- The paper introduces artifact-aware semantic anchors to guide fine-grained visual alignment and mitigate catastrophic forgetting in incremental face forgery detection.
- It employs a transformer-based architecture with Semantic-Guided Incremental Detector and Adaptive Decision Harmonizer to ensure stable adaptation without relying on data replay.
- Empirical results demonstrate state-of-the-art AUC performance and robustness to image perturbations across multiple datasets, enhancing interpretability and practical scalability.
AIFIND: Artifact-Aware Interpreting Fine-Grained Alignment for Incremental Face Forgery Detection
Motivation and Problem Setting
Incremental Face Forgery Detection (IFFD) addresses the practical necessity for face forgery detectors to adapt to new, unseen manipulation types over time, reflecting the continual evolution of generative forgery techniques. Existing IFFD methods suffer from catastrophic forgetting due to their reliance on data replay or coarse binary supervision, without explicitly constraining the feature space. These limitations result in severe feature drift, sub-optimal generalization, and are often impractical due to storage/privacy restrictions.
AIFIND introduces a new paradigm for IFFD by transferring the inductive bias of Vision-LLMs (VLMs) toward semantic anchoring of artifact regions, leveraging the stability of language embeddings as immutable guides for fine-grained visual alignment. The principal objective is to enforce a semantically grounded and geometrically consistent feature space evolution, eliminating the need for raw data replay and mitigating catastrophic forgetting.
Methodology
AIFIND's architecture consists of three principal modules: Artifact-Driven Semantic Prior Generator (ASPG), Semantic-Guided Incremental Detector (SGID) with Artifact-Probe Attention (APA), and the Adaptive Decision Harmonizer (ADH).
Semantic Anchoring via ASPG
ASPG derives a set of canonical semantic anchors by interpreting low-level artifacts (blur, color, structure, texture, boundary) across several facial regions (eyes, nose, cheeks, mouth, jawline, boundary). These are detected using automated local descriptors (e.g., Laplacian variance, SSIM, GLCM, gradient magnitude) and spatially localized via MediaPipe Face Mesh. For each artifact-region pair, ASPG leverages a LLM to synthesize candidate natural language artifact-vs-authentic descriptions and selects optimal anchors by maximizing CLIP similarity against handcrafted support sets.
The anchor selected for a region with the most severe anomaly in forgeries (or most pristine region in reals) becomes the corresponding semantic anchor; these are composed into an anchor library governing the "semantic coordinate system" for supervision.
Semantic-Guided Visual Alignment: SGID and APA
SGID injects the semantic anchors into the visual feature learning process through the APA module embedded in the Transformer backbone. APA utilizes a Multi-Head Attention mechanism where visual patch embeddings attend to textual artifact anchors, yielding fused representations whose semantic alignment is adaptively modulated by learnable gating. This achieves fine-grained, instance-specific, semantic-visual alignment.
Dual supervision is enacted via (i) global binary authenticity classification, and (ii) explicit multi-label artifact detection, with cross-entropy and binary cross-entropy loss, respectively. Joint training on these losses compels the model to encode not only the authenticity but the presence of precise artifact modalities, exploiting the persistent semantic anchor space for stability.
Geometric Consistency: Adaptive Decision Harmonizer (ADH)
To prevent boundary drift in the classifier heads with incremental learning, ADH performs manifold-constrained weight alignment. Classifier weights from historical and current tasks are compared in the normalized space; geometric affinity is calculated via cosine similarity, and a global semantic reference is aggregated as a weighted sum. Spherical interpolation (SLERP) adaptively rotates the head toward the reference based on semantic compatibility, with weight magnitudes rescaled post-alignment. This process rigorously conserves semantic angular relationships across tasks, maintaining geometry and preventing erasure of prior knowledge.
Training and Strategy
In early training, the anchor set is static to promote stable learning. With sufficient warm-up, a dynamic matching phase activates, adaptively selecting semantic anchors via cosine similarity between new instance features and anchor embeddings. A standard knowledge distillation loss is added to further regularize feature evolution. The final loss is a weighted sum of classification, artifact-detection, and distillation terms.
Experimental Results
Replay-Free Paradigm and Benchmarking
AIFIND is evaluated under two incremental learning protocols: cross-dataset and cross-forgery-category (Protocol 1 and Protocol 2). Compared to replay-based IFFD methods (DFIL, SUR-LID, HDP), AIFIND achieves state-of-the-art AUC (average 0.9686 on Protocol 1 final step) in a strict replay-free setting, outperforming both classical and transformer-based replay methods as well as recent replay-free approaches such as prompt- and adapter-based incrementals.
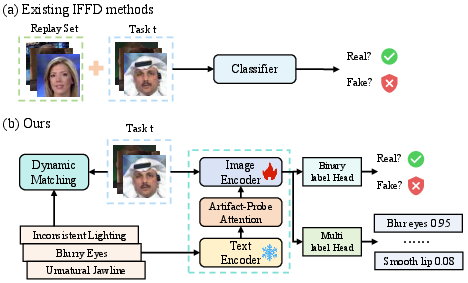
Figure 1: AIFIND eliminates reliance on replay data by continuously anchoring visual features to stable semantic priors, maintaining consistent decision boundaries.
Notably, superiority holds even when transformer backbones are aligned across baselines, eliminating architectural confounds. The result isolates the efficacy of semantic anchoring and fine-grained alignment strategies as the source of performance gains.
Ablation and Component Validation
Ablation studies corroborate the necessity of each module:
- Removing ADH yields significant boundary drift (AUC drop).
- Omitting APA or semantic artifact supervision (Lind) degrades alignment and discriminative focus, confirming the importance of both geometric and fine-grained semantic constraints.
- High-level APA injection achieves optimal trade-off by aligning at appropriate semantic granularity; excessive depth or breadth introduces noise.
Robustness and Generalization
AIFIND demonstrates robust generalization to severe image perturbations (noise, occlusion, compression), maintaining higher AUC across all perturbation levels versus baselines.

Figure 2: AIFIND's robustness to out-of-distribution perturbations surpasses existing approaches, preserving high AUC under challenging image corruptions.
On cross-dataset benchmarks (DFD, UniFace, SDv15, FAVC), AIFIND again achieves the highest mean AUC (0.8980), indicating transferability of learned artifact representations, in contrast to methods overfitting to dataset-specific cues.
Interpretability and Spatial-Semantic Consistency
Visualizations using Grad-CAM show that AIFIND's attention is tightly concentrated on semantically critical, artifact-prone facial regions (e.g., eyes, mouth), with attention maps congruent to predicted artifact-category probabilities.

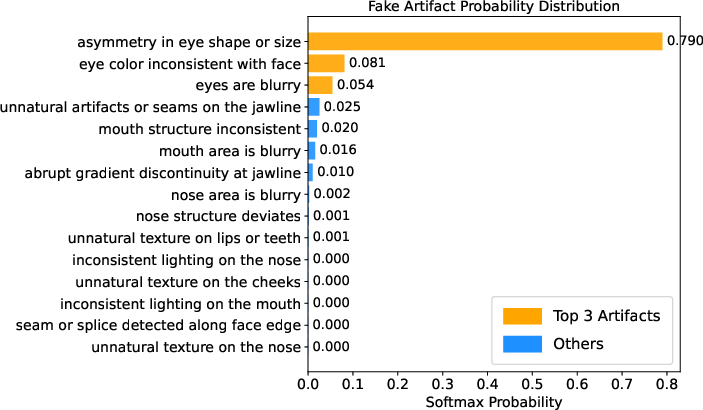

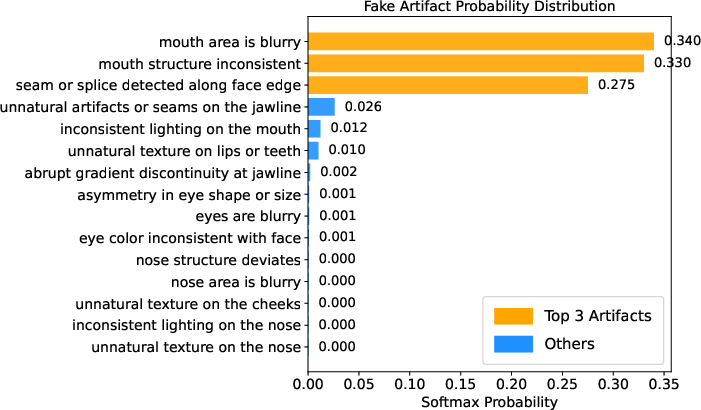
Figure 3: Grad-CAM heatmaps highlight AIFIND's attention focus on manipulated regions, matching predicted artifact probabilities for consistent interpretability.
This spatial-semantic alignment enhances both reliability and explanation of decisions, reducing susceptibility to spurious correlations.
Theoretical and Practical Implications
By interpreting artifacts as stable semantic anchors, AIFIND realizes data-efficient, privacy-preserving continual learning for face forgery detection. The architecture generalizes the application of vision-language alignment beyond static scenarios to incremental adaptation, exploiting the invariance and granularity of linguistic concepts for guidance in visual representation space. Moreover, the spherical alignment in classifier space introduces rigor in geometric continuity, informing future research on catastrophic forgetting mitigation in non-Euclidean parameter spaces.
Practically, AIFIND points toward scalable, minimally supervised, and explainable forensic systems that can rapidly adapt to evolving manipulation methods, a critical requirement as generative models proliferate. The semantic anchor framework is extensible to other domains (e.g., multimodal forensics, open-set recognition), especially where fine-grained, semantic-visual alignment is feasible.
Future Directions
Potential expansions include leveraging more advanced multimodal LLMs for anchor definition, extending semantic anchoring to open-set and out-of-distribution detection, and integrating temporal consistency for video forensics. Automated anchor generation and dynamic adaptation remain rich areas to pursue in addressing unseen attack modalities.
Conclusion
AIFIND establishes a new standard for replay-free IFFD via stable anchoring in a high-dimensional semantic space, explicit artifact-level supervision, and geometric classifier harmonization. Empirical evidence on compositional increments, robustness, and interpretability demonstrates both theoretical and practical value. The methodology signals a shift from data replay to guided semantic constraint as a general incremental learning principle in adversarial and evolving domains (2604.16207).