A Kernel Nonconformity Score for Multivariate Conformal Prediction
Published 23 Apr 2026 in stat.ML and cs.LG | (2604.21595v1)
Abstract: Multivariate conformal prediction requires nonconformity scores that compress residual vectors into scalars while preserving certain implicit geometric structure of the residual distribution. We introduce a Multivariate Kernel Score (MKS) that produces prediction regions that explicitly adapt to this geometry. We show that the proposed score resembles the Gaussian process posterior variance, unifying Bayesian uncertainty quantification with the coverage guarantees of frequentist-type. Moreover, the MKS can be decomposed into an anisotropic Maximum Mean Discrepancy (MMD) that interpolates between kernel density estimation and covariance-weighted distance. We prove finite-sample coverage guarantees and establish convergence rates that depend on the effective rank of the kernel-based covariance operator rather than the ambient dimension, enabling dimension-free adaptation. On regression tasks, the MKS reduces the volume of prediction region significantly, compared to ellipsoidal baselines while maintaining nominal coverage, with larger gains at higher dimensions and tighter coverage levels.
The paper introduces a kernel nonconformity score (MKS) that extends Mahalanobis methods using RKHS embeddings to create valid, tight prediction regions.
It decomposes MKS into a Maximum Mean Discrepancy term and a KPCA correction, ensuring finite-sample coverage and reduced prediction region volume.
Empirical results demonstrate that MKS delivers up to 86% smaller prediction volumes in multivariate regression compared to traditional methods.
Kernel-Based Nonconformity for Multivariate Conformal Prediction
Introduction and Motivation
Conformal prediction provides finite-sample coverage guarantees for prediction regions in regression scenarios, with the guarantee being distribution-free and robust to model specification. In the multivariate setting (Y∈Rd), the design of nonconformity scores---mappings from residual vectors to scalars---determines the geometry and efficiency of prediction regions. While Mahalanobis-distance-based (ellipsoidal) and density-level-set-based approaches are predominant, both have intrinsic limitations: ellipsoidal scores enforce a fixed geometric shape, failing with non-elliptic, multimodal, or heteroscedastic residuals; density-based scores are direction-invariant and unreliable in high dimensions due to the curse of dimensionality inherent in nonparametric density estimation.
The paper "A Kernel Nonconformity Score for Multivariate Conformal Prediction" (2604.21595) introduces the Multivariate Kernel Score (MKS), a kernelized generalization of the Mahalanobis distance that adapts to the geometry of calibration residuals via kernel embeddings, regularized covariance operators, and a functional calculus in reproducing kernel Hilbert spaces (RKHSs). The score connects Bayesian and frequentist paradigms, decomposing into a Maximum Mean Discrepancy (MMD) statistic and a kernel PCA (KPCA) correction. This approach enables construction of tight prediction regions with finite-sample coverage, particularly in non-elliptical and moderate/high-dimensional settings, while maintaining computation via efficient kernel-algebraic reductions.
Methodological Framework
The MKS is grounded in the split conformal prediction framework, where data are partitioned into training and calibration sets, a regression model f^ is fit, calibration residuals {εi} are computed, and a nonconformity scoreS maps each residual to a scalar. The conformal region is then the sublevel set of S at a data-dependent quantile threshold. Traditional approaches include:
Density-level-set scores: S(ε)=−p^(ε) from a density estimate
MKS generalizes this: for a positive definite kernel k(⋅,⋅) and corresponding feature map ϕ, calibration features are embedded in a (potentially infinite-dimensional) RKHS H, yielding centered features f^0, and a regularized empirical covariance operator f^1. The MKS is defined as
f^2
By the "kernel trick" and Woodbury identity, this score reduces to a function of kernel Gram matrices and inner products, enabling efficient computation.
Probabilistic and Geometric Interpretations
The MKS admits interpretations unifying Bayesian GP uncertainty with conformal calibration. Proposition 1 (GP Connection) shows that f^3 is exactly the GP posterior variance at f^4, given calibration points as locations (not as function values):
f^5
Hence, MKS measures the degree to which a test residual is unaccounted for by the geometry of calibration residuals under the GP prior (with observation noise regularization).
Additionally, Proposition 2 (MMD-KPCA Decomposition) shows that f^6 splits into two terms:
Isotropic density deviation: the squared MMD f^7, which, for the RBF kernel, reduces to a kernel density estimate.
Anisotropic KPCA correction: which discounts deviations in feature directions aligned with high empirical calibration variance, yielding directionally adaptive regions.
This decomposition generalizes Mahalanobis scoring (recovered for the linear kernel) and demonstrates that MKS balances local density and geometric structure without being restricted to convex or ellipsoidal shapes.
Theoretical Guarantees
The paper provides:
Finite-sample coverage: Conformal coverage holds for all f^8, so prediction regions based on MKS maintain f^9, under exchangeability.
Convergence rates: The convergence of conditional and marginal coverage, and the efficiency of region estimation, depend on the effective rank of the kernel covariance operator, not on the ambient dimension {εi}0. For smooth kernels with fast-decaying spectrum, this offers dimension-free adaptation.
Extension to temporal dependence: Under {εi}1-mixing, analogous marginal coverage results hold, relevant for time series and dependent data.
Empirical Results
Synthetic and real data experiments compare MKS with Mahalanobis, Bonferroni (coordinate-wise), and density-only scores. On both misspecified and well-specified regression tasks in {εi}2, MKS consistently produces tighter prediction regions (sometimes reducing region volume by up to 86% over Mahalanobis baseline), while strictly maintaining nominal marginal coverage.
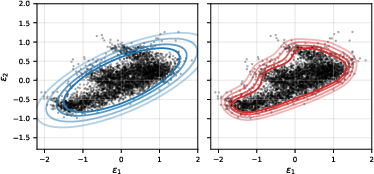
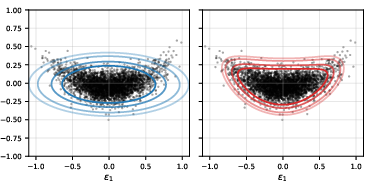
For instance, on synthetic bivariate regression (see visualization below), the MKS aligns prediction region boundaries with the empirical residual distribution, tightly excluding low-density regions that ellipsoidal or density-only scores cannot efficiently rule out.
Figure 1: Prediction regions on synthetic data at coverage levels {εi}3; left: Mahalanobis baseline (blue); right: MKS (red), both overlaid on calibration residuals.
Empirical results demonstrate that as the dimension grows, or as coverage becomes tighter ({εi}4), the volume savings of MKS become more pronounced. Across real datasets, with {εi}5, MKS reduces region volume substantially relative to both Mahalanobis and density-only baselines, with all methods maintaining marginal coverage at the nominal level.
Implications and Future Directions
The MKS score injects kernel methods and non-linear geometric adaptation into conformal multivariate uncertainty quantification, strictly generalizing previous approaches. Since the conformal guarantee is independent of the score, one can leverage advances in kernel embedding, GP geometry, or other high-dimensional metrics without sacrificing finite-sample validity.
Practically, MKS enables practitioners to construct prediction regions that are both valid and efficient in complex, structured, or high-dimensional data regimes (e.g., multi-output regression, structured prediction, and calibrated uncertainty estimation for deep networks). The geometry of the prediction region is both data-driven and computationally feasible, with hyperparameters (kernel, regularization) tunable by cross-validation or GP marginal likelihood.
Theoretically, the kernel machinery enables the application of infinite-dimensional statistics to calibration and coverage, fostering further links between functional analysis, Bayesian nonparametrics, and frequentist uncertainty quantification. The paper speculates on extensions to handle non-exchangeable data (covariate shift, temporal dependence) and function-valued outputs (process-level conformal sets), and suggests that adaptation to nonstationary, structured-output, or spatio-temporal settings would extend the impact of this framework.
Conclusion
The kernelized nonconformity score presented in the paper subsumes and extends existing approaches to multivariate conformal prediction. Its dual probabilistic (GP) and geometric (MMD+KPCA) interpretations, together with empirical validation across synthetic and real tasks, establish MKS as a robust, adaptable, and theoretically grounded tool for constructing valid and efficient prediction regions in multivariate regression. This work offers a unifying perspective and an extensible methodology for uncertainty quantification in high-dimensional predictive modeling.