Training Dynamics Impact Post-Training Quantization Robustness
Abstract: While post-training quantization is widely adopted for efficient deployment of LLMs, the mechanisms underlying quantization robustness remain unclear. We conduct a comprehensive analysis of quantization degradation across open-source LLM training trajectories up to 32B parameters and 15T training tokens to accurately assess the relationship between training dynamics and quantization performance. Our key finding is that quantization errors in large-scale training runs are driven by a complex interplay between learning rate and other training hyperparameters. Specifically, once learning rates decay, validation loss and quantization error diverge, largely independent of training data scale. To investigate interventions on the training dynamics and identify specific configurations that can modulate quantization robustness favorably, we train our own models in controlled experiments up to 100B tokens. Our results challenge the assumption that increasing dataset scale inherently compromises quantization effectiveness, demonstrating instead that strategic training hyperparameter interventions can improve quantization quality at scale.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a practical problem: how to shrink LLMs so they run faster and use less memory, without breaking their accuracy. The shrinking step is called post‑training quantization (PTQ). The authors discovered that how a model is trained—especially how its learning rate is changed over time—strongly affects whether it can be quantized well. In short: training choices can make a model either easy or hard to compress after training.
Key questions the paper asks
- Why do some models lose more accuracy than others when we compress them after training?
- Is the loss from quantization mainly about the amount of data a model was trained on, or about the training settings (like the learning rate)?
- Can we change training choices to make models more robust to low‑bit quantization (like 3‑bit or 4‑bit)?
How they studied it (methods explained simply)
Think of a trained model like a big, high‑resolution photo. Quantization is like reducing the photo’s resolution so it takes less space. After shrinking, they check how much detail was lost.
The authors did two kinds of studies:
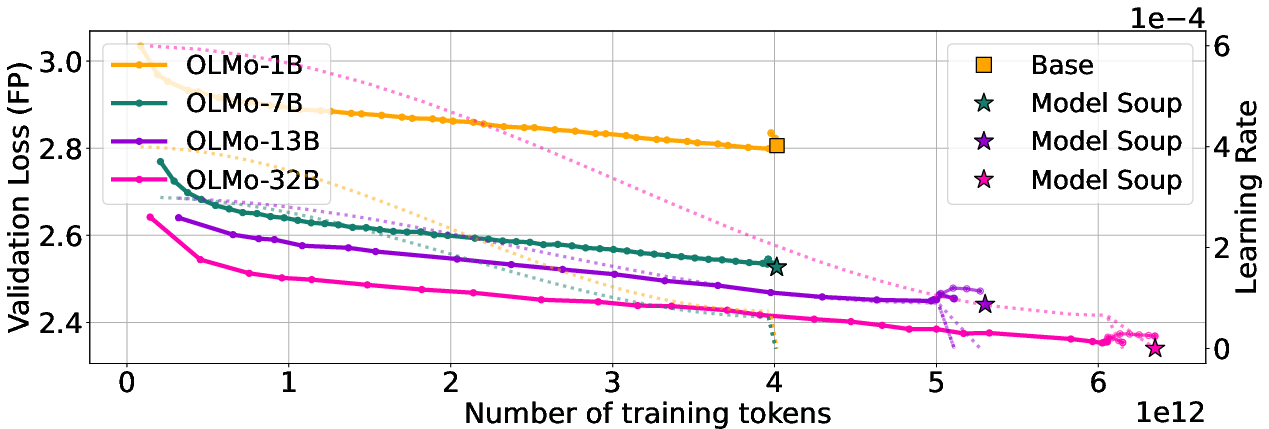
- “In the wild”: They measured quantization effects across many open‑source LLMs (some very big) at many points in their training. They tracked:
- Validation loss: how wrong the model is on a test set (lower is better).
- Quantization error: how much worse the model gets after shrinking to 3‑bit or 4‑bit precision.
- Learning rate (LR): like a “speed” knob for learning; high LR learns faster, low LR learns slower. They watched how LR schedules (constant, cosine decay, warmup‑stable‑decay) related to quantization.
- Controlled experiments: They trained smaller models themselves and changed one thing at a time—like the LR value, the LR schedule, the amount of data, weight averaging, optimizer type, and weight decay. This helped them isolate what really causes quantization problems.
Some helpful analogies:
- Quantization: rounding numbers to fewer digits. The fewer bits (like 3 or 4), the more rounding and potential error.
- Learning rate schedule: like a training plan that gradually turns down the learning speed—similar to a runner slowing down near the end of a long race to avoid overexertion.
- Weight averaging (including “model soup”): imagine taking snapshots of the model at different times and averaging them, like blending multiple recipes to get a smoother final dish.
They mostly used a popular PTQ method called GPTQ and focused on 3‑bit and 4‑bit quantization. They also checked other quantization methods (AWQ, BitsAndBytes) and found similar trends.
Main findings and why they matter
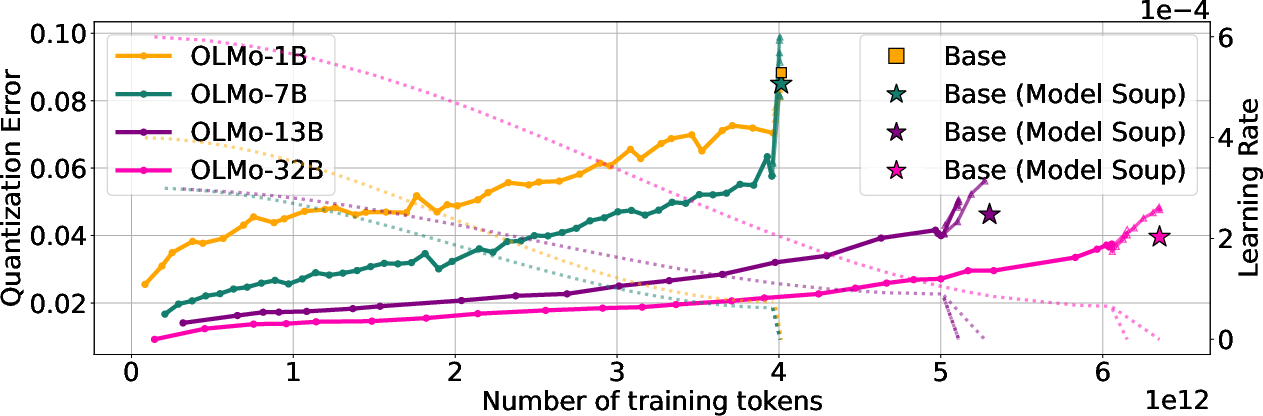
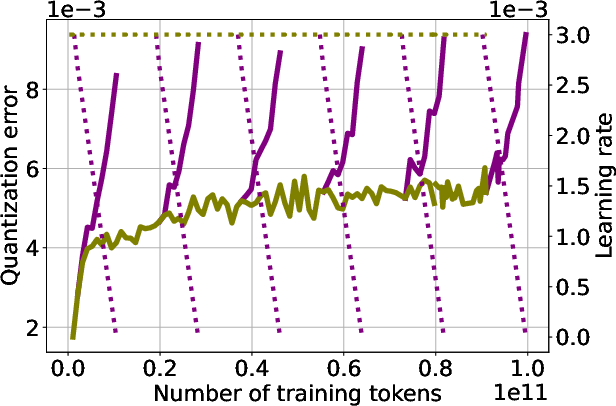
1) When the learning rate starts to decay, quantization error spikes
- Across many real training runs, the accuracy drop from quantization suddenly gets worse when LR is lowered at the end of training.
- Meanwhile, validation loss keeps improving (the uncompressed model gets better), but the compressed version gets more fragile.
- This pattern shows up regardless of how much data the model sees.
Why it matters: It’s not just “more data causes worse quantization.” The end‑of‑training LR decay plays a key role in making models harder to compress.
2) Data size isn’t the main culprit; training dynamics are
- Earlier work claimed that training on more data makes quantization worse.
- This paper shows that claim mixes together data size with LR schedule effects. When you control for LR schedules, the “more data = worse quantization” story weakens.
- The spike in quantization error aligns with LR decay rather than with total tokens seen.
Why it matters: Future giant models aren’t doomed to bad quantization. With smart training choices, they can still be compressed well.
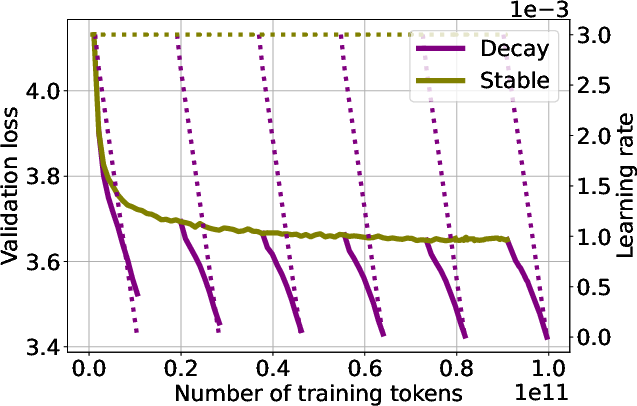
3) Keeping a larger learning rate longer improves quantization robustness
- In controlled tests, higher peak LRs and schedules that avoid extremely tiny LRs near the end tend to give models that compress better, without hurting full‑precision performance.
- Between two runs with similar validation loss, the one with a higher LR often quantizes better.
Why it matters: If two training setups tie on accuracy, pick the one with the higher LR—you’ll likely get a more compressible model.
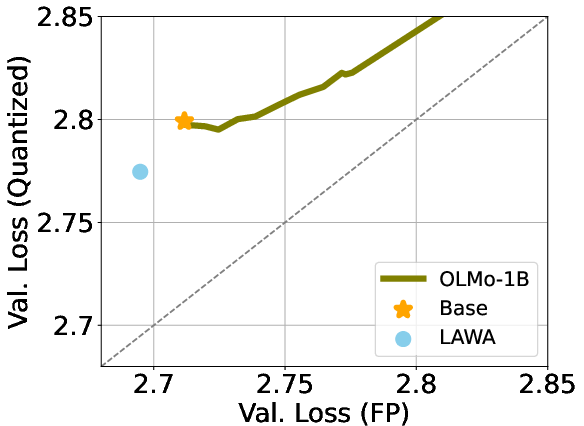
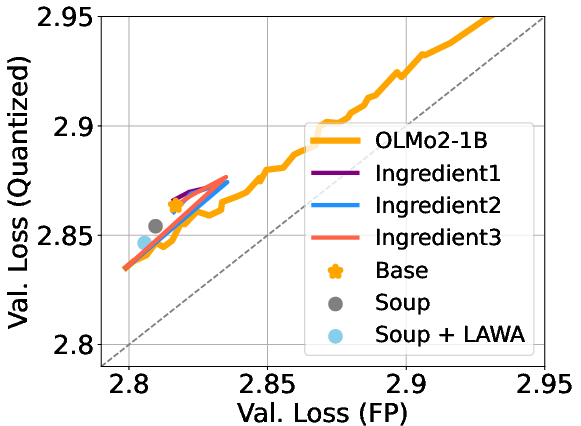
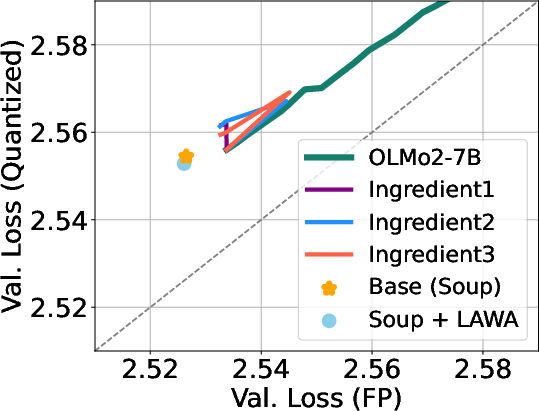
4) Weight averaging helps
- “Model soup” (averaging different runs) and averaging checkpoints along one run often reduce quantization error.
- In several cases, the averaged model not only performs better in full precision, but also loses less accuracy after 3‑bit/4‑bit quantization.
Why it matters: Averaging is a simple, low‑cost trick that can make models sturdier when compressed.
5) Weight decay helps somewhat; gradient spikes aren’t the direct cause
- Increasing weight decay (a regularization knob) can modestly improve quantization robustness among runs with similar full‑precision loss.
- Changing the optimizer to reduce late‑training gradient spikes did not change quantization error much, suggesting those spikes aren’t the main driver.
Why it matters: There are multiple knobs you can tune. LR and schedules matter most; weight decay helps; optimizer tweaks may not directly fix quantization fragility.
6) Downstream tasks show the same pattern
- It’s not just validation loss. Real benchmarks also show that quantization hurts more after LR decay.
- Post‑training steps like alignment and instruction tuning can change quantization robustness, and averaging can again help.
Why it matters: These findings apply to practical tasks, not just to internal loss numbers.
Implications and potential impact
- Train with quantization in mind: Don’t wait until the end to test PTQ. Measure quantization error throughout training, especially around LR changes.
- Choose LR schedules carefully: Avoid making the LR too small near the end. Warmup‑stable‑decay can be preferable to cosine if it maintains better control. If two recipes give similar accuracy, prefer the one with higher LR for better PTQ.
- Use weight averaging: Average checkpoints or build model soups. It’s a simple way to reduce PTQ error.
- Don’t fear big datasets: Large‑scale training can still yield models that quantize well. The issue is training dynamics, not size alone.
- Practical benefits: Better quantization means models that are cheaper to run, faster on consumer hardware, and more accessible. This can cut costs, save energy, and make powerful models usable on devices like laptops and phones.
In short, this paper shows that the way we train models shapes how well they can be compressed afterward. By adjusting learning rate schedules and using techniques like averaging, we can build large models that stay strong even when shrunk to low‑bit formats.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The paper establishes a strong empirical link between training dynamics—especially learning rate schedules—and post-training quantization (PTQ) robustness, but several aspects remain uncertain or unexplored. Future work could address the following gaps:
- Mechanistic cause of LR-decay–induced PTQ degradation: identify the causal factors (e.g., layerwise weight distribution shifts, outlier prevalence, activation scales, Hessian curvature, noise scale) that drive error spikes during annealing.
- Early-warning and predictive indicators: develop online metrics to anticipate PTQ degradation during training (e.g., per-layer quantization sensitivity, weight/activation statistics) and guide schedule transitions or averaging decisions.
- LR schedule design for PTQ robustness: characterize compute-optimal schedules that retain final performance while mitigating PTQ degradation (e.g., WSD variants, end-of-training LR floors, piecewise schedules).
- Generalization across quantization algorithms: systematically compare GPTQ, AWQ, BNB, QuIP, QuaRot, and codebook-based methods across training stages to isolate algorithm-specific vs training-dynamics effects.
- Quantization hyperparameter interactions: study how group size, rounding schemes, per-channel scaling, rotation, codebook size, and calibration sample count interact with training dynamics to affect PTQ robustness.
- Activation and KV-cache quantization: quantify how training dynamics affect activation/KV quantization (not only weights) and their impact on end-to-end inference, especially for long-context decoding.
- Ultra-low-bit regimes: assess whether the observed dynamics persist and remain tractable at 2-bit or 1-bit weights/activations, and identify thresholds where interventions cease to be effective.
- Architectural coverage: test whether findings transfer to sparse/MoE and sub-quadratic models (e.g., Mamba) and identify architecture-specific sensitivities to LR schedules and averaging.
- Optimizer choice beyond AdamW/AdamC: evaluate Adafactor, Lion, SGD+momentum, and schedule-free methods, isolating momentum, adaptive statistics, and clipping effects on PTQ robustness.
- Broader hyperparameter space: perform controlled ablations of batch size, gradient clipping, EMA/SWA, label smoothing, dropout, and their interactions with LR/weight decay on PTQ outcomes.
- Data curriculum and ingredient effects: disentangle whether model soups’ PTQ gains arise from diversity in data mixtures, orderings, or quality; design controlled curricula to test causality.
- Calibration dataset dependence: quantify how calibration domain match, size, and sampling strategies alter reconstruction error trends along training trajectories.
- Layerwise/component sensitivity: map which modules (embeddings, attention blocks, MLPs, LayerNorms) dominate quantization error after annealing and develop targeted per-layer interventions (e.g., per-layer LR or decay).
- Post-pretraining stages: explain why context extension reduces and mid-training increases PTQ degradation in SmolLM3; test generality across alignment methods (SFT, DPO/APO, RLHF) and datasets.
- Corrected scaling laws: propose and validate scaling laws for quantized models that explicitly control for LR schedules and final LR magnitudes to avoid confounding by optimization dynamics.
- Scaling to large models: replicate controlled interventions at 7B–32B scale with matched hyperparameters to verify that small-scale conclusions hold at realistic deployment sizes.
- Deployment-relevant metrics: connect validation-loss/accuracy degradation to practical throughput, latency, memory, and energy impacts; quantify trade-offs for different bit-widths and kernels.
- Variance across seeds/runs: measure robustness of the observed spikes and intervention benefits across multiple random seeds and training runs to establish statistical confidence.
- Averaging protocols: determine the optimal averaging window, frequency, and weighting (LAWA, SWA, EMA) that maximize PTQ robustness without degrading full-precision performance; compare soups vs trajectory averaging.
- Safety and alignment impacts: assess PTQ-induced changes on safety, calibration, and preference alignment, beyond the 12 benchmark tasks and 5-shot accuracy proxy.
- Theoretical modeling: derive principled relationships between training dynamics (LR, noise scale, optimization trajectory) and quantization error bounds; identify sufficient conditions for PTQ robustness.
- Joint intervention tuning: co-optimize LR schedules, weight decay, averaging, and souping; build automated HPO pipelines that include PTQ robustness as an objective during pretraining.
- Tooling and benchmarks: standardize protocols to monitor PTQ throughout training, release open tooling/datasets for continuous PTQ evaluation, and define reproducible reporting norms for open-weight runs.
Practical Applications
Applications derived from the paper’s findings, methods, and innovations
The paper shows that post-training quantization (PTQ) robustness is primarily shaped by training dynamics—especially learning-rate schedules—rather than dataset scale alone. It provides actionable interventions (e.g., maintaining higher learning rates longer, weight averaging/model souping, slightly higher weight decay) and recommends monitoring PTQ during pretraining. Below are practical applications, grouped by deployment horizon.
Immediate Applications
These can be incorporated now into model training and deployment workflows using current tooling (e.g., GPTQ, AWQ, BitsAndBytes), standard MLOps practices, and available compute.
- Training recipes that are “quantization-aware”
- What to do: Prefer higher peak learning rates (when runs tie on validation loss), extend constant LR phases, avoid aggressive end-of-training LR decay, and tune decay length and shape (e.g., WSD vs cosine) with PTQ robustness as a first-class objective.
- Why it matters: Reduces 3–4 bit quantization error spikes at the end of training without sacrificing full-precision performance.
- Sectors: Software/AI platforms, cloud inference, foundation model providers.
- Tools/workflows: Add “PTQ robustness” metrics to hyperparameter sweeps; LR schedule managers that surface quantization-error curves alongside loss; experiment tracking with “relative loss” and “accuracy-drop” metrics.
- Assumptions/dependencies: Comparable full-precision performance across LR choices; access to checkpoints and calibration datasets; specialized kernels supporting quantized inference.
- Weight averaging and model souping to improve PTQ
- What to do: Apply LAWA-style checkpoint averaging along the stable phase and/or soup across multiple data “ingredients.” Release averaged weights in addition to single-run checkpoints.
- Why it matters: Averaging can outperform LR decay for low-bit models and consistently reduces PTQ degradation while often improving full-precision validation loss.
- Sectors: Open-source model releases, enterprise model catalogs, cloud AI services.
- Tools/workflows: Automated checkpoint-averaging jobs in training pipelines; “soup builders” that combine ingredients before model release.
- Assumptions/dependencies: Frequent checkpoint saving; consistent training runs per ingredient; negligible extra compute for averaging.
- PTQ-aware hyperparameter tuning and monitoring
- What to do: Treat PTQ error (e.g., relative cross-entropy loss, accuracy-drop across benchmarks) as a gating metric during pretraining and post-pretraining stages (SFT, alignment, context extension).
- Why it matters: Prevents end-of-training surprises; guides when to cool down LR; highlights stages (e.g., context extension, APO/SFT) that mitigate PTQ degradation.
- Sectors: MLOps, model evaluation tooling, academic labs.
- Tools/workflows: Dashboards that track full-precision and quantized metrics over time; “PTQ readiness gates” in CI; downstream task evaluators using relative accuracy-drop.
- Assumptions/dependencies: Calibration datasets for GPTQ/AWQ; benchmark harnesses; data-management for staged training.
- Lower inference TCO by training for quantizability
- What to do: Incorporate quantization robustness targets into training objectives to reliably deploy 3–4 bit models at scale.
- Why it matters: Reduces memory bandwidth needs and accelerates autoregressive decoding; improves throughput and energy use.
- Sectors: Cloud inference, enterprise FinOps, edge AI.
- Tools/workflows: Capacity planning models that account for low-bit kernels; cost dashboards that link training choices to inference savings.
- Assumptions/dependencies: Hardware support for low-bit kernels; operational readiness for quantized deployment; performance SLAs tolerant to small accuracy differences.
- Edge and privacy-preserving deployments
- What to do: Use PTQ-optimized training to produce models that reliably run at 3–4 bits on mobile and embedded hardware.
- Why it matters: Enables on-device assistants and privacy-protecting applications without cloud dependence.
- Sectors: Mobile, robotics, consumer devices, healthcare wearables, education.
- Tools/workflows: AWQ/GPTQ pipelines with device-specific calibration; memory-aware packaging; telemetry validating on-device accuracy-drop.
- Assumptions/dependencies: Device kernel support; representative calibration data; thermal and battery constraints.
- Release practices and transparency for open models
- What to do: Publish PTQ robustness curves, learning-rate schedules, and averaged/souped checkpoints in model cards.
- Why it matters: Helps downstream users select checkpoints that quantize well; accelerates reproducible research.
- Sectors: Open-source AI communities, academic consortia.
- Tools/workflows: Model cards that include “Quantization Robustness” sections; reproducibility scripts.
- Assumptions/dependencies: Licensing permits releasing intermediate checkpoints; consistent logging of LR schedules and training states.
- Policy and procurement guidance for public-sector AI
- What to do: Require PTQ robustness reporting and checkpoint transparency in procurement and grant guidelines; include energy/efficiency targets aligned with low-bit inference.
- Why it matters: Improves cost-efficiency and climate impact of publicly funded models; supports equitable access on lower-end hardware.
- Sectors: Government, NGOs, research funders.
- Tools/workflows: Compliance checklists; energy-efficiency scoring tied to quantization-readiness.
- Assumptions/dependencies: Policy adoption; standardized metrics; vendor cooperation.
- Curriculum and lab exercises in education
- What to do: Teach PTQ-aware training and averaging; run small-scale LLMs with live quantization monitoring; compare schedules (WSD vs cosine).
- Why it matters: Builds practical skills and computational literacy around deployment constraints.
- Sectors: Higher education, vocational training, ML bootcamps.
- Tools/workflows: Open datasets (FineWebEdu), training scripts, quantization backends (GPTQ/AWQ/BNB), evaluation harnesses.
- Assumptions/dependencies: Access to modest GPUs; time to run controlled experiments.
Long-Term Applications
These require further research, scaling, validation across model families, or ecosystem changes (software/hardware, standards, or policy).
- Closed-loop training controllers that optimize for quantization robustness
- Vision: Multi-objective training that adapts LR schedules, weight decay, and averaging intensity in real time based on PTQ metrics.
- Sectors: Cloud training platforms, AutoML vendors.
- Tools/products: “Quantization-aware trainers” that co-optimize full-precision loss and low-bit loss; schedule controllers with PTQ feedback loops.
- Assumptions/dependencies: Robust online PTQ proxies; safe adaptation without destabilizing training; generalization across architectures.
- New optimizers and schedule-free methods tuned for PTQ stability
- Vision: Optimizers and regularizers (e.g., quantization-robust weight decay, layer-wise LR control) that reduce end-of-training error spikes without performance loss.
- Sectors: Foundation model builders, academic research.
- Tools/products: Quantization-regularized objectives; schedule-free algorithms that keep LR from collapsing to tiny values that hurt PTQ.
- Assumptions/dependencies: Theoretical understanding of PTQ–optimization dynamics; broad empirical validation.
- Standardized scaling laws and benchmarks that control for LR schedules
- Vision: Community benchmarks and scaling laws that isolate data scale from optimization confounders to predict PTQ degradation reliably.
- Sectors: Academia, standards bodies, industry consortia.
- Tools/products: Public “PTQ scaling suites” with prescribed schedules; cross-model leaderboards reporting relative-loss and accuracy-drop.
- Assumptions/dependencies: Widespread adoption; reproducible training logs; consensus on PTQ metrics.
- Hardware–software co-design for low-bit LLMs
- Vision: Accelerators, kernels, and memory hierarchies designed for robust 3-bit and 4-bit operation, informed by PTQ-friendly training.
- Sectors: Semiconductors, cloud hardware, mobile SoCs.
- Tools/products: Mixed-precision GEMM kernels; fused dequantization ops; profiling tools that exploit improved quantizability.
- Assumptions/dependencies: Stable low-bit numerical behavior across models; vendor support; compiler/runtime integration.
- Quantization Robustness Cards as part of model release standards
- Vision: A standard appendix to model cards with PTQ curves, schedules, averaging details, and accuracy-drop across tasks, mandated by communities or regulators.
- Sectors: Open-source communities, policy/regulatory frameworks.
- Tools/products: Model card templates; audit tools that verify PTQ disclosures.
- Assumptions/dependencies: Agreement on schema; incentives or requirements to comply.
- Edge AI ecosystems that rely on robust 3-bit LLMs
- Vision: Offline assistants, robotics stacks, and medical devices powered by reliably quantizable models, enabling broader access and better privacy.
- Sectors: Consumer tech, industrial robotics, healthcare.
- Tools/products: On-device LLM SDKs tuned for PTQ; calibration-on-deployment workflows; safety/validation packs for regulated domains.
- Assumptions/dependencies: Regulatory approvals for medical/industrial use; field calibration datasets; device support for quantized kernels.
- Quantizable-by-design training services
- Vision: Managed training products that guarantee PTQ targets, expose “quantization readiness” SLAs, and deliver averaged/souped releases by default.
- Sectors: Cloud ML platforms, model-as-a-service vendors.
- Tools/products: Turnkey training recipes with LR/WD presets; automatic checkpoint management; PTQ-first release pipelines.
- Assumptions/dependencies: Customer demand for low-bit SLAs; integration with downstream inference stacks.
- Extending findings to sparse and sub-quadratic architectures
- Vision: Validating that LR dynamics, averaging, and weight decay translate to MoE and state-space models to ensure low-bit viability across modalities.
- Sectors: Research labs, multimodal product teams.
- Tools/products: PTQ backends for MoE/Mamba-like models; architecture-specific LR controllers.
- Assumptions/dependencies: Architectural differences may alter PTQ behavior; new kernels and calibration strategies required.
- Carbon accounting frameworks that connect training choices to inference energy
- Vision: Sustainability metrics tying LR schedules and PTQ robustness to downstream energy savings, guiding procurement and regulation.
- Sectors: ESG reporting, public policy, enterprise sustainability.
- Tools/products: Emissions calculators that factor quantized inference; reporting standards.
- Assumptions/dependencies: Reliable measurement pipelines; industry adoption; alignment with climate disclosure norms.
- Developer and CI workflows that enforce “quantization readiness”
- Vision: CI gates that fail training runs if PTQ robustness falls below thresholds; checkpoint retention policies to enable averaging; automated PTQ regression tests.
- Sectors: Software engineering, MLOps.
- Tools/products: CI plugins; PTQ test suites; artifact managers that track checkpoints and soups.
- Assumptions/dependencies: Organizational buy-in; storage and orchestration for checkpoints; well-defined thresholds that correlate with production outcomes.
Glossary
- AdamC: An optimizer variant designed to correct undesirable training dynamics such as late-stage gradient spikes. "we train with AdamW \citep{loshchilov2019decoupled} (in cyan), and AdamC \citep{defazio_why_2025} (in orange) which aims to correct this behavior."
- AdamW: A widely used optimizer that decouples weight decay from the gradient-based update in Adam. "Fixing all other hyperparameters (more details in Appendix \ref{appendix:replicability}) we train with AdamW \citep{loshchilov2019decoupled} (in cyan)"
- Anchored Preference Optimization (APO): A post-training alignment method that optimizes preferences anchored to reference behaviors. "anchored preference optimization (APO) \citep{doosterlinck2024anchoredpreferenceoptimizationcontrastive} to promote alignment."
- Auto-regressive decoding: A generation process where tokens are produced sequentially, each conditioned on previously generated tokens. "LLM inference is dominated by auto-regressive decoding, which is in turn limited by memory bandwidth"
- AWQ: A post-training quantization method that uses activation-aware weighting to reduce quantization error. "However, our supplementary experiments demonstrate that AWQ \citep{awq} and BitsAndBytes (BNB) \cite{llmint8} quantization methods exhibit analogous trends"
- BitsAndBytes (BNB): A quantization library providing efficient low-bit inference primitives, e.g., 8-bit matrix multiplication for Transformers. "AWQ \citep{awq} and BitsAndBytes (BNB) \cite{llmint8} quantization methods exhibit analogous trends"
- Calibration dataset: A small data subset used during quantization to estimate activation statistics or reconstruction targets. "The latter methods require a calibration dataset to compute at quantization time"
- Cosine decay schedule: A learning-rate schedule that decays the rate following a cosine curve over the training horizon. "Whereas earlier LLM training largely relied on cosine decay schedules~\citep{loshchilov2017sgdr}"
- Cross-entropy loss: A standard probabilistic loss for language modeling that measures the negative log-likelihood of the correct tokens. "we show relative cross-entropy loss, defined as ."
- Dequantization: The process of converting low-precision weights back to higher-precision representations for computation. "Modern mixed-precision kernels fuse the dequantization and multiplication steps for efficiency."
- Dynamic range: The span of representable values in a tensor, critical when mapping to low-bit formats. "high-precision auxiliary states, such as scaling factors, to map between the dynamic range of original tensors and that representable in low-precision"
- GEMMs: General Matrix-Matrix Multiplications, a core operation in neural network inference and training. "the matrix multiplication (GEMMs) is performed with the dequantized weights such as ."
- GPTQ: A popular post-training quantization method that minimizes reconstruction error using a calibration set. "we focus our analysis on GPTQ \citep{frantar_gptq_2023} quantization at 3- and 4-bit precision levels."
- KV-cache: Stored key-value tensors that speed up auto-regressive decoding by reusing past attention states. "optimize which parts of the model to quantize and by what approach to minimize errors, when quantizing weights, activations and KV-cache."
- LAWA: Latest Weight Averaging; a checkpoint-averaging technique that aggregates recent weights to improve robustness. "LAtest Weight Averaging (LAWA) \citep{kaddour_stop_2022}"
- Mixed-precision kernels: Low-level implementations that combine different numeric precisions to accelerate inference while maintaining accuracy. "Modern mixed-precision kernels fuse the dequantization and multiplication steps for efficiency."
- Model souping: Averaging weights from multiple trained models (often with different data “ingredients”) to improve performance or robustness. "The final model weights are obtained through model souping~\citep{wortsman2022modelsoup}"
- Outliers (in quantization): Rare large-magnitude values that skew group-wise scaling and must be handled specially. "processing outliers that would affect the dynamic range of the group with different strategies."
- Post-training quantization (PTQ): Quantizing a model after it has been fully trained to reduce memory and computational cost. "In the following we will denote this workflow as post-training quantization (PTQ)."
- Quantization error: The performance degradation or discrepancy introduced by mapping high-precision weights to low-precision formats. "only as the learning rate decays does quantization error spike."
- Reconstruction error: The discrepancy between original and quantized outputs, often minimized during PTQ. "more recent approaches minimize the reconstruction error ."
- Schedule-free methods: Optimization approaches that avoid explicit learning-rate schedules. "we leave the exploration of schedule-free methods~\citep{defazio_road_2024} to follow-up work."
- Streaming multiprocessors: GPU compute units that execute parallel threads, crucial for throughput during inference. "e.g. streaming multiprocessors on GPUs"
- Supervised fine-tuning (SFT): A stage where models are trained on labeled data to improve task-specific skills. "supervised fine-tuning (SFT) for domain-specific skills"
- Trapezoidal schedule: A learning-rate schedule with warmup, a stable plateau, and a decay phase; synonymous with WSD. "more recently model builders have shown increasing interest in the trapezoidal schedule~\citep{zhai2022scalingvisiontransformers, hu2024minicpm}, also known as WarmupâStableâDecay (WSD)."
- Warmup–Stable–Decay (WSD): A learning-rate schedule that warms up, holds constant, then decays linearly. "We use WSD, training a 160M-parameter transformer up to 100B tokens and performing additional cooldowns at 12B, 28B, 46B, 64B, 82B tokens."
- Weight averaging: Aggregating multiple checkpoints from a single training run to reduce noise and improve robustness. "weight averaging along training trajectories can be used to improve quantization performance."
- Weight decay: A regularization technique that penalizes large weights to improve generalization and stability. "Learning rate and weight decay are coupled in popular AdamW implementations \citep{paszke2019pytorchimperativestylehighperformance}."
Collections
Sign up for free to add this paper to one or more collections.

