- The paper introduces NIMBLE, an endpoint-driven framework that dynamically orchestrates multi-path transfers to mitigate communication hotspots in GPU clusters.
- NIMBLE employs real-time monitoring and a multi-commodity flow approach to distribute load across intra- and inter-node links, achieving significant bandwidth improvements.
- Empirical results demonstrate up to 5.2× speedup for skewed All-to-Allv workloads and reduced iteration times for mixture-of-experts LLM training.
Node-Interconnect Multi-Path Load Balancing for Skewed Communication in GPU Clusters
Motivation and Problem Statement
Contemporary GPU-based HPC and AI clusters integrate high-throughput intra-node links (NVLink, NVSwitch, xGMI) with high-bandwidth, multi-rail inter-node networks (InfiniBand/RoCEv2), forming a heterogeneous communication fabric with terabyte-scale aggregate bandwidth potential. However, practical workloads often exhibit severe communication imbalance: a subset of links becomes oversaturated while others remain nearly idle, driven by dynamic, sparse, or highly skewed all-to-all communication typical in All-to-Allv collectives, Mixture-of-Experts parallelism, or graph/sparse algebra workloads. This imbalance results in hot-spot congestion, p99 tail latency spikes, and suboptimal throughput far below hardware limits.
State-of-the-art communication libraries (NCCL, RCCL, MPI/UCX) predominantly rely on static topology discovery and fixed path selection (init-time fastest-path/multi-rail striping/ring or tree construction), fundamentally lacking the mechanism to adapt at runtime to live load and evolving traffic skews. This directs repeated bottlenecks to the same links, systematically degrading cluster utilization and application scalability.
NIMBLE Architecture and Algorithms
The NIMBLE framework addresses these deficiencies with transparent endpoint-driven dynamic multi-path orchestration. Positioned logically between the application and underlying hardware, NIMBLE intercepts communication primitives and redistributes payloads across all available intra-node and inter-node links based on real-time monitoring of link utilization.
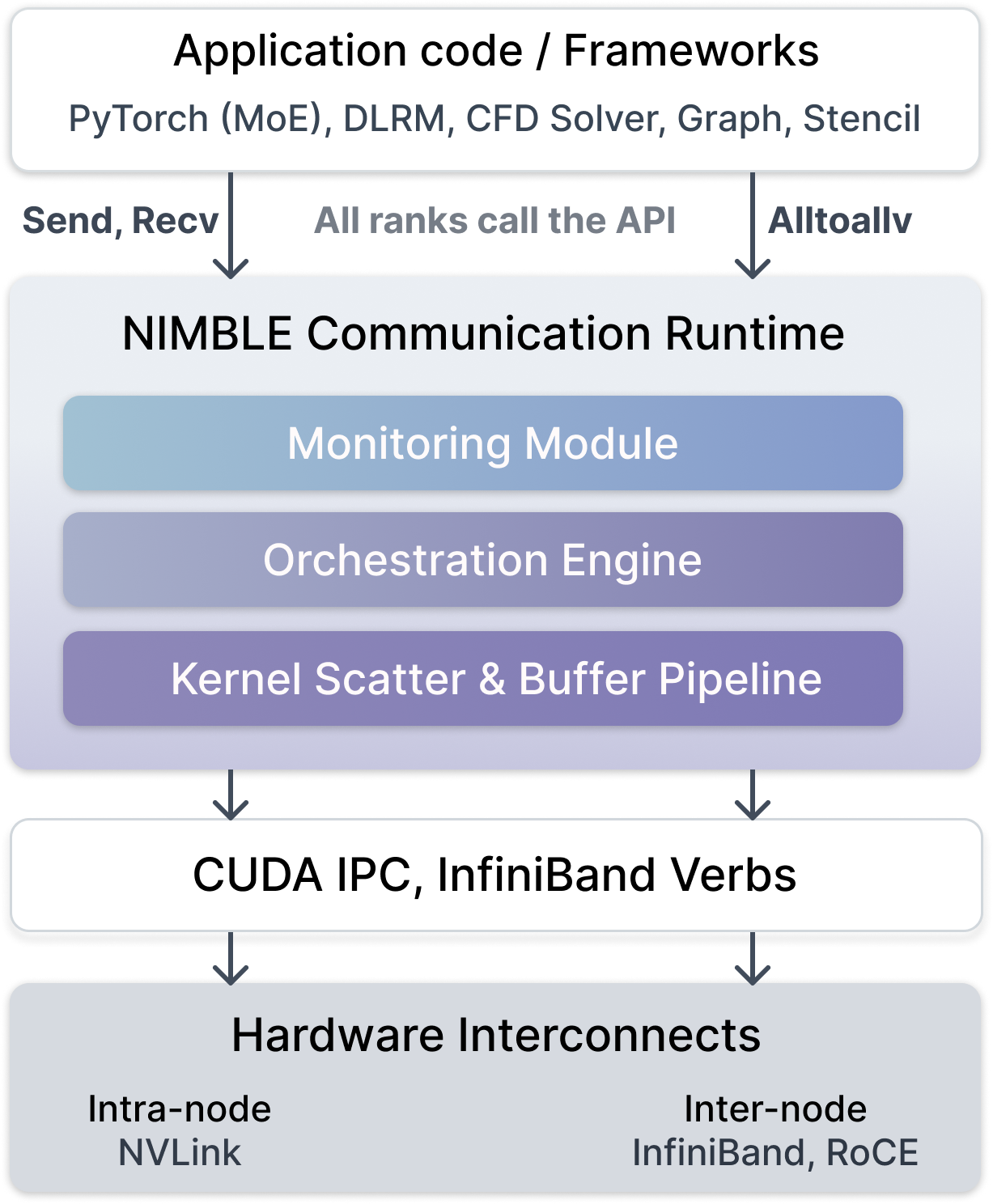
Figure 1: NIMBLE architecture: middleware intercepts communication and orchestrates dynamic link-aware multi-path transfers across both intra- and inter-node fabrics.
NIMBLE employs a three-layer architecture:
- Monitoring Module: Continuously tracks the utilization and congestion state on all hardware links, capturing fine-grained communication activity.
- Hop-Adaptive Orchestration Engine: Implements an efficient capacity-normalized minimum-congestion optimization formulated as a multi-commodity flow problem. Communication demands are iteratively allocated to paths so as to minimize the maximum link load, using an MWU-based approximation allowing practical runtimes.
- GPU Kernel-Based Pipelining: Leverages CUDA-aware kernel launching and peer-to-peer RDMA primitives to pipeline data across multiple intermediate GPU nodes and rail-matched NICs, achieving fully parallel, non-blocking forwarding with careful buffer and synchronization management.
The path selection process considers all feasible direct and multi-hop (one intermediate intra-node or inter-node rail-matched) paths. It dynamically updates path costs as a convex penalty function of observed link usage, ensuring new flows avoid building upon existing hotspots.
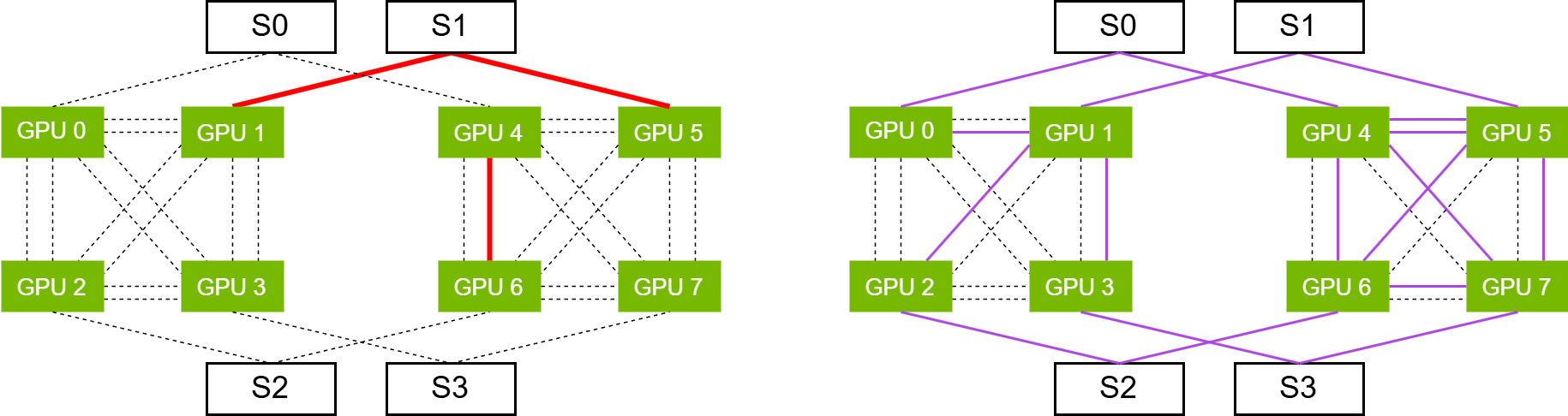
Figure 2: NIMBLE scatters original hotspot-dominated communication into aggregation over all available links, mitigating path congestion.
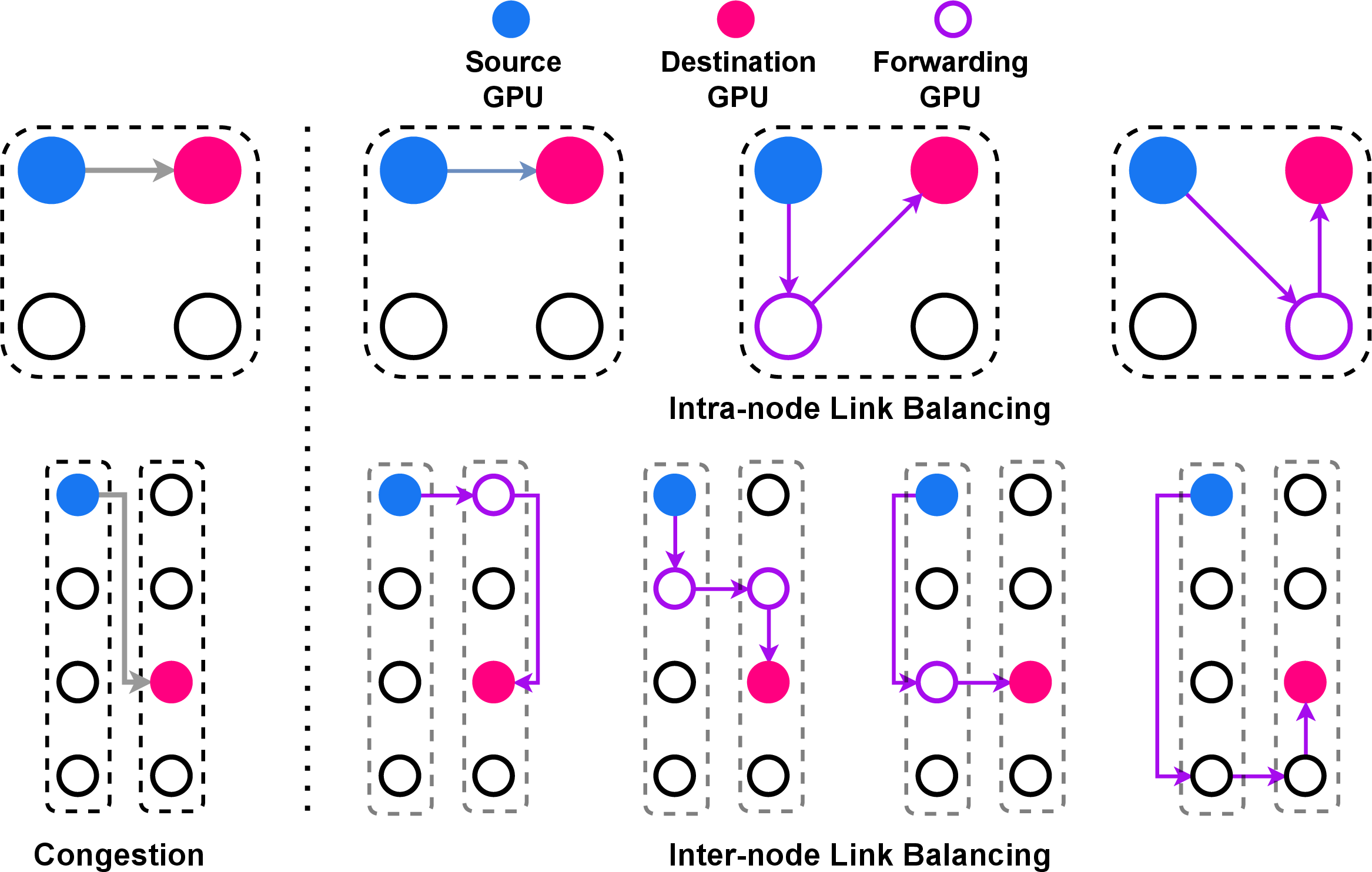
Figure 3: For 4-GPU, 4-NIC nodes, intra-node loads are distributed via direct or 2-hop GPU links, while inter-node loads leverage all possible rail-matched NIC pairings.
Critically, pipelined forwarding is enabled by fine-grained, persistent peer-to-peer buffer and counter allocations on all intermediate devices (GPUs and NICs). Data segments transit over the pipeline, synchronized by peer-accessible counters, minimizing both CPU intervention and intermediate buffering.
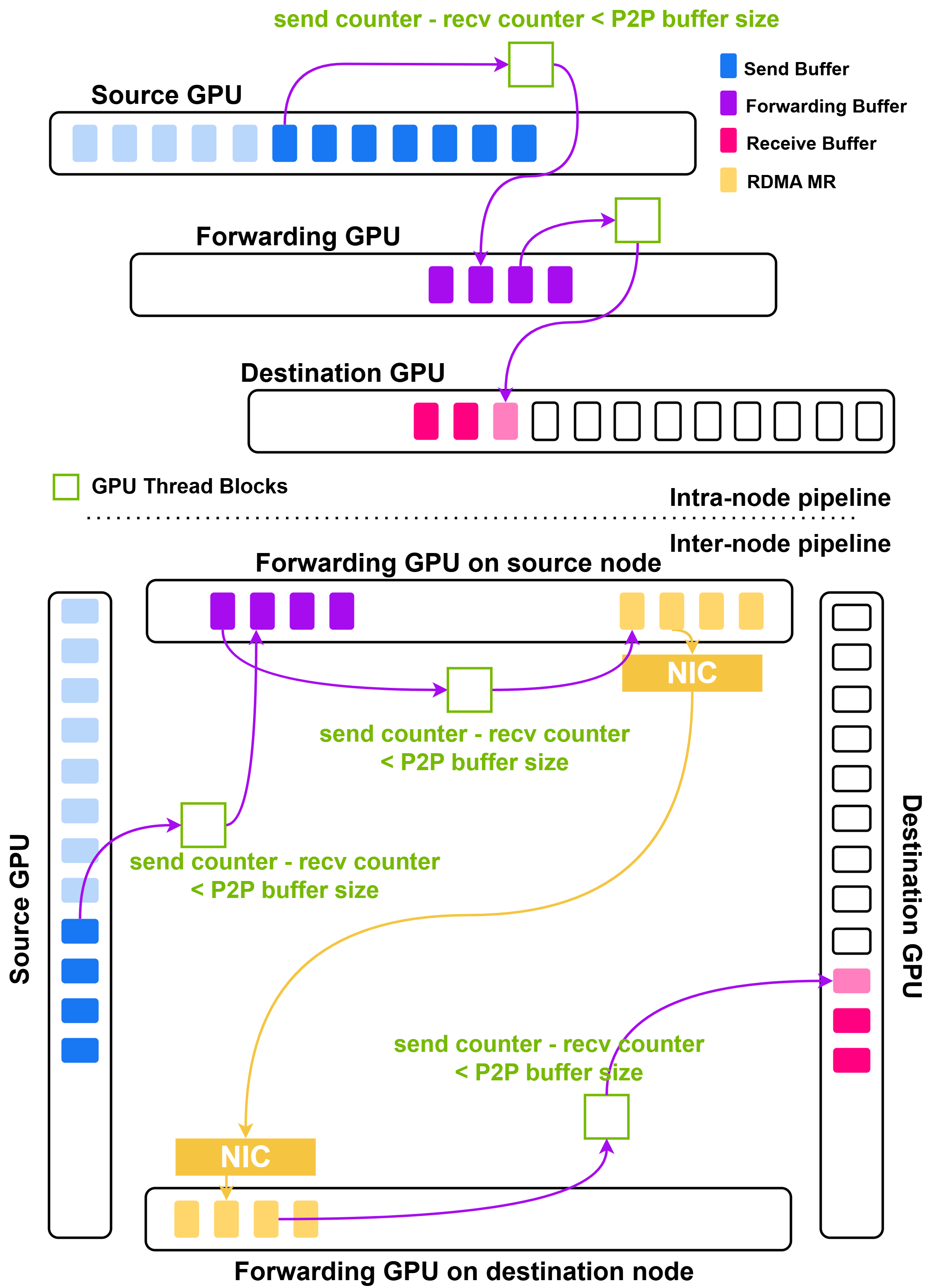
Figure 4: Intermediate per-GPU and per-NIC buffer allocations establish persistent pipelining pools, with synchronization counters ensuring correctness and avoiding races.
Evaluation and Results
The evaluation uses a representative configuration: H100-SXM5 nodes with fully connected NVLINK4 and four NDR400 HCAs per node, each NIC affined to a distinct GPU. Benchmarks span synthetic microbenchmarks, skewed All-to-Allv, and full end-to-end MoE LLM workloads.
Point-to-Point and Multi-Hop Path Scaling
Enabling NIMBLE's orchestration and multi-path utilization yields substantial bandwidth improvements:
- Intra-node: 2-hop GPU forwarding pushes peak bandwidth from 120 GB/s direct to 213.1 GB/s (one intermediate) and 278.2 GB/s (two intermediates), matching hardware limits for three active paths. (Figure 5)
- Inter-node: Aggregating over four rail-matched NICs, throughput rises from 45.1 GB/s (single NIC) to 170.0 GB/s (all four in use).
- Forwarding Overhead: The penalty from one or two optional GPU/NIC hops is minor for large messages, with the pipeline disabled or penalized for small (≤1 MB) sessions to avoid performance regressions.
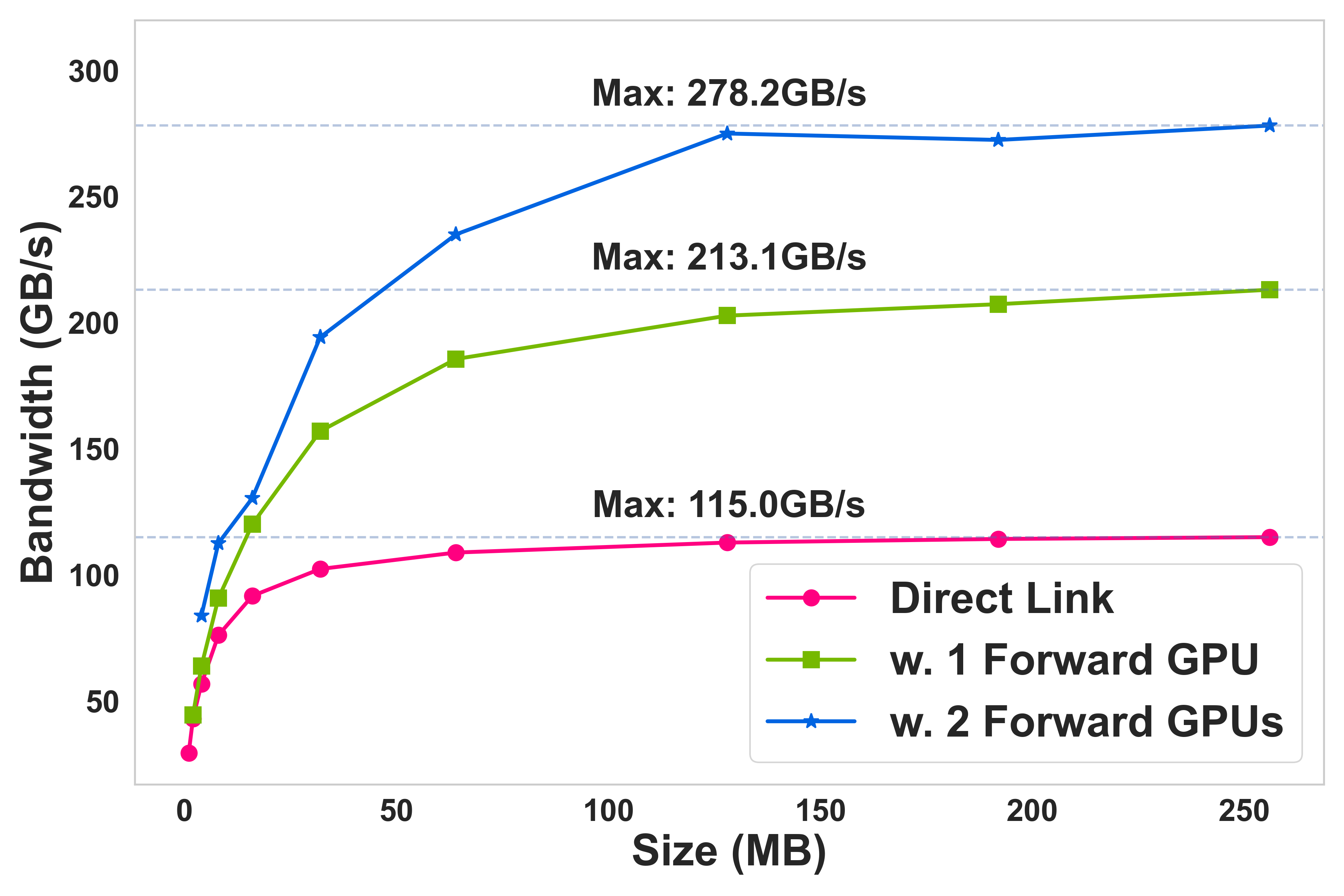
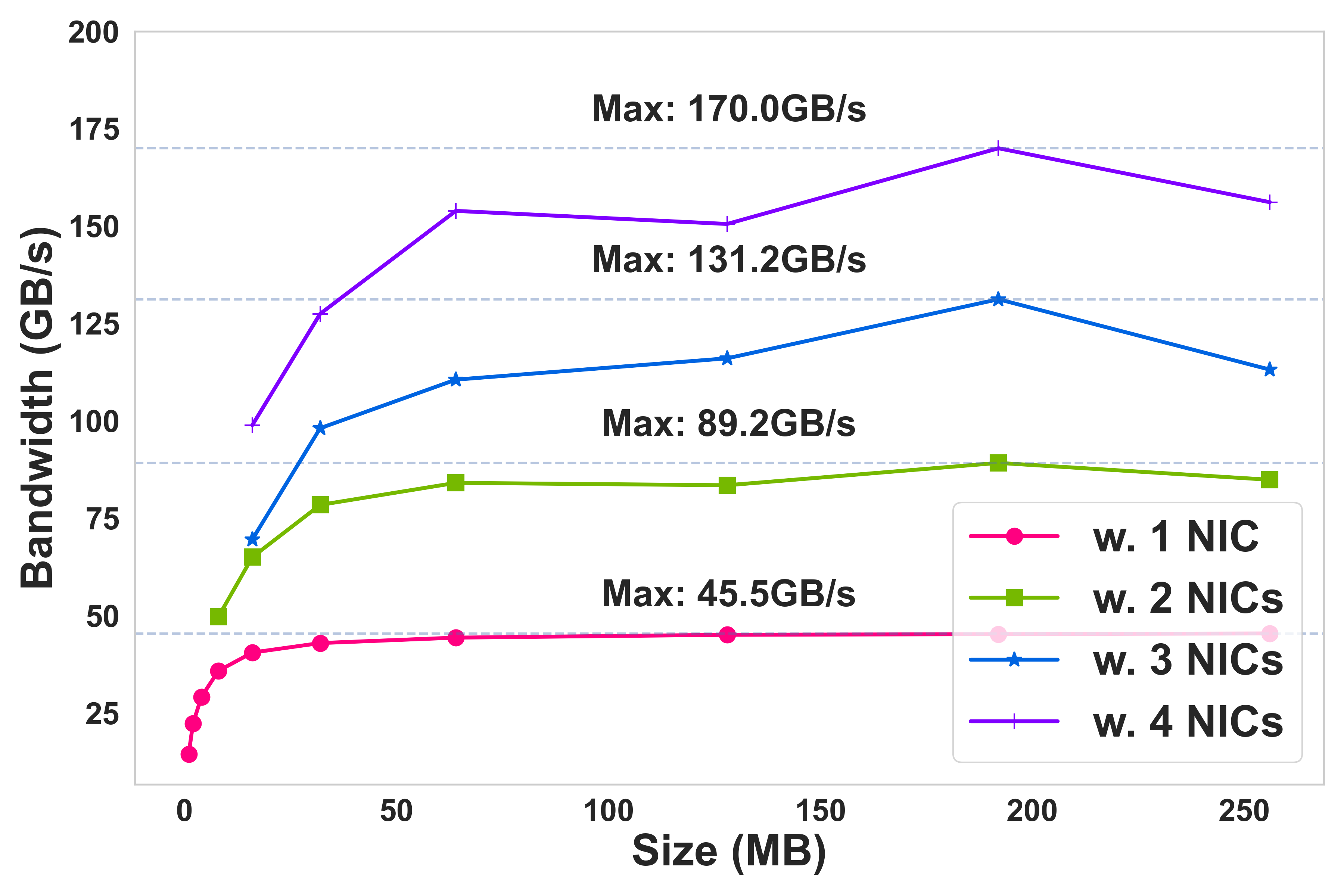
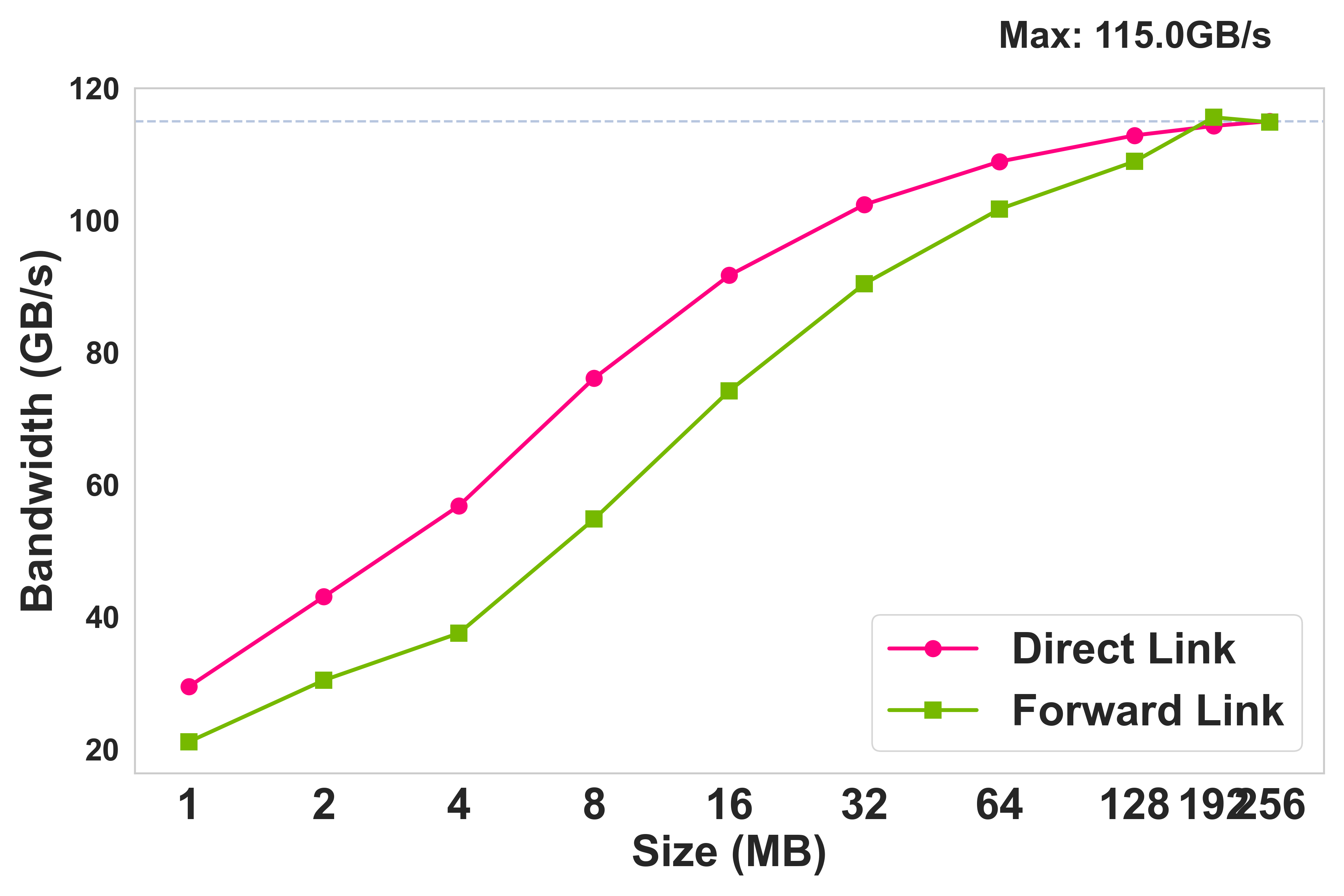
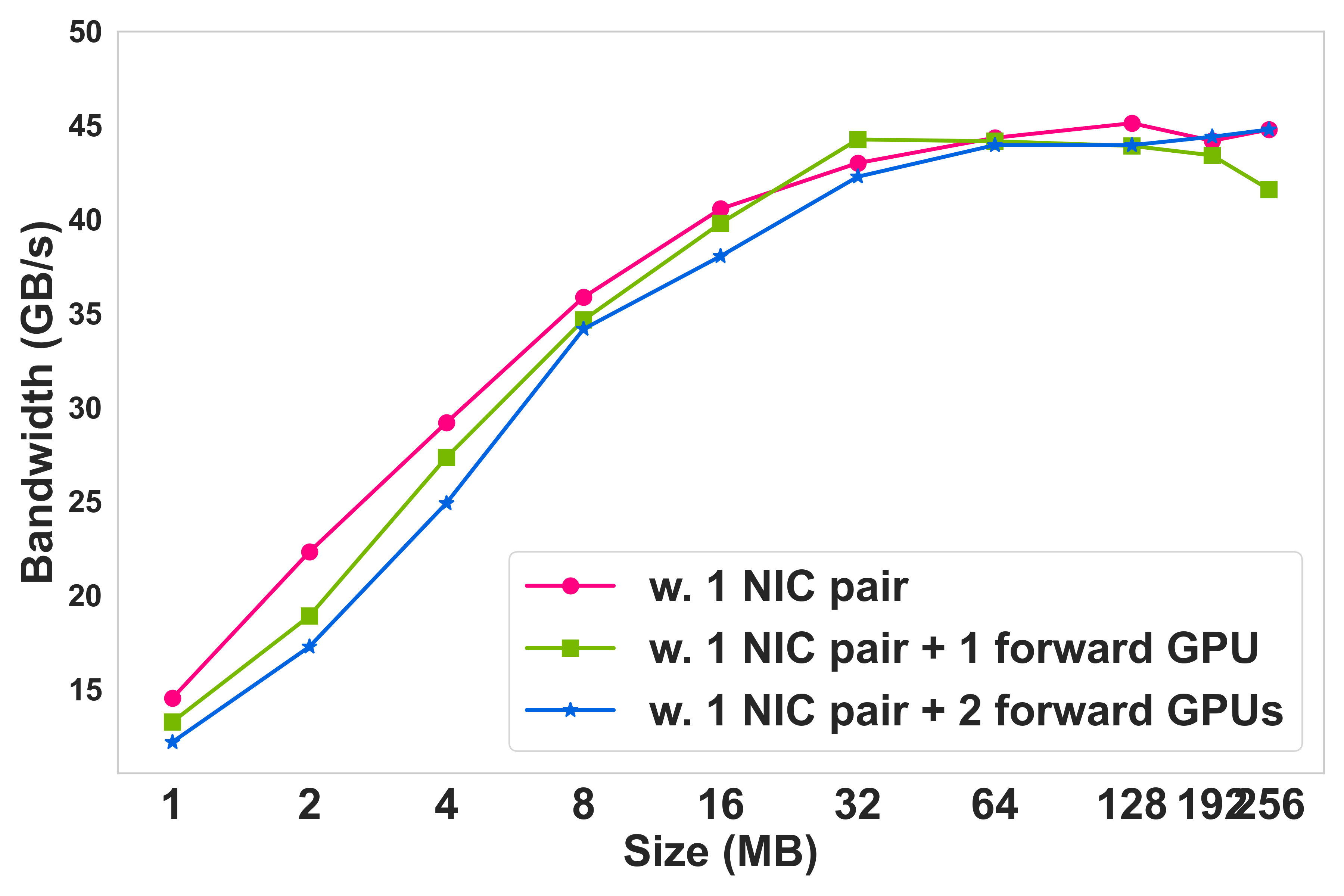
Figure 5: Multi-path aggregate bandwidth scaling as GPUs are added intra-node.
Mitigating Skewed All-to-Allv Bottlenecks
To assess real-world hotspot mitigation, the All-to-Allv primitive is benchmarked under synthetic skew: a configurable "hotspot ratio" fraction of payload directed at a single destination. As imbalance intensifies (hotspot ≥0.7), NIMBLE outpaces NCCL by up to 5.2× by adaptively rerouting off saturated links onto idle alternatives; speedups grow with both message size and degree of skew.
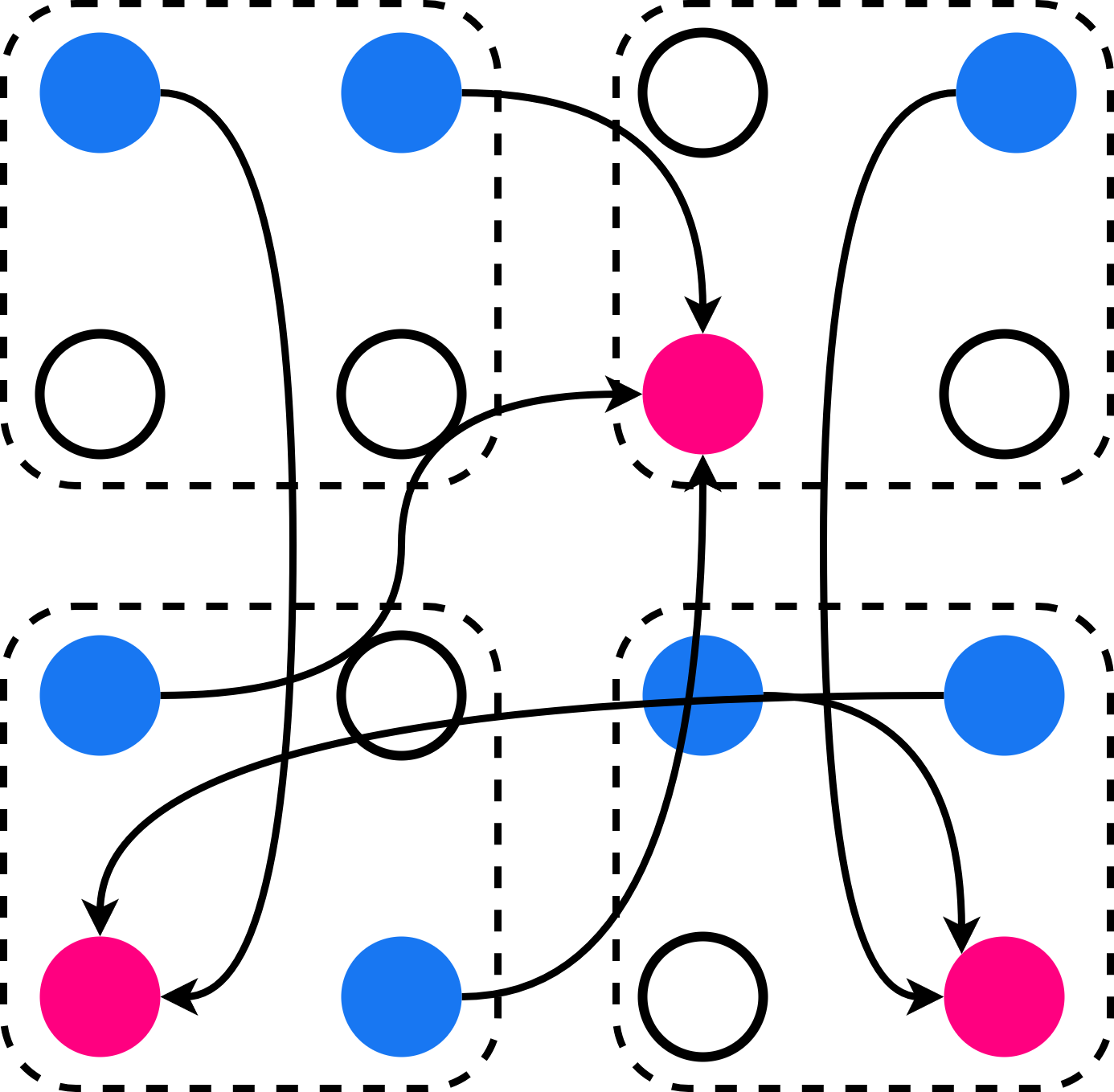
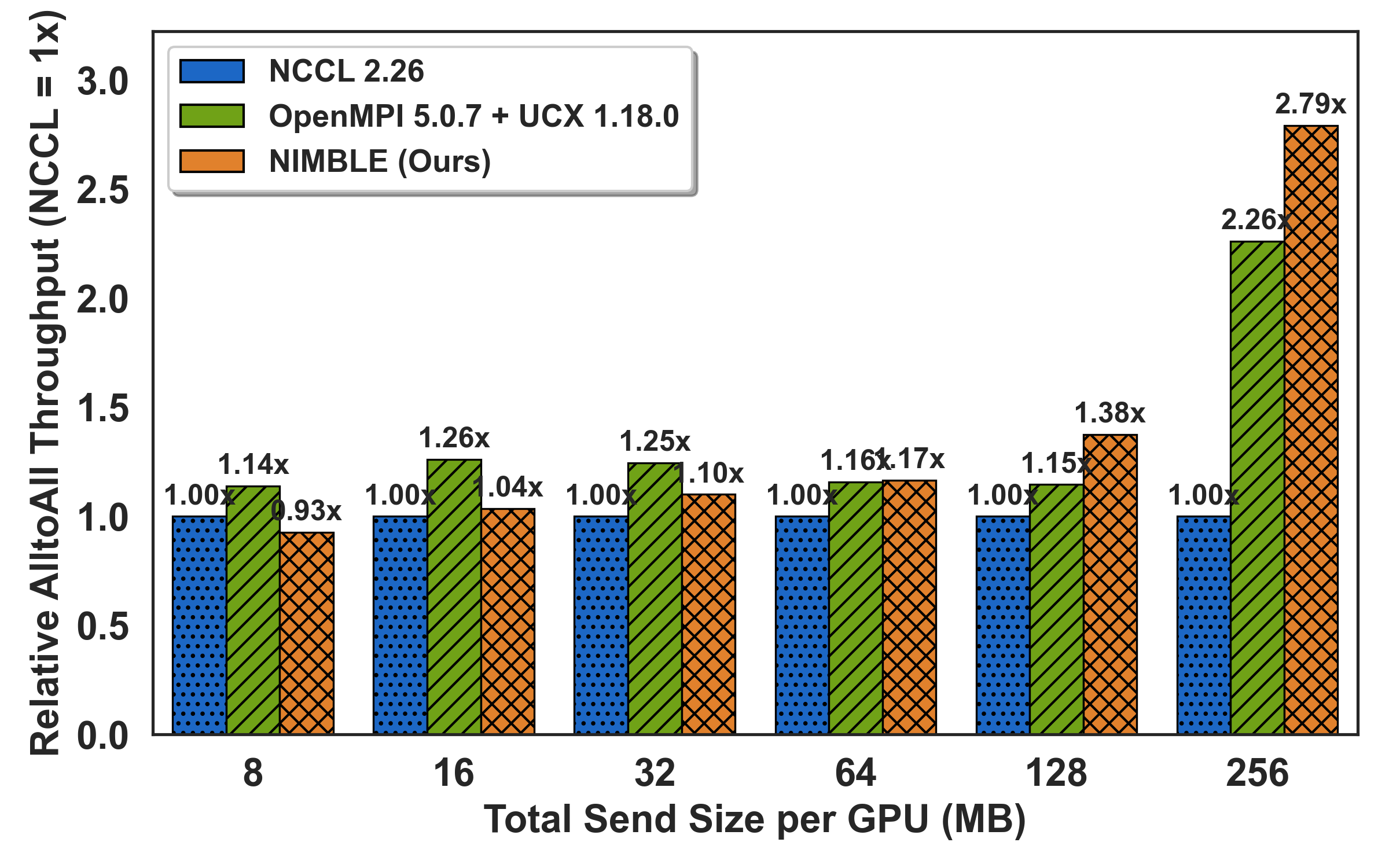
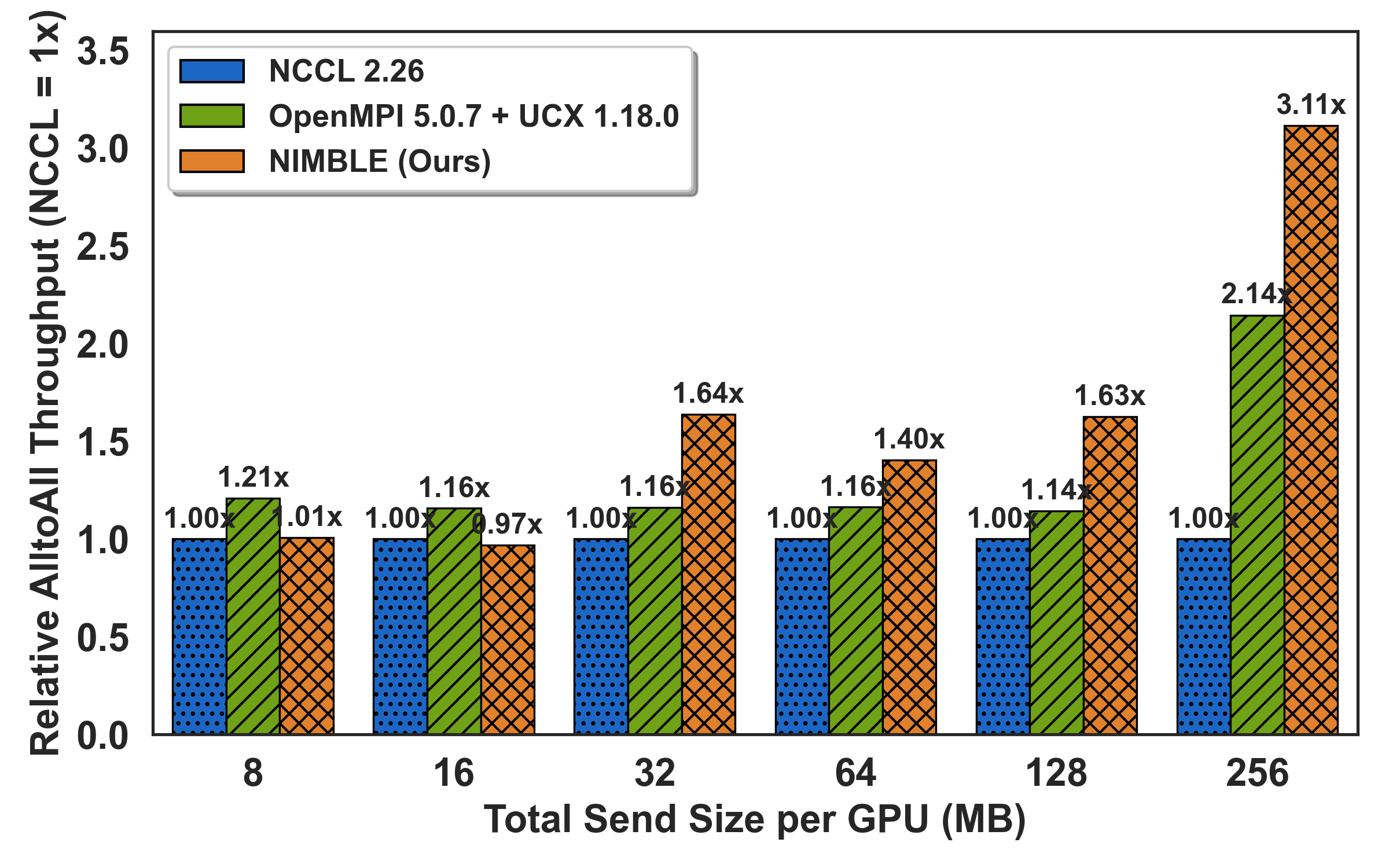
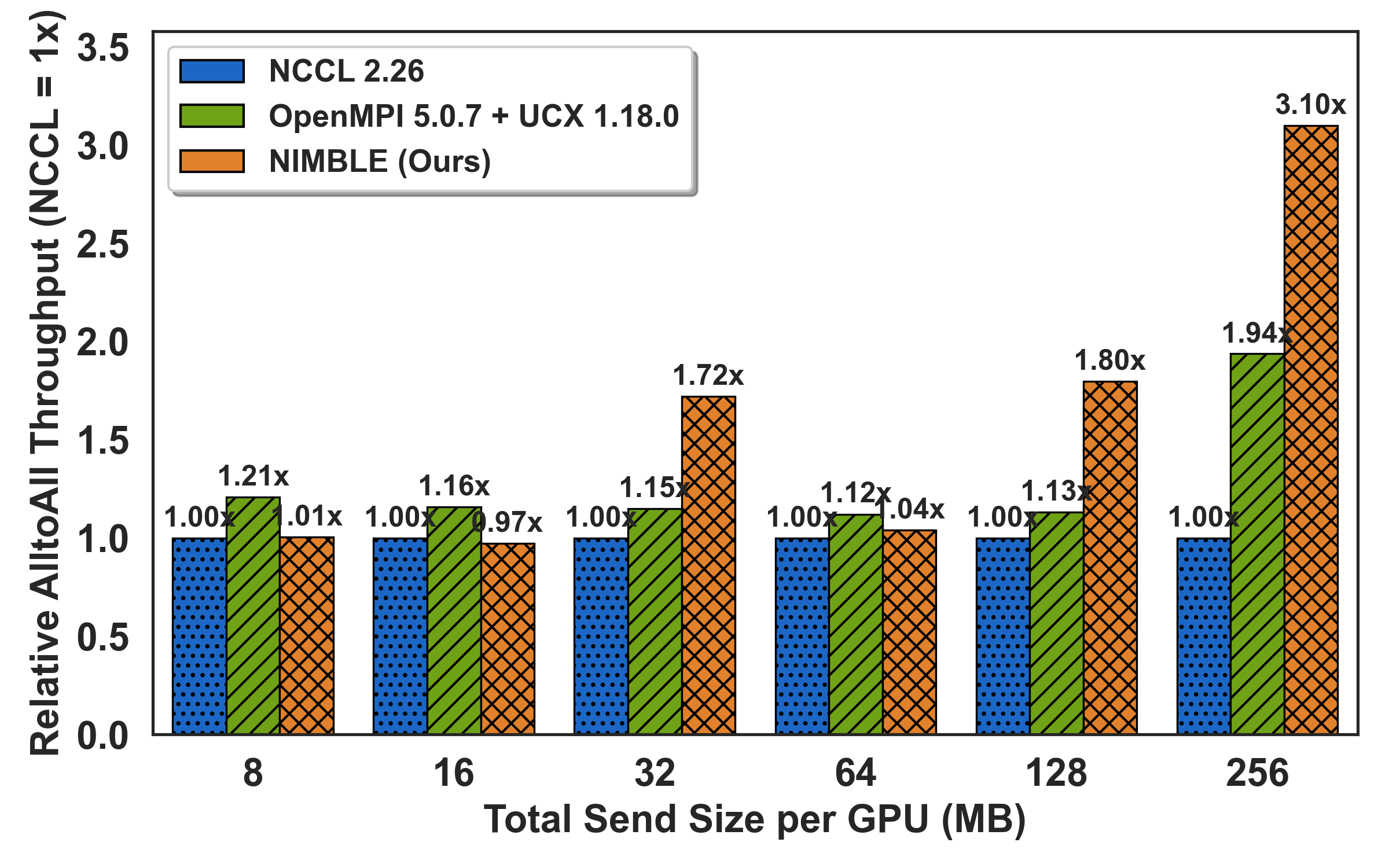
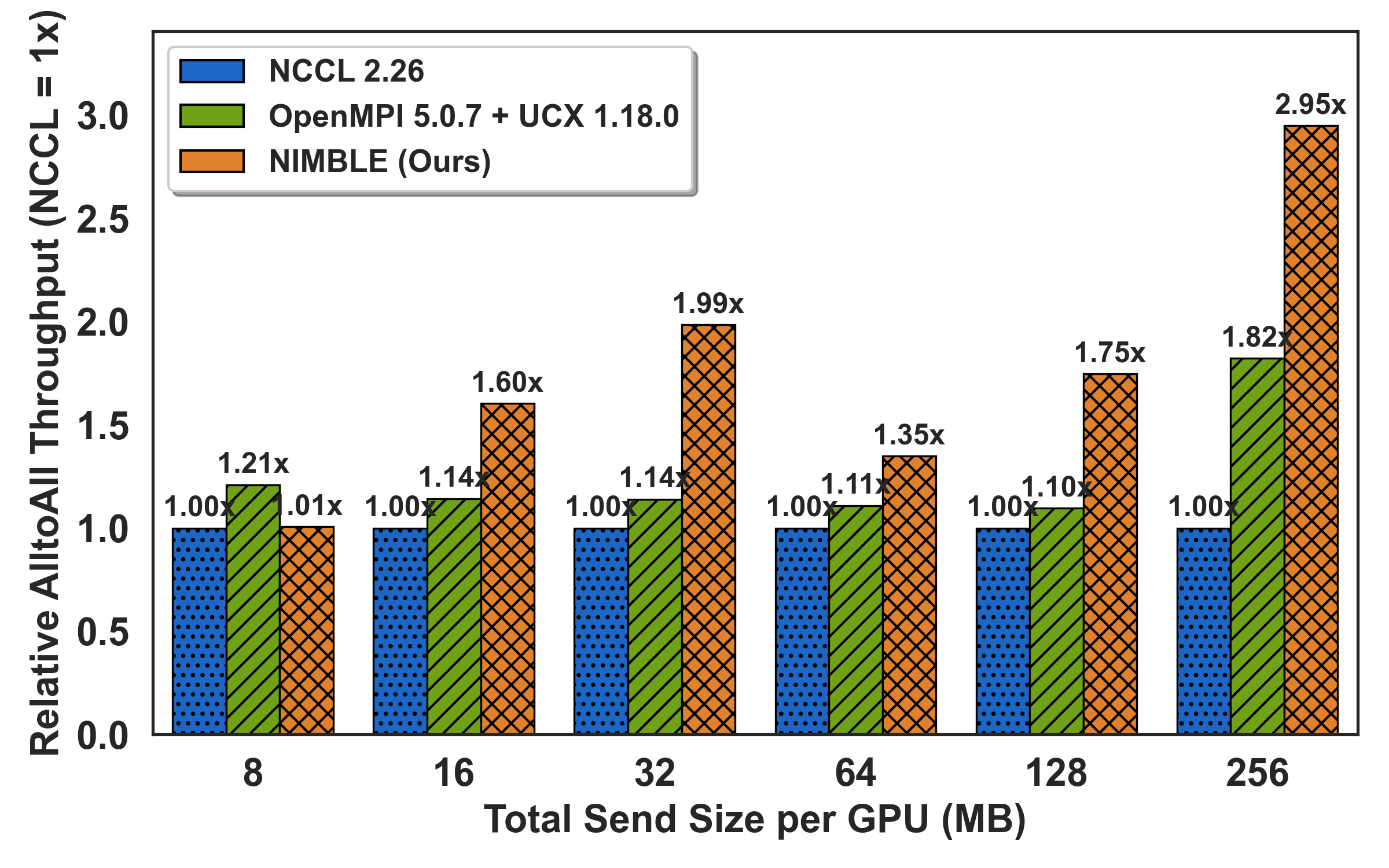
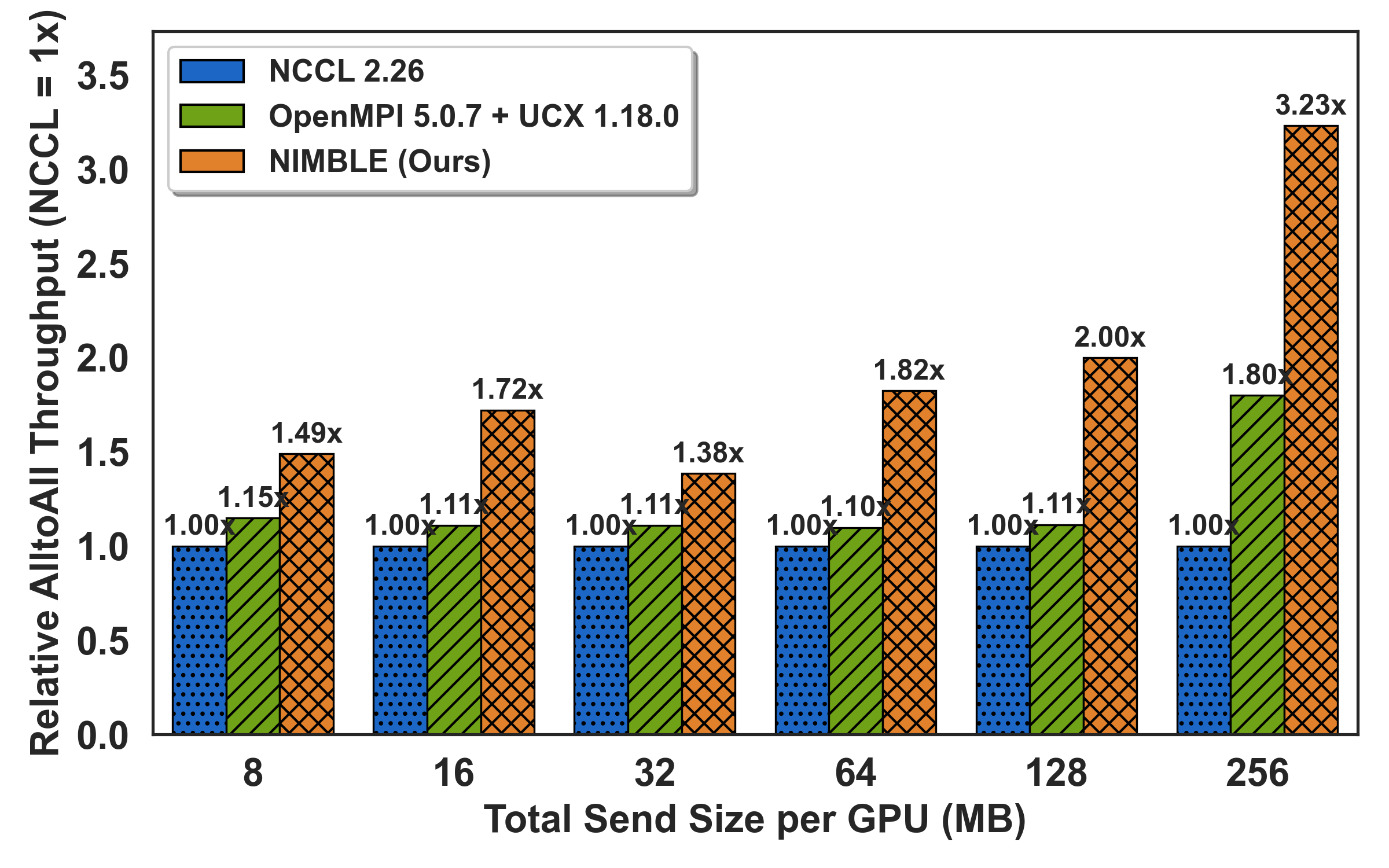
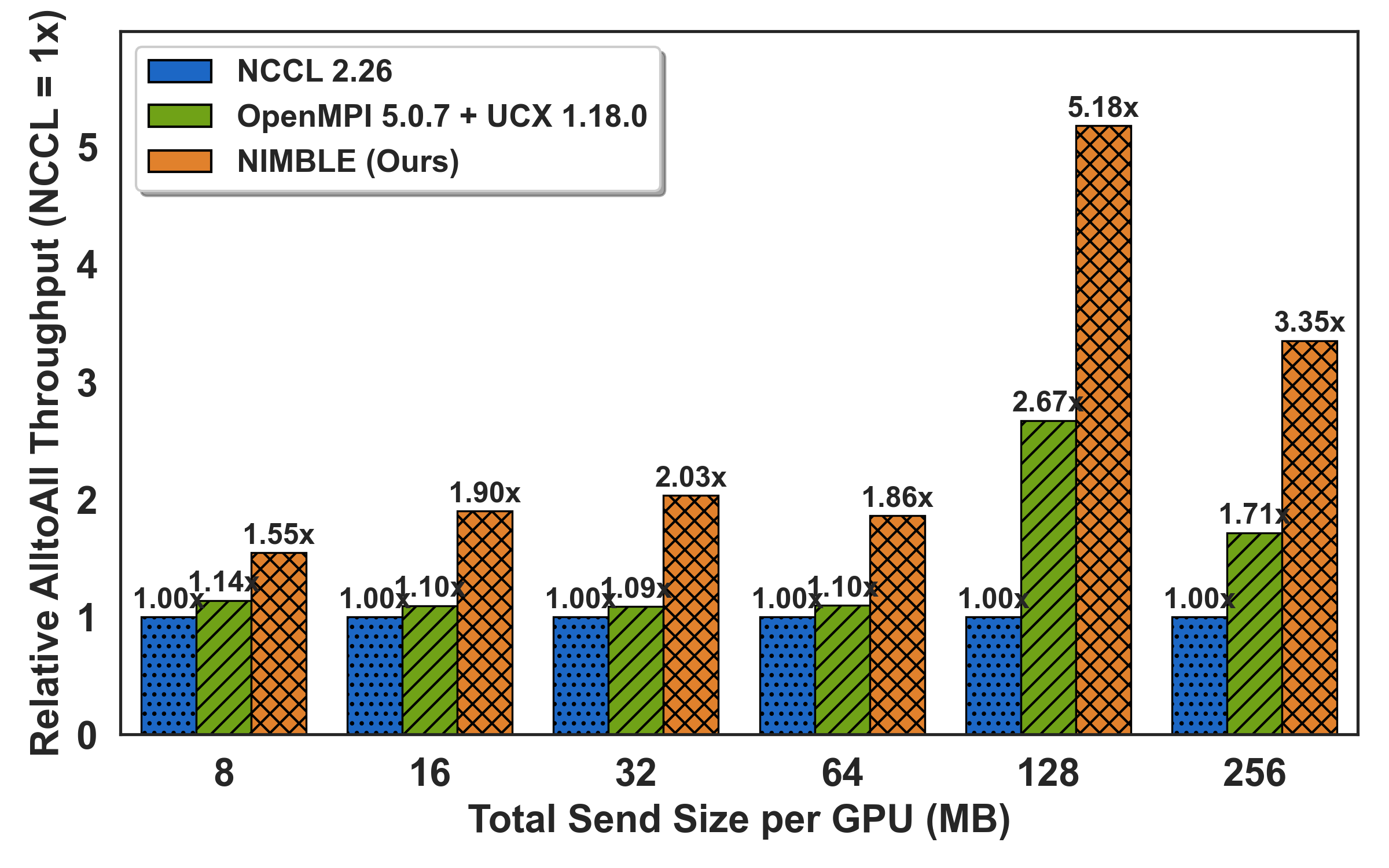
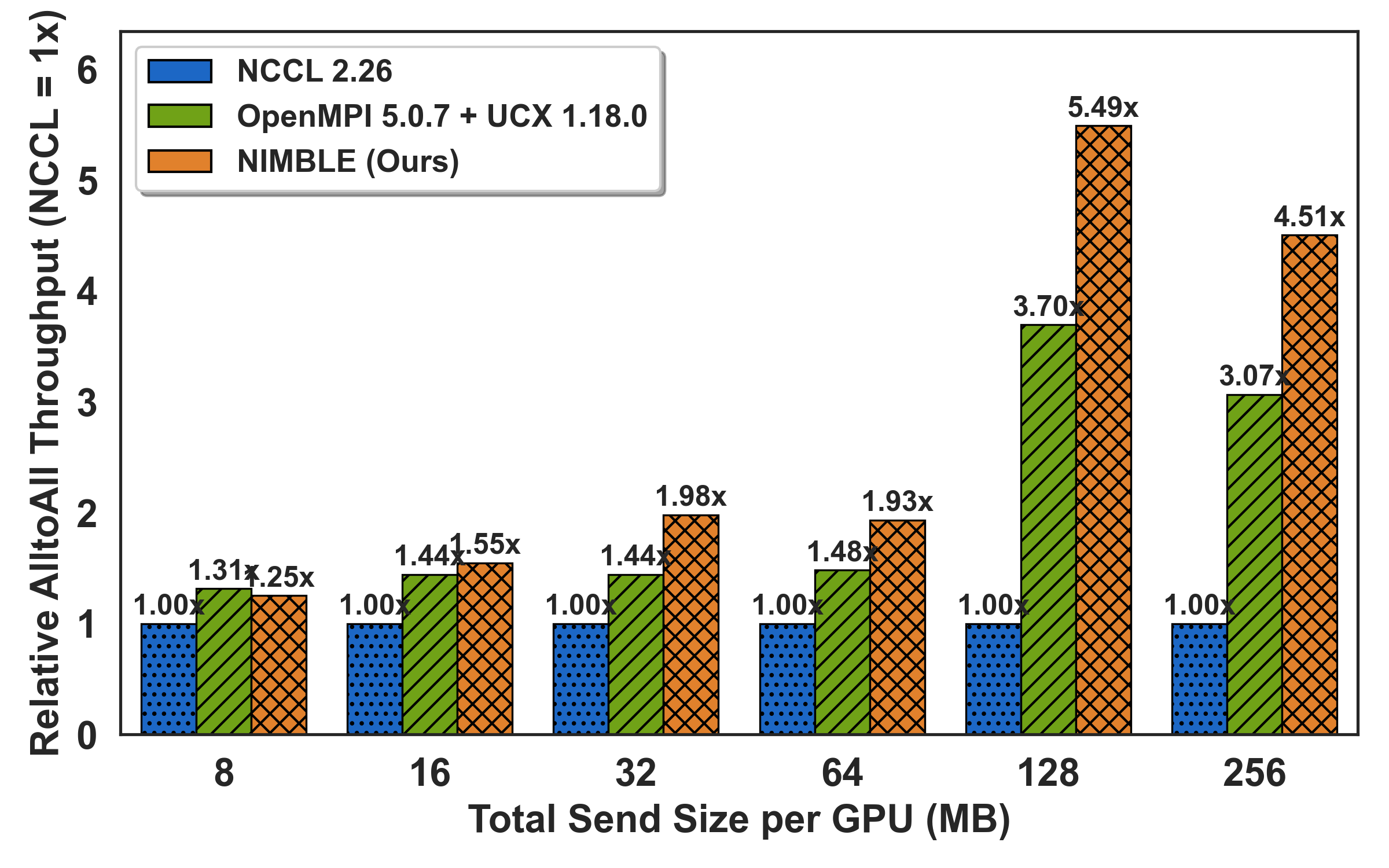
Figure 6: All-to-allv under controllable skew level; throughput gains with higher hotspot ratios via dynamic load rebalancing.
For step-level breakdown in LLM MoE inference/training (8 expert devices split over 2 nodes; up to 64k tokens per batch), measured improvements are substantial. With high token counts and skew, NIMBLE provides a consistent 1.13×–1.35× reduction in total iteration time, with compute held constant and all gains attributed to reduced dispatch and combine (all-to-allv) communication time.
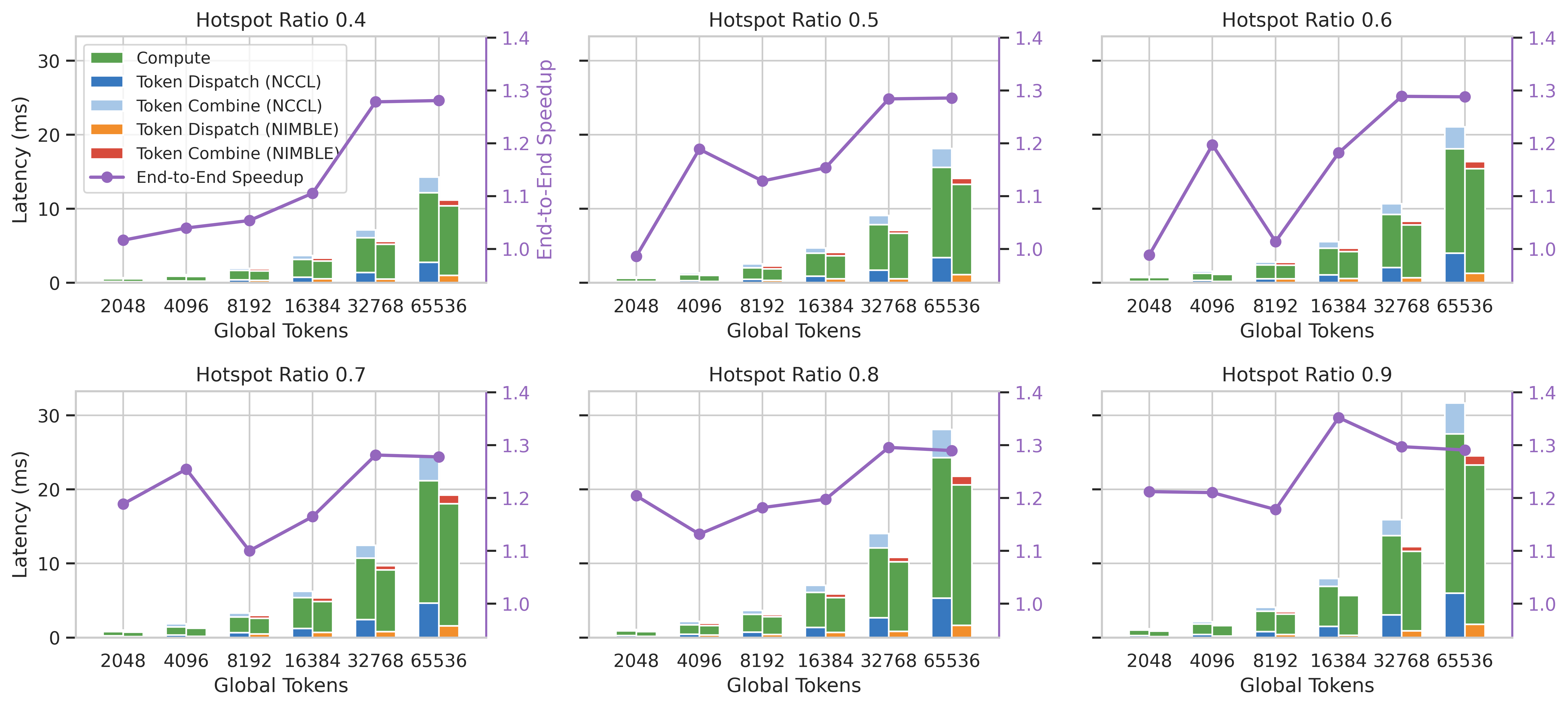
Figure 7: MoE end-to-end step latency with NCCL (left bars) vs. NIMBLE (right bars); NIMBLE yields large reductions in communication-dominated phases, especially with high skew/token count.
Notably, for mildly skewed/small payloads, NIMBLE defers multi-path orchestration to match or slightly underperform efficient DMA-based libraries (OpenMPI), reflecting precise policy gating.
Unlike framework-level topology-aware collectives synthesis (TACCL) or static transport-layer multi-rail (MPI/UCX, PXN in NCCL), NIMBLE provides runtime, endpoint-centric, communication-pattern-agnostic orchestration with global link monitoring and fast-enough optimization for millisecond-level workloads. Previous approaches either require offline profiling, static algorithm synthesis (TACCL), or fail to reslice workloads with changing skew, and do not target general point-to-point or dynamically routed collectives.
NIMBLE augments current congestion control (e.g., DCQCN, HPCC) by minimizing in-job bottlenecks and is orthogonal to inter-tenant fairness or global scheduling.
Limitations and Applicability
NVSwitch-based systems (e.g., 8-GPU DGX with central switch) do not expose all-to-all direct links for intra-node forwarding—here, only multi-NIC forwarding is meaningful. For workloads where collectives are already balanced (e.g., AllReduce, ReduceScatter), NIMBLE defers to established algorithms.
Implications and Future Directions
NIMBLE demonstrates that endpoint-transparent, dynamically load-aware multi-path traffic engineering can critically advance throughput and scalability for skewed and irregular HPC/AI workloads. As application collectives (especially in LLMs with dynamic MoE routing) exhibit larger and less predictable skews, practical distributed training and inference will increasingly require such mechanisms.
Future work includes enhanced orchestration engines further reducing overhead for sub-millisecond messages, closer integration with transport congestion measures, and kernel-based GPUDirect Async (IBGDA) orchestration to enable even lower-latency, lower-involvement data path scheduling.
Conclusion
NIMBLE introduces a runtime, link-aware, endpoint-driven approach to orchestrate and balance communication traffic in GPU clusters with heterogeneous fabrics. It efficiently addresses communication imbalance, yields strong empirical speedups for both microbenchmarks and realistic workloads, and integrates seamlessly with existing software. As the diversity and complexity of production cluster fabrics and AI workloads expand, adaptive runtime orchestration as realized in NIMBLE stands to become foundational for scalable multi-node deep learning and scientific computing.