CuRast: Cuda-Based Software Rasterization for Billions of Triangles
Abstract: Previous work shows that small triangles can be rasterized efficiently with compute shaders. Building on this insight, we explore how far this can be pushed for massive triangle datasets without the need to construct acceleration structures in advance. Method: A 3-stage rasterization pipeline first rasterizes small triangles directly in stage 1, using atomicMin to store the closest fragments. Larger triangles are forwarded to stages 2 and 3. Results: CuRast can render models with hundreds of millions of triangles up to 2-5x (unique) or up to 12x (instanced) faster than Vulkan. Vulkan remains an order of magnitude faster for low-poly meshes. Limitations: We currently focus on dense, opaque meshes that you would typically obtain from photogrammetry/3D reconstruction. Blending/Transparency is not yet supported, and scenes with thousands of low-poly meshes are not implemented efficiently. Future Work: To make it suitable for games and a wider range of use cases, future work will need to (1) optimize handling of scenes with tens of thousands of nodes/meshes, (2) add support for hierarchical clustered LODs such as those produced by Meshoptimizer, (3) add support for transparency, likely in its own stage so as to keep opaque rasterization untouched and fast. Source Code: https://github.com/m-schuetz/CuRast


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces CuRast, a super-fast way to draw 3D models made of triangles using the GPU in a different way than usual. Instead of relying on the GPU’s built‑in “drawing pipeline,” it uses general‑purpose GPU computing (CUDA) to “paint” triangles onto the screen with custom code. The goal is to render massive models—hundreds of millions to billions of triangles—in real time, without needing long, time‑consuming setup steps.
What questions did the researchers ask?
They mainly asked:
- Can we render huge triangle models really fast using software on the GPU (CUDA), without building special helper structures (like LODs or spatial trees) ahead of time?
- Can we make small, pixel‑sized triangles extremely fast while still handling medium and big triangles well enough?
- Can we beat (or at least rival) the speed of modern graphics pipelines (like Vulkan) for the kinds of scenes that have tons of tiny triangles?
How does it work? (Simple explanation of the method)
Think of the screen as a giant grid of pixels. Each triangle is like a sticker you place on that grid. If two stickers overlap, the one closer to the camera should show.
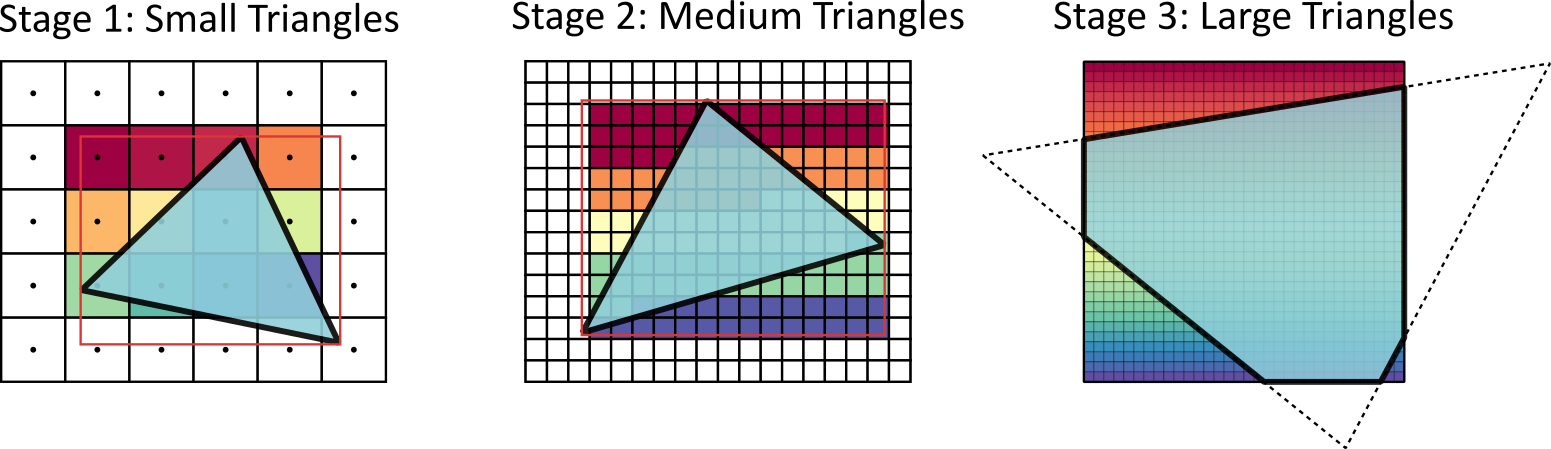
CuRast “paints” triangles using three stages, choosing the best approach depending on how big each triangle looks on the screen:
- Stage 1 (small triangles): One tiny worker handles one triangle at a time. This is super fast when triangles are tiny—like sprinkling pixel‑sized confetti.
- Stage 2 (medium triangles): A small team of workers shares a triangle, splitting the work so it finishes quickly.
- Stage 3 (large triangles): A larger team paints a triangle in chunks (tiles), making sure even giant triangles get done efficiently.
Key ideas explained simply:
- “Closest pixel wins” rule (atomics): When two triangles try to paint the same pixel, the GPU uses a built‑in rule so only the closest one sticks. This avoids arguing and makes the process fast and safe.
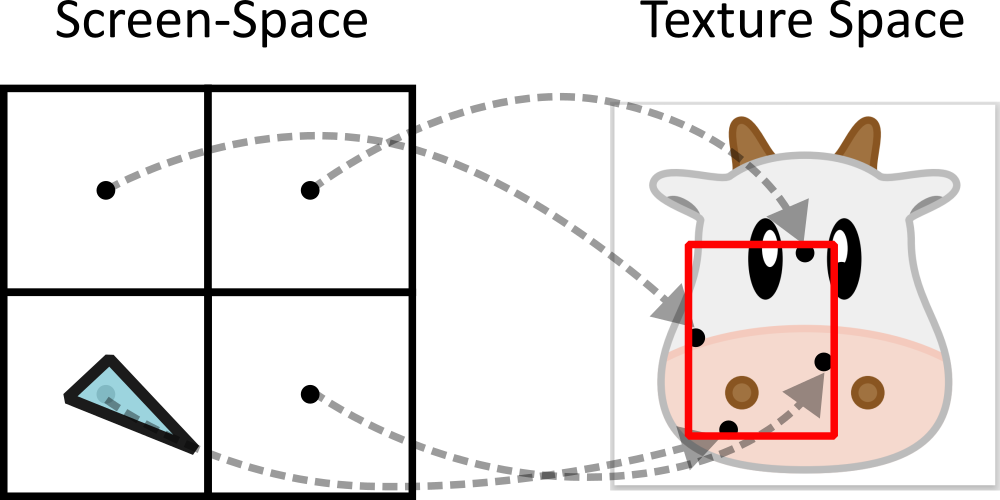
- “Visibility buffer”: Instead of storing full color and material details during painting, CuRast first stores “which triangle is in front for each pixel.” Later, in a separate pass, it looks up that triangle’s information (like texture) and shades the final color. This saves time and memory while drawing.
- No prebuilt acceleration structures: Many systems need hours of pre‑processing to build special data for skipping hidden details. CuRast skips that step, so it’s great for models that change often (like when editing or animating).
- Instancing: If the same object appears many times (like a lantern placed thousands of times), CuRast loads its triangle data once and reuses it, saving bandwidth.
- Compression: To fit giant scenes in GPU memory, positions are stored in 16‑bit fixed precision (good enough for millimeter‑level detail in many cases), and triangle indices are packed tightly so they take up fewer bits.
What did they find?
- For huge, dense models (lots of tiny triangles), CuRast is much faster than the standard Vulkan pipeline:
- About 2–5× faster for unique (non‑repeated) geometry.
- Up to about 12× faster when the same mesh is reused many times (instanced).
- For simple, low‑poly scenes (like the Sponza demo with big triangles and many separate parts), Vulkan is still much faster—about 7–13× faster. CuRast focuses on heavy, detailed geometry, not lightweight scenes with many small objects.
- Real‑world stress test: They rendered a massive scene (“Zorah”) with 18.9 billion triangles total (about 13.5 billion visible) at 4K resolution in roughly 67 milliseconds per frame on a top‑end GPU. The data (38.8 GB) was compressed to 21.7 GB and loaded to the GPU in around 6.6 seconds.
- Mesh optimization tools (which reorder triangles/vertices to improve memory access) help both Vulkan and CuRast, but they help Vulkan more. Even so, for big dense scenes CuRast remains faster.
- On the very latest GPUs, some traditional methods got faster, but CuRast still shines for the target cases.
Why this matters:
- It proves that a compute‑based, software‑style renderer can be ridiculously fast for certain types of scenes—especially scans or reconstructions with tons of tiny triangles—without the usual heavy pre‑processing.
Why is this important? (Implications and impact)
- Great for 3D scans, photogrammetry, and content creation tools: If you’re reconstructing real‑world objects from photos or editing huge meshes in tools like Blender, you often change the model a lot. CuRast avoids slow pre‑processing, so you can edit and view massive models more interactively.
- Handles billions of triangles in real time: This opens the door to smoother workflows for massive datasets that used to be too slow or needed lots of prep work.
- Not ready for all games (yet): Typical games have thousands of small, separate objects and often need transparency and special effects. CuRast currently focuses on dense, opaque meshes and doesn’t support transparency.
- Future improvements planned:
- Better handling of scenes with tens of thousands of separate meshes.
- Support for efficient “levels of detail” (so distant objects cost less to draw).
- Support for transparency without slowing down opaque rendering.
In short: CuRast shows that for the right kind of scenes—huge, dense triangle data—it’s possible to draw incredibly complex models at high speed using a custom CUDA pipeline, sometimes far faster than traditional graphics pipelines. This can make building and exploring massive 3D worlds much more practical.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each point highlights a concrete direction for future research or engineering work.
- Transparency and blending are unsupported; identify and implement an order-independent transparency strategy (e.g., weighted blended OIT, per-pixel linked lists, A-buffer) compatible with 64-bit atomicMin and quantify performance/memory trade-offs.
- Poor scaling for scenes with tens of thousands of low-density meshes; design a pipeline that efficiently handles many small drawables (batching, per-mesh/instance queues, GPU-side culling, and scheduling).
- Lack of hierarchical LOD integration; develop clustered/meshoptimizer-style LOD selection and switching policies suitable for a compute rasterizer, including dynamic updates without costly preprocessing.
- Large-triangle handling in Stage 3 relies on per-pixel world-space ray-triangle tests; explore more efficient coverage methods (clipping, edge functions with robust near-plane handling, tile-edge coverage tests) and assess accuracy/performance.
- Near-plane clipping is only approximated (accurate bbox only in Stage 2, no real clipping); implement robust triangle clipping across stages and evaluate its cost vs. Stage 3 fallback.
- Stage thresholds (≤128 px small, ≤4096 px medium) are heuristic; devise adaptive, hardware- and workload-aware thresholding and tile sizing, with a self-tuning strategy based on runtime telemetry.
- Visibility buffer bit allocation (28-bit depth, 36-bit triangle ID) is fixed; analyze precision/robustness across extreme depth ranges, sensitivity to z-fighting, and alternative encodings (log depth, configurable bit budgets, 96/128-bit atomics when available).
- Resolve pass locality is potentially poor (per-pixel binary search into a global prefix sum and random triangle fetches); investigate cache-friendly screen- or tile-space reordering, per-tile compaction, two-level indexing (mesh ID + local tri ID), and other data layouts to improve memory coherence.
- Compute cost in resolve is high for mip selection (four ray-plane intersections per pixel); explore cheaper approximations (screen-space derivatives, precomputed per-triangle gradients, hybrid rules near the near plane) with error/perf analysis.
- Anti-aliasing is not addressed; evaluate MSAA-like coverage masks, stochastic AA, or temporal AA integration with visibility buffers and atomicMin constraints.
- No anisotropic filtering or ddx/ddy-based texture filtering support; determine how to compute reliable derivatives in a compute/visibility-buffer pipeline and compare with hardware samplers.
- No occlusion culling beyond atomicMin; examine hierarchical Z (HZB) or coarse depth tiles to skip rasterization of fully occluded triangles, especially in high overdraw scenes.
- Load balancing and contention under extreme overdraw are not characterized; measure atomicMin contention patterns and test triangle ordering/screen-tiling strategies to reduce hot-pixel conflicts.
- Instancing is only optimized in Stage 1 and increases register pressure; design low-overhead instancing paths across stages (e.g., per-triangle shared data, instance bucketing, or kernel variants) and GPU-side per-instance frustum culling.
- Compression choices (16-bit fixed-point positions, variable-bit indices) lack a quality/error study; quantify geometric error, visual artifacts (especially near the camera), and the impact on shading/LODs; explore adaptive precision and on-the-fly encode/decode costs.
- Out-of-core streaming is briefly demonstrated (6.6 s load+compress), but no runtime streaming/eviction policy is presented; design asynchronous streaming, prioritization, and residency management for geometry and textures under tight VRAM budgets.
- Portability is limited to CUDA/NVIDIA; assess feasibility and performance on other backends (HIP, Vulkan/DirectX compute, Metal) and the availability/speed of 64-bit atomics across vendors.
- Evaluation scope omits comparisons with other visibility-buffer or software rasterizers (e.g., CUDARaster/Nanite-like paths) and lacks a Vulkan visibility-buffer baseline; conduct fair, like-for-like comparisons including resolve costs.
- Energy efficiency and thermal behavior under heavy atomics/compute are unmeasured; profile power/perf (perf/W) and explore energy-aware scheduling.
- Scalability with framebuffer resolution (e.g., 8K) and multi-sampling is not evaluated; characterize performance/memory scaling and adapt visibility buffer formats accordingly.
- CPU/GPU division of labor (CPU-side frustum culling, host-side mesh prefix sums) may bottleneck scenes with many nodes; prototype GPU-based culling and prefix-sum computation, and quantify latency/overhead trade-offs.
- Determinism and tie-breaking with equal-depth fragments are unspecified; define a deterministic policy (e.g., triangle ID priority) and assess artifact risks with quantized depth.
- Animated/skinned meshes are not tested; extend pipeline to dynamic per-vertex transforms, evaluate performance for animated content, and study implications for any future LOD/instancing schemes.
- Texture subsystem details (JPEG decode in CUDA) lack a general framework; generalize to diverse compressed formats (BCn/ASTC/ETC), explore hardware-accelerated decode paths, and quantify decode overhead vs. sampling quality.
- Memory footprint of visibility buffers at high resolutions and with MSAA is not discussed; analyze VRAM usage and evaluate compression or alternative encodings to keep memory in check.
- Mesh/triangle ordering for CuRast is only modestly explored; investigate screen-space or tile-space orderings tailored for atomicMin to maximize cache coherence and minimize pixel contention.
- Stage 3 tile size (64×64) is fixed; study adaptive tile sizes and workgroup shapes relative to triangle size/aspect to reduce underutilization and improve coherence.
- Robustness to degenerate/near-degenerate triangles and extreme aspect ratios is not examined; implement guards and test numerically stressful cases (very thin triangles, huge depth ranges).
- Integration with advanced lighting (shadows, PBR, deferred/clustered lighting) is not detailed; design a shading pipeline that marries visibility buffers with modern material graphs and measure end-to-end performance.
Practical Applications
Immediate Applications
These applications can be deployed now using the paper’s open-source code (CuRast) and the described methods, with light engineering for integration.
- Massive photogrammetry/scan viewer for dense opaque meshes
- Sectors: VFX, cultural heritage, surveying, digital twins (urban), AEC field capture
- What: A workstation or kiosk viewer that loads tens of GB of dense triangle meshes from NVMe, compresses/quantizes on the fly, and renders billions of triangles in real time without precomputed LODs or acceleration structures.
- Tools/workflows: Standalone CuRast-based “GigaMesh” viewer or a DCC plug-in (e.g., Blender viewport mode) that uses the 3-stage rasterization, visibility buffer, and compression (variable-bit indices, 16-bit positions).
- Assumptions/dependencies: NVIDIA CUDA-capable GPU with fast 64-bit atomics (RTX-class recommended), fast NVMe SSD, opaque geometry (no transparency), scenes skewed toward dense meshes with pixel-size triangles; VRAM capacity dictates compression and streaming strategy.
- On-set/field QC for 3D scanning and virtual production
- Sectors: Virtual production, AEC site capture, UAV photogrammetry
- What: Immediate visual validation of high-res scans (e.g., 20–40 GB) on a laptop/workstation in seconds (e.g., 6–7 s in the paper), enabling rapid decision-making without long LOD preprocessing.
- Tools/workflows: Integrate CuRast into scanning pipelines (RealityCapture/RealityScan → CuRast QC viewer) for instant preview before further processing.
- Assumptions/dependencies: Same as above; can tolerate lack of transparency; field hardware must have a capable NVIDIA GPU.
- Server-side high-throughput renders for asset catalogs and archives
- Sectors: 3D marketplaces, museums/archives, digital twin platforms
- What: Headless, containerized microservice that renders turntables/thumbnails or on-demand views of massive scanned assets; avoids LOD building and reduces operational latency.
- Tools/workflows: CuRast as a service (gRPC/REST) rendering to images/streams; frame streaming via WebRTC/VNC; autoscaling per GPU.
- Assumptions/dependencies: NVIDIA GPUs in the datacenter; opaque models preferred; request routing and caching around camera paths; bandwidth to transfer frames.
- Instanced-scene preview at extreme scale
- Sectors: DCC set dressing, vegetation scattering, product catalogs, manufacturing
- What: Interactive preview of scenes with millions of triangles per mesh and thousands of instances (billions of triangles total), benefiting from the stage-1 instancing optimization.
- Tools/workflows: CuRast instancing path for one-to-many transforms; scene graph that submits one geometry with many instances.
- Assumptions/dependencies: Best when each base mesh is dense; identical geometry across instances; opaque materials.
- Synthetic data generation (depth and IDs) from large scans
- Sectors: Robotics, autonomous driving, computer vision
- What: Rapid generation of ground-truth depth and per-triangle/per-instance IDs via the visibility buffer for segmentation, occlusion, and depth maps from dense environments.
- Tools/workflows: Render scripted camera paths to depth/ID buffers; map triangle IDs to instance/semantic labels; export masks and metadata.
- Assumptions/dependencies: Opaque surfaces; semantic ID mapping pipeline; NVIDIA GPU.
- Texture-on-demand via in-kernel JPEG decoding for large textures
- Sectors: Graphics software, digital twins, visualization platforms
- What: Render scenes with very high-resolution textures that don’t fit in VRAM by decoding only visible JPEG blocks during the resolve pass.
- Tools/workflows: Integrate CuRast’s JPEG-block indexing/decoding in shading; pair with visibility buffer to fetch only needed texels.
- Assumptions/dependencies: Textures stored as JPEG; CUDA-capable JPEG decode on GPU; minor latency from per-block decode acceptable.
- Asset packaging with lightweight geometry compression
- Sectors: Content pipelines, 3D data distribution
- What: Reduce memory and I/O by quantizing positions to 16-bit fixed precision per-mesh and compressing indices to the minimum bit-width required by index span.
- Tools/workflows: Pre-export step that computes per-mesh bounds and index spans; stores scales/offsets for decode in kernels; optional dual-path kernels (compressed/uncompressed).
- Assumptions/dependencies: Acceptable precision loss (e.g., 1 mm for 65 m span); encode/decode logic integrated into tools; compressed indices not directly compatible with standard 16/32-bit indexed draws.
- Teaching and research testbed for software rasterization at scale
- Sectors: Academia, training, graphics R&D
- What: Use CuRast as an open, reproducible platform to study atomics-based rasterization, visibility buffers, persistent kernels, and mip mapping in world space on massive datasets.
- Tools/workflows: Course labs comparing compute vs hardware pipelines; research into load balancing, culling, compression.
- Assumptions/dependencies: NVIDIA GPUs; access to large datasets; tolerance for opaque-only constraints.
Long-Term Applications
These applications require additional R&D (e.g., scaling to many low-density meshes, transparency, cross-vendor support) before broad deployment.
- Game engine integration for micropolygon-heavy content
- Sectors: Gaming, real-time engines
- What: A Nanite-like path that uses CuRast’s compute rasterizer for pixel-sized triangles but adds support for hierarchical clustered LODs, scene graphs with tens of thousands of nodes, and a dedicated transparency stage.
- Tools/workflows: Hybrid renderer switching between compute rasterization and hardware depending on triangle size; vis-buffer resolve with material graph integration.
- Assumptions/dependencies: New stage for transparency; cluster/LOD build pipeline (e.g., Meshoptimizer clusters); cross-vendor compute backend (Vulkan/DX12/HIP).
- CAD/BIM/GIS visualization with many low-density meshes
- Sectors: AEC, GIS, infrastructure digital twins
- What: Extend pipeline scalability to tens of thousands of coarse meshes (buildings, parts) via improved batching, node-level culling, and coarse-grained scheduling.
- Tools/workflows: Scene-graph aware persistent kernels; batched draws by material/mesh families; hierarchical culling.
- Assumptions/dependencies: Algorithmic changes to address current scaling limitations for low-density mesh counts; feature parity with CAD materials; transparency for glass.
- AR/VR viewing of city-scale scans
- Sectors: AR/VR, urban planning, digital heritage
- What: Low-latency, foveated compute rasterization for photogrammetric cities in headsets; streaming high-detail periphery on demand.
- Tools/workflows: Eye-tracking–driven variable-rate shading in compute; asynchronous time-warp; GPU-side LOD streamers.
- Assumptions/dependencies: Significant optimization for latency; mobile/standalone headsets require non-CUDA paths; transparency and antialiasing support.
- Hybrid renderers combining compute, hardware rasterization, and splats
- Sectors: Game/film engines, visualization
- What: Dynamically choose between CuRast for dense triangles, hardware for large/low-density meshes, and 3D Gaussian splats/points for certain content.
- Tools/workflows: Runtime scheduler based on primitive size and material; unified visibility and shading interfaces.
- Assumptions/dependencies: Complex orchestration and compositing; consistent material/shading across paths; transparency handling.
- Multi-GPU and distributed trillion-triangle visualization
- Sectors: Cloud visualization, HPC, national archives
- What: Partition screens/geometry across GPUs or nodes (sort-first/last) with parallel visibility buffers and fast compositing; interactive city or country-scale models.
- Tools/workflows: NVLink-aware tiling; RDMA-based compositing; cluster scheduling; out-of-core geometry streaming.
- Assumptions/dependencies: High-bandwidth interconnects; robust load balancing; fault tolerance.
- Sensor-accurate simulators for robotics and AV
- Sectors: Robotics, autonomous systems, simulation
- What: Extend resolve stage to simulate LiDAR returns, RGB-D sensors, and material-dependent effects over dense meshes; generate multi-modal ground truth.
- Tools/workflows: Add per-hit material queries, BRDFs, and temporal effects; integrate translucency and reflective materials.
- Assumptions/dependencies: Transparency/blending stage; physically based shading; deterministic timing for closed-loop sim.
- Public-sector remote visualization portals for massive 3D scans
- Sectors: Government, policy, cultural heritage access
- What: Citizen-facing portals that stream interactive views of large 3D reconstructions (cities, artifacts) rendered server-side on GPUs.
- Tools/workflows: Cloud-hosted CuRast clusters; access control, caching, and progressive camera-path streaming.
- Assumptions/dependencies: Privacy and data governance; operational costs; network bandwidth; multi-tenant fairness.
- Cross-vendor portability and mobile-class deployment
- Sectors: Software, mobile XR
- What: Port the pipeline to Vulkan/DX12 compute or HIP to support AMD and mobile GPUs; explore subgroup operations for atomics and depth updates.
- Tools/workflows: Backend-abstraction layer; performance tuning per architecture; feature probes for 64-bit atomics and subgroup capabilities.
- Assumptions/dependencies: Platform differences in atomicMin performance; potential redesign for memory and wavefront sizes.
- High-throughput offline baking and map generation
- Sectors: Games, VFX, DCC
- What: Use the compute rasterizer to accelerate baking (normals, AO, ID maps) from ultra-high-poly sources onto target assets without LOD preprocessing.
- Tools/workflows: Batch baking service that leverages visibility buffer and world-space shading; integration with DCC bake pipelines.
- Assumptions/dependencies: Additional passes for AO/occlusion rays; UV/mip control; non-opaque effects may be needed.
- Incremental editing and streaming of massive meshes
- Sectors: DCC tools, CAD
- What: Editing sessions on huge meshes where geometry changes invalidate LODs—CuRast’s no-precompute pipeline enables immediate viewport updates.
- Tools/workflows: DCC integration that streams deltas; per-mesh recompaction of compressed buffers; fast re-culling.
- Assumptions/dependencies: Efficient editor APIs; improved handling of many scene nodes; optional transparent overlays for selections.
Notes on feasibility across all applications:
- Best performance arises with dense, opaque, triangle-heavy content and significant instancing; scenes dominated by many low-density meshes or transparency currently underperform.
- NVIDIA CUDA dependency is a near-term constraint; cross-vendor adoption needs a compute-port (e.g., Vulkan/DX12/HIP) with comparable 64-bit atomic performance.
- IO and memory bandwidth (NVMe → VRAM) are critical; benefits grow with faster SSDs, larger VRAM, and high memory bandwidth GPUs.
Glossary
- 3D Gaussian Splatting (3DGS): A point-based rendering method that represents scenes with 3D Gaussian primitives and blends them in screen space for high-quality reconstructions. "3DGS proposes using translucent gaussian primitives for scene reconstruction from photos, resulting in high-quality models of the real world."
- acceleration structures: Spatial data structures (e.g., BVH, grids) built to speed up rendering or intersection queries. "without the need to construct acceleration structures in advance."
- atomic-CAS: An atomic compare-and-swap operation used to implement locking or synchronization on the GPU. "first attempts to lock it with atomic-CAS, then updates and subsequently unlocks it."
- atomicMin: An atomic minimum operation that safely updates a shared value (e.g., depth) with the smallest of competing writes. "using atomicMin to store the closest fragments."
- backface culling: Skipping triangles whose orientation faces away from the camera to reduce rasterization work. "followed by performing backface culling."
- barycentric coordinates: A coordinate system for points inside a triangle, used for interpolation and inside-triangle tests. "computes the barycentric coordinates of the triangle"
- coalesced memory access: GPU-friendly memory access pattern where adjacent threads access adjacent addresses to maximize bandwidth. "promote coalesced memory access"
- compute shaders: GPU programs executed in the compute pipeline, often used for general-purpose or custom rasterization tasks. "Previous work shows that small triangles can be rasterized efficiently with compute shaders."
- cooperative groups: CUDA programming construct enabling synchronization and coordination among thread groups. "persistent-kernel launch using cooperative groups"
- deferred rendering: A pipeline that first writes per-pixel attributes to G-Buffers, then performs lighting in a later pass. "such as deferred rendering with rich G-Buffers."
- deferred shading: Performing the shading/lighting step after geometry rasterization using stored per-pixel attributes or IDs. "Visibility buffer rendering and deferred shading with G-Buffers are closely related."
- depth buffer: A per-pixel buffer storing depth values to resolve visibility during rasterization. "the depth buffer"
- exclusive prefix sum: A scan operation producing cumulative totals where each output excludes the current element; used for indexing. "compute a cumulative triangle count for each mesh and instance (i.e. the exclusive prefix sum)"
- eye-dome lighting: A screen-space shading technique that enhances edge contrast in dense geometry or point clouds. "with screen space ambient occlusion and eye-dome lighting enabled."
- frustum culling: Discarding objects or triangles outside the camera’s view volume to avoid unnecessary work. "13.5 billion triangles visible after frustum culling."
- G-Buffers: Geometry buffers storing per-pixel attributes (normals, albedo, etc.) for deferred shading. "Deferred shading creates G-Buffers with various attributes that may be needed for the shading pass."
- GPGPU: General-purpose computing on graphics processing units, using GPUs for non-graphics workloads. "GPGPU-accelerated software rasterization"
- hierarchical levels of detail (LOD): Multi-resolution representations used to render simpler versions of distant or small objects. "without the need to create spatial acceleration structures or hierarchical levels of detail in advance."
- instancing: Rendering many copies of the same mesh efficiently by reusing geometry with different transforms. "Instancing allows us to reduce this bandwidth bottleneck"
- item buffers: Early term for visibility buffers that store per-pixel IDs of first-hit scene elements (in ray tracing). "Visibility buffers were initially introduced under the term item buffers in the context of ray tracing"
- JPEG-compressed textures: Textures stored in JPEG format and decoded at runtime to reduce memory footprint and bandwidth. "j: JPEG-compressed textures."
- meshoptimizer: A toolkit for optimizing mesh data for locality, cache efficiency, and vertex reuse. "Meshoptimizer is an open source project that implements strategies that promote locality and vertex reuse"
- micropolygons: Very small triangles, often around pixel-sized, that stress rasterization throughput. "pure micropolygon geometry."
- mipmap level: The selected resolution level in a mipmapped texture that best matches the pixel’s texture footprint. "determine the mipmap level"
- near plane: The closest clipping plane of the camera frustum; geometry intersecting it needs clipping. "intersects the near plane"
- normalized device coordinates (NDC): The post-projection coordinate space where x,y,z are normalized before viewport transform. "in normalized device coordinates"
- persistent kernel: A GPU kernel that runs persistently, fetching tasks dynamically to improve load balancing. "persistent-kernel launch"
- perspective-correct interpolation: Interpolation of attributes accounting for perspective division to avoid distortion. "For efficient perspective-correct interpolation of depth values"
- photogrammetry: Reconstructing 3D geometry from photographs, often producing dense, detailed meshes. "photogrammetry reconstruction"
- programmable index pulling: Fetching indices in shader code (rather than fixed-function index buffers) for flexible formats or compression. "uses programmable index pulling and vertex pulling."
- ray cast: Tracing a ray from the camera through a pixel to find intersections with geometry. "performs a ray cast in world space"
- ray-triangle intersections: Computing whether and where a ray hits a triangle, typically used for visibility or shading. "ray-triangle intersections in world space"
- resolve pass: A full-screen pass that uses stored per-pixel IDs to fetch attributes and perform shading. "in the full-screen resolve pass"
- screen space ambient occlusion (SSAO): A technique estimating ambient occlusion using depth information in screen space. "with screen space ambient occlusion and eye-dome lighting enabled."
- sort-middle: A graphics pipeline organization that sorts primitives between geometry and rasterization stages. "via a sort-middle approach"
- spin loops: Busy-wait loops used in synchronization patterns, e.g., for atomic locking on pixels. "based on spin loops"
- Sutherland-Hodgman algorithm: A polygon clipping algorithm used to clip triangles against the view frustum. "via the Sutherland-Hodgman algorithm."
- vertex pulling: Fetching vertex attributes directly in shaders, bypassing fixed-function vertex fetching. "uses programmable index pulling and vertex pulling."
- vertex reuse: Reusing transformed vertices to reduce redundant processing and memory access. "vertex reuse mechanisms"
- visibility buffer: A buffer storing per-pixel IDs (mesh/triangle) of the visible surface, deferring attribute fetch and shading. "Visibility buffers only store triangle indices."
- warp: A group of 32 threads executing in lockstep on NVIDIA GPUs. "Launch a warp (32 threads) per triangle"
- workgroup: A set of threads launched together that can cooperate via shared memory and synchronization. "one workgroup comprising 64 threads"
Collections
Sign up for free to add this paper to one or more collections.

