- The paper presents DASH-Q, a PTQ method focusing on statistically stable diagonal Hessian estimation to mitigate noise in ultra low-bit quantization.
- It reformulates quantization as group-wise independent weighted least squares, achieving up to 14.01 percentage points improvement in zero-shot reasoning accuracy.
- DASH-Q is efficient and resilient, reducing quantization time up to 74.5× faster and maintaining perplexity stability even with minimal calibration data.
Robust Ultra Low-Bit Post-Training Quantization via Stable Diagonal Curvature Estimate
Introduction and Motivation
The paper "Robust Ultra Low-Bit Post-Training Quantization via Stable Diagonal Curvature Estimate" (2604.13806) addresses the longstanding challenge of deploying LLMs in resource-constrained environments, specifically focusing on the robustness of PTQ for ultra low-bit weight quantization. While traditional Hessian-based PTQ approaches, including GPTQ, utilize full Hessian matrices estimated from limited calibration data for error compensation, the authors demonstrate that these methods suffer significant degradation at low bit-widths. The core finding is that off-diagonal Hessian entries are highly sensitive to sampling noise and lack statistical stability across calibration batches, whereas diagonal entries exhibit batch-stable behavior.
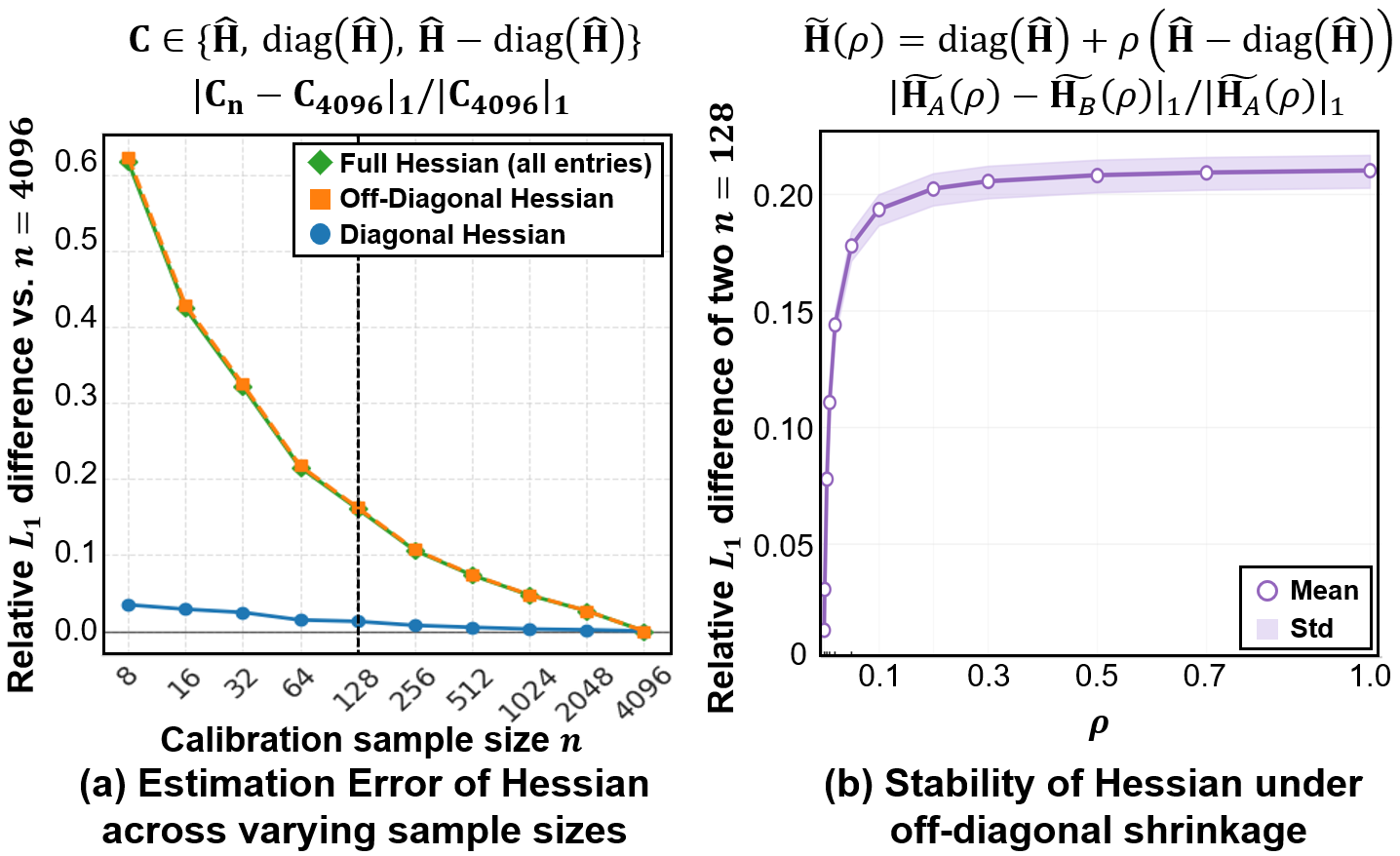
Figure 1: Relative ℓ1 error of Hessian estimates in Llama-2-7B, showing rapid stabilization for diagonal entries and persistent instability for off-diagonal entries.
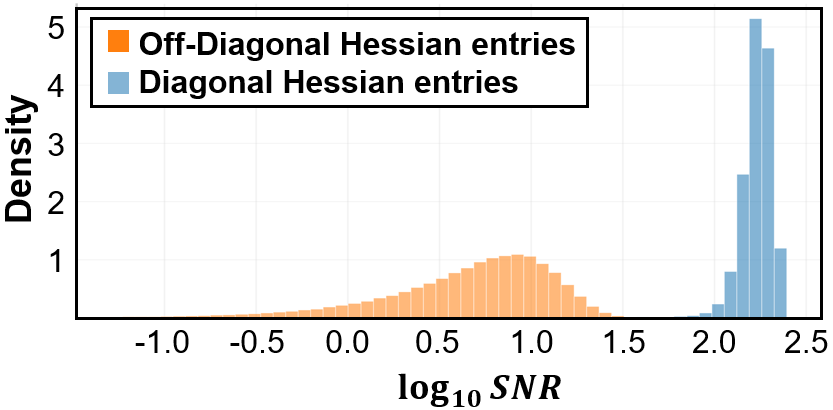
Figure 2: Normalized histogram of SNR for diagonal and off-diagonal Hessian entries; diagonals exhibit high SNR, validating their statistical reliability.
Statistically, the paper quantifies signal-to-noise ratio (SNR) for individual Hessian entries, finding that off-diagonal terms are dominated by noise. This instability in estimating cross-feature curvature leads to unreliable quantization error compensation and loss of downstream accuracy, particularly in ultra low-bit regimes and under restricted calibration data.
Proposed Method: DASH-Q
The authors introduce DASH-Q, a PTQ framework that exploits only diagonal Hessian approximation, discarding noise-prone feature correlations to achieve robust calibration. The diagonal Hessian enables quantization to be reformulated as group-wise independent weighted least squares, directly prioritizing the preservation of salient features based on their importance. The method solves for quantization scale and zero-point parameters in closed-form under a ridge-regularized objective, with iterative refinement via coordinate descent.
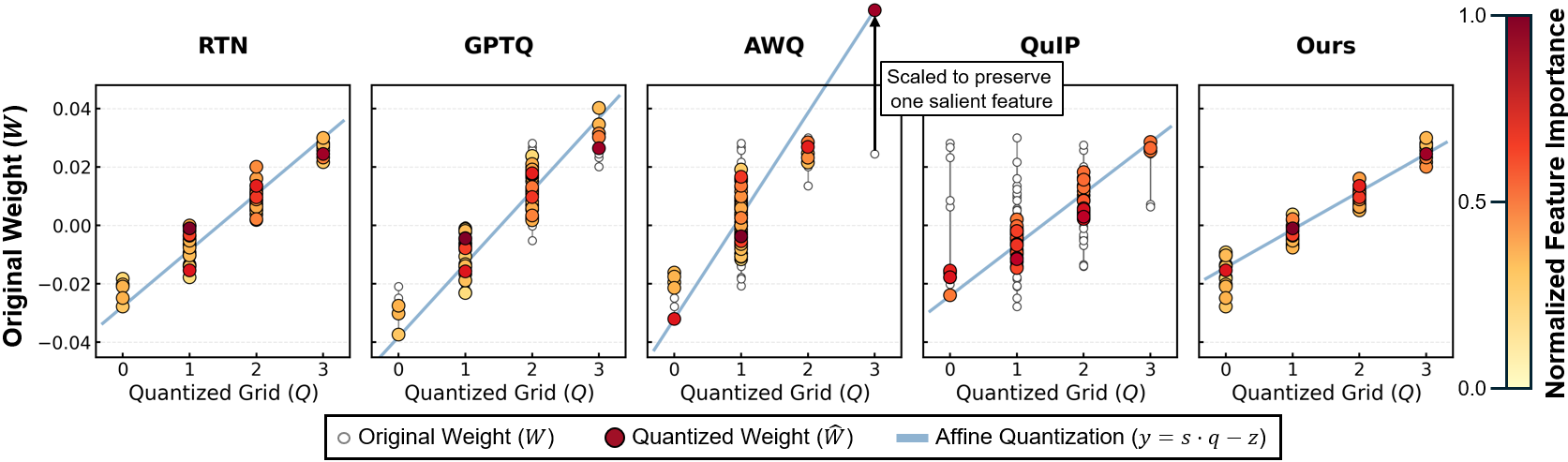
Figure 3: Mapping of weights (W) to quantized levels (Q) under DASH-Q's affine mapping, colored by normalized log importance (diagonal Hessian signal).
By focusing exclusively on statistically robust diagonal curvature signals, DASH-Q systematically filters out batch-sensitive noise, ensuring consistent accuracy across calibration variations. The method maintains compatibility with standard inference engines: weights are quantized in the conventional affine form without introducing outlier-aware or rotation-based inference-time overhead.
Evaluation and Numerical Results
Extensive benchmarking is conducted on six LLMs (Llama-3.1-8B-Instruct, Qwen3-14B, DeepSeek-MoE-16B, Phi-3.5-MoE, Mixtral-8x7B, Llama-2-7B) over multiple zero-shot reasoning benchmarks, WikiText-2 perplexity, and quantization time. DASH-Q is compared to RTN, AWQ, GPTQ, QuIP, QuaRot, and OWQ under 2-, 3-, and 4-bit settings.
Key numerical findings include:
- Ultra Low-Bit Robustness: DASH-Q achieves the highest average zero-shot reasoning accuracy in the 2-bit regime across all models, outperforming the strongest baselines by up to 14.01 percentage points and 1.33× relative improvement (e.g., on Llama-3.1-8B, Qwen3-14B, DeepSeek-MoE-16B).
- Calibration Efficiency: DASH-Q is highly resilient to calibration data scarcity; perplexity remains stable even with extremely small calibration sets (n≤4), whereas full-Hessian PTQ approaches diverge (Figure 4).
- Quantization Overhead: The method is up to 74.5× faster in quantization time than optimization-based baselines.
- Downstream Performance: DASH-Q maintains strong perplexity scores and preserves reasoning quality better than rotation- and outlier-aware methods, especially under aggressive compression constraints.
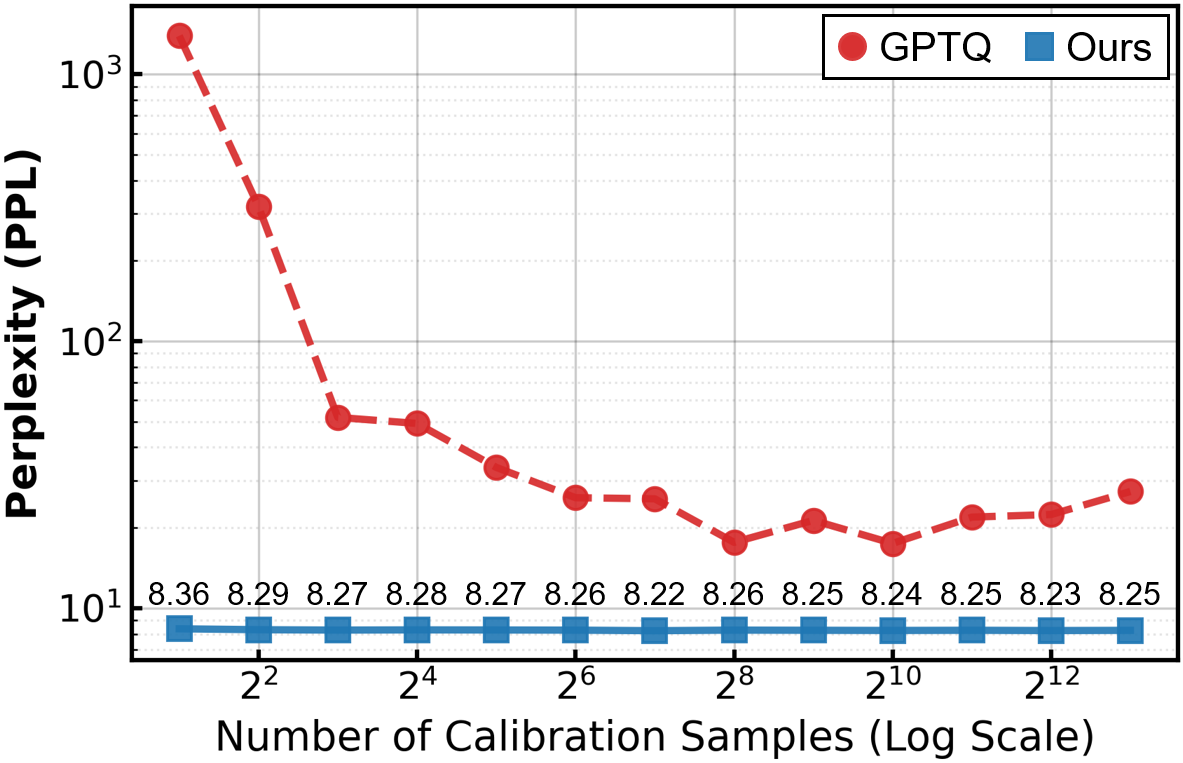
Figure 4: Comparison of perplexity between DASH-Q and GPTQ under varying calibration sizes, highlighting DASH-Q's robustness against data scarcity.
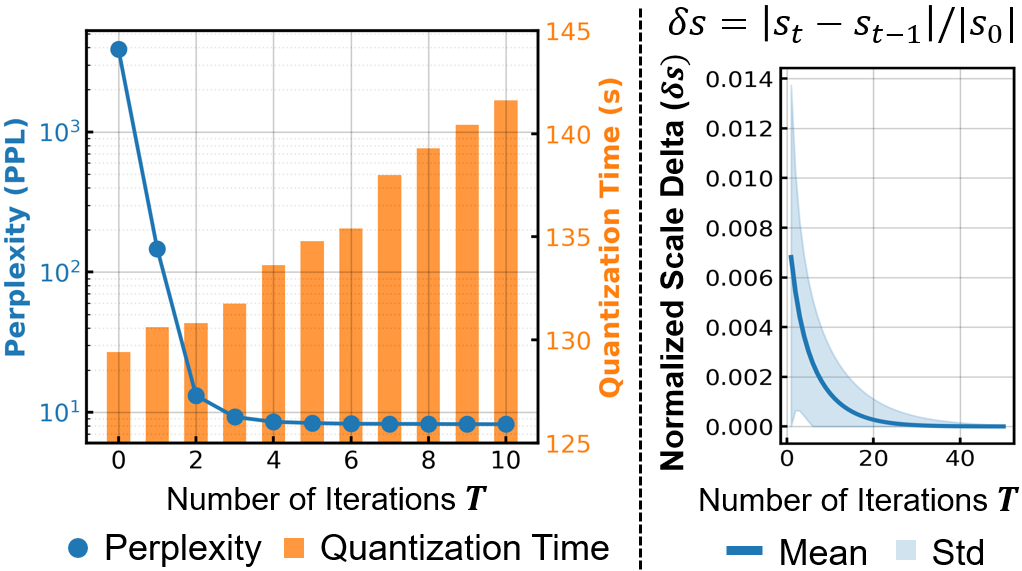
Figure 5: Left: Perplexity and quantization time by iteration. Right: Convergence of scaling factors for important weight groups in DASH-Q, with rapid early stabilization.
Qualitative visualization (Figure 3) demonstrates that DASH-Q aligns salient weights tightly to quantization bins, in contrast to grid collapse and rounding errors evident in baselines, providing direct evidence of superior importance preservation.
Theoretical and Practical Implications
The findings assert that statistical stability—not merely second-order expressivity—should guide the design of PTQ solvers. The diagonal Hessian approximation, while increasing bias, mitigates variance and achieves consistent downstream accuracy unattainable with noisy cross-feature compensation. The work calls into question the long-held assumption that full Hessian error propagation is universally optimal for quantization, especially in ultra-low precision and limited calibration contexts.
Practically, the compatibility of DASH-Q with standard inference and quantized backends (including vLLM, TensorRT-LLM, Marlin, GemLite) makes it attractive for real-world deployment of compressed LLMs, avoiding the integration complexity and runtime overhead of rotation or outlier-aware schemes.
Directions for Future Research
Potential future avenues include adaptive diagonal weighting using model- or data-driven importance priors, mixed-precision schemes dynamically allocating bits based on diagonal signal, and further investigation into the mismatch between token-level metrics (perplexity) and instruction-following utility in compressed generative models. The theoretical trade-offs between bias and variance in quantization parameter estimation may generalize to other modalities and architectures beyond transformers.
Conclusion
DASH-Q represents a statistically principled approach to PTQ for ultra low-bit quantization, grounded in the batch stability of diagonal Hessian estimation. By reframing quantization as importance-weighted regression, it achieves dominant accuracy, robust calibration and low overhead across benchmark LLMs, outperforming state-of-the-art Hessian and rotation-based baselines. The work underscores the criticality of statistical robustness in low-bit quantization and offers a scalable solution for practical compressed LLM deployment (2604.13806).