- The paper introduces the Cross-AUC metric and SFAM framework to address cross-domain score misalignment in deepfake detection.
- It employs patch-level image-text alignment and facial region-specific experts to improve local and global detection robustness.
- Empirical results on multiple benchmarks show that SFAM achieves higher cross-domain AUC with lower variance compared to baselines.
Cross-Domain Evaluation in Face Forgery Detection: Semantic Fine-Grained Alignment and Mixture-of-Experts
Introduction
Face forgery detection remains a core research area amidst the proliferation of robust generative models that can synthesize extremely realistic fake facial content. While recent advances in CNN and ViT-based models have substantially improved within-dataset detection, generalization to unseen forgeries and datasets with shifting biases continues to be a bottleneck. The prevailing practice in the community is to report intra-dataset AUC, which obfuscates underlying cross-domain weaknesses as significant shifts exist in the detection score distributions between datasets, compromising real-world applicability.
To address this, the paper "Rethinking Cross-Domain Evaluation for Face Forgery Detection with Semantic Fine-grained Alignment and Mixture-of-Experts" (2604.21478) delivers two principal contributions: (1) the Cross-AUC metric, specifically measuring cross-domain comparability and exposing previously hidden robustness defects, and (2) the SFAM (Semantic Fine-grained Alignment and Mixture-of-Experts) framework, which integrates patch-level image-text alignment and a facial region-specific expert mixture to enhance cross-domain discriminative performance. The empirical findings decisively demonstrate the superiority of the proposed approach across standard benchmarks.
Theoretical Motivation and Cross-AUC Metric
Detection methods are commonly benchmarked using the Area Under the ROC Curve (AUC), reported within a single dataset. This approach, however, is fundamentally limited for open-world deployment—as it is invariant under monotonic score transformations, it fails to guarantee that detection scores are calibrated or even comparable across domains. Due to data set-specific biases (e.g., acquisition pipelines, post-processing), detectors can maintain strong intra-dataset separation while experiencing major inter-dataset distributional shifts, rendering practical deployment unreliable.
This issue is highlighted by the score distribution analysis across FaceForensics++, WDF, and Celeb-DF datasets, where intra-dataset separability contrasts sharply with inconsistent cross-domain score alignments.
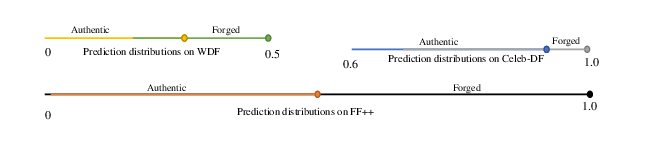
Figure 1: Prediction score distributions of authentic and forged samples across FF++, WDF, and Celeb-DF datasets, showing intra-dataset separability but severe cross-domain distribution shifts.
To address this, the Cross-AUC metric is introduced. Instead of evaluating only on (real, fake) pairs within a single domain, Cross-AUC averages AUC values across all pairs where real samples from dataset i are contrasted with fake samples from dataset j (i=j), directly penalizing models whose decision scores are non-comparable between datasets. This exposes previously unmeasured vulnerabilities and sets a higher bar for generalization.
Semantic Fine-Grained Alignment and Mixture-of-Experts Framework
The SFAM architecture builds on a frozen CLIP backbone and introduces two critical modules: 1) Patch-Level Image-Text Alignment (PaITA) and 2) Facial Region Mixture-of-Experts (FaRMoE).
Architecture Overview
The overall workflow combines mask-guided hybrid data augmentation, region-aligned feature specialization, and local patch-level alignment imposed via explicit loss constraints.
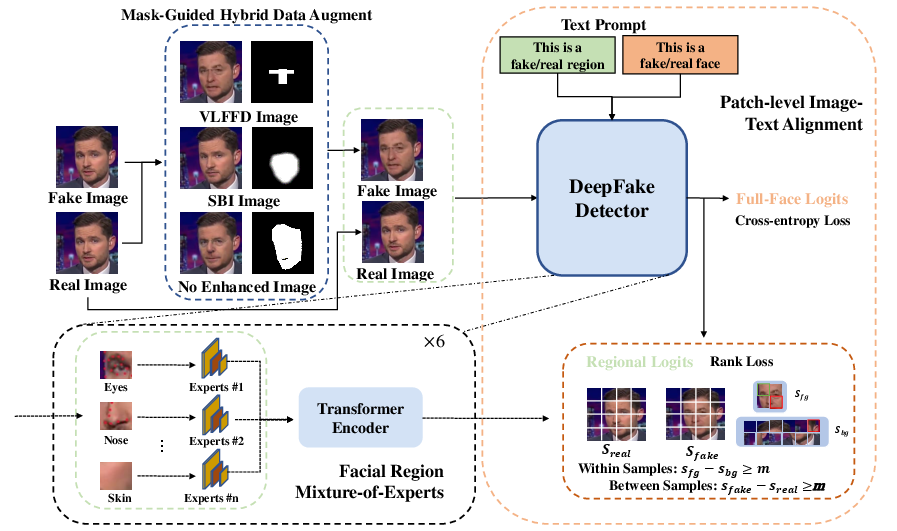
Figure 2: The workflow of the proposed SFAM framework.
Mask-Guided Hybrid Data Augmentation
Mask-guided hybrid augmentation exploits facial region masks derived from landmarks to generate synthetic images where selected regions (e.g., eyes, nose, mouth) are authentically or synthetically forged, using combinations of real-fake and self-blended image pairs. This mechanism explicitly supervises the model to focus on manipulated areas while widening the diversity of forgeries.
Facial Region Mixture-of-Experts (FaRMoE)
To mitigate the limitation of global feature sharing in ViT/CLIP, FaRMoE partitions facial images into anatomically meaningful regions and assigns each to a specialized expert MLP. FaRMoE replaces keys in self-attention layers for certain patches with region-specific features, encouraging extraction of organ–localized artifacts.
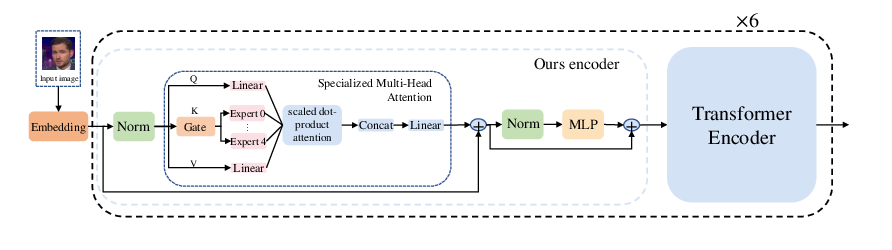
Figure 3: The structure of vision encoder with our proposed FaRMoE module.
Patch-Level Image-Text Alignment (PaITA)
PaITA extends CLIP’s global image-text contrastive training to a local, mask-supervised paradigm. Patch embeddings from the vision backbone are paired with local textual prompts corresponding to real/forged attributes, and innovative ranking losses are imposed: intra-image (forged > authentic patch scores within an image) and cross-image (forged patch > corresponding real patch across matched real/fake pairs). This fine-grained alignment provides strong gradients for artifact detection at a local level.
The complete loss combines global classification, intra-image ranking, and inter-image ranking. Impactful settings for ranking loss weights are empirically validated, with λ1=0.3 and λ2=0.2 maximizing both intra-dataset and Cross-AUC performance.
Experimental Evaluation
Datasets and Experimental Rigor
The evaluation leverages FaceForensics++ as the training domain and tests on the broad Celeb-DF, DFDCP, DFDC, and UADFV benchmarks, encompassing diverse manipulation techniques and post-processing artifacts. Metrics include AUC, Cross-AUC, Cross-AUC minimum, and standard deviation to capture average and worst-case generalization characteristics.
AUC and Cross-AUC Analysis
While leading baselines such as Forensics Adapter achieve intra-dataset AUC above 0.90, their Cross-AUC minimum often collapses below 0.67. In contrast, SFAM reports the highest Cross-AUC average (0.885) and minimum (0.747) with the lowest performance standard deviation (0.066). The minimal difference between SFAM’s AUC and Cross-AUC demonstrates genuine cross-domain universality, rather than overfitting to dataset-confirmed artifacts.
Ablation Studies
Systematic ablations confirm the orthogonality and necessity of each SFAM module. The mask-guided augmentation and PaITA provide the principal generalization improvements, elevating Cross-AUC average from 0.740 (raw CLIP) to 0.881, while FaRMoE further increases organ-specific discrimination without sacrificing generalization or stability.
Feature Embedding Visualization
Feature space analysis using t-SNE demonstrates that while baselines such as CLIP, Effort, and Forensics Adapter suffer from data set–localized clustering (implying reliance on spurious correlations and dataset biases), SFAM learns a representation in which real/fake separation is maintained and samples from different domains overlap more tightly, supporting robust cross-domain inference.

Figure 4: t-SNE visualization results of four methods.
Implications and Future Directions
Theoretical impact: The Cross-AUC metric sets a new community standard for evaluating deepfake detection models, revealing issues with score calibration and intra-dataset overfitting that were hidden by previous protocols.
Practical relevance: Models like SFAM reduce catastrophic performance drops in real-world deployment, where the origin and corruption type of forgeries are unknown. The modular integration of mask guidance, patch-level alignment, and mixture-of-experts represents a blueprint for similar improvements in other cross-domain forensic tasks.
Future research may extend Cross-AUC to more diverse synthetic and authentic domains, investigate dynamic expert routing conditioned on wider attributes (beyond facial anatomy), and generalize the principle of fine-grained alignment in multimodal transformers. The framework is also extensible to audio and video modalities and can be integrated with explainability and interpretability pipelines.
Conclusion
This work demonstrates that traditional closed-set evaluation metrics mask critical generalization faults in face forgery detectors. By introducing the Cross-AUC metric and designing SFAM—a framework coupling patch-level image-text alignment with facial region mixture-of-experts—the research achieves robust, stable, and universally applicable deepfake detection. The approach outlines an effective pathway for generalizable forensics, well suited to the rigorous demands of deployment in unconstrained real-world media analysis.