GICC leverages device-accessible doorbells/UARs, fully eliminating host mediation for RDMA and synchronization. On OFI/CXI, the host pre-stages all necessary NIC work, which the GPU then triggers via thresholded counter updates. Explicit host threads asynchronously recycle and re-arm NIC state to sidestep resource exhaustion while keeping the coordination path device-resident.
The execution model on Slingshot can be summarized as:
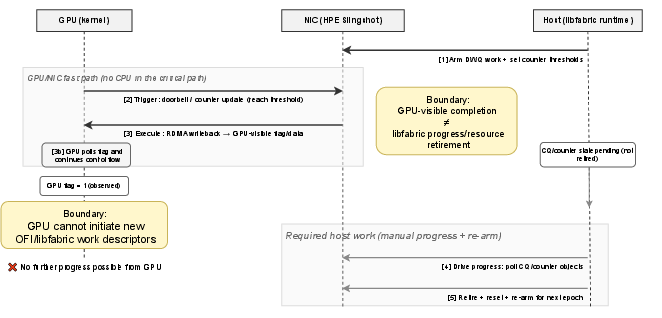
Figure 3: Boundary conditions for GPU-driven coordination on Slingshot (CXI) under libfabric manual progress, capturing pre-staging, triggering, GPU-visible completion, and host-mediated progress.
GICC’s API exposes device-side synchronization, active messages, and put/get semantics, with kernel-level coordination points decoupled from host round-trips. RDMA operations and collectives, including barriers, are realized as finite sequences of host-armed, device-triggerable work, managed through a double-buffered, epoch-based slotting mechanism. This avoids blocking flushes and maintains low pre-staged work footprints regardless of usage frequency or scale.
GICC outperforms both host-driven MPI and hybrid runtimes across all evaluated dimensions. Microbenchmarks on Tioga (Slingshot + AMD MI250X) and Maple (InfiniBand HDR + NVIDIA GH200) substantiate the substantial reduction in overhead achieved by direct GPU-driven coordination.
For high-coordination-frequency workloads, GICC exhibits up to 229× lower per-coordination latency (0.11μs vs 25.2μs), maintaining flat execution times as N increases.
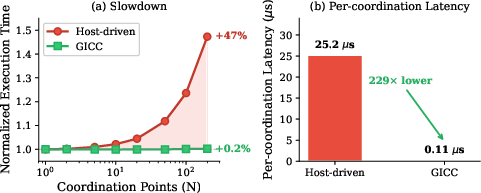
Figure 4: End-to-end slowdown and per-coordination latency as N increases, comparing GICC to host-driven baselines.
Point-to-point put latency on both InfiniBand and Slingshot confirms GICC's streamlined device path. For small messages, GICC reduces put latency by up to 1.95× compared to NVSHMEM, primarily due to the elimination of proxy threads, locking, and redundant synchronization.
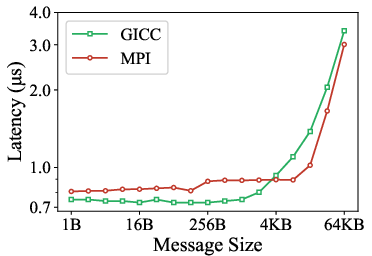
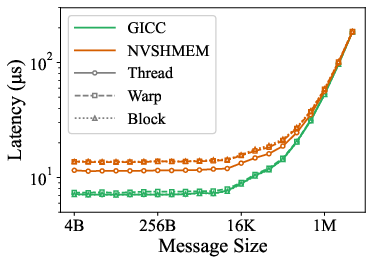
Figure 5: (Left) P2P put latency on Tioga (Slingshot + AMD MI250X). (Right) P2P put latency across different scopes on Maple (InfiniBand HDR + GH200).
Application-Level Benchmarks
GICC’s impact extends to concrete applications:
- Weak scaling on 2D Jacobi: Sustains >93% efficiency intra-node and outperforms MPI by 25% on 64 GPUs, directly attributable to efficient GPU-driven halo exchange and reduced host mediation.
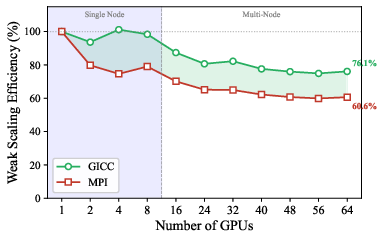
Figure 6: Weak-scaling efficiency of a 2D Jacobi stencil on Tioga, highlighting GICC's superior scaling.
- Distributed Matrix Multiplication (Cannon): GICC yields up to 6.4% speedup on small matrices; for larger sizes, GICC and MPI converge, reflecting reduced relative overhead when fewer fine-grained coordination points exist.
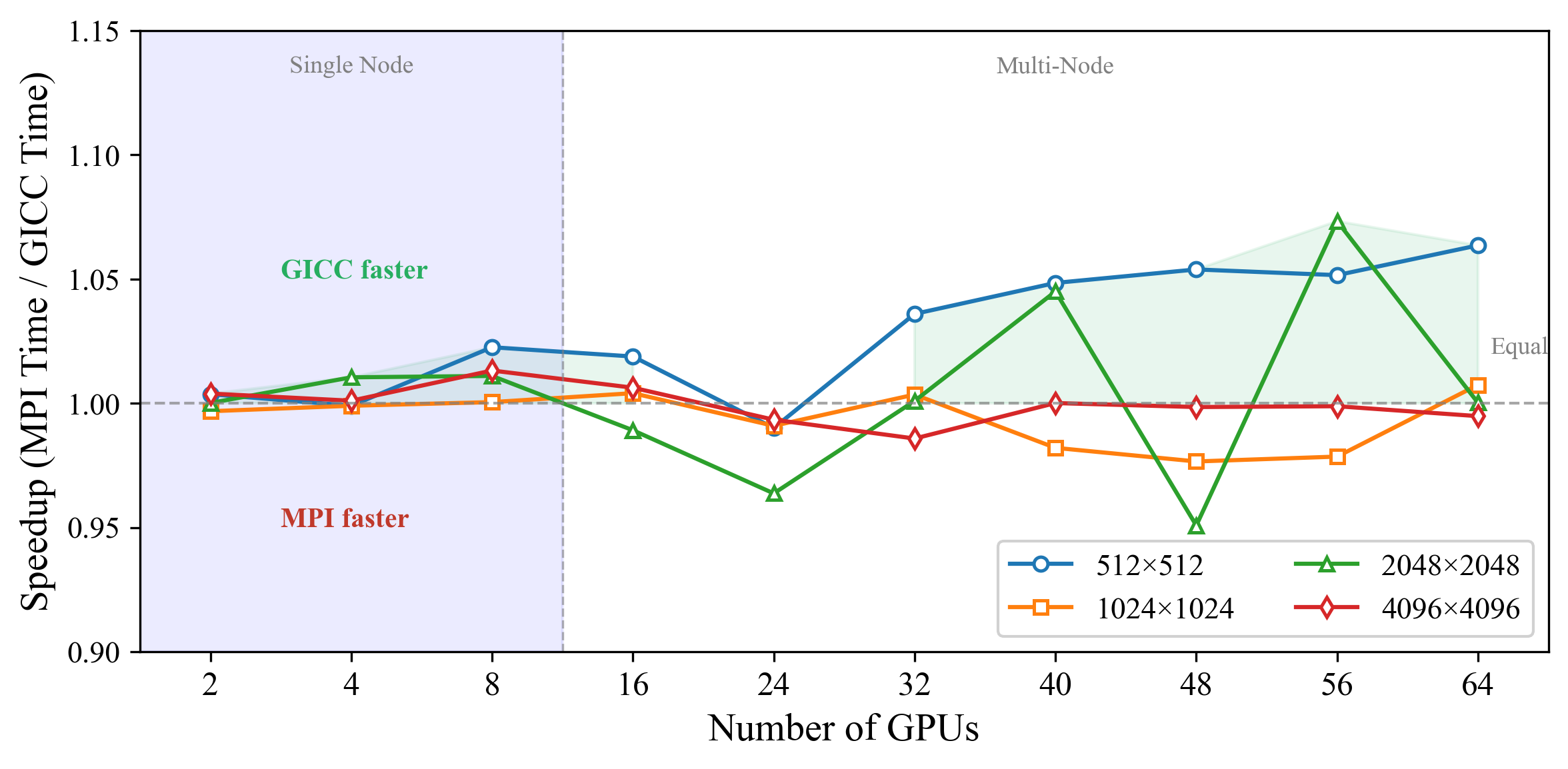
Figure 7: GICC speedup over MPI for distributed matrix multiplication, evidencing the major gains for phase-intensive workloads.
- Minimod (industrial stencil proxy): At 64 GPUs, GICC outperforms MPI with 52% lower communication time and achieves 42% parallel efficiency versus MPI’s 35.4%. This is a direct result of coordinating complex, multi-kernel phases from the GPU side while hiding host-NIC synchronization latency.
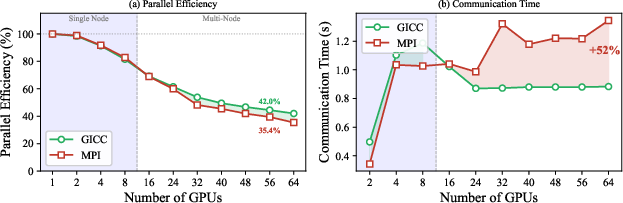
Figure 8: Parallel efficiency and communication time for Minimod on Tioga, contrasting GICC and MPI across the scaling range.
Implications, Limitations, and Future Directions
GICC resolves a critical gap in device-driven control for distributed GPU applications, particularly under resource-constrained OFI/CXI fabrics. The clear separation of coordination from communication, and the enforcement of bounded pre-staged work with resource-aware reclamation, enables sustainable GPU-native control at scale. This brings practical benefits to multi-phase, communication-heavy scientific codes, supporting tighter compute–communication overlap and unlocking new algorithmic strategies.
However, the fundamental limitation remains: on OFI/CXI, GPUs cannot dynamically enqueue new NIC operations. GICC’s resource model, while robust, is best suited for semi-regular (predictable) coordination patterns where the action space can be staged ahead. Fully dynamic or unpredictable communication graphs may suffer back-pressure or require defensive host fallback. Additionally, the difference in resource semantics across InfiniBand and OFI introduces subtle, non-portable aspects concerning progress guarantees and resource consumption.
Theoretically, these advances imply that further hardware–runtime co-design is necessary to fully bridge the gap between device-centric programming and tightly constrained NIC state. Practically, many high-value scientific workloads stand to benefit immediately from GICC, particularly those with iterative, fine-grained synchronization boundaries.
Future work should extend GICC to commercial cloud fabrics (e.g., AWS EFA), generalize the resource-pipelining model, and integrate with compiler toolchains to enable architectural abstraction without sacrificing backend-specific performance.
Conclusion
GICC establishes a new paradigm for sustaining fine-grained, GPU-initiated coordination and communication in modern distributed HPC clusters. By explicitly addressing both interconnect-specific and generic resource management issues, decoupling coordination semantics from data movement, and providing practical, high-performance implementations on both AMD and NVIDIA hardware, GICC enables device-resident distributed control that was previously unattainable on the majority of large-scale systems. The framework demonstrates large reductions in latency, improved scaling, and direct application-level benefits, especially for communication-intensive, phase-heavy computations, setting a clear trajectory for future design in distributed accelerator runtimes.

