- The paper introduces DDRL, a framework combining confidence-aware sampling, debiased advantage estimation, and off-policy refinement to mitigate spurious signal amplification in TTRL for math reasoning.
- It empirically demonstrates that ambiguous, medium-frequency pseudo-labels contribute significant reward noise, distorting gradient estimates in GRPO.
- The framework achieves notable improvements on benchmarks like AIME 2024 and AMC, confirming its value in stabilizing unsupervised test-time adaptation.
Spurious Signal Amplification in Test-Time Reinforcement Learning for Math Reasoning
Problem Setting and Challenges in TTRL
Unsupervised test-time reinforcement learning (TTRL) constitutes a major avenue for adapting LLMs to distribution shifts in mathematical reasoning tasks. TTRL eliminates reliance on ground-truth labels by generating pseudo-labels through majority voting over model rollouts. Subsequent policy optimization is conducted by treating these pseudo-labels as targets for reward assignment. However, this unsupervised process is fundamentally vulnerable to spurious signal amplification—optimization dynamics can be dominated by incorrect or ambiguous pseudo-labels, especially when reinforced by inappropriate advantage estimation mechanisms such as group-relative policy optimization (GRPO).

Figure 1: Overview of TTRL, showing how noisy pseudo-labels are produced during reward assignment and further amplified during group-relative advantage estimation.
The critical observation is that pseudo-labels, particularly those in ambiguous medium-frequency regimes, systematically introduce reward noise. Standard group-relative normalization in GRPO further exacerbates the issue by amplifying the influence of these ambiguous signals, distorting the optimization trajectory.
Empirical Analysis of Spurious Signal Amplification
The empirical investigation exposes a striking correlation between answer frequency in the sampled rollouts and answer correctness. High-frequency responses are highly reliable (almost always correct), while low-frequency answers are predominantly incorrect. Most importantly, answers with medium frequency are ambiguous, possessing high variance in correctness, thereby constituting a dense source of reward noise.
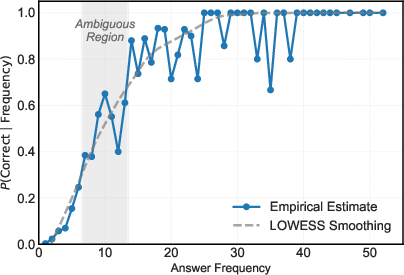
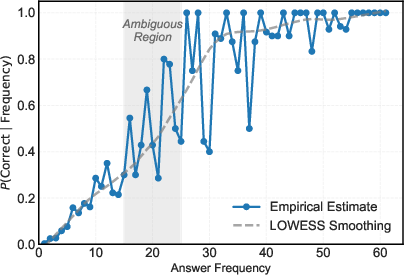
Figure 2: The relationship between answer sampling frequency and correctness on MATH-500 (Qwen2.5-Math-1.5B); medium-frequency samples correspond to high uncertainty.
In TTRL, all samples contribute equally to pseudo-label construction and policy updates. This allows ambiguous medium-frequency answers to introduce substantial spurious signals that are not distinguishable by the underlying algorithm. An additional layer of error is introduced by GRPO: during advantage normalization, sparse positive signals—often the result of low consensus pseudo-labels—are assigned disproportionately high advantage values, effectively amplifying their impact during optimization.
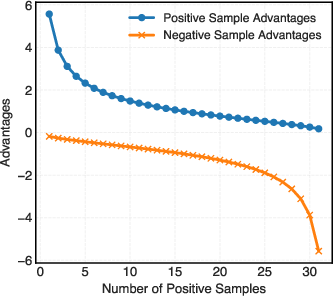
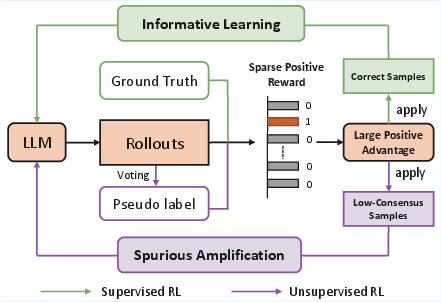
Figure 3: Advantage versus number of positive samples in GRPO. When positive samples are few (low consensus), normalization yields large advantage values, intensifying the effect of spurious signals.
DDRL: Mitigation Framework
To suppress the influence of these spurious signals, the authors introduce Debiased and Denoised Test-Time Reinforcement Learning (DDRL), a unified mitigation framework. DDRL consists of the following components:
- Balanced Confidence-Aware Sampling: By leveraging empirical frequency-correctness patterns, DDRL filters out medium-frequency ambiguous samples and constructs a balanced batch of positive (predominantly high-frequency) and negative (low-frequency) samples. This mechanism prioritizes samples with reliable correctness proxies, thus reducing the introduction of reward noise.
- Debiased Advantage Estimation: DDRL assigns fixed, label-dependent advantage values, decoupled from group statistics. This eliminates the amplification of spurious signals caused by group-relative normalization in GRPO, stabilizing gradient estimates in the unsupervised context.
- Consensus-Based Off-Policy Refinement: Following the RL phase, DDRL employs a lightweight off-policy refinement stage. By constructing a rejection-sampled dataset based on majority-consensus answers from the adapted policy, the method consolidates high-confidence behaviors via supervised fine-tuning, resulting in efficient and stable test-time adaptation.
Numerical Results and Comparative Evaluation
On multiple mathematical reasoning benchmarks (AIME 2024, AMC, MATH-500), DDRL consistently outperforms TTRL and ETMR baselines in pass@1 metrics. For instance, on Qwen2.5-MATH-1.5B, DDRL yields a 19.0% gain on AIME 2024, 4.1% on AMC, and 4.9% on MATH-500 over ETMR, demonstrating the significant utility of mitigating spurious signals in well-calibrated models.
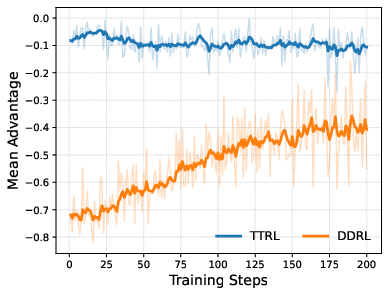
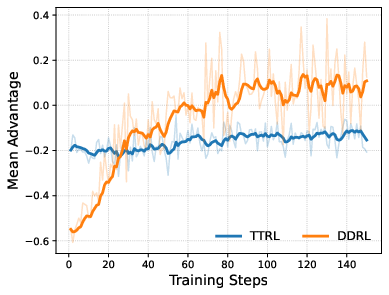
Figure 4: Training dynamics on AIME 2024 with Qwen2.5-Math-1.5B, comparing test-time adaptation approaches.
Notably, the empirical results confirm that advantage debiasing and refinement stages each contribute complementary gains, with advantage debiasing correcting distorted optimization dynamics and off-policy refinement consolidating high-consensus behaviors efficiently.
Theoretical Insights and Failure Modes
A probabilistic analysis of answer sampling frequencies substantiates the empirical findings: for low- and high-frequency answers, the conditional probability of correctness is either close to 0 or 1, hence reliable. In the ambiguous, medium-frequency regime, conditional densities overlap, producing inherently high-variance pseudo-labels and exaggerated sensitivity to sampling fluctuations. The amplification mechanism in GRPO further intensifies the impact of these cases due to its reliance on within-group normalization, underscoring the necessity of bias correction in advantage estimation.
Broader Implications and Future Prospects
This line of work has critical implications for unsupervised reinforcement learning with LLMs. Practically, DDRL equips math and code reasoning systems with robust, test-time debiasing mechanisms, yielding higher stability and accuracy even in the absence of external verifiers. Theoretically, the findings suggest that future unsupervised RL approaches should integrate confidence-aligned filtering and principled debiasing strategies into their core optimization pipelines.
Further extensions could focus on more expressive, uncertainty-aware advantage formulations that interpolate between fixed and adaptive scaling as a function of pseudo-label reliability. Moreover, generalization beyond well-defined correctness tasks (e.g., open-ended generation and dialogue) requires additional research to rigorously characterize pseudo-label ambiguity and to adapt sampling or reward mechanisms.
Conclusion
The diagnosis and mitigation of spurious signal amplification in TTRL for math reasoning elucidate foundational pitfalls of unsupervised RL adaptation in LLMs. DDRL addresses both the introduction and amplification of reward noise by integrating confidence-aware sampling, debiased advantage estimation, and consensus-based refinement. The observed performance improvements and stabilized training dynamics strongly support the proposed methodology as a preferred approach for reliable TTRL in structured reasoning domains.

