- The paper presents a detailed investigation of inter-APU communication strategies on AMD MI300A systems, leveraging Infinity Fabric to maximize GPU performance.
- The paper evaluates various programming models and memory allocation techniques using micro-benchmarks and case studies to measure latency and bandwidth improvements.
- The paper identifies key optimizations, demonstrating that hardware utilization and specific programming choices can significantly enhance data movement in high-performance computing.
Inter-APU Communication on AMD MI300A Systems via Infinity Fabric: a Deep Dive
The focus of this paper is the exploration and evaluation of data movement strategies in high-performance computing (HPC) nodes using AMD MI300A systems, which integrate CPUs and GPUs within a single package. Four of these APUs are interconnected in a compute node using Infinity Fabric, an interconnect technology that facilitates efficient data communication necessary to harness the full computing power of modern GPUs.
Architecture of AMD MI300A Systems
The AMD MI300A system integrates CPU and GPU components, facilitating unified memory access which contrasts with NVIDIA's NVLink approach maintaining separate memory spaces. Each MI300A APU incorporates 24 CPU cores and 228 GPU compute units, interconnected through Infinity Fabric (Figure 1).
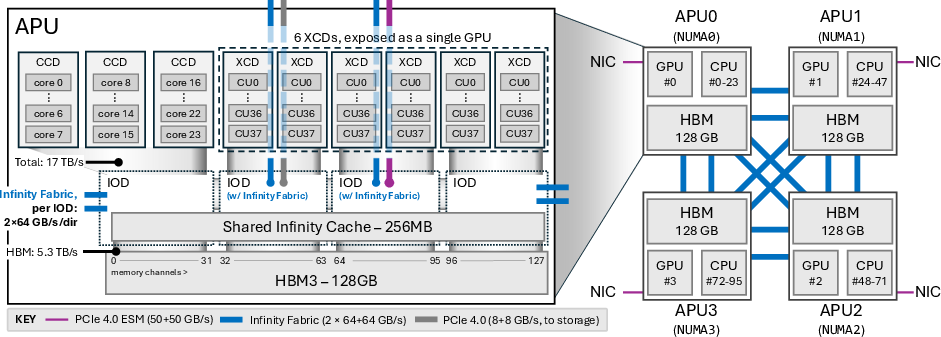
Figure 1: Node Architecture (right) with four MI300A APUs, and detailed APU architecture (left). The Infinity Fabric (in blue) interconnects the four APUs. From the user perspective, each APU is a NUMA node in this cache-coherent NUMA system.
The Infinity Fabric interconnects the APUs, providing a bandwidth of 128 GB/s per direction, essential for designing efficient communication strategies (Figure 2).
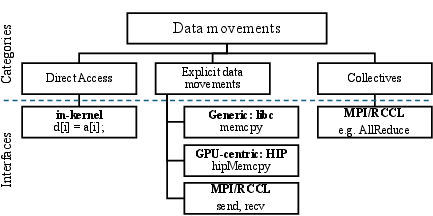
Figure 2: A taxonomy of communication on multi-APU systems, associated data movement categories and programming interfaces and libraries.
Communication Taxonomy
The research defines a taxonomy of communication mechanisms on the MI300A platform:
- Direct Memory Access (DMA): Facilitates in-kernel memory access from GPU compute units across APUs, ensuring cache coherence and high bandwidth data transfer.
- Explicit Data Movement: Utilizes APIs like HIP and standard libraries to move data between memory spaces of different APUs, often leveraging SDMA engines for parallelization and efficiency.
- Point-to-Point and Collective Communications: Managed via MPI for distributed processing, leveraging specialized libraries such as RCCL for enhanced GPU-GPU interconnect efficiency.
Evaluation Methodology
The research employs micro-benchmarks and real-world application tests to evaluate data movement efficiency on the MI300A platform:
- Latency and Bandwidth Testing: Benchmarks like STREAM, adapted for GPU, measure performance for both local and remote memory accesses, illustrating latency and maximum achievable bandwidth (Figures 5 and 6).
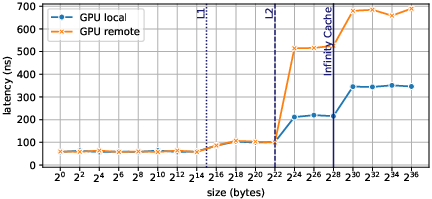
Figure 3: GPU memory access latency, measured with a pointer-chasing approach, for data located locally, or on a neighbour APU.
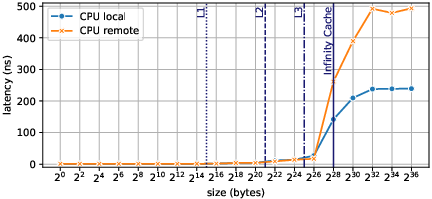
Figure 4: CPU memory access latency, measured with a pointer-chasing approach, for data either located locally or on a neighbour APU.
- Application Case Studies: Optimization of HPC applications, Quicksilver and CloverLeaf, demonstrating improved inter-APU communication efficiency and runtime reduction by leveraging identified optimization strategies (Figures 21 and 23).
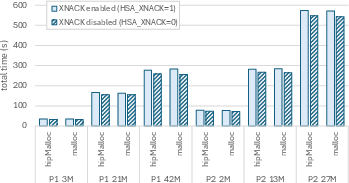
Figure 5: End-to-end runtime measured in Quicksilver for all input problems, comparing the impact of XNACK settings and allocators.
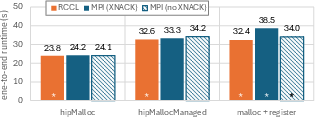
Figure 6: End-to-end runtime (in seconds) of CloverLeaf using the original implementation and our implementation using various memory allocators. All adapted versions are marked with ``
''. Average over five runs.*
Key Observations and Optimizations
- Allocator Impact: Communication performance is heavily reliant on memory allocation strategies. Using
hipMalloc achieves maximum interconnect bandwidths across various MPI and RCCL configurations.
- Programming Model Efficiency: GPU-centric interfaces (RCCL) tend to outperform CPU-centric approaches (MPI) for large message sizes due to efficient Infinity Fabric usage. For small messages, MPI's CPU-staging offers lower latency.
- Hardware Utilization: Disabling SDMA improves bandwidth for certain MPI communication patterns, although RCCL consistently leverages hardware to achieve full bandwidth.
Practical Implications and Future Work
These findings have practical implications for optimizing data movements in high-density GPU environments, such as those in emerging supercomputing platforms. Efficient data movement sustains application throughput, crucial for simulations and workloads in scientific computing and neural networks. Future work could explore integrating these optimized strategies into middleware frameworks to abstract and automate optimizations in multi-APU systems.
In conclusion, the paper delineates guidelines and strategies for optimizing APU-APU communication on AMD MI300A systems, enabling researchers and engineers to better leverage their computational infrastructure for scalable and efficient performance.