RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization
Abstract: Reinforcement learning with human-annotated data has boosted chain-of-thought reasoning in large reasoning models, but these gains come at high costs in labeled data while faltering on harder tasks. A natural next step is experience-driven learning, where models improve without curated labels by adapting to unlabeled data. We introduce RESTRAIN (REinforcement learning with Self-restraint), a self-penalizing RL framework that converts the absence of gold labels into a useful learning signal. Instead of overcommitting to spurious majority votes, RESTRAIN exploits signals from the model's entire answer distribution: penalizing overconfident rollouts and low-consistency examples while preserving promising reasoning chains. The self-penalization mechanism integrates seamlessly into policy optimization methods such as GRPO, enabling continual self-improvement without supervision. On challenging reasoning benchmarks, RESTRAIN delivers large gains using only unlabeled data. With Qwen3-4B-Base and OctoThinker Hybrid-8B-Base, it improves Pass@1 by up to +140.7 percent on AIME25, +36.2 percent on MMLU_STEM, and +19.6 percent on GPQA-Diamond, nearly matching gold-label training while using no gold labels. These results demonstrate that RESTRAIN establishes a scalable path toward stronger reasoning without gold labels.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to train AI models to reason better (solve math and science problems) without needing answer keys. The method is called RESTRAIN. It lets a model teach itself from unlabeled questions (questions with no known correct answer) by carefully learning from its own guesses—and even “penalizing” itself when it’s being overconfident or inconsistent.
What questions did the researchers ask?
In simple terms, they asked:
- Can a model get better at reasoning without being told the right answers?
- If we don’t have answer keys, how can the model figure out which of its own attempts are useful to learn from?
- How do we avoid the model “tricking itself” by always trusting the most common answer it gives, even when that answer is wrong?
How did they try to solve this?
Think of a classroom where there’s no answer key. A student (the AI) tries each question multiple times. The student then:
- Looks at all their different answers, not just the one they wrote most often.
- Punishes themselves a little when their answers are inconsistent or overconfident.
- Learns more from questions they seem more certain about, and less from ones where their attempts are all over the place.
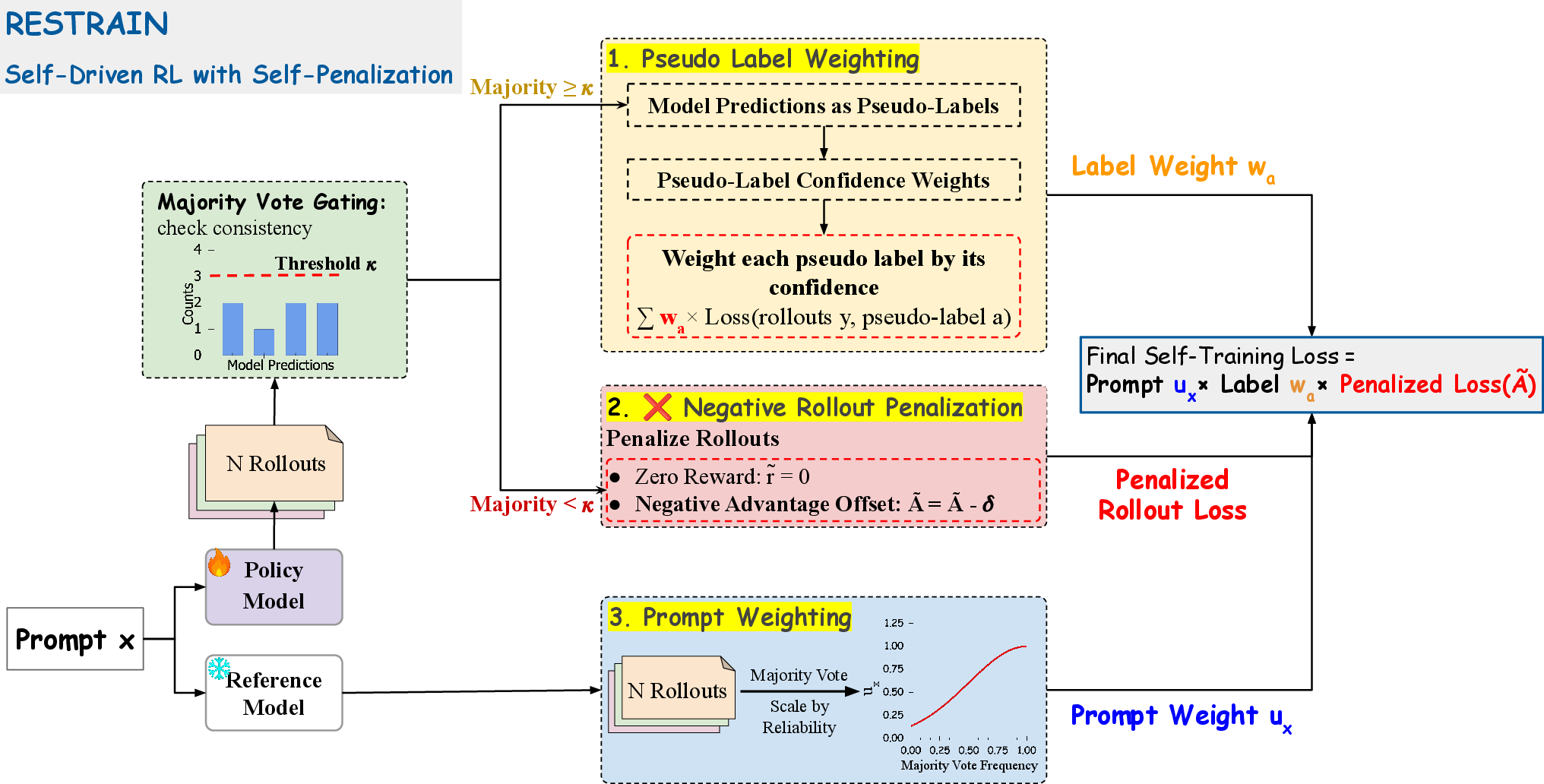
Here are the three main parts of RESTRAIN, with everyday explanations:
1) Pseudo-label weighting: Learn from all tries, not just the majority
- What it means: For each question, the model answers many times. Some answers repeat more than others. Instead of trusting only the most common answer (majority vote), RESTRAIN gives each different answer a weight based on how often it appears.
- Why it helps: Sometimes the “majority” is wrong. A rare answer might actually be the correct one. By considering all answers (but favoring the ones that show up more), the model learns from the full picture and avoids getting stuck on a wrong majority.
2) Negative rollout penalization: Don’t reward messy guessing
- What it means: If the model’s multiple tries for a question disagree a lot (low consistency), RESTRAIN treats the situation as “unreliable” and gently penalizes all those tries. This tells the model: “These paths weren’t helpful—try different reasoning next time.”
- Why it helps: It stops the model from reinforcing random or confused thinking. It nudges the model toward clearer, more dependable reasoning paths.
3) Prompt-level weighting: Trust confident questions more
- What it means: Some questions are ones the model is more consistent on; others are chaotic. RESTRAIN gives more training weight to questions where the model is more self-consistent (measured using a frozen “reference” model so it can’t cheat by inflating confidence while training).
- Why it helps: This avoids a feedback loop of learning from noise. It focuses learning on questions that offer clearer signals.
The training engine (GRPO), explained simply
- The model uses a type of reinforcement learning (think: “try, get feedback, adjust”) called GRPO. You can view it like practicing with a coach who compares your current approach to a safe baseline and encourages improvements while preventing wild changes. RESTRAIN plugs its “weights” and “penalties” into this engine so the model steadily improves without needing answer keys.
What did they find?
Across tough reasoning tests (math and science), RESTRAIN:
- Beat other “no-answer-key” methods by a lot. For example:
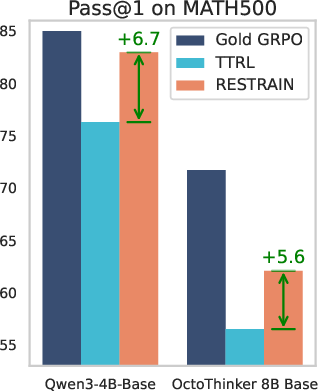
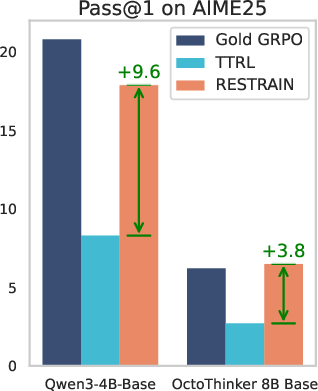
- Up to +140.7% improvement on AIME25 (a challenging math contest set).
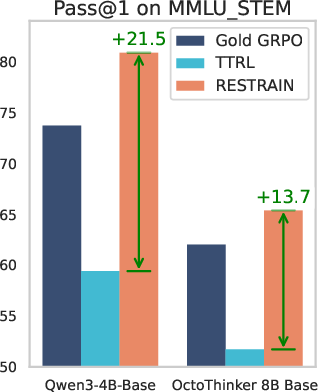
- +36.2% on MMLU-STEM (science and math subjects).
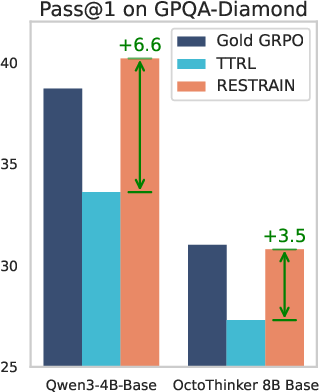
- +19.6% on GPQA-Diamond (graduate-level science questions).
- Nearly matched training that did use answer keys. On one model (Qwen3-4B-Base), RESTRAIN got an average score of 51.0% vs 51.4% for the “gold-label” (with answers) method—almost the same, but without labels.
- Sometimes even beat the “with-answer-keys” method on science tests like MMLU-STEM and GPQA-Diamond, suggesting better generalization beyond math.
- Worked well at test time too (adapting on the fly to new questions), outperforming other test-time methods on average.
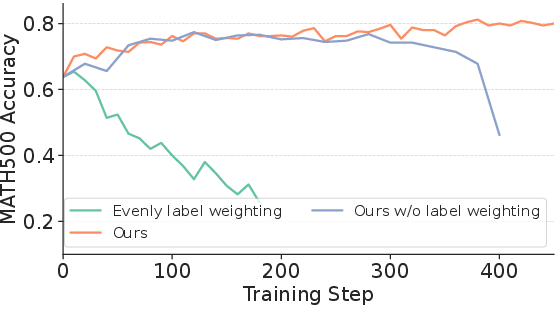
- Prevented “training collapse,” a problem where the model suddenly gets worse because it over-trusts its own wrong majorities. RESTRAIN stayed stable because it learns from all attempts and penalizes overconfident messiness.
What is “Pass@1”? It’s a score that checks whether the model’s top (first) answer to a question is correct. Higher means more questions solved on the first try.
Why is this important?
Getting human-labeled answers for huge numbers of complex problems is expensive—and sometimes impossible. RESTRAIN shows a way for AI models to keep improving their reasoning using unlabeled data by:
- Learning from the whole spread of their attempts (not just the majority).
- Penalizing overconfident or inconsistent answers.
- Focusing on clearer signals and skipping noisy ones.
This means we can build stronger reasoning AIs:
- With far fewer labeled examples.
- That generalize better to new subjects (not just what they were trained on).
- That avoid the trap of “the majority is always right.”
The big takeaway
RESTRAIN turns “no answer key” from a problem into a learning opportunity. By balancing self-trust with self-penalties, and by listening to all of its own answers (not just the loudest one), an AI can teach itself to reason more reliably—at scale, at lower cost, and sometimes even better than with traditional labeled training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several issues unresolved that future work could concretely address:
- Generalization beyond math-style QA: How to adapt RESTRAIN to open-ended generation, dialogue, and tasks without canonical final answers where majority-vote string matching is ill-defined.
- Answer normalization and equivalence: Robust, task-agnostic methods for canonicalizing outputs (e.g., symbolic math equivalence, units, paraphrase-invariant matching) during pseudo-label construction are not specified.
- High-consistency but wrong answers: Strategies to detect and avoid reinforcing confidently wrong majorities (e.g., via epistemic uncertainty, verifier signals, model ensembles) are not developed.
- Intermediate reasoning quality: RESTRAIN uses final-answer agreement; mechanisms to reward/penalize intermediate steps (self-checks, subgoal verification) to improve chain-of-thought fidelity are missing.
- Hyperparameter adaptivity: No principled method to adapt , , , to model size, rollout count , or dataset difficulty; rules for scaling with are unspecified.
- Theoretical guarantees: Lack of analysis on convergence, bias, and conditions where frequency-weighted pseudo-labeling improves expected task reward vs. majority-vote or entropy-based methods.
- Handling very low-consistency regimes: When or near-zero agreement, negative offsets may dominate; bootstrapping strategies to recover learning signal are not explored.
- Prompt-level weighting staleness: Offline prompt weights may become stale as the policy changes; safe online reweighting or periodic refresh strategies (without feedback loops) need design and evaluation.
- Penalty design alternatives: Uniform negative offsets for low-consistency prompts may over-penalize hard but valuable items; explore entropy/variance-adaptive or curriculum-aware penalties.
- KL regularization interplay: The role of KL coefficient selection with self-penalization is not ablated; guidelines for stability vs. exploration are absent.
- Reward hacking and distributional side effects: Whether the model learns to increase superficial diversity or length to avoid penalties is unmeasured; need analysis of entropy, length, and mode usage shifts.
- Calibration outcomes: Claims about mitigating overconfidence are not backed by calibration metrics (e.g., ECE, Brier); measure calibration before/after RESTRAIN.
- Sample efficiency and compute cost: Impact of rollout count on wall-clock cost, memory, and performance is not quantified; optimal under compute constraints is unknown.
- Data efficiency curves: How performance scales with the amount of unlabeled data vs. labeled supervision (to match gold labels) is not analyzed.
- Scaling to larger models: Results are limited to 4B/8B; behavior, stability, and cost at 30B–70B+ scales remain unknown.
- Robustness to dataset noise: Sensitivity to noisy or heterogeneous unlabeled corpora (domain shift, spurious patterns) is untested; need controlled noise and OOD ablations.
- Cross-domain generalization mechanism: The hypothesis that RESTRAIN reduces domain overfitting is not tested; controlled training on non-math corpora and transfer to math/science is needed.
- Comparative breadth: Direct comparisons to unlikelihood/negative-sampling RL (e.g., NSR), RLIF/entropy-based intrinsic rewards, and DPO/SCPO-style self-consistency methods at training time are missing.
- Algorithmic generality: RESTRAIN is only evaluated with GRPO; compatibility and performance with PPO+value functions, AWR, RPO, and DPO variants are not demonstrated.
- Function g(·) specification: The exact form and smoothing/prior (e.g., temperatured softmax, concave/convex transforms, Dirichlet smoothing) are under-specified; alternatives and their effects need study.
- Difficulty-aware curricula: No mechanism to upweight hard-but-informative prompts over training while avoiding early collapse; dynamic curricula could improve stability.
- Data leakage checks: Potential overlaps between DAPO-MATH and evaluation sets are not reported; rigorous decontamination procedures and release are needed.
- Evaluation protocol clarity: The use of “averaged over 16 seeds” vs. “16 samples per question” is ambiguous; standardized reporting and released seeds/checkpoints would aid reproducibility.
- Test-time RL generalization: Effects of repeated adaptation on the same test set and transfer to subsequent unseen tests are not analyzed; risk of overfitting at test time remains.
- Safety/alignment side effects: Impact on instruction-following, harmlessness, and hallucination rates is unmeasured; trade-offs with general capabilities should be evaluated.
- Multi-turn/tool-use/code extensions: How to integrate RESTRAIN with tool-augmented reasoning, unit tests (code), or program-of-thought verifiers to create stronger unsupervised signals is open.
- Multilingual and multimodal applicability: The method is not evaluated on multilingual prompts or multimodal reasoning; normalization and pseudo-labeling in those settings require design.
- Hard-instance retention vs. pruning: Negative penalization may suppress rare but correct minority solutions; methods to detect and preserve such signals (e.g., minority-consistent subchains) are needed.
- Interaction with decoding parameters: Training uses temperature sampling; evaluation uses both sampling and greedy in different settings; sensitivity to decoding choices is not quantified.
Practical Applications
Overview
Below are practical, real-world applications that follow from the paper’s findings and methods, organized into Immediate Applications (deployable now) and Long-Term Applications (requiring further research, scaling, or development). Each item notes relevant sectors and highlights tools, products, or workflows that could emerge, along with assumptions or dependencies affecting feasibility.
Immediate Applications
These applications can be deployed with existing LLMs, RL tooling, and unlabeled corpora, using the RESTRAIN components (pseudo-label weighting, negative rollout penalization, prompt-level weighting) within GRPO/PPO-style optimization.
- Label-free reasoning model fine-tuning to cut annotation costs
- Sectors: AI/Software, EdTech, Research Labs
- What emerges: “RESTRAIN trainer” module integrated into GRPO pipelines to fine-tune models on math/science reasoning without gold labels; soft consensus weighting over rollouts; stability safeguards to prevent collapse
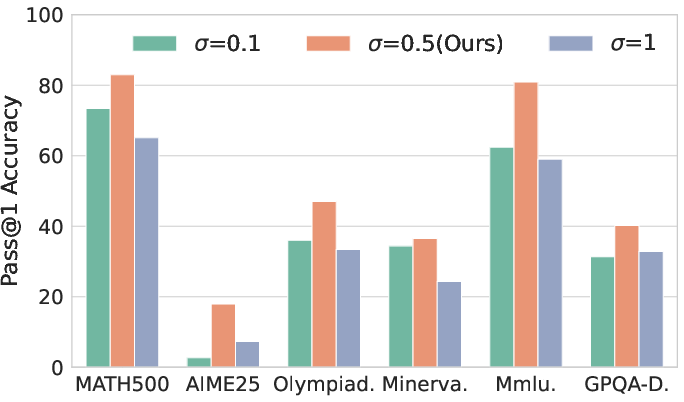
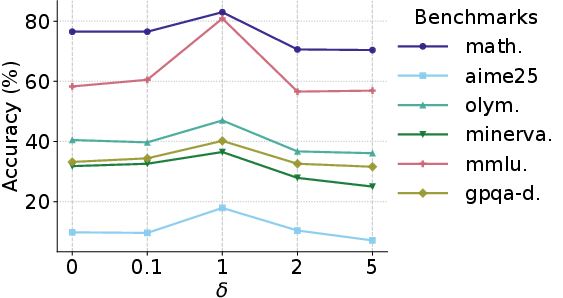
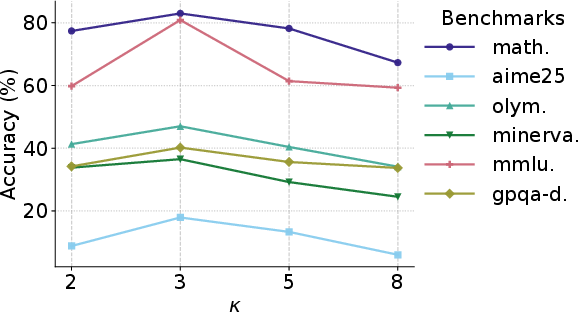
- Assumptions/Dependencies: Access to representative unlabeled prompts; compute for multi-rollout training; base model has baseline reasoning capability; careful hyperparameter tuning (σ, δ, κ)
- Test-time adaptation of LLMs on new task distributions without labels
- Sectors: Education (adaptive tutors), Software Operations (runbooks), Finance (analyst Q&A), Consulting
- What emerges: Inference-time RESTRAIN TTT add-on that uses multiple samples per prompt, reweights pseudo-labels, penalizes low-consistency cases, and updates a lightweight policy head or adapter; caching and latency-aware batching
- Assumptions/Dependencies: Permission to adapt using test-time data; latency/compute budget supports multi-rollouts; guardrails for data leakage and performance regressions
- Training stability controls for label-free RL
- Sectors: MLOps/Model Engineering
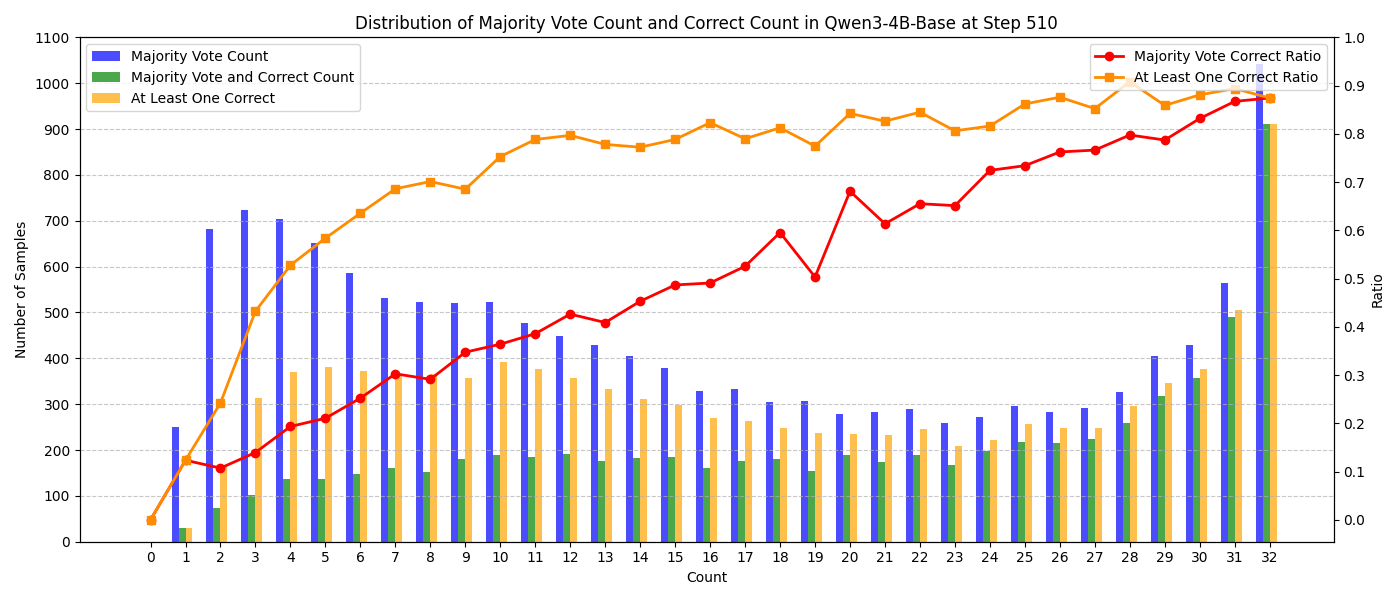
- What emerges: Self-consistency dashboards (majority-count histograms, Pass@n vs majority gaps), automated triggers for negative rollout penalization, prompt weighting precomputation services
- Assumptions/Dependencies: Monitoring infrastructure; ability to freeze/compare to a reference policy; operational playbooks for collapse recovery
- Curriculum and dataset weighting via offline prompt-level self-consistency
- Sectors: Data Engineering, EdTech
- What emerges: Dataset preprocessor that computes consensus with a frozen reference model; weights prompts to prioritize reliable signals and reduce wasted compute
- Assumptions/Dependencies: Reliable reference model; consistent formatting; weights remain fixed during training to avoid feedback loops
- Cost-aware replacement of portions of RLVR with RESTRAIN phases
- Sectors: AI Product Companies, Startups
- What emerges: Hybrid RL workflows where early or broad-domain phases are label-free (RESTRAIN) and domain-critical phases use gold labels; measurable savings on annotation without sacrificing accuracy
- Assumptions/Dependencies: Clear segmentation of tasks by risk/importance; robust evaluation; willingness to accept slightly lower peak accuracy in exchange for scale and cost gains
- Domain adaptation for knowledge-base and internal document reasoning
- Sectors: Enterprise Search/Knowledge Management
- What emerges: RESTRAIN fine-tuning on internal, unlabeled ask-answer logs to strengthen step-by-step reasoning over procedures, policies, and FAQs
- Assumptions/Dependencies: Data governance approval; de-identification; oversight to prevent amplifying spurious internal conventions
- EdTech tutoring systems that adapt to class-specific problem sets
- Sectors: Education
- What emerges: Tutor agents performing test-time RL on a school’s problem sets (e.g., AMC/MATH-type tasks), improving reasoning without labeled solutions; teachers can monitor consensus metrics
- Assumptions/Dependencies: Multi-rollout inference capacity; transparent reporting; optional teacher validation of “hard” or low-consensus problems
- Research replication and benchmarking expansion
- Sectors: Academia
- What emerges: Reproducible pipelines applying RESTRAIN to other open models (Qwen3, Llama family) and datasets (DAPO-MATH, synthetic S1k), including ablations of σ/δ/κ to characterize stability and transfer
- Assumptions/Dependencies: Open-source implementations or faithful re-implementations; standardized benchmarking; seed averaging practices
- Internal troubleshooting and incident reasoning assistants
- Sectors: DevOps/IT, SRE
- What emerges: On-the-fly adaptation to unlabeled incident tickets and runbooks via test-time RESTRAIN, improving step-by-step diagnosis; pseudo-label weighting reduces overcommitment to noisy patterns
- Assumptions/Dependencies: Data privacy and access controls; guardrails to avoid reinforcing outdated runbooks; engineer-in-the-loop review for critical incidents
- Annotation triage: where to invest human labeling
- Sectors: Data/Annotation Ops
- What emerges: Use majority size and prompt-level weights to automatically flag low-consistency prompts for human labeling, while allowing RESTRAIN to self-train on high-consistency prompts
- Assumptions/Dependencies: Human-in-the-loop workflows; well-defined thresholds; QA processes for labeled subsets
Long-Term Applications
These applications need stronger safety mechanisms, multimodal extensions, validation infrastructure, regulatory clarity, or scaled engineering to be reliable and widely deployable.
- High-stakes domain reasoning (clinical, legal, compliance) with hybrid rewards
- Sectors: Healthcare, Legal, Public Sector Compliance
- What emerges: Hybrid RL pipelines combining RESTRAIN’s self-penalization with verifiable proxy rewards (e.g., clinical calculators, statute checks), human oversight on low-consensus outputs, post-hoc verification
- Assumptions/Dependencies: Robust domain validators; rigorous safety audits; regulatory approvals; data access and privacy controls
- Privacy-preserving continual learning from production logs
- Sectors: Consumer Apps, Enterprise SaaS
- What emerges: Federated/on-device RESTRAIN for test-time adaptation without centralizing sensitive data; fixed prompt weights to avoid feedback loops; differentially private gradient accounting
- Assumptions/Dependencies: Efficient on-device compute; privacy tech (DP, secure aggregation); drift detection; governance policies
- Multimodal and embodied reasoning (code, tools, images, robotics)
- Sectors: Robotics, Autonomous Systems, Vision/Language, Software Engineering
- What emerges: Extensions of self-penalization to plan/action trajectories, multimodal rollouts, and tool-use; frequency-based weighting over candidate plans; negative penalization for low-consistency trajectories
- Assumptions/Dependencies: Environment simulators; telemetry for self-consistency; safe exploration constraints; integration with unit tests or simulators for partial verification
- Continuous training on live data with strong guardrails
- Sectors: MLOps Platform Providers
- What emerges: “Label-free RL-as-a-Service” platforms offering RESTRAIN-based continual training with data connectors, policy/reference model management, hyperparameter schedulers, and compliance tooling
- Assumptions/Dependencies: Data licensing; observability and rollback; legal agreements; robust model-versioning and audit trails
- Active learning loops to allocate human labels with maximal impact
- Sectors: Annotation Services, Research Labs
- What emerges: RESTRAIN-driven selection of ambiguous prompts (low majority size) for targeted human labeling, closing the gap to gold-label performance while minimizing cost
- Assumptions/Dependencies: Budget and process for human labeling; clear task specifications; integration with training pipelines
- Safety frameworks that extend negative penalization to risky content
- Sectors: Trust & Safety
- What emerges: Penalization of trajectories flagged by safety classifiers (toxicity, hallucination risk) alongside consensus-based penalties; safer self-improvement without labels
- Assumptions/Dependencies: High-precision safety detectors; calibration to avoid over-suppression; red-teaming; continuous evaluation
- Code-generation and software reasoning with partial verifiers
- Sectors: Software Engineering
- What emerges: RESTRAIN applied to code tasks using pseudo-label weighting across candidate solutions; negative penalization for low-consensus code plus partial verifiable signals (unit tests, static analysis) for hybrid rewards
- Assumptions/Dependencies: Test harness availability; realistic coverage; prevention of reward hacking; compute to run tests
- Financial analysis and decision-support with robust validation
- Sectors: Finance
- What emerges: Reasoning assistants that adapt to unlabeled filings/transcripts with RESTRAIN; hybrid validation via backtests or rule-based checks; human analyst oversight for low-consensus outputs
- Assumptions/Dependencies: High-quality domain data; compliance constraints; backtesting infrastructure; controls against spurious correlations
- Policy and standards for label-free, self-improving AI
- Sectors: Policy/Regulation, Standards Bodies
- What emerges: Audit frameworks for label-free RL (reporting self-consistency, penalization rates, transfer metrics), certification criteria for safe deployment, guidance on permissible test-time adaptation
- Assumptions/Dependencies: Multi-stakeholder consensus; benchmark toolkits; disclosure norms; legal recognition of audit artifacts
- Synthetic data generation loops with self-improvement
- Sectors: AI Research, Data Generation
- What emerges: Iterative CoT-Self-Instruct + RESTRAIN cycles to synthesize high-quality, diverse reasoning datasets with minimal human intervention
- Assumptions/Dependencies: Quality controls on synthetic data; measures against mode collapse; periodic human review; bias audits
Glossary
- Advantage: In policy-gradient RL, a centered estimate of how much better a sampled action (trajectory) performs compared to a baseline for the same state; it scales the policy update. Example: "For each rollout , we denote by reward with advantage ."
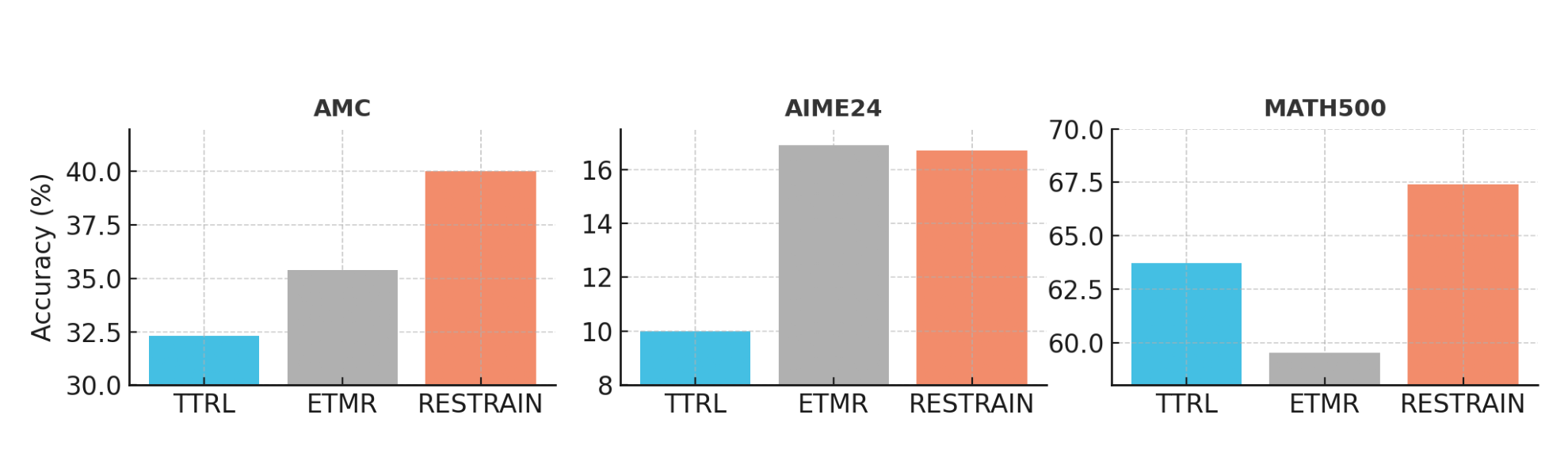
- AIME24: A test set of American Invitational Mathematics Examination 2024 problems used to assess mathematical reasoning. Example: "AIME24, AMC23, and MATH500"
- AIME25: A test set of American Invitational Mathematics Examination 2025 problems used for evaluation. Example: "+140.7% on AIME25"
- AMC23: A test set of American Mathematics Competitions 2023 problems used for evaluation. Example: "AIME24, AMC23, and MATH500"
- Chain-of-thought: A prompting and training paradigm that elicits step-by-step reasoning traces from LLMs to improve problem solving. Example: "chain-of-thought reasoning in large reasoning models"
- DAPO-14k-MATH: A 14k English-only split derived from the DAPO-Math dataset used for label-free RL training. Example: "Pass@1 of Qwen3-4B-Base and OctoThinker Hybrid-8B-Base trained on DAPO-14k-MATH without gold label."
- Entropy-fork Tree Majority Rollout (ETMR): A test-time RL method that uses entropy-guided branching and majority voting across rollouts to improve reasoning. Example: "Entropy-fork Tree Majority Rollout (ETMR)"
- Entropy-based Test-Time Reinforcement Learning (ETTRL): A method that balances exploration and exploitation at test time via entropy mechanisms to adapt LLMs without labels. Example: "Entropy-based Test-Time Reinforcement Learning (ETTRL) is an entropy-based strategy that improves test-time reinforcement learning for LLM reasoning."
- GPQA-Diamond: The hardest split of the GPQA benchmark with graduate-level science questions used to evaluate reasoning. Example: "GPQA-Diamond"
- Group-mean baseline: A variance-reduction baseline that centers rewards using the mean over a group of rollouts for the same prompt. Example: "using a group-mean baseline for variance reduction."
- Grouped Relative Policy Optimization (GRPO): A PPO-style RL algorithm that optimizes a policy relative to a frozen reference policy using grouped rollouts and a KL penalty. Example: "We adopt Grouped Relative Policy Optimization (GRPO) as our main RL algorithm."
- Kullback–Leibler divergence (KL divergence): A regularization term measuring how much the updated policy deviates from a reference policy during RL fine-tuning. Example: "-\beta \mathbb{D}{K L}\left[\pi\theta \| \pi_\text{ref}\right]"
- MATH500: A 500-problem subset of the MATH dataset used as a standardized math reasoning benchmark. Example: "MATH500"
- Majority vote: A self-consistency heuristic that selects the most frequent answer among multiple model rollouts; can be unreliable on hard tasks. Example: "majority votes can be spurious"
- Minerva_math: The mathematics split from the Minerva quantitative reasoning suite used for evaluation. Example: "Minerva_math"
- MMLU_STEM: The STEM categories from the MMLU benchmark suite used to evaluate scientific reasoning. Example: "MMLU_STEM"
- Negative rollout penalization: A self-penalizing mechanism that assigns negative advantages (penalties) to all rollouts when self-consistency is low, discouraging unreliable reasoning paths. Example: "we introduce negative rollout penalization"
- Nucleus (top-p) sampling: A decoding strategy that samples tokens from the smallest set whose cumulative probability exceeds p, controlling diversity. Example: "top- value of 0.95"
- Pass@1: The probability that the first sampled solution is correct; commonly used to report single-shot accuracy. Example: "Pass@1"
- Pass@n: The probability that at least one of n independent samples is correct; used to measure multi-try success. Example: "leverages control of Pass@n"
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm with clipped objectives to stabilize updates; GRPO uses a “PPO-style objective.” Example: "updating with a PPO-style objective"
- Prompt-level weighting: Scaling the contribution of each training prompt in RL updates by a precomputed confidence weight based on the reference model’s self-consistency. Example: "Prompt-level weighting"
- Pseudo-label weighting: A scheme that assigns soft weights to all distinct predicted answers proportional to their vote frequencies, avoiding collapse to a single majority label. Example: "Pseudo-label weighting"
- Reference policy: A frozen policy used as an anchor during RL fine-tuning to constrain updates via KL regularization. Example: "against a fixed reference policy "
- Reinforcement Learning from AI Feedback (RLAIF): RL that aligns models using feedback generated by AI systems rather than humans. Example: "and from AI feedback (RLAIF)"
- Reinforcement Learning from Human Feedback (RLHF): RL that aligns models to human preferences via preference data and learned reward models. Example: "RL from human feedback (RLHF)"
- Reinforcement Learning from Internal Feedback (RLIF): Unsupervised RL approaches that derive intrinsic rewards from a model’s own signals (e.g., entropy, confidence). Example: "Reinforcement Learning from Internal Feedback (RLIF)."
- Reinforcement Learning with Verifiable Rewards (RLVR): RL settings where model outputs can be automatically checked against ground truth or validators to compute rewards. Example: "verifiable rewards (RLVR)"
- Rollout: A sampled trajectory or complete generated answer from a policy for a given prompt, used to compute rewards and advantages. Example: "sampling rollouts per prompt "
- Self-consistency: The degree of agreement among multiple independent generations for the same prompt; used as a proxy for confidence. Example: "low self-consistency"
- Self-penalization: Training that explicitly applies negative updates to discourage low-confidence or inconsistent outputs in the absence of gold labels. Example: "This self-penalization mechanism integrates seamlessly into policy optimization methods"
- Self-Rewarded Training (SRT): A label-free training approach where the model leverages its own signals (e.g., majority labels or difficulty) to guide learning. Example: "Self-Rewarded Training (SRT)"
- Test-time training: Adapting a model on-the-fly using only the test inputs (and no labels) to improve performance on those inputs. Example: "Test-time training Llama3.1-8B-Instruct using unlabeled test data"
- TTRL: Test-Time Reinforcement Learning; a label-free RL method that typically reinforces the majority-voted answer during test-time adaptation. Example: "TTRL"
- Unlikelihood training: A learning technique that penalizes generating undesirable tokens or trajectories by decreasing their likelihood. Example: "Unlikelihood training is a widely adopted technique in neural text generation to penalize undesirable outputs."
Collections
Sign up for free to add this paper to one or more collections.

