- The paper introduces GPU-Initiated Networking (GIN), allowing CUDA kernels to directly initiate asynchronous network operations.
- The paper details dual-backend designs—GDAKI and Proxy—that achieve latencies as low as 16.7 μs, closely matching NVSHMEM performance.
- The paper demonstrates GIN's scalability in high-throughput and low-latency MoE communication, paving the way for unified, efficient AI deployments.
Introduction
This paper introduces GPU-Initiated Networking (GIN) as a fundamental extension to the NVIDIA Collective Communication Library (NCCL), addressing the increasingly critical need for low-latency, device-driven GPU-GPU communication required by modern AI workloads such as Mixture-of-Experts (MoE), LLM inference, and compiler-fused communication patterns. Traditional NCCL communication relies on host-initiated, CPU-coordinated paradigms that are suboptimal for computation–communication fusion on GPUs. GIN enables direct, asynchronous network operations from within CUDA kernels, bypassing the CPU and reducing end-to-end communication latency.
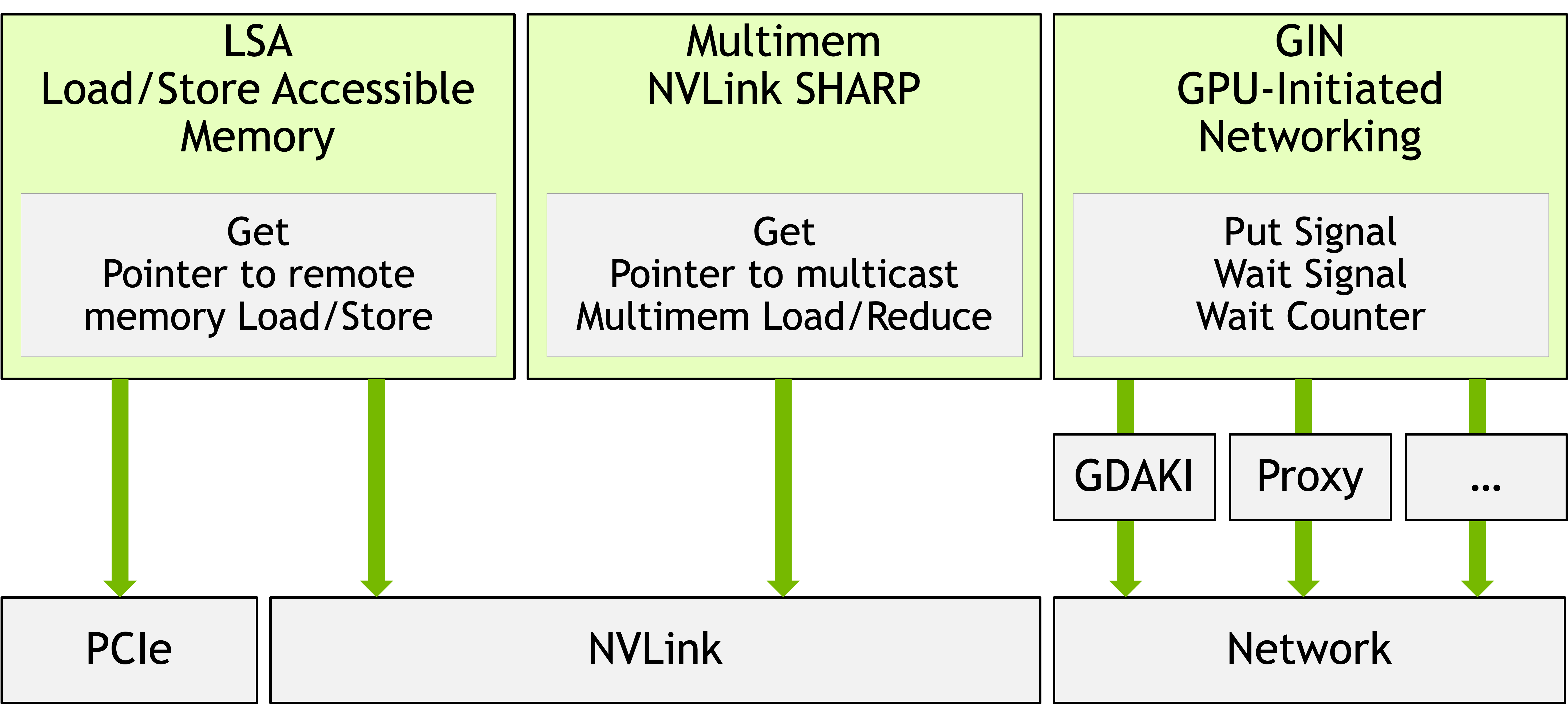
Figure 1: NCCL Device API architecture showing three operation modes: Load/Store Accessible (LSA) for intra-node, Multimem for NVLink SHARP multicast, and GPU-Initiated Networking (GIN) for inter-node RDMA, each leveraging different hardware interconnects.
NCCL Device API and GIN Architecture
NCCL 2.28 introduces a Device API with three operation modes:
- Load/Store Accessible (LSA): Direct memory operations over NVLink/PCIe for intra-node access.
- Multimem: Hardware multicast via NVLink SHARP.
- GPU-Initiated Networking (GIN): Device-driven network operations over InfiniBand/RoCE via RDMA semantics.
The focus of GIN is inter-node RDMA, enabling CUDA kernels to initiate one-sided network operations—put, putValue, and signal—with flexible synchronization and completion semantics. The architecture is organized across three layers: NCCL Core host-side API (for communicator and memory window management), device-side APIs invokable from GPU code, and a modular plugin backend supporting both direct and proxy network semantics.
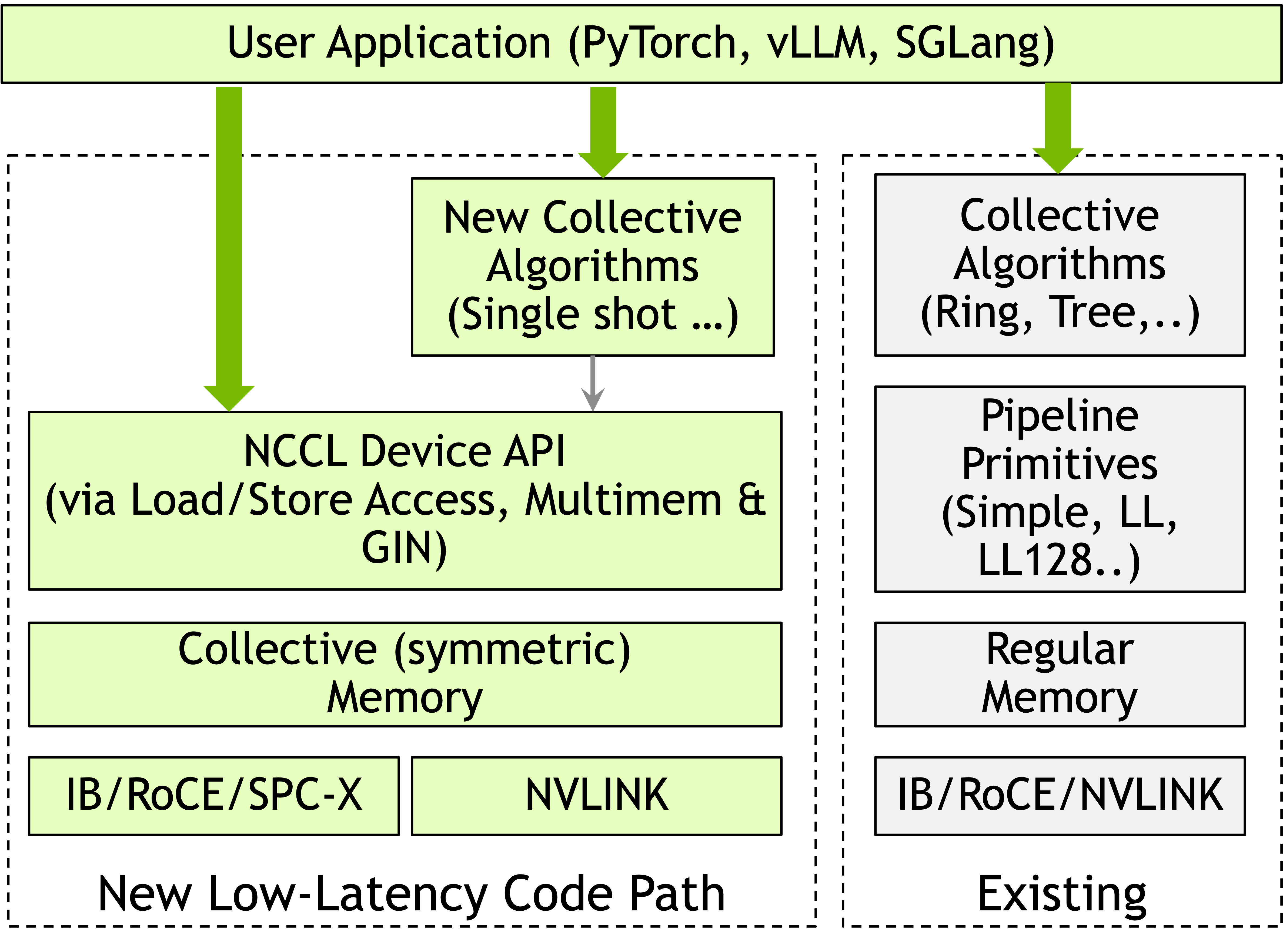
Figure 2: Comparisons between the NCCL Device API's device-initiated architecture and traditional host-initiated NCCL, highlighting GIN’s support for single-shot, device-driven collectives over symmetric memory.
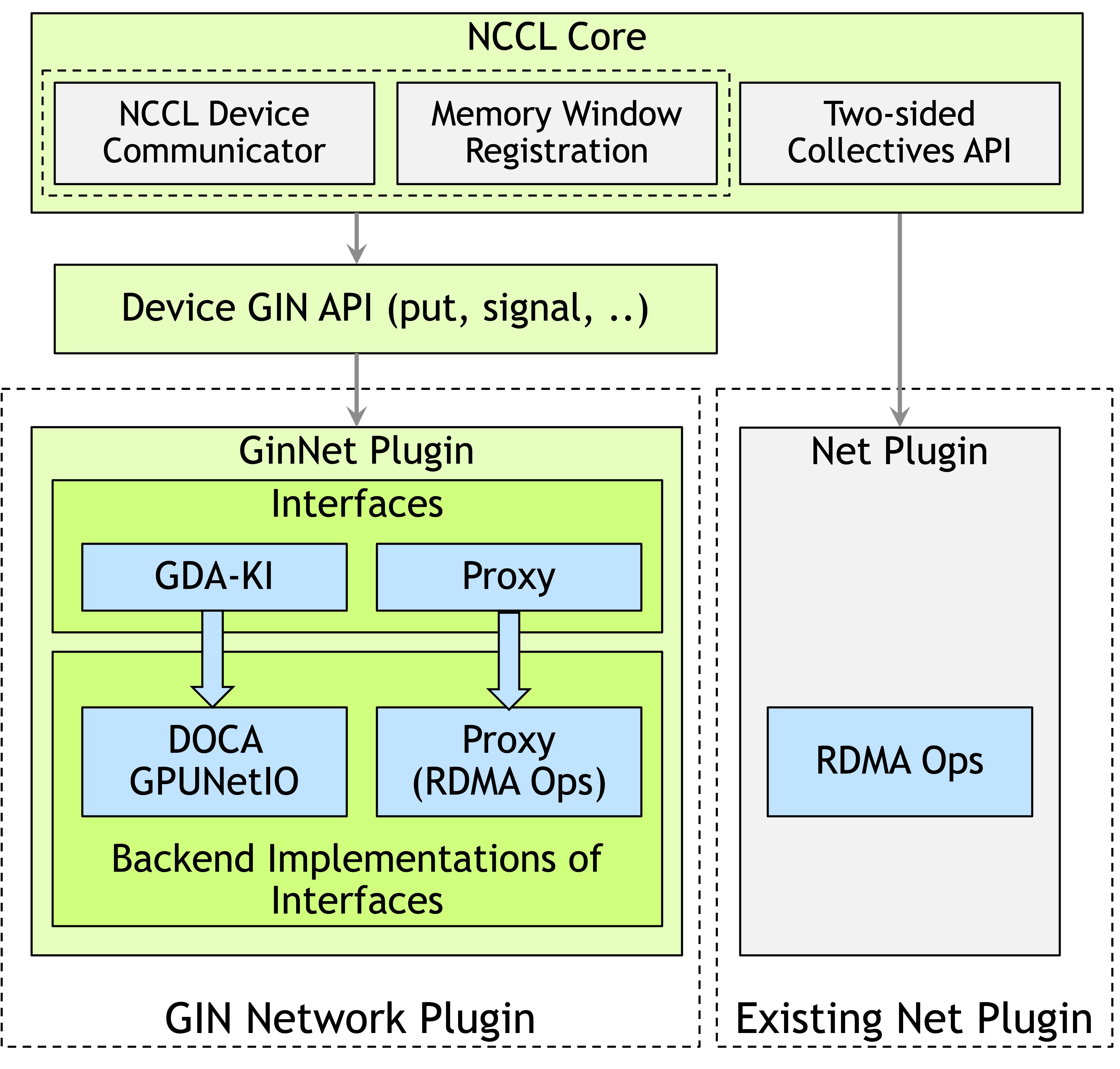
Figure 3: Detailed GIN architecture depicting the interplay between host-side NCCL core, plugin infrastructure, and device-accessible collective API.
The GIN plugin system supports two modes:
- GDAKI Backend: Leverages DOCA GPUNetIO for direct GPU-to-NIC communication, eliminating CPU intervention.
- Proxy Backend: Employs lock-free GPU-to-CPU queues where the CPU proxy thread posts operations on behalf of the GPU, ensuring broad hardware compatibility at some latency cost.
Device-Side Semantics and Programming Model
The GIN device API exposes GPU-callable methods to initiate remote memory operations, synchronization, and completion tracking. The model centers on registered symmetric memory windows and context abstractions, with each context enabling parallel communication streams (multi-QP, multi-NIC aware).
Notable semantic features include:
- One-sided operations: Unilateral RDMA primitives (remote writes, signals) for maximal overlap and reduced synchronization.
- Flexible completion tracking: Local counters for sender-side completion and signals for remote notification, decoupled via integer (ID-based) addressing rather than memory-based synchronization.
- Fine-grained ordering: Ordered delivery between
put and signal on a per-context, per-peer basis, with user-managed thread ordering via CUDA synchronization.
Backend Implementation: GDAKI vs. Proxy
GIN's dual-backend architecture addresses heterogeneous hardware environments:
- GDAKI delivers true device-initiated networking by allowing kernels to enqueue work queues that are polled and processed autonomously by modern NICs (e.g., ConnectX-6 Dx+), achieving minimal communication latency.
- Proxy ensures universality, supporting any RDMA-capable NIC and CUDA environment by routing GPU requests through host-resident proxy threads.
The two backends provide identical device-facing APIs but diverge in performance characteristics and hardware requirements.
DeepEP Integration for MoE Communication
GIN was integrated into DeepEP, an MoE communication library, replacing the existing NVSHMEM backend for dense all-to-all kernel patterns in both high-throughput (HT) and low-latency (LL) regimes.
The DeepEP integration maintains:
- High degrees of QP parallelism: By distributing work across multiple contexts and communicators.
- Window and offset translation: Kernels dynamically resolve address offsets within symmetric windows, mirroring pointer-based semantics of NVSHMEM but mapped to GIN's window abstraction.
- Remote synchronization: Signal objects replace direct memory atomics for head/tail pointer management in queue-style communication.
Comprehensive benchmarking was performed on H100-equipped DGXH100 clusters using both GDAKI and Proxy backends, baselined against NVSHMEM with IBGDA/IBRC transports.
Microbenchmark Results
GIN GDAKI achieves 16.7 μs round-trip latency for small messages, closely matching NVSHMEM IBRC (16.0 μs) and outperforming NVSHMEM IBGDA (24.3 μs). GIN Proxy incurs minor additional latency (18.0 μs) due to CPU mediation.
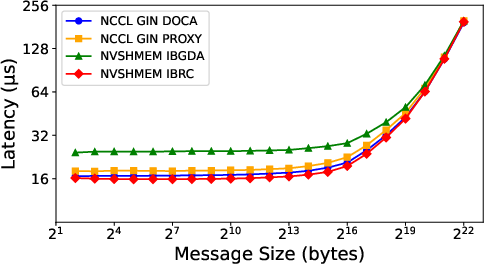
Figure 4: Point-to-point latency comparison for small messages across NVSHMEM (IBGDA, IBRC) and NCCL GIN (GDAKI, Proxy) backends.
High-Throughput MoE Kernels
For large batch, hierarchical MoE communication on up to 64 GPUs, GIN matches NVSHMEM’s bandwidth within 1–2% for both FP8 and BF16 precisions—~84 GB/s for 2 nodes and ~54 GB/s at 8 nodes in dispatch operations.
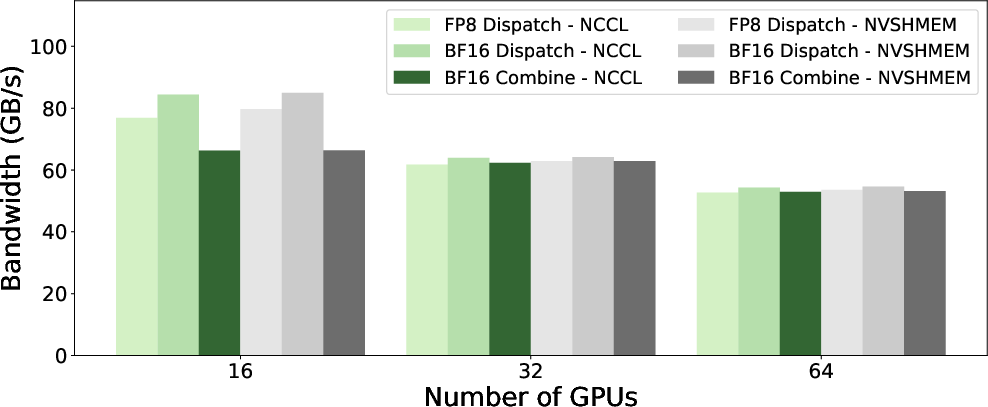
Figure 5: Throughput of HT kernels for NCCL GIN and NVSHMEM across cluster scales.
Low-Latency MoE Kernels
With hybrid NVLink+RDMA enabled, GIN marginally outperforms NVSHMEM for both bandwidth (~185 GB/s) and latency (~40 μs) at single-node, maintaining parity at scale. With NVLink disabled (pure RDMA), GIN and NVSHMEM remain nearly indistinguishable (~47 GB/s, ~161 μs at single node).
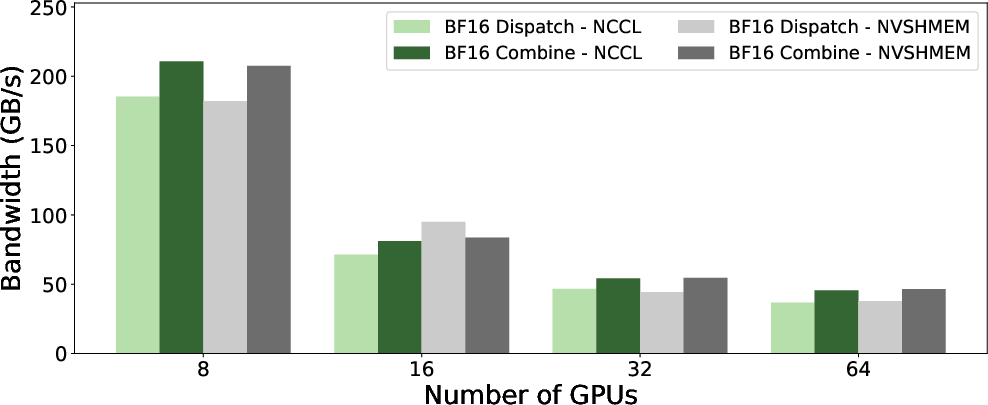
Figure 6: LL kernel bandwidth (NVLink enabled) shows comparable or superior performance for GIN over NVSHMEM.
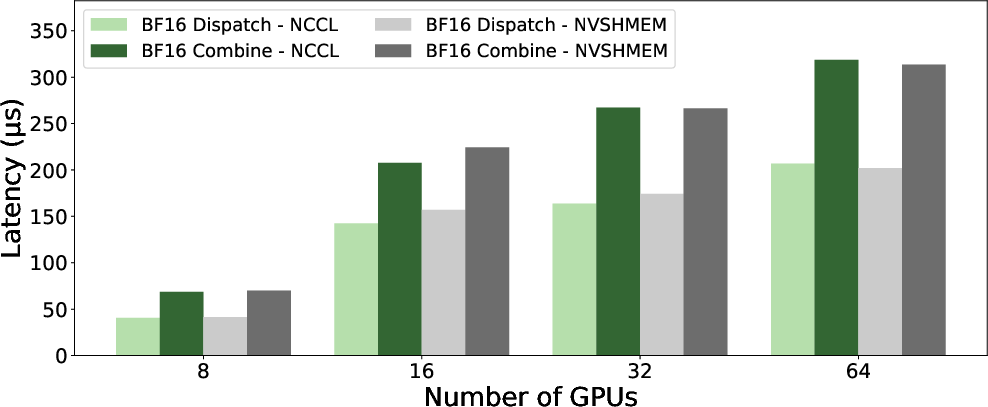
Figure 7: LL kernel latency (NVLink enabled) for GIN and NVSHMEM, with GIN showing lower latency across scales.
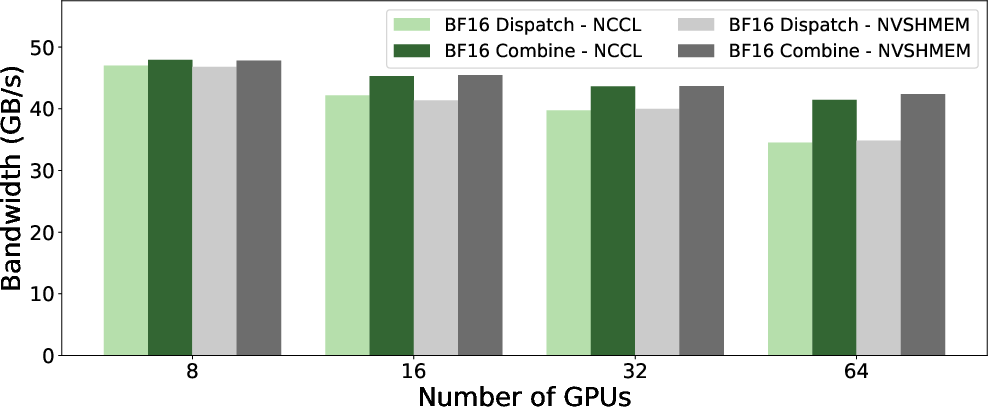
Figure 8: LL kernel bandwidth with pure RDMA paths, demonstrating negligible differences between GIN and NVSHMEM.
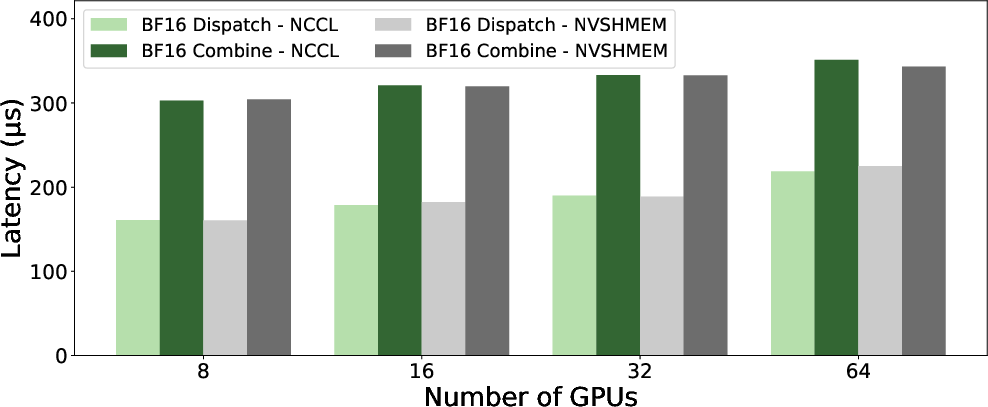
Figure 9: LL kernel latency with pure RDMA, reinforcing GIN’s performance equivalence with established GPU-initiated libraries.
Implications and Future Prospects
The integration of device-initiated communication into NCCL via GIN has meaningful implications for the deployment of emerging AI applications:
- Unified runtime: GIN combines the flexibility of device-initiated primitives with NCCL's robust hierarchical communicators, elasticity, and fault tolerance, reducing the need for multiple communication runtimes in large-scale deployments.
- Performance parity: GIN achieves latency and bandwidth on par with—or slightly better than—NVSHMEM, while integrating tightly with NCCL’s host-based collectives for hybrid patterns.
- Broader applicability: With dual-backend support, GIN enables both high-end clusters (GDAKI) and commodity configurations (Proxy) to benefit from device-driven programming models.
- Enhanced software stack adoption: Facilitation of device-initiated communications in production ML frameworks (PyTorch, TensorRT-LLM, vLLM, SGLang) and compiler-generated code (JAX/Triton) is projected as future development, with GIN poised as the standard communication substrate for next-generation AI workloads.
Conclusion
The GIN extension to NCCL encapsulates the state-of-the-art in GPU-initiated networking: it exposes device-callable, one-sided network operations, implants a pluggable device-side API, and achieves performance matching standalone GPU-initiated communication libraries across a breadth of AI-relevant workloads, thereby paving the way for scalable, computation-communication fusion in training and inference pipelines. GIN’s architecture and dual-backend design navigate the diversity of hardware deployments while offering a unified, programmable, and performant collective communication infrastructure for the AI ecosystem.

