NVGS: Neural Visibility for Occlusion Culling in 3D Gaussian Splatting
Abstract: 3D Gaussian Splatting can exploit frustum culling and level-of-detail strategies to accelerate rendering of scenes containing a large number of primitives. However, the semi-transparent nature of Gaussians prevents the application of another highly effective technique: occlusion culling. We address this limitation by proposing a novel method to learn the viewpoint-dependent visibility function of all Gaussians in a trained model using a small, shared MLP across instances of an asset in a scene. By querying it for Gaussians within the viewing frustum prior to rasterization, our method can discard occluded primitives during rendering. Leveraging Tensor Cores for efficient computation, we integrate these neural queries directly into a novel instanced software rasterizer. Our approach outperforms the current state of the art for composed scenes in terms of VRAM usage and image quality, utilizing a combination of our instanced rasterizer and occlusion culling MLP, and exhibits complementary properties to existing LoD techniques.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making 3D scenes render faster and use less memory on a graphics card, without hurting image quality. It focuses on a popular 3D technique called 3D Gaussian Splatting, which draws scenes using lots of tiny, fuzzy “paint dots” in 3D. The authors add a smart step that skips drawing dots you can’t see anyway because they’re hidden behind other parts of the scene. This skipping is called occlusion culling.
What questions did the researchers ask?
They asked:
- How can we figure out, quickly and accurately, which of those 3D “paint dots” are actually visible from the camera and which are hidden?
- Can we do this in a way that saves a lot of graphics memory (VRAM) and increases frame rate (FPS), especially in big scenes with many repeated objects?
- Can this idea work together with other speed-up tricks, like Level of Detail (LoD), instead of replacing them?
How did they do it? (In simple steps and analogies)
Think of a 3D scene like a stage full of actors (objects), each made of thousands of tiny, semi-transparent confetti dots (Gaussians). When you take a photo, most confetti dots at the back don’t matter because they’re hidden by the ones in front. The trick is to not waste time drawing those hidden dots.
Here’s their approach:
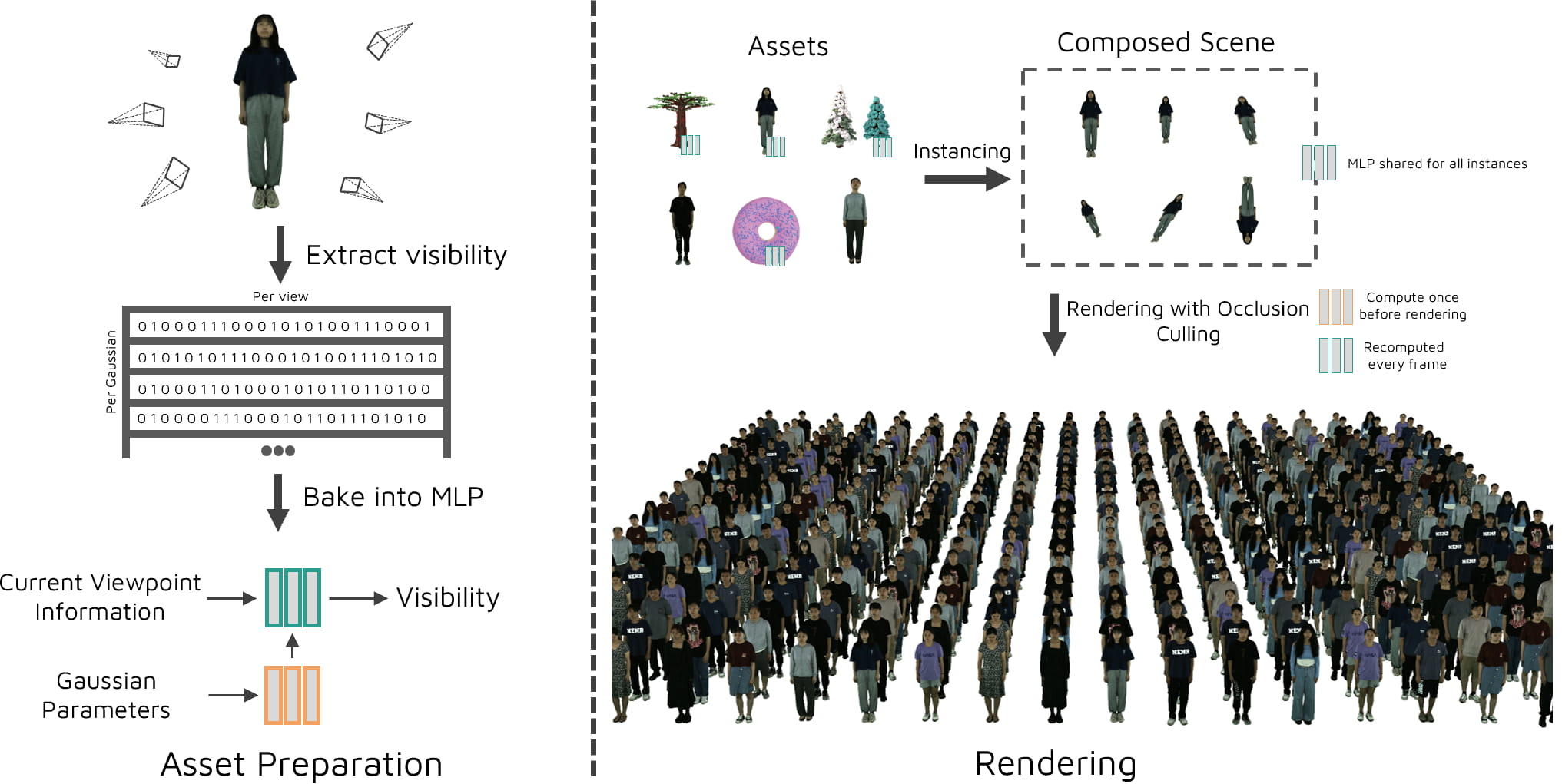
- Step 1: Teach a tiny “visibility judge” to spot hidden dots
- The team shows each object (like a tree or a human) from many camera angles, like walking around it and taking pictures.
- For each dot, they check whether it actually affects the final image from that angle (if it adds visible color or is blocked).
- Using these examples, they train a very small neural network (an MLP) to answer a yes/no question: “From this camera view, is this dot visible?”
- This “visibility judge” is tiny (about 18 KB per object), quick to train (a few minutes per object), and reusable for every copy (instance) of that object in a scene.
- Step 2: Combine the visibility judge with a smart renderer
- Instanced rendering: If your scene has the same tree 100 times, you don’t store 100 separate trees. You store one tree and place it 100 times—this saves memory.
- Frustum culling: Only consider dots inside the camera’s view cone (like not drawing what’s behind the camera).
- Neural occlusion culling: Before actually drawing, ask the tiny neural network which dots are hidden and skip those immediately.
- Only after these quick checks does the renderer “instantiate” and draw the remaining dots. This avoids wasting memory and time on dots that won’t show up.
- They carefully make this run fast on the GPU’s special math units (Tensor Cores), so the neural checks are cheap.
Simple translations of technical terms:
- 3D Gaussian Splatting: Building a 3D scene from many fuzzy dots, which makes rendering fast and flexible.
- Occlusion culling: Don’t draw what’s hidden behind something else.
- MLP (tiny neural network): A small, learned function that answers “Is this dot visible from here?”
- Instancing: Reusing one stored object many times in different places.
- VRAM: The graphics card’s memory.
- FPS: How many frames per second you can render (higher is smoother).
What did they find, and why is it important?
Main results:
- Much lower VRAM use: Their system uses roughly 4× less VRAM than a strong LoD baseline (V3DG) on big, composed scenes. This means you can load and render bigger scenes on the same hardware.
- Faster rendering: They consistently get higher FPS than other methods in close and medium views, and stay competitive at far distances.
- High image quality: Their images closely match the ground truth. The “visibility judge” skips the hidden dots without hurting what you see.
- Scales to huge scenes: They can render scenes with over 100 million dots in real time.
- Tiny and fast-to-train helper: The per-object visibility model is tiny (~18 KB) and takes only a few minutes to train, yet speeds up rendering by culling lots of useless dots.
Why it matters:
- Games, virtual production, and VR often reuse objects many times (trees in a forest, people in a crowd). This method is especially helpful there.
- Saving VRAM is crucial on real hardware. Lower memory use means fewer crashes, more stuff on screen, and smoother performance.
- The method works well alongside Level of Detail. LoD is great when things are far away; neural occlusion culling is great for skipping hidden parts at any distance. Together, they can push performance even further.
What’s the potential impact?
- Faster, smoother 3D experiences: This can help games, AR/VR, and film previsualization run better on the same GPUs.
- Bigger, richer worlds: With less VRAM needed, creators can pack more detail into their scenes.
- Plays well with other tech: Because it complements LoD and doesn’t require changes to how the objects are originally trained, it’s easy to adopt in existing pipelines.
- Opens doors for more advanced lighting and effects: Since the system saves time per dot, future work can spend that time on nicer materials or lighting without slowing everything down.
In short, the paper shows a clever, practical way to skip drawing what you’ll never see, using a tiny learned “visibility judge.” That makes big 3D scenes faster, lighter on memory, and just as beautiful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues and opportunities for future research raised by the paper.
- Scene-level occlusion by other assets is not modeled: the per-asset MLP learns self-occlusion only, leaving occlusion caused by different assets in composed scenes unaddressed. Investigate hybrid pipelines that combine the proposed per-Gaussian visibility with coarse scene-level occlusion queries (hierarchical Z, Hi-Z depth, portals) to cull Gaussians hidden behind other objects.
- Dynamic and deformable assets are unsupported: visibility is learned for rigid, static assets. Extend the approach to animated or deforming assets (e.g., skinned humans), including strategies for per-frame visibility estimation, conditional embeddings keyed on pose, or online adaptation.
- Resolution and aspect-ratio invariance is assumed but not validated: labels are defined per pixel (via ), so visibility depends on pixel footprint. Provide a formal derivation and empirical validation of resolution/FoV corrections across wide camera settings (zoom, aspect ratio), and quantify errors when rendering at resolutions different from training.
- High-frequency visibility patterns and concave geometry: the small MLP may be under-capacity for assets with complex self-occlusion. Quantify sample complexity and model capacity requirements; explore frequency encodings or hierarchical models that preserve Tensor Core efficiency while capturing high-frequency visibility.
- False negative/positive analysis is missing: no confusion matrix or failure-rate bounds are reported for visibility predictions. Establish tolerable error budgets (e.g., transmittance tolerance) that bound FLIP/PSNR degradation; introduce confidence-based gating or conservative guard bands to prevent holes.
- Camera sampling strategy may be mismatched to deployment: training uses uniform distance + Fibonacci sphere + random offset + auxiliary views. Investigate importance sampling driven by expected camera distributions, active sampling to target hard views, and online correction for distribution shift.
- Binary “visible” labeling lacks threshold calibration: “nonzero contribution” is used as the visibility criterion. Define and validate practical thresholds (e.g., contribution < ε) tied to perceptual metrics (FLIP) and rendering budgets; study sensitivity to ε and dynamic thresholds per-distance.
- Generalization across 3DGS variants is untested: evaluate NVGS with Mip-Splatting, StopThePop, PRoGS, alias-free formulations, and varying SH degrees/material models; adapt the visibility definition where covariance or opacity changes with LoD/aliasing.
- Shared models across assets are unexplored: the paper uses one MLP per asset. Test category-level or universal visibility models (conditioned on Gaussian parameters/learned codes) to reduce per-asset training overhead and storage.
- Hardware portability is unknown: results are on an RTX 3090 Ti. Benchmark across diverse GPUs (Ada/Lovelace, mobile SoCs) and investigate performance without Tensor Cores, including CPU fallback paths and memory-bandwidth sensitivity.
- Numerical discrepancies near the near plane persist: observed FLIP spikes (DonutSea) due to rasterizer differences with gsplat. Analyze and resolve near-plane clipping and precision issues; provide equivalence or error bounds relative to gsplat.
- Integration with LoD is only conceptual: occlusion culling and LoD are complementary, but no integrated system is reported. Design a joint scheduler that allocates budgets between MLP queries and LoD levels, especially for far distances where NVGS slows down.
- Scaling beyond ~100M Gaussians lacks comprehensive benchmarks: provide end-to-end FPS/VRAM/quality results on truly full-scale scenes (not downscaled), including streaming scenarios and out-of-core rendering.
- Semi-transparency and partial contributions: the binary visibility decision may discard small but perceptually relevant contributions. Investigate probabilistic visibility (e.g., predicting expected contribution or transmittance margin) and progressive refinement for borderline cases.
- Real-time adaptation to changing zoom/FoV: although FoV correction is proposed, no runtime adaptation strategy is given for rapidly changing camera intrinsics. Validate stability under zoom sweeps and provide robust normalization for extreme FoV values.
- Robustness to 3DGS artifacts: auxiliary views and random offsets help, but their optimal number/magnitude are not studied. Quantify how many auxiliary views/offset ranges are needed per asset to suppress popping/aliasing without excessive preprocessing.
- Heuristic min/max distance selection: using object-diagonal coverage (90%/5%) may be suboptimal for elongated or highly nonconvex assets. Explore data-driven or geometry-aware bounds (e.g., screen-space area targets, convex hulls) and measure impact on accuracy/performance.
- Secondary MLP (per-Gaussian embedding) design space is unexamined: no ablation of embedding dimension, architecture, or encodings. Evaluate alternatives (hashed grids, vector quantization, codebooks) that balance accuracy, memory, and Tensor Core alignment.
- Microarchitectural profiling of the instanced rasterizer is missing: quantify global memory traffic reductions, occupancy, warp divergence, and the overhead vs savings of per-tile instance creation to guide further GPU optimization.
- Failure-case characterization is limited: aside from the near-plane issue, other systematic failures (e.g., deeply concave assets, extreme scales, dense foliage) are not cataloged. Develop a benchmark of challenging assets and report where NVGS breaks down.
- Application to monolithic (non-asset) scenes: NVGS assumes per-asset training and instancing. Investigate automatic partitioning/clustering of monolithic 3DGS scenes into “assets” suitable for NVGS, and compare with occlusion-aware chunking (OccluGaussian).
- Preprocessing cost vs quality trade-offs: visibility extraction requires rendering many views. Study acceleration strategies (coarse-to-fine labeling, proxy geometry, adaptive sampling), and quantify the Pareto frontier between preprocessing time, model size, and runtime gains.
- Radius clipping criterion: the paper swaps AABB-based radius with 2D covariance determinant but provides no calibration. Derive an area-based pruning threshold linked to pixel footprint and perceptual error, and validate across assets and distances.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, organized by sector. Each entry includes potential tools/products/workflows and key assumptions or dependencies.
- Gaming and Interactive Entertainment
- Applications:
- Real-time rendering of large composed scenes (e.g., levels assembled from repeated assets) with improved frame rates and lower VRAM budgets.
- Asset-heavy scenes on mid/high-end PCs and consoles can maintain quality while reducing preprocessing and sorting overhead.
- Tools/products/workflows:
- Unity/Unreal plugin: “NVGS Renderer” integrating the instanced 3DGS rasterizer and per-asset neural visibility MLP.
- Content pipeline step: “Visibility bake” per asset (2–4 minutes) producing a ~18 kB MLP checkpoint reusable across instances.
- Runtime workflow: frustum culling → per-instance local-space conversion → MLP visibility query → instantiate survivors → render.
- Assumptions/dependencies:
- Availability of 3DGS assets and NVIDIA-class GPUs with Tensor Cores (TCNN-backed inference).
- Scenes benefit most from occlusions and asset repetition; limited gains in scenes with minimal occlusion or highly top-down cameras.
- Correct FoV and scale correction is implemented to avoid visibility mispredictions.
- Film/VFX and Previsualization
- Applications:
- Shot assembly and previs for complex scenes with many hero/background assets (e.g., forest, crowds, urban sets) at near-to-medium camera distances.
- Faster iteration with high fidelity (near-perfect PSNR/SSIM, low FLIP) while using significantly less VRAM (~3–7 GB reported vs >13 GB baselines).
- Tools/products/workflows:
- DCC integration: NVGS-based “asset visibility bake” exporter (e.g., from Blender/Maya) producing the asset MLP + packaged 3DGS.
- Previs viewer: real-time composed scene renderer leveraging instancing and neural occlusion culling.
- Assumptions/dependencies:
- Studios use 3DGS for asset-centric scene assembly; LoD remains complementary for far distances.
- Requires CUDA/Tensor Core acceleration for optimal throughput; small numeric differences near the near plane should be acceptable.
- Digital Twins, Architecture/Engineering/Construction (AEC), and Industrial Design
- Applications:
- Real-time walkthroughs of large facilities or sites composed of repeated assets (trees, furniture, equipment), with lower memory and higher FPS.
- Review sessions on mid-tier workstations without exceeding VRAM limits.
- Tools/products/workflows:
- “NVGS Twin Viewer” with instanced rendering and per-asset MLP visibility.
- Workflow: convert CAD/scan-based assets to 3DGS → bake visibility → assemble scenes → real-time review.
- Assumptions/dependencies:
- 3DGS conversion pipeline is in place; occlusion is prevalent (dense clutter, repeated modules).
- GPU-based rendering; benefits strongest at near-to-medium view ranges.
- Cloud Rendering and Streaming for XR/Web Platforms
- Applications:
- Server-side cost and energy savings via lower VRAM and global memory traffic, enabling higher concurrency or smaller instance sizes.
- Progressive streaming pipelines can prioritize visible splats and reduce bandwidth/compute.
- Tools/products/workflows:
- “NVGS Render Microservice” providing occlusion-aware instanced rendering at scale.
- Asset registry storing MLP visibility metadata per asset; server orchestrates frustum + visibility culling before streaming frames.
- Assumptions/dependencies:
- GPU instances with Tensor Cores; streaming stack compatible with 3DGS outputs.
- Visibility MLP trained per asset and stored alongside asset metadata.
- Robotics Simulation and Autonomy (Sensor Simulation)
- Applications:
- Faster photorealistic camera simulations in synthetic environments built from 3DGS assets (e.g., crowd, forest, warehouse).
- Reduced VRAM enabling larger scenario libraries per GPU for training/perception validation.
- Tools/products/workflows:
- Isaac/ROS-compatible “NVGS Sensor Simulator” for camera-based training using occlusion-aware 3DGS rendering.
- Workflow: bake visibility per asset once → assemble environment → simulate camera viewpoints.
- Assumptions/dependencies:
- Environments use 3DGS for visual realism; benefits strongest in cluttered spaces with high occlusion.
- Performance measured at near-to-medium ranges; LoD can be layered for far distances.
- Education and Museums (PC-based VR/AR)
- Applications:
- Classroom and exhibit viewers of complex photogrammetry scenes on mid-tier PCs with constrained VRAM.
- Improved reliability and reduced preprocessing overhead for demos and training modules.
- Tools/products/workflows:
- Lightweight NVGS viewer with per-asset visibility baked offline; museum exhibits run on affordable GPUs.
- Educator workflow: convert scans to 3DGS → bake visibility → distribute scenes with small MLPs.
- Assumptions/dependencies:
- PC-based setups with CUDA/Tensor Core support; mobile standalone headsets may require further optimization (see long-term).
- E-commerce and Virtual Showrooms
- Applications:
- Large product halls composed of repeated 3DGS assets (e.g., shelves, fixtures, SKUs) rendered in real-time for sales demos and configurators.
- Tools/products/workflows:
- “NVGS Showroom” web/desktop viewer: server-side occlusion-aware rendering, client-side streaming.
- Workflow: bake visibility per product asset; dynamically assemble scenes based on customer queries.
- Assumptions/dependencies:
- Server-side rendering with GPU acceleration; client receives video frames or compressed buffers.
- Gains depend on occlusion density and asset repetition.
- Academic Research (Computer Graphics and Vision)
- Applications:
- Baseline for neural visibility modeling in semi-transparent splat renderers; reproducible pipeline for studying viewpoint-dependent occlusion.
- Rapid prototyping of LoD + occlusion culling combined strategies and renderer-side NN queries.
- Tools/products/workflows:
- Research toolkit: scripts for camera sampling (Fibonacci sphere), visibility extraction, MLP training (TCNN), and instanced rasterizer.
- Assumptions/dependencies:
- Access to GPU hardware; willingness to integrate CUDA kernels and TCNN; familiarity with 3DGS training and asset preparation.
Long-Term Applications
The following use cases require further research, scaling, or development before broad adoption.
- Mobile/Edge Deployment (Phones, Standalone VR Headsets, AR Glasses)
- Applications:
- On-device occlusion-aware 3DGS rendering for consumer devices with limited memory and power.
- Tools/products/workflows:
- Ported NVGS inference stack to mobile NPUs/GPUs (Metal/Vulkan); quantized/low-precision MLPs; WebGPU/ANGLE backends.
- Assumptions/dependencies:
- Replacement of Tensor Core–specific optimizations with mobile-friendly kernels; aggressive quantization and operator fusion.
- End-to-end profiling and memory scheduling for mobile SoCs.
- City-Scale Digital Twins and Geospatial Visualization
- Applications:
- Real-time interactive exploration of city-scale 3DGS twins (hundreds of millions to billions of splats) blending LoD and neural occlusion culling.
- Tools/products/workflows:
- Hierarchical scene management (chunking, streaming) with per-asset visibility MLPs; dynamic LoD selection; region-aware sampling strategies.
- Assumptions/dependencies:
- Advanced orchestration across distributed GPUs; robust visibility learning for assets with complex, high-frequency occlusion patterns.
- Standardized metadata for visibility ranges and sampling bounds.
- Standardization of Asset-Level “Visibility MLP” Metadata
- Applications:
- Interchange formats (e.g., USD extensions) carrying per-asset visibility models for plug-and-play culling across engines.
- Tools/products/workflows:
- “Visibility Profile” spec (inputs: normalized means, directions, distance, camera forward, Gaussian features; normalization ranges, FoV correction).
- Assumptions/dependencies:
- Industry consensus on schema; versioning for training parameters; tooling for validation and fallback behavior.
- Advanced Lighting and Material Models for 3DGS
- Applications:
- Enabling more expensive per-Gaussian computations (e.g., higher-degree spherical harmonics, view-dependent materials) made viable by occlusion-aware culling.
- Tools/products/workflows:
- Renderer modules that budget compute per visible splat; adaptive shading driven by MLP predictions; deferred splat shading.
- Assumptions/dependencies:
- Stable quality with richer shading; accurate visibility predictions when shading complexity increases; joint training or calibration.
- Robotics and Autonomous Systems (Onboard, Real-Time)
- Applications:
- On-robot perception simulation and digital twins with occlusion-aware rendering under strict latency/energy constraints.
- Tools/products/workflows:
- Embedded NVGS stack with real-time MLP inference; incremental visibility learning for dynamic scenes (online training).
- Assumptions/dependencies:
- Efficient embedded inference; strategies for handling dynamic occluders; online re-baking or adaptive visibility models.
- Healthcare and Surgical Training Simulators
- Applications:
- High-fidelity patient-specific visualizations and simulators with constrained GPU resources (hospital workstations).
- Tools/products/workflows:
- 3DGS pipeline for medical scans; per-asset visibility bake for repeated instruments/devices; stable frame rates for interactive modules.
- Assumptions/dependencies:
- Medical-grade validation of 3DGS reconstructions; integration with haptics/physics; compliance with data and privacy standards.
- Sustainability, Cost, and Policy Frameworks for Rendering Infrastructure
- Applications:
- Incorporating occlusion-aware rendering in sustainability metrics (energy-per-frame, VRAM-per-scene) and procurement guidelines for GPU clusters.
- Tools/products/workflows:
- Benchmarks reporting energy and cost savings of NVGS vs baselines; policies favoring culling/LoD-aware pipelines.
- Assumptions/dependencies:
- Robust measurement methodology; agreement across cloud providers and studios; alignment with broader green computing standards.
Notes on Feasibility and Dependencies
- Hardware: Current implementation is optimized for NVIDIA GPUs with Tensor Cores (TCNN). Non-Tensor Core or mobile deployments need kernel and inference rework.
- Asset Preparation: Requires 3DGS assets, pruning of low-opacity splats, centering, distance bounds for sampling, and optional auxiliary views to avoid training on popping/artifacts.
- Scene Characteristics: Gains are largest in near-to-medium distances and in scenes with high occlusion and repeated assets; LoD complements occlusion culling for far views.
- Quality and Stability: Correct FoV and scale normalization are critical; minor numerical differences near the near plane can occur with alternative rasterizers.
- Storage and Build Time: Per-asset visibility MLP is tiny (~18 kB) and quick to train (~3.3 minutes total including visibility extraction), facilitating broad asset library coverage.
Glossary
- 3D Gaussian Splatting (3DGS): A real-time rendering representation using anisotropic 3D Gaussian primitives to model scenes for view synthesis. "3D Gaussian Splatting can exploit frustum culling and level-of-detail strategies to accelerate rendering of scenes containing a large number of primitives."
- Aliasing: Visual artifacts caused by insufficient sampling, leading to jagged or flickering patterns. "robust to common 3DGS artifacts such as popping and aliasing"
- Auxiliary views: Additional camera viewpoints sampled near the main view to improve robustness during training. "we avoid training on these artifacts by also sampling a small set of auxiliary views on the intersection of a cone rotated towards the camera and the sphere at the same distance as the camera."
- Axis-aligned bounding box: A bounding box aligned with coordinate axes, used for conservative culling or sizing. "In gsplat, radius clipping works by using the largest radius of the axis-aligned bounding box to decide whether a Gaussian should be pruned."
- Backface culling: A technique discarding geometry facing away from the camera to reduce rendering work. "similar to backface culling for meshes"
- Chunk-based rendering: Rendering strategy that divides scenes into spatial chunks to manage memory and performance. "Similar to other LoD approaches, they then use a chunk-based rendering approach to reduce required memory."
- Codebooks: Learned dictionaries used for compressing parameters by quantization or indexing. "utilizing codebooks or exploiting the redundant nature within the Gaussian parameters."
- Densification: Training step that adds or refines Gaussians to better cover the scene. "The densification step used in 3DGS to promote exploration also inspired several follow-up works"
- Fibonacci sphere sampling: A low-discrepancy method to uniformly sample directions on a sphere. "We then uniformly sample directions using the Fibonacci sphere sampling~\cite{article_fibonacci_sphere_sampling} method."
- Field of View (FoV): Angular extent of the observable scene through a camera. "regardless of instance transformations or different camera properties, such as resolution or Field of View."
- FLIP: A perceptual image difference metric tailored for alternating images in graphics. "We scaled FLIP by a factor of five to facilitate better visual comparison."
- Frustum culling: Discarding objects outside the camera’s viewing frustum before rendering. "Per frame, we then perform frustum culling based on the means of the Gaussian"
- Gimbal-Sigmoid: A method to learn approximate binary masks for pruning via a sigmoid-based mapping. "learns this masking by using the Gimbal-Sigmoid method to achieve an approximate binary mask"
- Instanced rasterizer: A rasterizer that renders multiple transformed instances of the same asset efficiently. "We also propose a novel instanced rasterizer specifically tailored for composed scenes consisting of multiple 3DGS assets."
- Level of Detail (LoD): Rendering technique that varies representation complexity by distance or importance. "introduced the traditional Level of Detail (LoD) approach to the context of 3DGS."
- Min-max normalization: Scaling a value into a fixed range using its minimum and maximum bounds. "Finally, we map this distance into the [-1, 1] range using standard min-max normalization, based on the per-asset minimum and maximum distances."
- Mip-Splatting: A smoothing/filtering approach to reduce aliasing in 3D Gaussian splatting. "they use the 3D smoothing filter from MipSplatting~\cite{Yu2024MipSplatting}"
- Multilayer Perceptron (MLP): A small feedforward neural network used to predict visibility per Gaussian. "baking the visibility data into a lightweight MLP that is fully integrated into this rasterizer"
- Occlusion culling: Skipping objects hidden by others to reduce rendering workload. "We propose a novel approach for occlusion culling in 3DGS rendering"
- PSNR: Peak Signal-to-Noise Ratio; a quantitative image quality metric. "we utilize the standard image quality metrics PSNR and SSIM"
- Radius clipping: Pruning Gaussians whose projected radius is too small to matter at a given distance. "gsplat with the radius clipping parameter enabled."
- Spherical harmonics: Basis functions for representing view-dependent lighting or appearance. "which were trained with zero degrees for spherical harmonics."
- Tensor Cores: Specialized GPU units that accelerate matrix operations for neural inference. "Leveraging Tensor Cores for efficient computation"
- tiny-cuda-nn (TCNN): A GPU-optimized library for training and inference of small neural networks. "we bake it into a lightweight MLP implemented using tiny-cuda-nn (TCNN)~\cite{tiny-cuda-nn}"
- Transmittance: The accumulated transparency of a ray up to a point, affecting subsequent contributions. "once transmittance saturates, subsequent splats can be discarded without any significant loss in color."
- Virtualized rendering: A pipeline that abstracts assets and instances to manage large scenes efficiently. "We provide an efficient, virtualized, and instanced rendering pipeline for 3DGS capable of processing scenes over 100 million Gaussians at real-time frame rates."
- Viewing frustum: The pyramidal (or truncated) volume defining what the camera can see. "By querying it for Gaussians within the viewing frustum prior to rasterization"
- Viewpoint-dependent visibility function: A function mapping camera viewpoint to whether a primitive is visible. "learn the viewpoint-dependent visibility function of all Gaussians"
- Voxel grids: 3D grids of volumetric cells used to organize or anchor scene representations. "employing different levels of voxel grids."
- VRAM: GPU video memory used to store assets and intermediate rendering data. "Our approach uses significantly less VRAM"
Collections
Sign up for free to add this paper to one or more collections.