- The paper presents CCCL, a drop-in, NCCL-compatible library that integrates an in-GPU lossless compression module to reduce communication overhead.
- The methodology leverages localized exponent frequency estimation and single-pass compression to achieve up to 70% data reduction with over 20% throughput gain.
- Empirical evaluations show up to 10.1% end-to-end throughput improvements and 3× effective bandwidth on modern GPUs, highlighting its practical impact.
Compression-Coupled Collective Communication: The CCCL Framework
Introduction and Motivation
Distributed training and inference for LLMs are increasingly bottlenecked by collective communication overheads due to the growing gap between rapid hardware compute and more constrained interconnect bandwidths. Application-level attempts to overlap computation and communication generally demand extensive code changes and are infeasible for paradigms like tensor or expert parallelism. The paper introduces CCCL, a drop-in, NCCL-compatible collective communication library that transparently integrates an in-GPU, high-throughput, lossless compression module to mitigate communication bottlenecks without requiring user-side code modification (2604.17172). CCCL compresses data on the sender and decompresses at the receiver, overlapping these operations with data transfer and utilizing otherwise idle GPU SMs during communication.
Profiling large-scale LLM training reveals an average 20% communication–computation overlap ratio (Figure 1), confirming the chronic underutilization of compute during communication phases. Prevailing collective communication primitives such as NCCL, while offering simplicity and portability, are constrained by coarse-grained kernel launches and lack of fine-grained coupling with computation. Recent efforts that bypass NCCL for custom co-scheduling achieve higher overlap but at the cost of architecture-specific, non-portable code, burdening system maintainability.
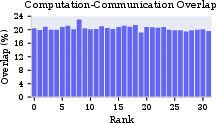
Figure 1: The Comm-Comp Overlap Ratio is low, demonstrating diminished overlap and substantial idle GPU resource during collective communication.
CCCL System Architecture
CCCL merges a GPU-native compression engine (CCCL-core) directly into the data path of collective communication. The architecture (see incorrect Figure 2, not shown in this essay due to paper's note) comprises two decoupled but composable layers:
- CCCL-core: A high-throughput, exponent-focused, lossless compression library operating entirely on the GPU. By leveraging the skew in exponent distributions in typical ML tensors, CCCL-core achieves compression ratios up to 70% with throughput that matches or surpasses NVLink bandwidth.
- Compression–communication co-design: Integrates CCCL-core with NCCL’s pipeline at the kernel level. Data to be transferred across GPUs is compressed within the GPU, transmitted over bandwidth-constrained links, and decompressed (again in-GPU) at the destination, maximizing overlap with ongoing computation.
Compression Algorithmic Pipeline
CCCL-core advances over naive GPU compression by localizing frequency estimation for exponent components within tensor blocks, thereby eliminating the need for costly global memory passes and synchronization. Each GPU thread block samples its assigned tensor block, constructs a local frequency table, and performs compression using that table. This localized approach achieves a negligible drop (<7%) in compression ratio relative to global frequency estimation but increases throughput by over 20% compared to prior GPU exponent compressor baselines such as DietGPU.
Instead of three global memory scans typical in baseline GPU compression (for frequency counting, block-wise compression, and output coalescing), CCCL-core performs all operations in a single global memory pass, writing compressed data directly into the final communication buffer. This design is critical to sustaining compression throughput at or above interconnect rates, thereby enabling computation–communication overlap in distributed training workloads.
Integration with NCCL and Collective Communication
Compression and decompression kernels are fused into the collective communication path at the level of NCCL’s CopyReducePacks function, which processes 128×8×256-element segments. At warp granularity, these kernels operate independently, mirroring NCCL’s own warp-cooperative primitives, thus ensuring cross-generational GPU portability.
Compression is selectively applied:
- All inter-GPU transfers are compressed; intra-GPU transfers remain uncompressed.
- For multi-stage collectives (e.g., ring-based all_reduce), only remote data in each stage undergo decompression and recombination, with local GPU-resident data bypassing decompression.
- Data-aligned blocks are compressed; remaining tail data are transmitted uncompressed to avoid costly corner-case synchronization.
This careful selection avoids unnecessary compute overhead while maximizing the reduction in communication volume.
Empirical Results
Application-Level Evaluation: vLLM Parameter Disaggregation
Evaluating CCCL within vLLM parameter disaggregation (PD) workloads demonstrates up to 10.1% end-to-end throughput improvement over standard NCCL, with microbenchmarks reporting bandwidth increases of up to 30%. These application-level improvements align with the fraction of total execution time attributable to communication (e.g., for sequence length 7,680 tokens, KV cache transfer constitutes 23% of execution time).
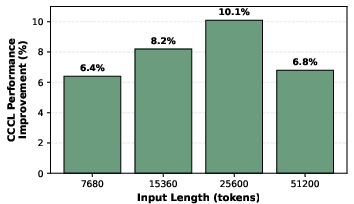
Figure 3: PD Disaggregation – CCCL achieves notable throughput improvement in distributed inference, especially reducing KV cache transfer latency.
Primitive Benchmarks: Send/Recv, Alltoall, Allreduce
- Send/Recv: CCCL outperforms standard and configuration-matched NCCL by >20% for transfers >32MB, with incremental overhead for smaller transfers where communication time is dominated by kernel launch latency (Figure 4).
- Alltoall: CCCL achieves ~18% gain for large messages, attributed to the compounded benefit across aggregated send/recv operations (Figure 5).
- Allreduce: CCCL currently incurs overhead for this pattern due to compounded compression/decompression at each collective stage. Each GPU in ring-style allreduce must compress and decompress $2k$ times for k peers, and gains from reduced data volume are counteracted by incomplete overlap due to architectural limitations.
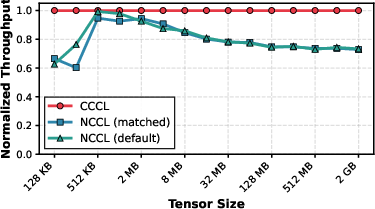
Figure 4: Send/Recv primitive benchmark – CCCL yields consistent bandwidth improvements across message sizes above 32MB.
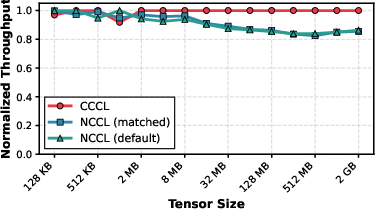
Figure 5: Alltoall primitive – CCCL demonstrates reduced communication latency but with diminishing returns versus send/recv due to increased coordination overhead.
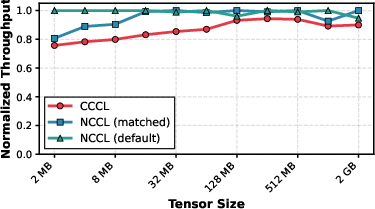
Figure 6: AllReduce – CCCL exhibits performance degradation, especially as the number of stages increases, highlighting compression overlap challenges.
Microbenchmarks without communication overlap show CCCL-core can achieve up to 1300 GB/s on H200 (and 700 GB/s on A100), 3× and 2× higher than measured NVLink bandwidth, indicating substantial headroom for further overlap/optimization (Figure 7, Figure 8, Figure 9).
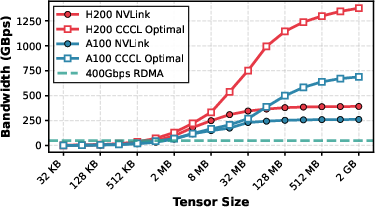
Figure 7: Measured optimal NVLink bandwidth for CCCL shows up to 3× improvement above the effective unconstrained NVLink rate on H200.
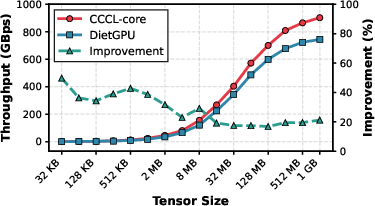
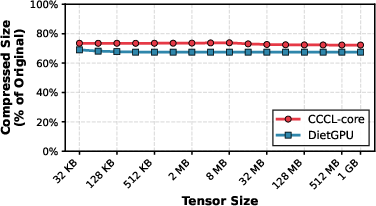
Figure 8: H200 microbenchmark throughput for CCCL achieves 1300 GB/s for 2GB messages, demonstrating significant bandwidth headroom.
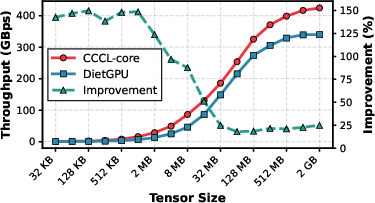
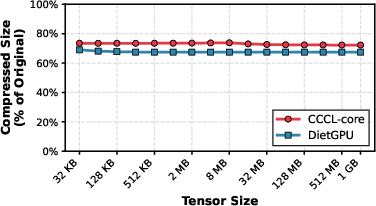
Figure 9: A100 throughput for CCCL reaches 700 GB/s, validating the portability and performance gain across architectures.
Compression ratio remains robust at all scales (<7% regression vs. global estimation baseline, DietGPU), and throughput is superior (minimum 18% gain for 128MB sizes). These trends are architecture-agnostic, indicating broad applicability on modern NVIDIA GPUs.
Implications and Prospects
Theoretically, CCCL demonstrates that in-GPU, lossless compression leveraging exponent distribution can seamlessly integrate with collective communication. Practically, CCCL offers immediate performance improvements in production LLM inference and training workloads, as demonstrated by integration with vLLM parameter disaggregation. Its transparent compatibility with existing NCCL APIs vastly reduces adoption friction relative to hand-coded communication overlap solutions. The realized bandwidth utilization (up to 3× effective NVLink) challenges the prevailing notion that only device interconnects—or application-level kernel fusion—can close communication–computation gaps.
Further, CCCL exposes the limitations of allreduce pattern optimization when frequent, repeated compression/decompression is mandatory. Addressing this with hardware scheduling improvements (warp specialization or CUDA graph integration) presents an avenue for future work towards near-perfect overlap.
Potential advances include:
- Automatic, hardware-aware adaptation of compression parameters for heterogeneous links and collective stages.
- Lossy compression extensions for even more aggressive volume reduction with minimal error accumulation in less-sensitive update exchanges.
- Tight integration with emerging ML framework schedulers to holistically co-optimize communication, computation, and memory scheduling.
- Application to mixture-of-experts, expert parallelism, and fine-grained pipeline parallel contexts where communication is an even more dominant bottleneck.
Conclusion
CCCL demonstrates that integrating high-throughput, exponent-focused lossless compression within the GPU’s collective communication path can greatly alleviate communication bottlenecks in distributed LLM workloads. By tightly coupling compression and collective transmission—without sacrificing compatibility or programmability—CCCL achieves up to 3× effective bandwidth and double-digit throughput gains in practice. These results strongly motivate further research into computation–communication co-design, particularly leveraging idle in-GPU resources and asynchronous kernel scheduling, as fundamental principles for future distributed ML systems evolution.