- The paper introduces a Bayesian framework that optimizes ensemble diffusion priors by tuning exponent weights from a single measurement.
- It leverages unbiased gradient estimation via sampling and annealed MCMC to efficiently maximize the evidence field.
- Empirical validations in black hole imaging and text-conditioned tasks demonstrate robust and interpretable posterior calibrations.
Optimizing Diffusion Priors in Image Reconstruction from a Single Observation
Inverse imaging challenges—where the observation operator is ill-posed or severely underdetermined—demand accurate priors to regularize solution spaces. Diffusion models have become the de facto high-fidelity generative priors. However, such models are typically trained on limited or biased datasets, resulting in model mismatch: the learned prior p(x) often does not coincide with the distribution of the sought-after ground-truth images. Over-reliance on a fixed, potentially misspecified diffusion prior risks introducing bias and overconfident posterior estimates, especially for measurements outside the training distribution.
The paper proposes a principled Bayesian approach: given only a single measurement y, ensembled priors are formed by exponentiating and combining n candidate diffusion models in a product-of-experts form, πa(x)∝∏i=1npi(x)ai. The central objective is to identify exponents ai that maximize the model's Bayesian evidence for the given observation,
logpa(y)=log∫p(y∣x)πa(x)dx,
thus meaningfully tuning both prior strength and composition in a data-driven and interpretable manner.
Evidence Field Estimation and Exponent Optimization
Gradient Estimation via Sampling
A key technical contribution is an efficient and unbiased estimation of the evidence gradient with respect to the prior exponents. The evidence gradient with respect to component i is given by
∂ai∂logpa(y)=Ex∼πa(x∣y)[logpi(x)]−Ex∼πa(x)[logpi(x)],
computed empirically using unconditional and posterior samples generated from the current product prior (see Algorithm 1).
Product-of-Experts Sampling with Diffusion Models
Sampling from the tempered product prior is tackled using annealed MCMC over the model marginals πa(xt), leveraging an effective noise schedule for stability and mixing. The predictor step exploits score information from all constituent diffusion models, weighted with the current exponents, and is justified by the equivalence to sampling from an ensemble Gaussian under specific assumptions.
For posterior sampling, the approach anneals along the path πa(xt)p(y∣μπ(xt))βt, efficiently transitioning between prior and posterior while ensuring appropriate data fit. Exploiting the surrogate denoiser mean given by a generalized Tweedie's formula further improves mixing speed and estimator quality.
Scalar Field Reconstruction and EM Optimization
When only two priors are considered, the evidence field over exponent combinations can be reconstructed via grid-based finite differences and least-squares integration, with robust handling of gradient stochasticity. For higher-dimensional exponents or increased computational efficiency, a generalized expectation-maximization (EM) strategy is developed (Algorithm 2): evidence gradients guide a local ascent procedure, efficiently finding interpretable exponent vectors maximizing the evidence.
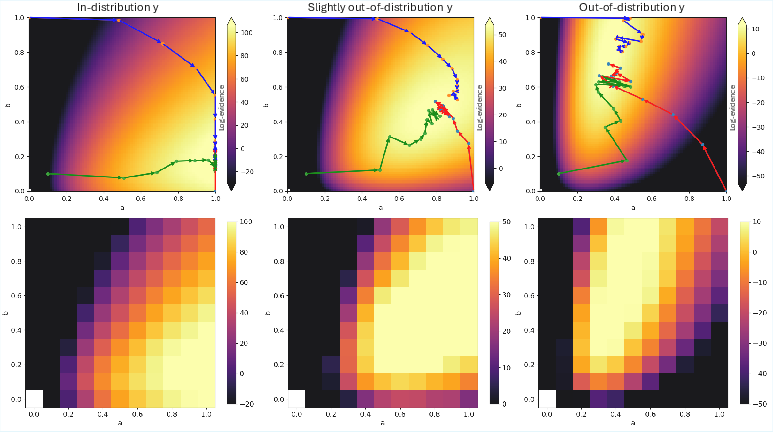
Figure 1: Expectation-maximization trajectories and reconstructed evidence field demonstrate accurate maximization of Bayesian evidence with product-of-Gaussian priors in toy high-dimensional settings.
Empirical Validation and Experimental Results
Gaussian Toy Model
The methodology is first substantiated on controlled high-dimensional (1000-D) Gaussian product priors, where the analytic evidence field and optimum are available. Both grid-based and EM-based exponent optimization rapidly converge to the true evidence maximizer, with empirical fields nearly indistinguishable from analytical ground truth, demonstrating robustness to the curse of dimensionality and estimator noise.
Black Hole Imaging
A central application is EHT-style black hole imaging, where the dominant scientific prior (GRMHD-based models) is necessarily incomplete. Sparse interferometric measurements are reconstructed under ensembles containing:
- A strong, physics-based GRMHD prior
- A broad astrophysical image prior
- A synthetic regularization prior (e.g., MNIST 0's to simulate alternative ring structures)
The evidence-maximizing exponents frequently identify improved posterior distributions away from using the GRMHD prior alone, either by tempering it (relaxing its confidence/strength) or combining it with a generic space prior. The approach quantitatively and visually improves coverage of unusual or slightly out-of-distribution features, enhancing the trustworthiness and physical plausibility of posteriors.
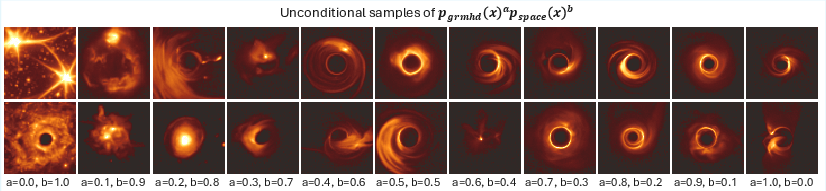
Figure 2: Samples from the product of GRMHD and space diffusion priors illustrate how combinatorial exponentiation generates plausible black hole image samples outside the standard training regime.
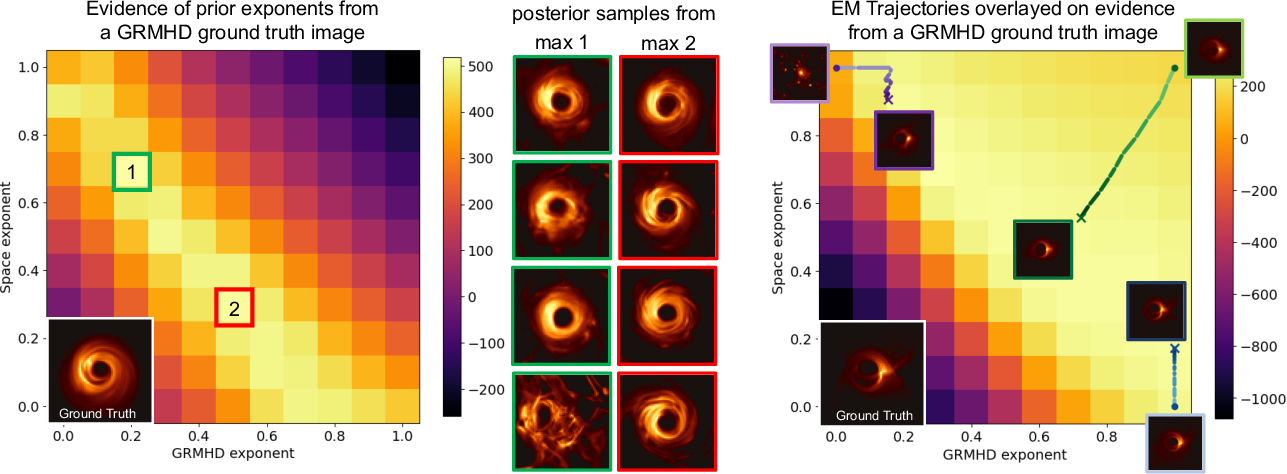
Figure 3: Evidence fields for in-distribution GRMHD images show (left) evidence maximization via prior tempering and space prior combination in atypical cases, and (right) favor sharpening the prior in highly typical cases, with EM trajectories converging to high-evidence regions.
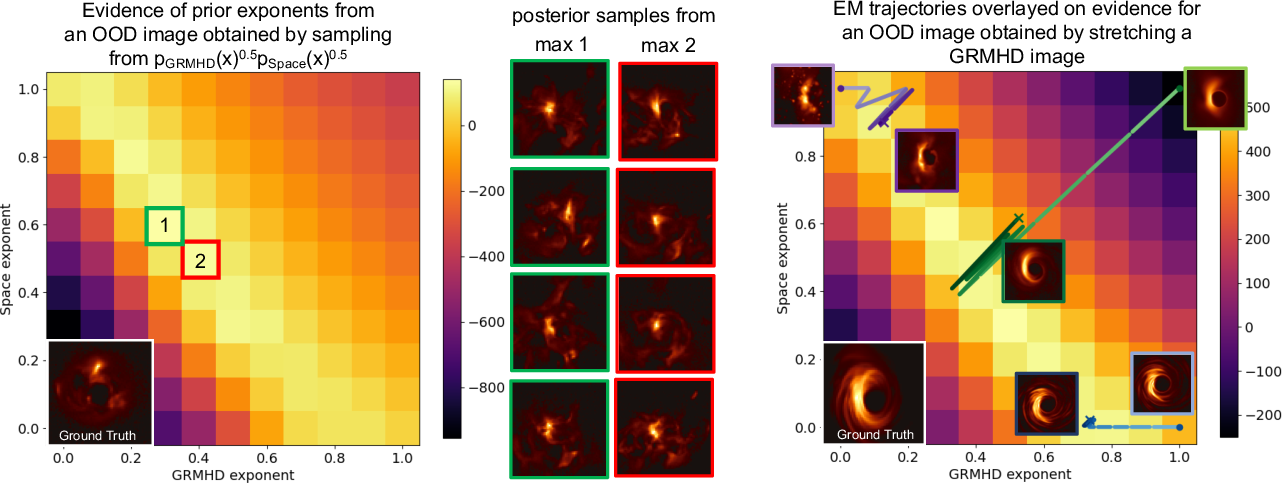
Figure 4: Slightly out-of-distribution cases validate evidence field localization to ground-truth exponents (left) and robust maximization by relaxed or combined priors (right).
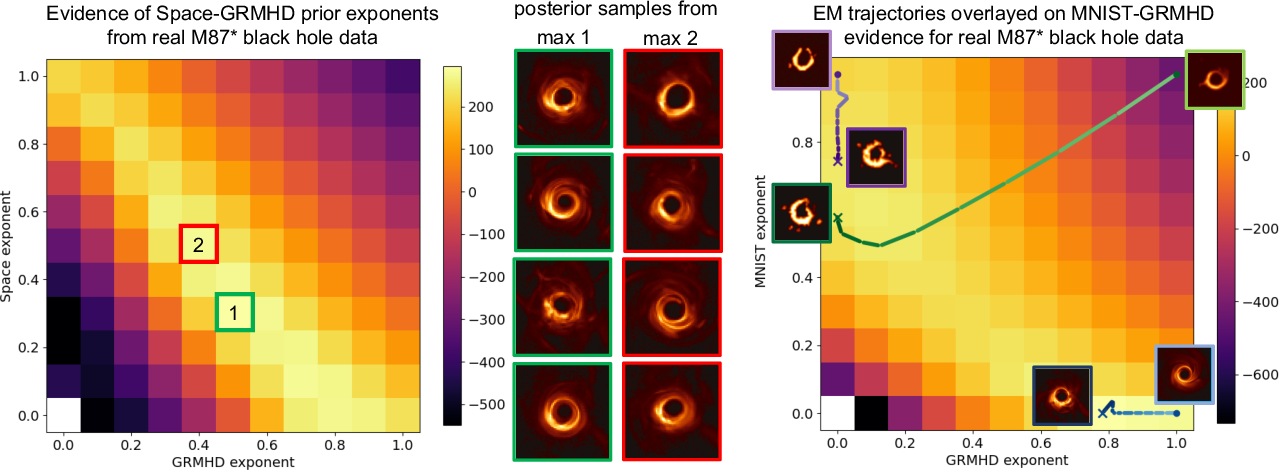
Figure 5: Evidence fields for real M87
observations show that maximum Bayesian evidence is obtained by tempering the GRMHD prior or combining with more general priors; secondary local maxima (right) reveal the landscape of plausible regularization.*
Text-Conditioned Posterior Sampling
The extension to semantic or text-conditioned priors is demonstrated with Stable Diffusion. In challenging deblurring setups, EM-optimized products of text-conditioned priors robustly and interpretably discover the underlying semantic composition of the measurement, e.g., converging to high weights on "golden retriever" and "corgi" (with negative weight on "poodle") for a mixed-breed dog, or on "cathedral" and "temple" for a photo of Sacré-Cœur. This simultaneously improves reconstruction fidelity and provides a semantically meaningful posterior structure.

Figure 6: EM optimization exponents and corresponding reconstructions for a mixed-breed dog indicate semantic identification and correct negation of unrelated text priors.

Figure 7: EM dynamics for a real-world church image highlight the convergence to interpretable exponent weights on relevant architectural text priors and visual refinement of semantic reconstruction.
Comparison to Finetuning and Baseline Methods
The paper also includes ablation studies showing that naive finetuning of priors based on a single measurement (as in existing diffusion EM finetuning methods) results in overfitting and collapsed, untrustworthy priors, with unconditional samples converging to singular modes capturing noise and null space structure. The principled evidence-maximization over prior exponents avoids this collapse and delivers more calibrated posteriors by confining adaptation within the convex hull of interpretable, pretrained priors.

Figure 8: Single-measurement diffusion EM finetuning leads to overfitting, with the prior collapsing onto the likelihood and losing uncertainty quantification.
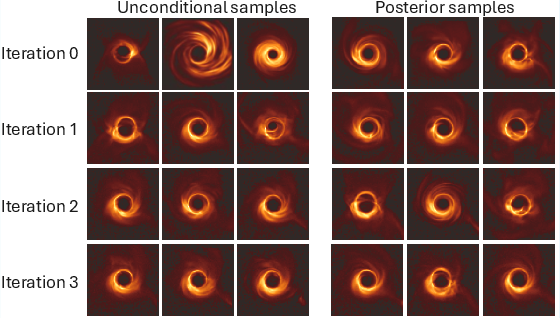
Figure 9: Diffusion finetuning on real M87
data shows the prior narrowing at each EM iteration—ultimately resulting in a degenerate, overfitted distribution.*
Practical and Theoretical Implications
From a theoretical perspective, this framework formalizes prior selection as an observation-driven inference problem over a continuous evidence surface, rather than an arbitrary or hard-coded modeling choice. Exponent optimization over product-of-experts diffusion priors yields an evidence-based trade-off between specificity and generality. Practically, the technique addresses the challenge of robustly adapting priors with only a single measurement, outperforming naive finetuning.
The method is agnostic to the specific choice of pretrained diffusion models and forward operators, making it suitable for a broad range of imaging/inverse problems where data scarcity and model bias are critical concerns—especially in scientific domains where ground-truth distributions are fundamentally unverifiable.
Furthermore, evidence field mapping mechanisms provide insight into the "landscape" of prior plausibility and model misspecification. The identified local and global maxima afford a quantification of how much prior structure is justified by the data, distinguishing between trustable regularization and potential inadvertent hallucination or overconfidence.
Future Directions
Extensions could include integrating larger or more diverse prior sets, structured prior graphs (beyond flat product forms), or generalized hierarchical Bayesian optimization over more complex regularizer bases. Further work might also explore tight integration with advances in posterior sampling (e.g., SMC, Feynman-Kac correctors) and adaptive, online exponent tuning in multi-observation or time-varying settings.
Conclusion
The paper establishes a rigorous, data-adaptive methodology for tuning ensemble diffusion priors in severely ill-posed inverse problems. By maximizing Bayesian evidence over exponentiated product-of-experts priors—using efficient score-based sampling and robust gradient estimation—the approach significantly improves posterior calibration and interpretability, especially in single-observation regimes subject to training set limitations and model misspecification. These insights shift the paradigm of prior selection toward evidence-driven inference and offer robust empirical advantages for practical scientific imaging tasks where ground truth is elusive.
(2604.21066)