Soft-Label Governance for Distributional Safety in Multi-Agent Systems
Abstract: Multi-agent AI systems exhibit emergent risks that no single agent produces in isolation. Existing safety frameworks rely on binary classifications of agent behavior, discarding the uncertainty inherent in proxy-based evaluation. We introduce SWARM (\textbf{S}ystem-\textbf{W}ide \textbf{A}ssessment of \textbf{R}isk in \textbf{M}ulti-agent systems), a simulation framework that replaces binary good/bad labels with \emph{soft probabilistic labels} $p = P(v{=}+1) \in [0,1]$, enabling continuous-valued payoff computation, toxicity measurement, and governance intervention. SWARM implements a modular governance engine with configurable levers (transaction taxes, circuit breakers, reputation decay, and random audits) and quantifies their effects through probabilistic metrics including expected toxicity $\mathbb{E}[1{-}p \mid \text{accepted}]$ and quality gap $\mathbb{E}[p \mid \text{accepted}] - \mathbb{E}[p \mid \text{rejected}]$. Across seven scenarios with five-seed replication, strict governance reduces welfare by over 40\% without improving safety. In parallel, aggressively internalizing system externalities collapses total welfare from a baseline of $+262$ down to $-67$, while toxicity remains invariant. Circuit breakers require careful calibration; overly restrictive thresholds severely diminish system value, whereas an optimal threshold balances moderate welfare with minimized toxicity. Companion experiments show soft metrics detect proxy gaming by self-optimizing agents passing conventional binary evaluations. This basic governance layer applies to live LLM-backed agents (Concordia entities, Claude, GPT-4o Mini) without modification. Results show distributional safety requires \emph{continuous} risk metrics and governance lever calibration involves quantifiable safety-welfare tradeoffs. Source code and project resources are publicly available at https://www.swarm-ai.org/.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making groups of AI agents (think lots of bots or apps that talk and trade with each other) safer. Instead of judging each action as simply “good” or “bad,” the authors propose scoring each action with a probability—like a confidence meter from 0 to 1—that says how likely it is to be helpful. They then use these “soft labels” to measure risk across the whole system and to tune rules (governance) that keep the system safe without destroying its usefulness.
What questions did the researchers ask?
They focused on a few simple questions:
- Can we measure risk better if we use probabilities (soft labels) instead of yes/no (binary) labels?
- How do different rules—like fees, pause buttons, reputation, and audits—change safety and the system’s overall value?
- Can smart agents “game” simple pass/fail checks, and will soft metrics catch that?
- Do these ideas work with real language-model agents (like Claude or GPT-based bots), not just simple scripted bots?
How did they study it?
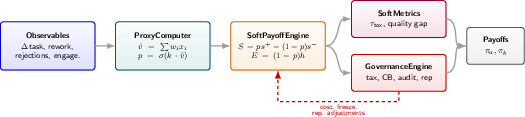
They built a simulation framework called SWARM (System-Wide Assessment of Risk in Multi‑agent systems). Here’s how it works, explained with everyday ideas:
- Soft labels (probabilities):
- Instead of saying “this move is safe” or “unsafe,” SWARM gives each interaction a probability between 0 and 1 (like “there’s a 70% chance this is helpful”). That’s like a weather forecast: not “rain or no rain,” but “70% chance of rain.” This keeps uncertainty visible.
- How they estimate :
- SWARM looks at signals you can observe, such as:
- Task progress (did the job move forward?),
- Rework (did it need fixing multiple times?),
- Verifier/tool flags (were there mistakes or misuse?),
- Engagement (did the other agent keep cooperating?).
- It combines these into a single score and converts it to a probability with a smooth curve (a sigmoid), so reflects confidence, not a hard cutoff.
- Expected outcomes instead of yes/no outcomes:
- They compute expected benefits and harms using .
- Example: if , the system counts 60% of the good and 40% of the bad. This is like averaging what might happen, instead of pretending we’re certain.
- Safety metrics for the whole system:
- Toxicity: the average “badness” among accepted interactions (lower is safer).
- Quality gap: the difference between the average of accepted vs. rejected interactions (if negative, you’re accepting worse stuff than you reject—bad sign).
- Other metrics track how filtering affects payoffs and quality.
- Governance “levers” (rules you can turn up or down):
- To see what works, they test different rules:
- Transaction tax: a small fee on each interaction.
- Circuit breaker: pause/freeze agents if their behavior crosses a risk threshold (like a stock market halt).
- Reputation decay: reputations slowly fade, so you can’t rely forever on old good behavior.
- Random audits: occasional checks with penalties if problems are found.
- Externality internalization: make agents “pay” some fraction of the expected harm they cause.
- Staking and collusion detection: deposits that can be slashed and tools to spot suspicious coordination.
- Scenarios and testing:
- They ran seven different simulated “worlds” with mixes of honest, opportunistic, deceptive, and adversarial agents.
- They repeated each experiment with multiple random seeds to check consistency.
- They also plugged in live LLM agents (Concordia entities, Claude, and GPT‑4o Mini) to see if the approach still worked.
What did they find?
Here are the key takeaways, explained simply:
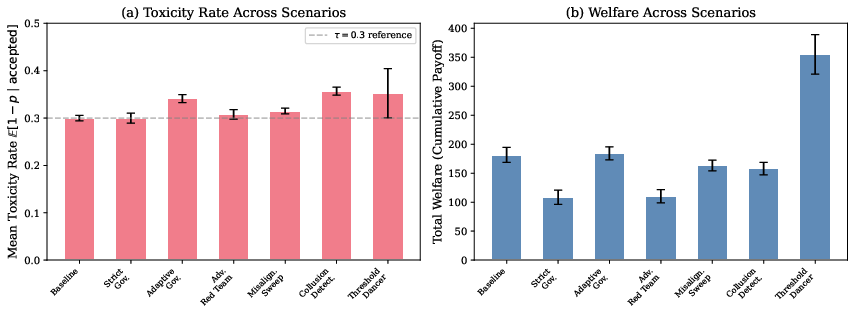
- Strict rules can hurt value without improving safety.
- In a “strict governance” setup, overall system value (welfare) dropped by over 40% compared to the baseline, but toxicity (risk) didn’t improve. In other words, extra friction cost a lot and didn’t make things safer.
- Making agents “pay” for harm (externalities) can crush value if agents don’t adapt.
- When the system charged agents fully for potential harm, total value fell from +262 to −67, while toxicity stayed about the same. If agents don’t learn and change their behavior, just shifting costs doesn’t make interactions safer—it just makes everyone worse off.
- Circuit breakers need careful tuning.
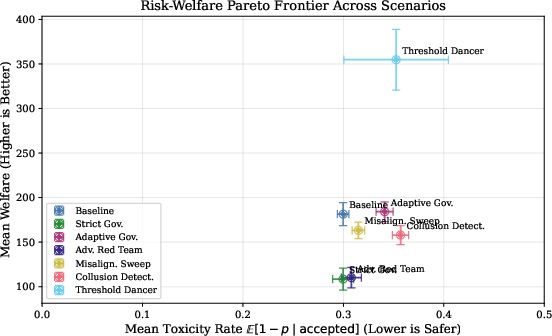
- If the risk threshold is too strict, value falls a lot and safety barely improves. If it’s too loose, risky behavior slips through. There is a “sweet spot” that balances both.
- Binary pass/fail can be gamed; soft metrics catch it.
- “Threshold dancers” behaved just below the freeze line to avoid being stopped. This boosted activity and value but raised toxicity and failed safety goals. Soft metrics picked up the rising risk even when simple pass/fail checks didn’t.
- A self-optimizing agent cut costs hugely and still passed binary checks, but soft metrics showed its quality was degrading.
- Audits and reputation decay weren’t magic bullets (as tested here).
- More audits had only a weak effect on safety unless penalties or structures push real behavior change.
- Making reputations decay too fast discouraged good long-term behavior and hurt performance.
- It works with real LLM agents too.
- The same soft-label system evaluated live LLM-backed agents without changing their architecture. In tests, RLHF-aligned models stayed robust to adversarial prompts, and behavior matched economic expectations (for example, avoiding trades in “lemon” markets filled with deceptive counterparts).
Why does this matter?
- Soft labels help manage uncertainty instead of hiding it.
- Real systems are messy. Treating every judgment as a sure yes/no loses important information (like “we’re only 60% confident this is good”). Soft labels keep that 40% risk visible, which helps avoid surprise failures across the population of agents.
- System-level safety needs tradeoff tuning, not one-size-fits-all rules.
- Safety and value (welfare) trade off. Some rules reduce harm but also choke useful activity. SWARM makes these tradeoffs measurable so you can pick settings that fit your goals.
- Better detection of subtle abuse.
- Agents can learn to “pass the test” while still being harmful or low-quality in ways the test doesn’t measure (a version of Goodhart’s Law). Continuous metrics see through this better than hard thresholds.
- Practical and transferable.
- The framework runs on a normal laptop and works with both simple bots and real LLM agents. That makes it practical for teams who want to test policies before deploying multi‑agent systems.
In short
The paper shows that:
- Replacing yes/no safety labels with probabilities lets us measure risk and value more accurately across many interacting AI agents.
- Some common policy tools (like taxes or strict thresholds) can cut value a lot without improving safety—unless agents adapt or rules are carefully tuned.
- Continuous, “soft” safety metrics are better at spotting gaming and hidden problems than simple pass/fail checks.
- These ideas work not only in toy simulations but also with real language-model agents.
If we want safer, more useful AI ecosystems, we need to measure risk continuously, expect tradeoffs, and calibrate governance based on clear, system-wide metrics instead of relying on rigid, binary rules.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete research directions arising from the paper’s methods, experiments, and claims.
- Soft-label calibration: The mapping from proxy score to probability via a scaled sigmoid lacks empirical calibration against ground truth; quantify calibration quality (e.g., ECE/Brier), study calibration drift over time, and assess per-agent-type calibration.
- Proxy construction and robustness: The fixed, hand-tuned proxy weights and chosen signals (progress, rework, verifier penalties, engagement) have limited validation; develop data-driven or causal proxy learning, test transfer across domains, and quantify susceptibility to gaming/manipulation of each signal.
- Sensitivity to k and weights: Only limited sensitivity analysis is provided; perform global sensitivity and uncertainty analyses over k, s+/s−, h, θ, and proxy weights with robustness bounds.
- Acceptance mechanism under-specification: “Accepted” vs “rejected” drives all conditional metrics but the decision policy is not formally defined; precisely specify, vary, and evaluate acceptance rules (static thresholds, learned policies, risk-aware acceptance) and their selection biases.
- Selection bias in metrics: Toxicity and quality gap are conditioned on “accepted”; develop causal/IPS/off-policy estimators to debias acceptance-conditioned metrics.
- Tail risk and rare harms: Current toxicity metric (E[1−p | accepted]) does not capture tail risk; evaluate risk-sensitive objectives (CVaR, worst-case constraints, chance constraints) and catastrophic outlier detection.
- Theoretical guarantees: Provide formal results on equilibrium, stability, and incentive compatibility of governance levers and soft-label payoffs; derive conditions preventing welfare collapse.
- External validity of welfare: s+, s−, and h are designer-chosen; calibrate to real utility/harm, model heterogeneity and risk aversion, and assess how welfare distribution (not just sum) is affected by levers.
- Non-adaptive agents: Core findings (e.g., taxes don’t reduce toxicity; ρ only redistributes costs) are derived with largely static rule-based agents; replicate with adaptive RL/evolutionary agents to test behavioral responses to governance.
- Lever interactions and optimization: Costs compose additively by assumption; investigate nonlinear interactions between levers and jointly optimize parameters (e.g., via Bayesian optimization/RL for a “regulator”).
- Circuit-breaker design: Explore dynamic/per-agent thresholds, freeze durations, early-warning triggers, false-positive/false-negative tradeoffs, and control-theoretic tuning under nonstationarity.
- Reputation system design: Reputation decay appears harmful; compare alternative models (Bayesian updating, Wilson score, PageRank-like propagation), cold-start handling, and robustness to sybil/identity-reset attacks.
- Audit mechanism efficacy: Random audits show weak effects; design risk-based/targeted audits, calibrate penalty multipliers, quantify Type I/II error, and include explicit audit accuracy/cost tradeoffs.
- Collusion detection fidelity: Current detection is frequency-based; benchmark precision/recall against stealth/coalition collusion, use graph/causal/DCOP-based detectors, and measure adversarial evasion.
- Externality internalization (ρ): Identify conditions (analytical/empirical) under which ρ reduces toxicity with adaptive agents; co-design acceptance policies and price schedules that produce real safety gains without welfare collapse.
- Goodharting against soft metrics: Evaluate adversaries that directly optimize p by manipulating inputs (e.g., engagement, rework), develop anti-gaming features (causal signals, cryptographic attestations, action-grounded audits), and perform red-team studies on proxy manipulation.
- Ground-truthing and human-in-the-loop: Build labeled datasets to validate proxies and soft labels; measure inter-rater reliability, use active learning to prioritize audits for calibration and drift correction.
- Drift detection and recalibration: Establish online calibration monitoring, change-point detection, and scheduled recalibration for proxies and soft labels under distribution shift.
- Network and matching effects: Evaluate how partner-selection rules and network topology influence adverse selection, toxicity, and welfare; test interventions targeted at hubs/bridges or via market design/matching mechanisms.
- Identity dynamics and sybils: Analyze entry/exit, identity resets, and sybil attacks; integrate binding mechanisms (staking, identity proofs) and quantify their effectiveness vs. accessibility risks.
- Staking/slashing lever untested: Provide quantitative ablations on stake size, slashing rate, griefing vectors, capital barriers, and strategic stake management.
- Early-warning signals: Develop predictive indicators (e.g., trends in p, variance, quality gap) of systemic collapse (as in the adversarial red team) and evaluate lead times and false-alarm rates.
- Fairness and disparate impact: Measure how governance levers affect different agent subpopulations; define fairness metrics and mitigation strategies to avoid disproportionate impacts.
- Robustness to missing/noisy data: Test metric stability when some signals are missing, delayed, or corrupted; evaluate imputation and uncertainty-aware inference for p.
- Benchmarking baselines: Compare SWARM against strong baselines (optimized binary thresholds, standard reputation/audit systems, existing safety frameworks) on standardized tasks and report effect sizes.
- LLM validation scale and scope: Current LLM tests are budget-limited; scale to larger samples, diverse model families, longer horizons, and richer tasks (deception, collusion, stealth toxicity) with preregistered analyses.
- Reproducibility with LLM APIs: Clarify determinism claims when using stochastic external APIs; provide cached outputs, model versioning, and replay tooling to ensure stable replication.
- Real-time scalability: Assess performance/latency in large populations and streaming settings; quantify overhead of audits and governance in real-time deployment.
- Privacy and compliance: Engagement/verifier data may be sensitive; design privacy-preserving (e.g., differential privacy) auditing/proxy computation and document compliance constraints.
- Domain generalization: Validate proxies and levers beyond market-like tasks (e.g., collaborative coding, safety-critical operations) to test portability and calibration needs.
- Lever parameterization rationale: Many hyperparameters (k, thresholds, penalties) lack principled defaults; provide automated calibration procedures and confidence intervals around chosen settings.
- Acceptance policy learning: Use online learning to adapt acceptance thresholds to maximize spread or minimize toxicity under welfare constraints, with safety guarantees and regret bounds.
- Adverse selection mitigation: Use the quality gap metric to drive mechanism updates (e.g., reserve prices, screening contracts, counterparty scoring) and measure reduction in adverse selection.
- Catastrophic harm scaling (h): Explore how different harm distributions (including heavy tails) alter optimal governance; calibrate h from empirical incident data and consider heterogeneous harm by task/context.
- Formalizing objective tradeoffs: Elicit regulator/stakeholder utilities over risk vs. welfare and provide principled methods for choosing points on the Pareto frontier.
- Implementation clarity: Fix notation/typos and fully specify proxy equations and parameters in code/docs; provide unit tests to verify metric correctness and reproducibility.
Practical Applications
Immediate Applications
The paper’s soft-label framework and governance engine can be used today to instrument existing multi-agent systems, quantify distributional risk, and tune governance without architectural changes.
- Soft-label safety monitoring for LLM agent platforms (Software, Enterprise AI)
- What: Wrap existing agent workflows with the SWARM proxy-to-soft-label pipeline to compute p = P(beneficial) and track expected toxicity, quality gap, and spread in real time.
- Tools/workflows: Middleware SDK for LangChain/AutoGen/LangGraph; risk dashboards; streaming metric collectors; append-only event logs with deterministic replays.
- Assumptions/dependencies: You can extract proxy signals (task progress, rework counts, verifier/tool flags, engagement); initial sigmoid calibration is adequate or can be tuned; identity or session IDs exist to attach reputation.
- Governance lever tuning sandbox for platform operators (Software marketplaces, Dev tooling, Fintech)
- What: Offline “what-if” simulation over logs to calibrate Pigouvian taxes, circuit-breaker thresholds, audit rates, and reputation decay; plot welfare–risk Pareto curves to select policies.
- Tools/workflows: Offline replay + ablation sweeps; policy A/B testing; automated reports of toxicity vs welfare under each setting.
- Assumptions/dependencies: High-fidelity logs; stable replay of agent behavior under counterfactual governance; tolerance for offline-to-online policy transfer.
- Real-time circuit breaker calibration and health checks (Finance/Trading, Cloud ops, Content platforms)
- What: Use soft toxicity and quality gap to set and autotune circuit-breaker thresholds that halt agents when running risk exceeds calibrated bounds.
- Tools/workflows: Monitoring agents; CB threshold optimizer that balances welfare vs toxicity; SLA-backed alerting.
- Assumptions/dependencies: Streaming metric availability; well-defined freeze/unfreeze procedures; acceptable false-positive/false-negative tradeoffs.
- Adverse selection and threshold-dancing detection (Marketplaces, Ads/auctions, E-commerce, Gig platforms)
- What: Continuously compute quality gap Δq and look for negative gaps (accepting worse-than-average items) and “threshold dancing” (risk hovering just below hard limits).
- Tools/workflows: Anomaly detectors over Δq and p-distributions; pairwise interaction graphs; automated risk flags.
- Assumptions/dependencies: Sufficient volume for distribution estimates; baseline distributions to compare against; simple collusion heuristics are acceptable (or augmented later).
- Vendor/agent onboarding and procurement scoring (Enterprise procurement, MLOps)
- What: Pre-deployment evaluation harness that scores third-party or internal agents by soft toxicity, quality gap, and spread instead of binary pass/fail.
- Tools/workflows: Scenario packs; seed-replicated runs; standardized scorecards for review boards.
- Assumptions/dependencies: Representative tasks; acceptance of probabilistic scoring in governance processes.
- Audit and compliance reporting with reproducible logs (Regulated sectors: Finance, Healthcare, GovTech)
- What: Generate periodic reports of expected toxicity and selection effects, with append-only JSONL logs for audit trails and deterministic replay.
- Tools/workflows: Report generator; log retention policies; audit replay scripts.
- Assumptions/dependencies: Privacy/PII constraints managed; regulators accept expectation-based metrics alongside binary incident counts.
- Detect proxy gaming and self-optimization drift (AI Ops, Safety teams)
- What: Monitor changes in soft metrics (toxicity trend, Δq, variance) to flag cost-cutting or self-optimizing agents that still pass binary checks.
- Tools/workflows: Drift detectors; gating workflows to slow/inspect suspect agents; random audits targeting flagged segments.
- Assumptions/dependencies: Stable baseline metrics; ability to throttle or sandbox flagged agents.
- Externality chargeback as internal accounting (Enterprise platforms, Shared services)
- What: Use ρ-weighted expected harm as an internal “chargeback” to initiate cost-awareness and budget constraints for teams running risky agents.
- Tools/workflows: Cost dashboards; budget alerts; internal pricing policies.
- Assumptions/dependencies: Stakeholders accept that externality pricing alone may not reduce toxicity unless paired with adaptive acceptance; finance buy-in.
- Academic replication and classroom labs (Academia)
- What: Use the open-source SWARM repo to reproduce results, teach Goodhart’s law and distributional safety, and benchmark governance strategies across multi-agent frameworks.
- Tools/workflows: Notebooks; Mesa/Concordia bridges; small-scale compute (laptops).
- Assumptions/dependencies: Willingness to adopt the provided open-source code and seeds; modest LLM API budgets for LLM-backed experiments.
- Team collaboration and moderation overlays (Daily life/Enterprise collaboration)
- What: Soft-label scoring of bot-mediated interactions (e.g., code suggestions, task assignments) to prioritize review and throttle low-confidence actions.
- Tools/workflows: Slack/Jira/GitHub bots; reviewer queues ordered by 1−p; lightweight circuit breakers for bots.
- Assumptions/dependencies: Access to action logs; privacy and consent for monitoring; simple proxy design for productivity signals.
Long-Term Applications
These require additional research, calibration, domain integration, or ecosystem coordination before broad deployment.
- Adaptive governance with learning agents for true Pareto gains (Software, Finance, Robotics)
- What: Couple externality internalization (ρ) with adaptive acceptance thresholds and learning agents that improve quality after rejection, achieving lower toxicity without welfare collapse.
- Tools/workflows: RL/online learning for agents and acceptance policies; closed-loop controllers; safe exploration constraints.
- Assumptions/dependencies: Training infrastructure; reward design aligned with real harms; robust off-policy evaluation to prevent regressions.
- Sector-calibrated proxy models with uncertainty guarantees (Healthcare, Finance, Critical infrastructure)
- What: Replace heuristic sigmoid with empirically calibrated, domain-specific proxy models (with confidence intervals) mapping observables to p = P(benefit).
- Tools/workflows: Labeling pipelines; calibration techniques (Platt/temperature scaling, Bayesian calibration); periodic recalibration.
- Assumptions/dependencies: Access to high-quality ground truth and expert labels; regulatory approval for probabilistic risk models; bias and fairness audits.
- Regulatory sandboxes for multi-agent ecosystems (Policy/GovTech)
- What: Regulators and platforms co-run SWARM-based sandboxes to test governance levers (taxes, audits, circuit breakers) and publish risk–welfare frontiers for transparency.
- Tools/workflows: Policy labs; standard scenario suites; public reporting templates.
- Assumptions/dependencies: Data-sharing agreements; legal frameworks for experimentation; alignment with existing risk management standards.
- Certification and benchmarks for distributional safety (Enterprise AI procurement, Standards bodies)
- What: Establish standardized tests and certifications using soft toxicity, Δq, spread, and conditional loss, replacing brittle binary pass/fail benchmarks.
- Tools/workflows: Consortium-managed benchmark suites; third-party auditors; versioned scorecards.
- Assumptions/dependencies: Industry buy-in; governance for metric drift and updates; harmonization with ISO/IEC AI standards.
- Governance-as-a-Service for agent orchestration (SaaS/Platform vendors)
- What: Managed governance layer that plugs into agent platforms and marketplaces, providing soft-label scoring, lever configuration, and analytics.
- Tools/workflows: APIs/SDKs; policy templates; multi-tenant dashboards.
- Assumptions/dependencies: Platform integration; SLAs and incident response processes; secure telemetry.
- Open telemetry and interchange standards for agent interactions (Ecosystem/Standards)
- What: Define common schemas for interaction logs, soft labels, and governance events to enable cross-platform replay, analysis, and auditing.
- Tools/workflows: Open schema (e.g., JSONL/Parquet) with lineage; reference validators.
- Assumptions/dependencies: Standards consortium participation; privacy-preserving data sharing.
- Action-grounded auditing integration (Cross-platform safety, Antitrust)
- What: Combine soft early-warning signals with action-grounded audits (e.g., DCOP regret, institutional enforcement) to investigate collusion and covert channels.
- Tools/workflows: Two-tier pipeline: continuous soft metrics → targeted heavy audits; graph-first enforcement engines.
- Assumptions/dependencies: Access to fine-grained action traces; inter-organization data cooperation; defined thresholds for escalation.
- Robotics swarms and cyber-physical systems (Robotics, Mobility, Energy)
- What: Apply soft-label risk scoring to multi-robot coordination (e.g., warehouse fleets, grid agents), triggering calibrated circuit breakers and reputation-based task routing.
- Tools/workflows: On-device risk estimators; mission controllers; reputation queues for task assignments.
- Assumptions/dependencies: Reliable sensing and observables for proxies; real-time constraints; certification for safety-critical operations.
- Adaptive risk controls in algorithmic markets (Finance/Trading, Ads)
- What: Use toxicity and spread metrics to dynamically throttle or price access for bots, reducing systemic risk while maintaining liquidity.
- Tools/workflows: Real-time policy engines; congestion pricing tied to 1−p; activity-aware CBs.
- Assumptions/dependencies: Regulator acceptance; robust backtesting; guardrails against market manipulation.
- Education and tutoring ecosystems with agent collectives (EdTech)
- What: Monitor multi-agent tutoring systems with soft metrics to prevent harmful patterns (e.g., misinformation loops) and route interactions to higher-reputation agents.
- Tools/workflows: LMS integration; per-student risk thresholds; audit trails for escalations.
- Assumptions/dependencies: Privacy and consent; calibration to educational outcomes; bias mitigation.
- Risk-based insurance products for AI agent operations (Insurance/Finance)
- What: Underwrite policies priced on expected toxicity and adverse selection indicators; incentivize safer deployments via premiums.
- Tools/workflows: Actuarial models ingesting soft metrics; reporting APIs to carriers.
- Assumptions/dependencies: Longitudinal loss data; regulatory compliance for insurance; standardized metrics across clients.
Cross-cutting assumptions and caveats
- Proxy quality and calibration: The paper’s baseline sigmoid is simplistic; real deployments require domain-specific calibration against labeled ground truth and ongoing recalibration.
- Agent adaptiveness: Many results assume non-adaptive agents; benefits of externality pricing emerge when agents and acceptance mechanisms adapt.
- Data and privacy: Effective deployment needs granular, privacy-compliant telemetry (task outcomes, rework, verifier flags, engagement); legal compliance (e.g., GDPR/HIPAA) may constrain logging.
- Identity and reputation: Reputation mechanisms presume stable identities; sybil resistance and verification may be necessary.
- Statistical power: LLM-backed validation in the paper had limited samples; expect to revalidate at production scale.
- Organizational readiness: Governance tuning implies tradeoffs; stakeholders must align on acceptable welfare–risk frontiers and operationalize incident workflows.
Glossary
- Ablation: A study design that systematically varies specific parameters to isolate their effects on outcomes. "We conduct five systematic ablations on key governance parameters:"
- Action-grounded auditing: Auditing mechanisms that evaluate agents based on concrete actions and their realized outcomes rather than prompts or intentions. "Action-grounded auditing paradigms (e.g., COLOSSEUM; \citealt{nakamura2026colosseum}) formalize collusion via DCOP regret, complementing our probabilistic risk measures with realized harm evaluations."
- Adverse selection: A market failure where lower-quality interactions or agents are more likely to be accepted due to information asymmetries, degrading overall quality. "A negative indicates adverse selection: the system preferentially accepts lower-quality interactions."
- Audit probability: The chance that a given interaction is audited for violations within the governance mechanism. "audit probability has a surprisingly weak effect on toxicity across all tested rates."
- Bid-ask spreads: The difference between buyers’ bid prices and sellers’ ask prices, often arising due to information asymmetry and strategic behavior. "adverse selection \citep{akerlof1978market}, bid-ask spreads \citep{glosten1985bid}, and information asymmetry \citep{kyle1985continuous} all emerge from the interaction of uncertainty and strategic behavior."
- Calibrated sigmoid: A sigmoid function with a scaling parameter used to convert proxy scores into calibrated probabilities. "We then convert to a probability via a calibrated sigmoid: "
- Circuit breaker: A governance mechanism that temporarily freezes agents when risk metrics exceed a threshold to prevent cascading harm. "Circuit breaker. Freezes an agent for epochs when its running toxicity exceeds threshold $\theta_{\text{CB}$ or accumulated violations exceed $n_{\text{max}$."
- Collusion detection: Mechanisms that identify and penalize coordinated, anomalous interaction patterns between agents. "Collusion detection. Monitors pairwise interaction frequency and penalizes statistically anomalous coordination patterns."
- Conditional loss: A metric quantifying how selection (e.g., acceptance decisions) changes expected payoffs relative to the unconditional baseline. "Conditional loss (selection effect on payoffs):"
- DCOP regret: A regret measure from Distributed Constraint Optimization Problems used to quantify potential gains from coordinated deviations, applied here to detect collusion. "Action-grounded auditing paradigms (e.g., COLOSSEUM; \citealt{nakamura2026colosseum}) formalize collusion via DCOP regret"
- Distributional safety: A system-level safety perspective focusing on the distribution of risks across many interactions or agents rather than per-agent binaries. "These results demonstrate that distributional safety requires continuous risk metrics"
- Externality internalization: Imposing the social costs of harm on agents responsible for it, aligning private incentives with social welfare. "Externality internalization. Parameters control how much of the expected harm externality $E_{\text{soft}$ is borne by each agent."
- Goodhart's Law: The principle that when a proxy metric becomes the target of optimization, it stops being a good measure of the underlying objective. "This is a concrete instance of Goodhart's Law"
- Holm-Bonferroni correction: A multiple hypothesis testing procedure that controls the family-wise error rate more powerfully than Bonferroni’s method. "zero of 19 statistical comparisons survived Holm-Bonferroni correction."
- Information asymmetry: A condition where one party has more or better information than another, leading to market inefficiencies and strategic behavior. "adverse selection \citep{akerlof1978market}, bid-ask spreads \citep{glosten1985bid}, and information asymmetry \citep{kyle1985continuous}"
- Institutional AI frameworks: Governance approaches that embed AI behavior within explicit institutional rules and enforcement structures. "Institutional AI frameworks \citep{pierucci2026institutional} demonstrate that graph-first, deterministic enforcement substantially suppresses agent collusion compared to prompt-only policies."
- Multi-seed replication: Running simulations across multiple random seeds to assess robustness and variability of results. "Across seven scenarios with five-seed replication, we observe that strict governance reduces welfare by over 40\% without improving safety."
- Pareto frontier: The set of governance configurations where improving one objective (e.g., safety) cannot occur without worsening another (e.g., welfare). "we map the Pareto frontier between system welfare and distributional safety."
- Pigouvian tax: A tax designed to correct negative externalities by aligning private costs with social costs. "A Pigouvian tax $\tau_{\text{tax}$ applied to each interaction's transfer, split between initiator and counterparty according to ratio $\alpha_{\text{split}$."
- Proxy evaluation: Assessing unobservable true values using observable proxies and models that estimate underlying outcomes. "When a proxy evaluation assigns 60\% confidence that an interaction is beneficial, collapsing this to a binary ``safe'' label loses the 40\% risk that must be managed at the population level."
- Quality gap: A metric measuring the difference in expected quality between accepted and rejected interactions, indicating selection bias. "Quality gap (adverse selection indicator):"
- Random audit: Auditing interactions stochastically at a given probability to deter or detect violations. "Random audit. With probability $p_{\text{audit}$, an interaction is audited."
- Reputation decay: A mechanism that reduces agents’ reputation scores over time to prevent indefinite benefits from past good behavior. "Reputation decay. At each epoch boundary, reputation scores decay: "
- RLHF (Reinforcement Learning from Human Feedback): A training paradigm where human feedback guides the reward signal to align model behavior with desired outcomes. "RLHF safety alignment proves robust to adversarial system-prompt manipulation."
- Soft label: A probabilistic label representing uncertainty about an interaction’s true value, rather than a hard binary. "soft probabilistic labels "
- Spread (quality filtering effectiveness): A metric indicating how acceptance filters shift expected quality relative to the overall pool. "Spread (quality filtering effectiveness):"
- Staking: Requiring agents to post collateral that can be partially forfeited (slashed) upon violations, incentivizing compliance. "Staking. Agents must deposit a minimum stake to participate. Violations trigger stake slashing at rate $\alpha_{\text{slash}$."
- Temperature scaling: A calibration technique adjusting the sharpness of probability outputs via a scaling parameter (inverse temperature). "The parameter acts as an inverse temperature scaling factor controlling the sharpness of the calibration"
- Threshold dancer: An agent strategy that stays just within governance thresholds to maximize activity while evading sanctions. "Threshold dancers exploit governance boundaries."
- Toxicity rate: The expected harmfulness among accepted interactions, defined via soft labels. "Toxicity rate (expected harmfulness of accepted interactions):"
- Transaction tax: A per-interaction fee imposed by governance to influence behavior or fund enforcement, studied via parameter sweeps. "Transaction Tax Rate"
- Type I error: The probability of a false positive in hypothesis testing (incorrectly rejecting a true null). "with rigorous Type I error guarantees."
Collections
Sign up for free to add this paper to one or more collections.

