- The paper introduces a cross-modal decoupling framework (CDPD) that isolates forgery-specific artifact signals from general facial content for robust deepfake detection.
- It employs instance-conditioned dual-stream prompt generation and cross-modal attention to dynamically separate and align content and artifact features.
- Experimental results show up to an 8% AUC gain over visual-only baselines, demonstrating improved resilience against various data corruptions.
Cross-Modal Decoupled Prompt Learning for Robust Deepfake Detection
Introduction
This work introduces Cross-Modal Decoupled Prompt Learning (CDPD), a framework coupling vision–language representations with explicit feature disentanglement for robust face forgery detection. The methodology is motivated by the observation that state-of-the-art deepfake detectors are susceptible to spurious correlations due to the entanglement of semantic content and forgery-specific artifacts in the learned features. Such entanglement severely impairs generalization to unseen data distributions and manipulation techniques.
CDPD leverages the multimodal capabilities of CLIP, utilizing instance-conditioned, learnable prompts to dynamically guide the decoupling of visual backbone features into orthogonal content and artifact components through cross-modal attention. Only artifact features—which capture manipulation-specific signals—are used for classification, explicitly suppressing content-level shortcuts. The framework tightly integrates asymmetric cross-modal alignment, orthogonality constraints, and prompt diversity regularization to enforce semantic separation and enhance robustness.
The field of deepfake detection is broadly divided into spatial-domain, frequency-domain, and hybrid methods. Spatial approaches identify inconsistencies in texture, blending, or geometry, while frequency-domain and hybrid models have demonstrated superior generalization by focusing on low- and high-frequency manipulations [f3net, srm, spsl].
Feature disentanglement methods—F3Net [f3net], UCF [ucf], and recent orthogonal subspace decomposition mechanisms [svd]—aim to separate content from artifact representations, but are generally restricted to the visual domain. The use of vision–LLMs (VLMs), including CLIP-based detectors [unifd, c2p_clip, deepfakeclip], shows promise for universal generalization but relies on static or weakly image-conditioned prompts, which are suboptimal for capturing manipulation artifacts.
CDPD extends prior prompt learning approaches (CoOp [coop], CoCoOp [cocoop])—which were developed for category-adaptive visual tasks—by constructing dual instance-specific prompt branches for semantic and artifact decoupling. It also introduces a closed-loop, bidirectional visual–linguistic interaction to enforce semantic orthogonality.
Methodology
CDPD consists of: (1) instance-conditioned prompt generation via lightweight meta-networks, (2) cross-modal attention for text-guided feature decoupling, (3) an integrated loss architecture ensuring orthogonality, prompt diversity, and asymmetric cross-modal alignment, and (4) a dedicated pre-training phase for semantically grounding prompt representations.
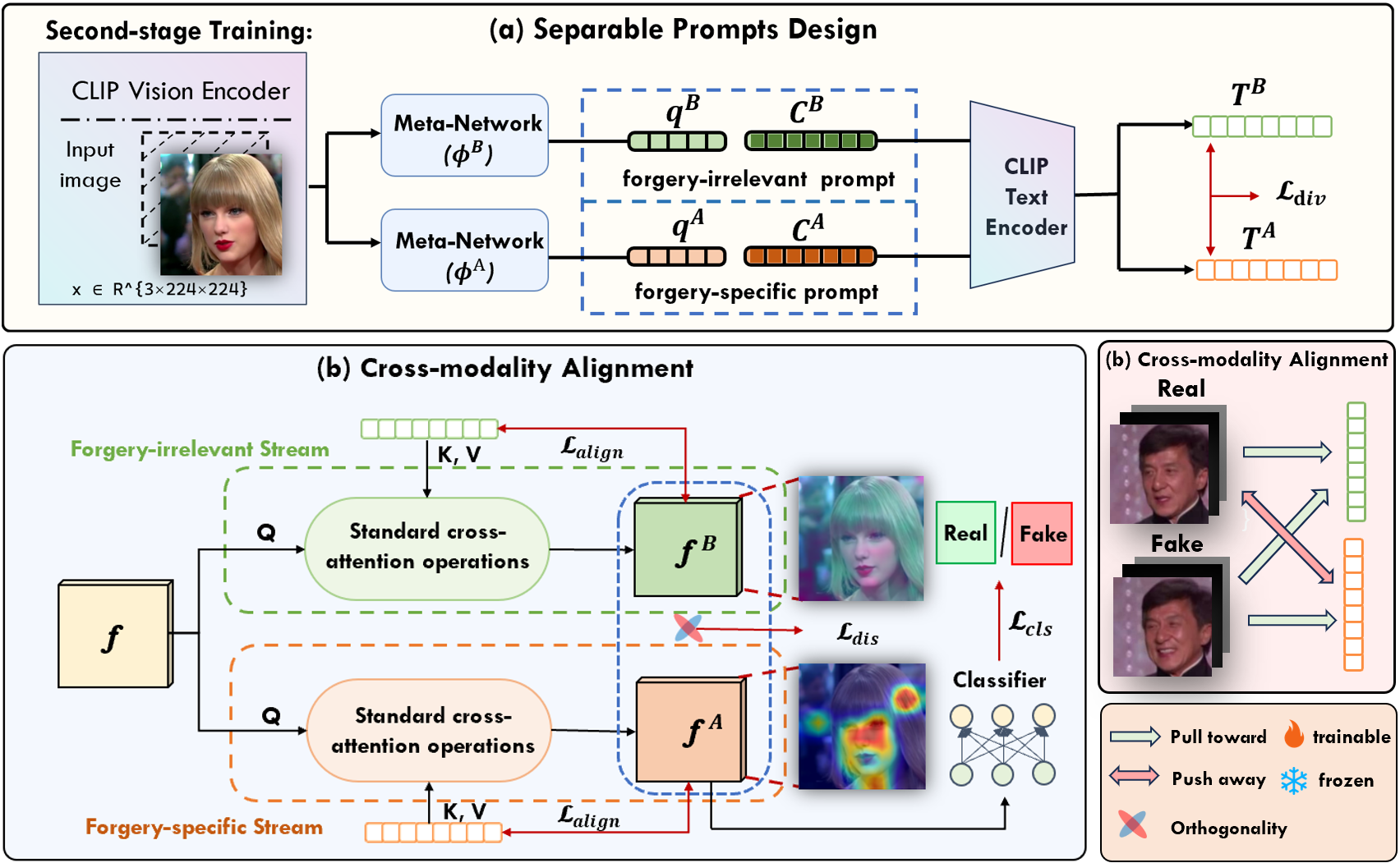
Figure 2: The upper diagram shows generation and encoding of instance-specific content/artifact text embeddings; the lower diagram illustrates the text-guided feature decoupling and cross-modal alignment.
Instance-Conditioned Dual-Stream Prompt Generation
Separate meta-networks generate conditional tokens from CLIP backbone features, which are concatenated with learnable global context vectors to form content and artifact prompts. These prompts, when passed through the CLIP text encoder, yield embeddings serving as class-agnostic content or manipulation-specific artifact queries. Prompt construction is fully learnable, allowing adaptation to diverse forgery traces.
Cross-Modal Attention and Guided Decoupling
The CLIP backbone feature serves as the attention query over the content/artifact textual embeddings (keys/values) in a cross-modal Transformer attention operation. This enables selective extraction of content and artifact information via adaptive visual–linguistic fusion, a mechanism not available in prior pure-visual or prompt-tuning architectures.
Loss Architecture
- Contrastive Pre-Training: Before joint training, the content meta-network is aligned to CLIP's visual space using a contrastive image–text objective, ensuring initialization avoids degenerate prompt collapse.
- Cross-Modal Alignment: Symmetric alignment is enforced for content features (all images); artifact features use an asymmetric push–pull strategy that discriminates between real and fake, reflecting the one-sided nature of forgeries.
- Orthogonality Constraint: Explicit orthogonalization loss ensures the content and artifact representations are decorrelated, maximizing decomposition efficacy.
- Prompt Diversity: Regularization prevents trivial prompt-mapping solutions, promoting instance-specific adaptivity and robust generalization.
- Supervised Contrastive Learning: Applied at the backbone level, this further enhances class separation before decoupling.
Experimental Results
Benchmarks: Cross-Dataset and Cross-Method Generalization
CDPD is evaluated on FaceForensics++ (c23), Celeb-DF-v2, DFD, DFDC, DFDCP, WDF, and various manipulation protocols (UniFace, BlendFace, MobSwap, etc.), with the main metric being video-level ROC AUC.
(Table 1)
Key Results:
- CDPD attains the highest or competitive AUC in both cross-dataset and cross-method settings. For cross-method, an average AUC of 0.976 is observed, reflecting a +2.7% gain over the strongest visual-only CLIP baseline.
- The framework achieves large gains—up to 8% AUC—on challenging forgery types (e.g., BleFace), outperforming other approaches that rely purely on visual encoders or naive prompt learning.
Visualization and Analysis

Figure 4: t-SNE visualizations highlight that post-decoupling, artifact features exhibit strong class separation, while the content stream becomes class-agnostic.

Figure 6: Qualitative visualizations on four manipulation types demonstrate that artifact attention aligns precisely with known manipulation regions.
Robustness is validated under six real-world corruptions (blockwise masking, color saturation, noise, blur, JPEG compression), where CDPD consistently degrades more gracefully than FWA, LSDA, or SBI.
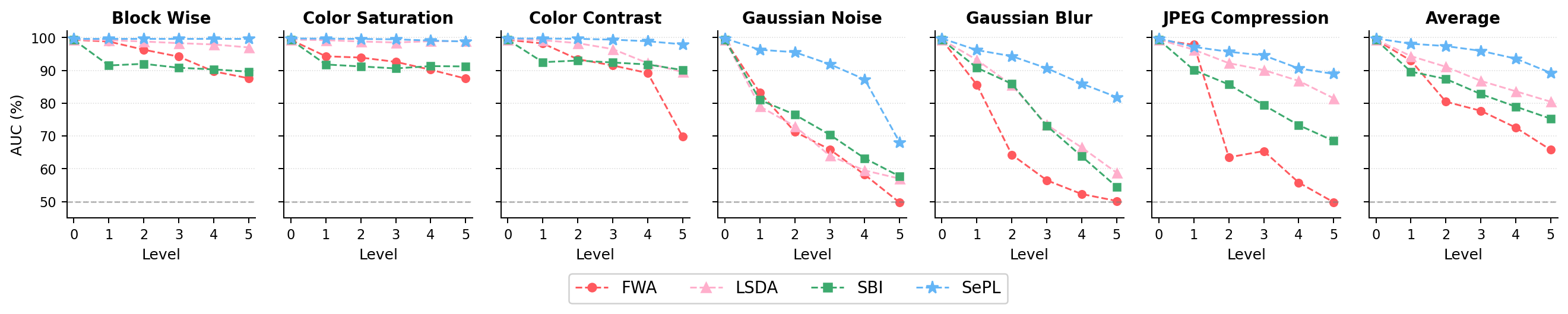
Figure 8: Across all types and perturbation levels, average AUC is highest for CDPD, indicating strong resilience to both low-frequency and high-frequency distortions.
Generalization to Universal Forgery Detection
Experiments on UniversalFakeDetect, covering both GAN and diffusion-produced images, demonstrate high mean accuracy (94.51%) and AP (98.33%), confirming the scalability of the proposed cross-modal decoupling.
Ablation and Architectural Analysis
Ablation confirms that each loss component (contrastive, orthogonality, alignment, diversity) incrementally improves detection accuracy and robustness. Cross-modal attention outperforms feature concatenation for text-guided decoupling, and prompt length is optimal around K=16, balancing expressivity and overfitting risk. Both LoRA and SVD-based backbone adaptation are compatible, confirming that gains are due to cross-modal decomposition rather than adaptation mechanism selection.
Implications and Future Work
CDPD demonstrates that explicit, prompt-guided, cross-modal feature decoupling sets a new standard for robustness and generalization in deepfake detection. The asymmetric, semantically grounded alignment prevents exploitation of dataset bias, mitigates shortcut learning, and adapts effectively to new manipulation pipelines. Prompt diversity and adaptive context modulate the balance between flexibility and overfitting, a recurring challenge in prompt/PEFT-based paradigms.
Potential developments include:
- Extending adaptive prompt length and structure to further enhance per-instance response to forgery complexity.
- Integrating temporal dynamics and multi-frame attention for video-level manipulation tracing.
- Generalizing to non-facial and multi-modal synthetic media.
Conclusion
CDPD establishes a principled framework for cross-modal orthogonal feature decomposition, leveraging the semantic richness of VLMs to achieve robust deepfake detection that generalizes across datasets, manipulation methods, corruptions, and generators. The methodology demonstrates that instance-adaptive, semantically filtered artifact representations and explicit alignment/disentanglement objectives are key to advancing generalizable and interpretable forensic AI.
Figure 8: Robustness evaluation underscores superior AUC across all corruption types and severities, confirming the efficacy of cross-modal feature decoupling.
Figure 4: t-SNE distributions evidence improved clustering of true and forged images post-artifact decoupling.
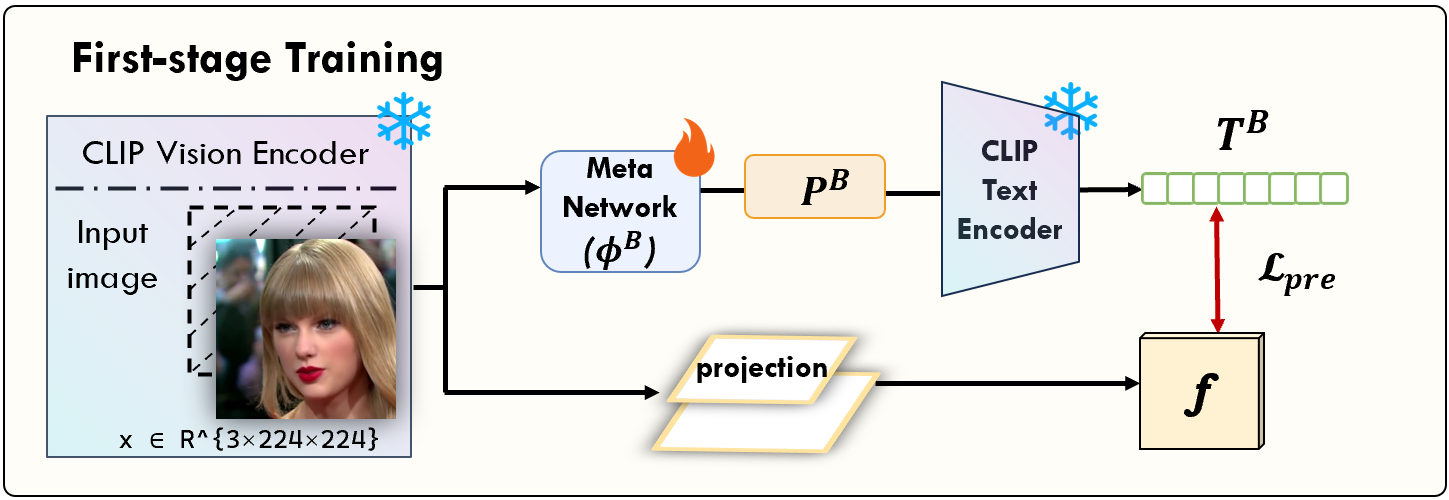
Figure 6: Manipulation-specific visualizations display the mechanism's ability to produce spatially precise attention on manipulated facial regions.