- The paper introduces a unified latent action tokenizer that integrates vision and action data to bridge human and humanoid motion gaps.
- It employs a tri-branch encoder with bidirectional cross-reconstruction to generate discrete, embodiment-agnostic tokens for policy learning and world modeling.
- The approach achieves robust out-of-distribution generalization and zero-shot transfer, outperforming baselines on RoboCasa GR1 with significantly less data.
UniT: Unified Physical Language for Human-to-Humanoid Policy Learning and World Modeling
Motivation and Background
The scarcity of high-quality robotic data presents a critical bottleneck for scaling foundation models in humanoid policy learning and world modeling. By contrast, large-scale egocentric human motion datasets encapsulate diverse physical interaction priors. However, kinematic and embodiment gaps—distributional mismatch, differing DoFs, and control paradigms—impede cross-embodiment transfer. Traditional motion retargeting pipelines (e.g., inverse kinematics) are labor-intensive, domain-specific, and scale poorly across heterogeneous morphologies.
Recent approaches exploiting latent action representations are limited by modality-specific design flaws: action-only methods lack external grounding, vision-only methods entangle appearance confounders and miss structural pose detail, and independent vision/action tokenizers fail to produce unified control vocabularies. Empirical validation on dexterous humanoid tasks remains sparse and underexplored.
UniT Framework: Architecture and Principles
UniT introduces a unified latent action tokenizer with a visual anchoring mechanism, operationalized via a tri-branch cross-reconstruction architecture. This methodology leverages the premise that visual outcomes encode universal physical intent, irrespective of embodiment-specific kinematics.
Three encoding branches are deployed:
- Visual branch: Summarizes temporal transitions between consecutive observations using frozen DINOv2 features.
- Action branch: Encodes state-action sequences from heterogeneous morphologies, normalizing through per-embodiment MLPs.
- Fusion branch: Integrates vision and action latents for compact visuo-motor representations.
All branches are quantized via a shared RQ-VAE codebook, yielding discrete Unified Latent Action (UniT) tokens. Cross-reconstruction is enforced: each token is decoded by both visual and action decoders, requiring bidirectional reconstruction of physical outcomes and kinematic details. This bidirectional constraint enforces the intersection of modalities and discards unaligned noise, producing tokens embodying embodiment-agnostic physical intent.
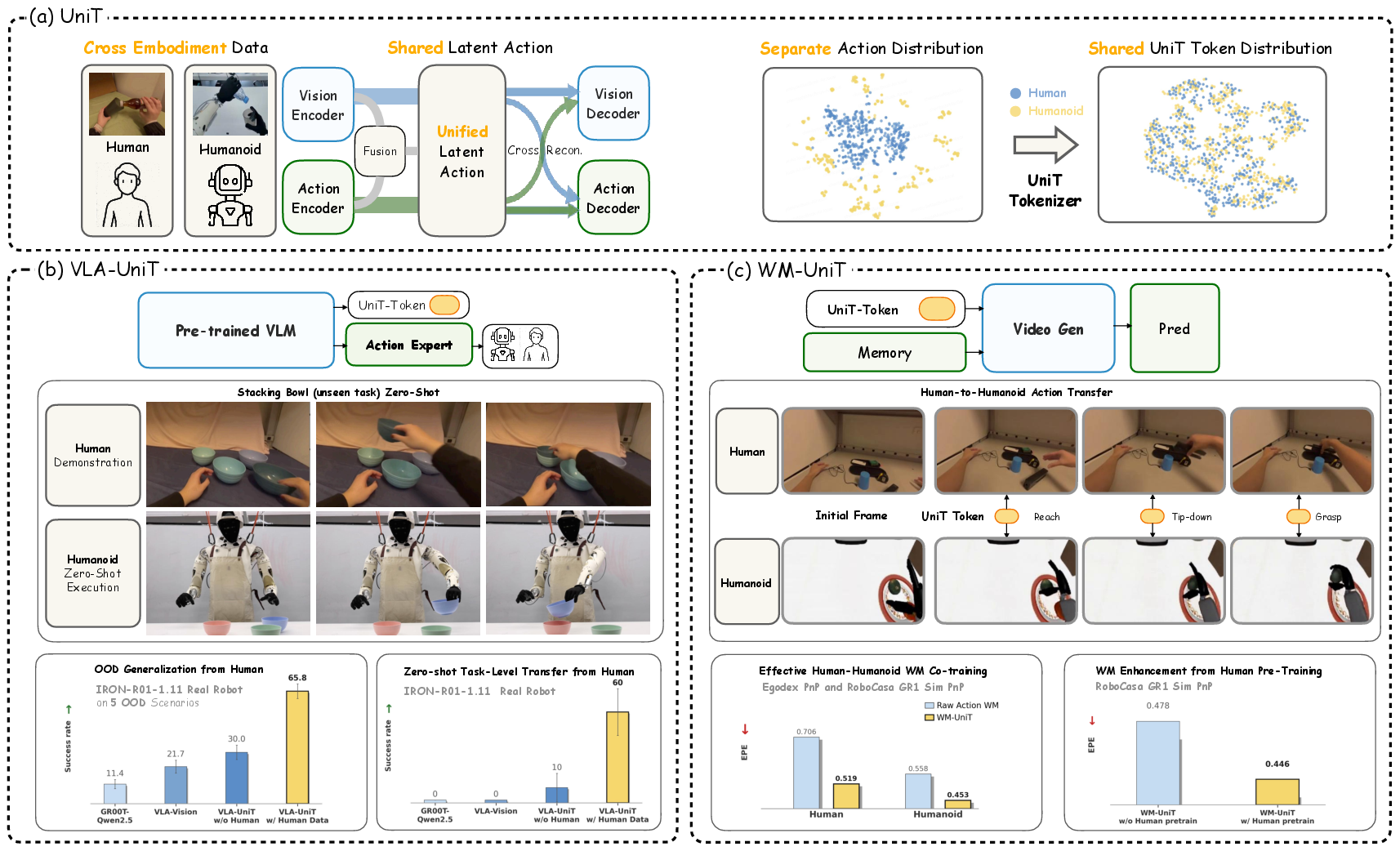
Figure 1: Overview of the UniT Framework with unified tokenization and downstream policy/world modeling.
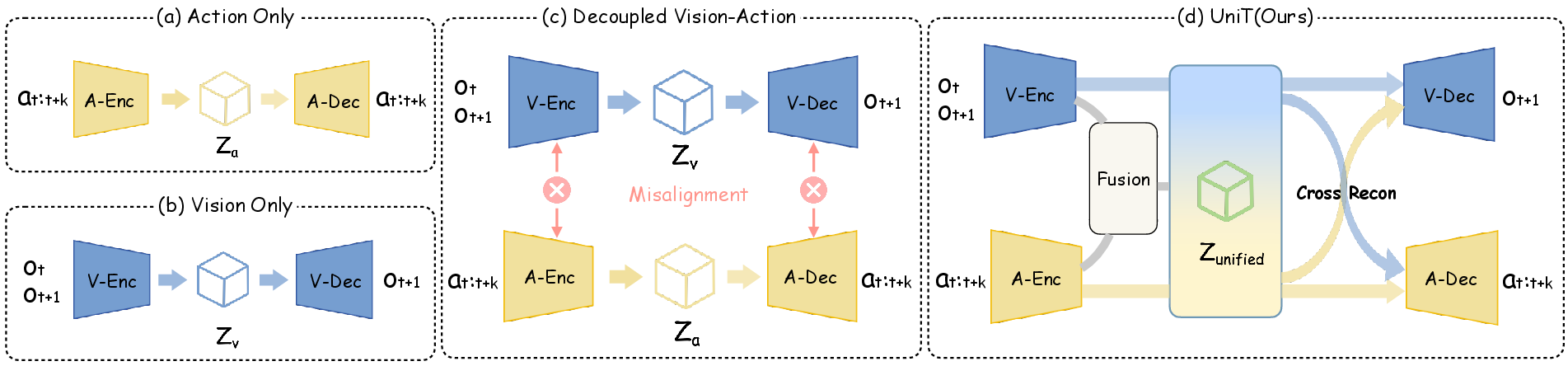
Figure 2: Comparative analysis showing the benefits of UniT's cross-modal alignment over action-only, vision-only, and decoupled paradigms.
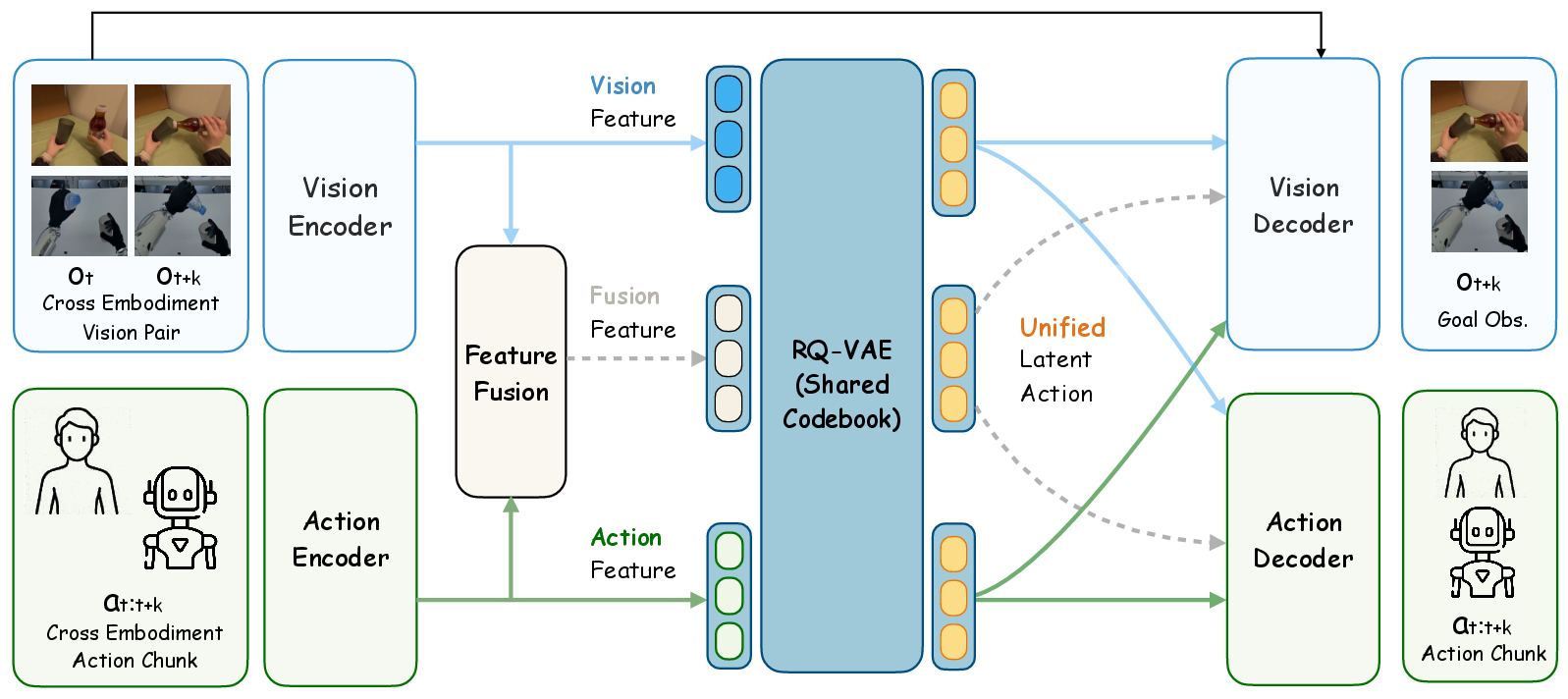
Figure 3: UniT architecture demonstrating tri-branch encoding and quantization.
Policy Learning with VLA-UniT
Instead of direct regression to raw actions, VLA-UniT leverages UniT tokens as prediction targets in Vision-Language-Action (VLA) architectures. The policy decomposition involves predicting UniT tokens from vision-language context (leveraging Qwen2.5-VL), followed by embodiment-specific action generation via a lightweight flow-matching expert.
VLA-UniT demonstrates robust OOD generalization, improved sample efficiency, and zero-shot task transfer on both simulation (RoboCasa GR1) and real-world humanoid settings. Incorporating large-scale human demonstrations (EgoDex) translates directly to enhanced policy performance and generalization along multiple axes—geometry, distractor, target, and visual background.
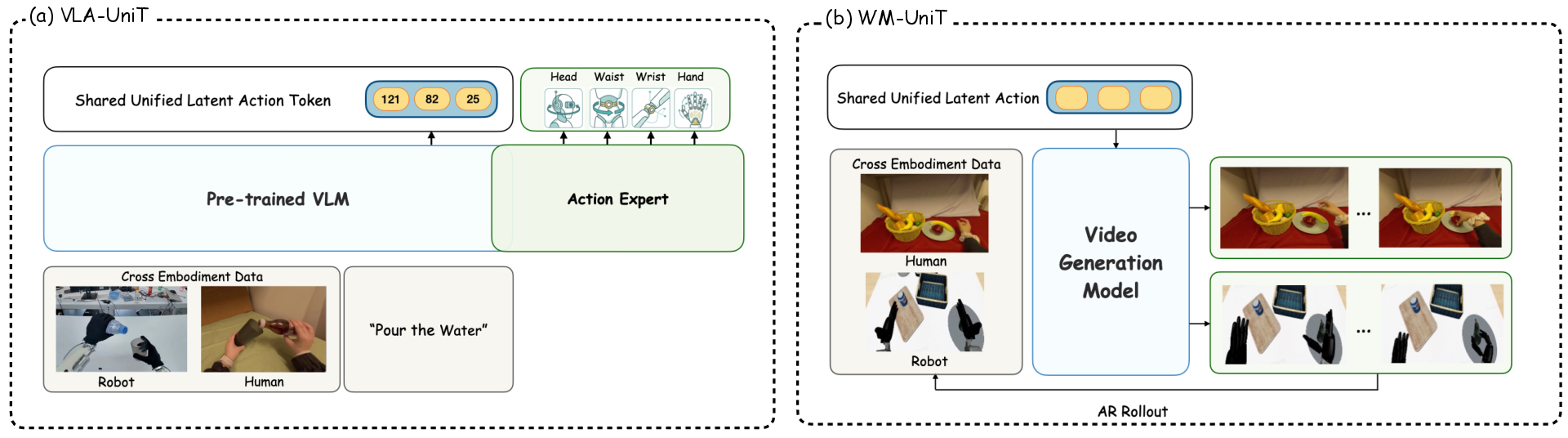
Figure 4: Downstream deployment of UniT tokens in VLA policy learning and WM world modeling.

Figure 5: Example of real-world in-domain tasks designed for humanoid benchmarking.

Figure 6: OOD evaluation scenarios leveraging human data to fill unexplored variation gaps.
Unified World Modeling with WM-UniT
WM-UniT employs UniT tokens as universal action conditions in action-conditioned world models, replacing embodiment-specific raw actions. The action branch tokens inject visuo-motor priors learned from human data, supporting fine-grained, controllable autoregressive video generation—validated empirically on DROID and RoboCasa benchmarks. Pretraining on human data enhances downstream humanoid controllability, reinforcing the latent action transfer capacity.
Direct cross-embodiment conditioning is demonstrated: feeding UniT tokens derived from one morphology (human/robot) as conditions produces faithful control and video generation in the other, preserving semantic, temporal, and geometric consistency of action dynamics.
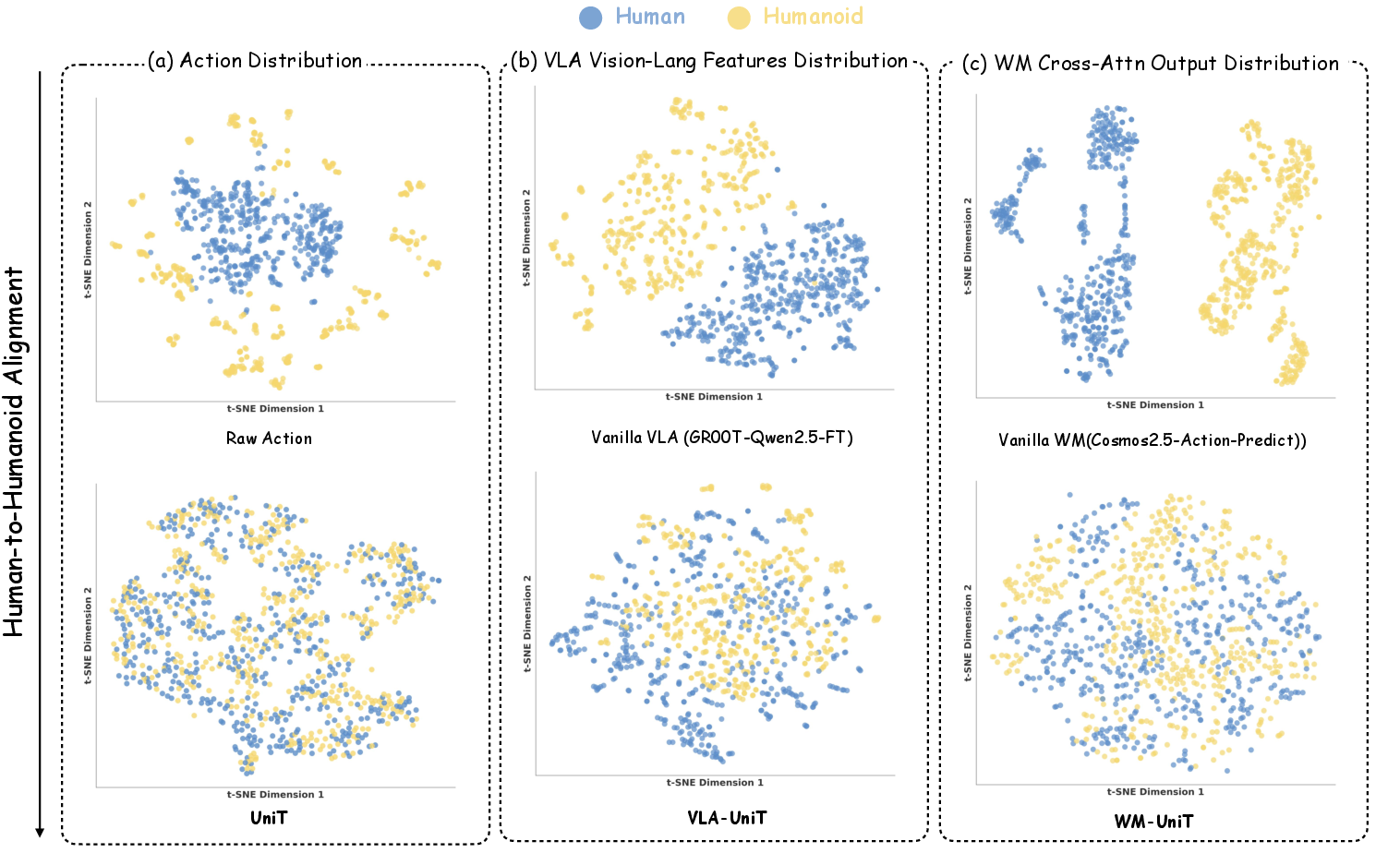
Figure 7: t-SNE analysis showing alignment between human and humanoid token embeddings at various representational levels.
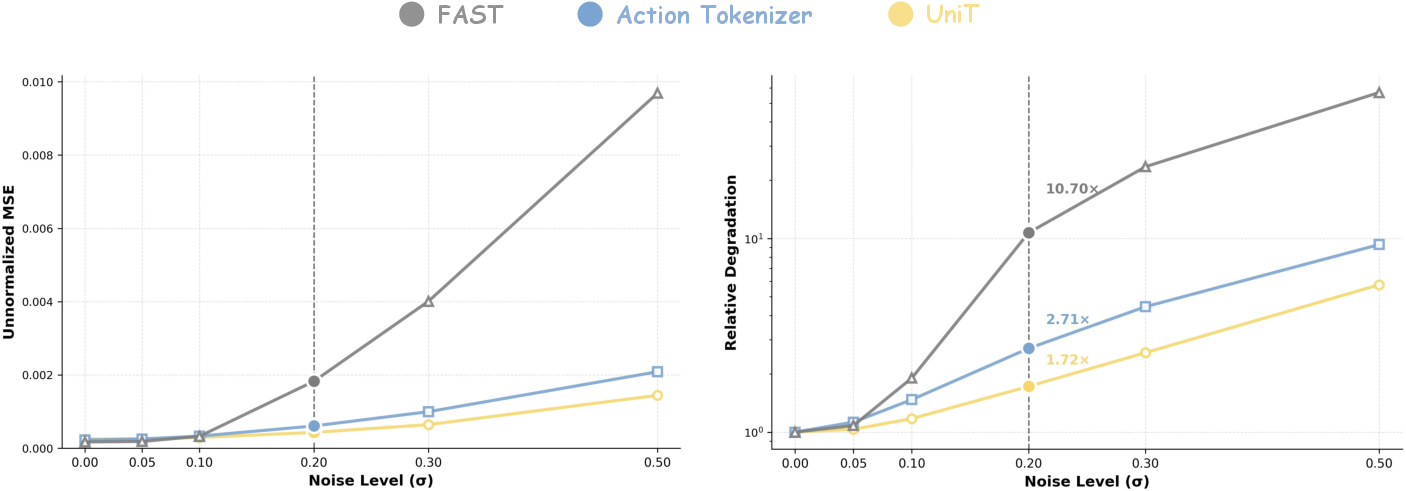
Figure 8: Robustness to injected action noise—visual anchoring filters uncorrelated artifacts, preserving trajectory fidelity.
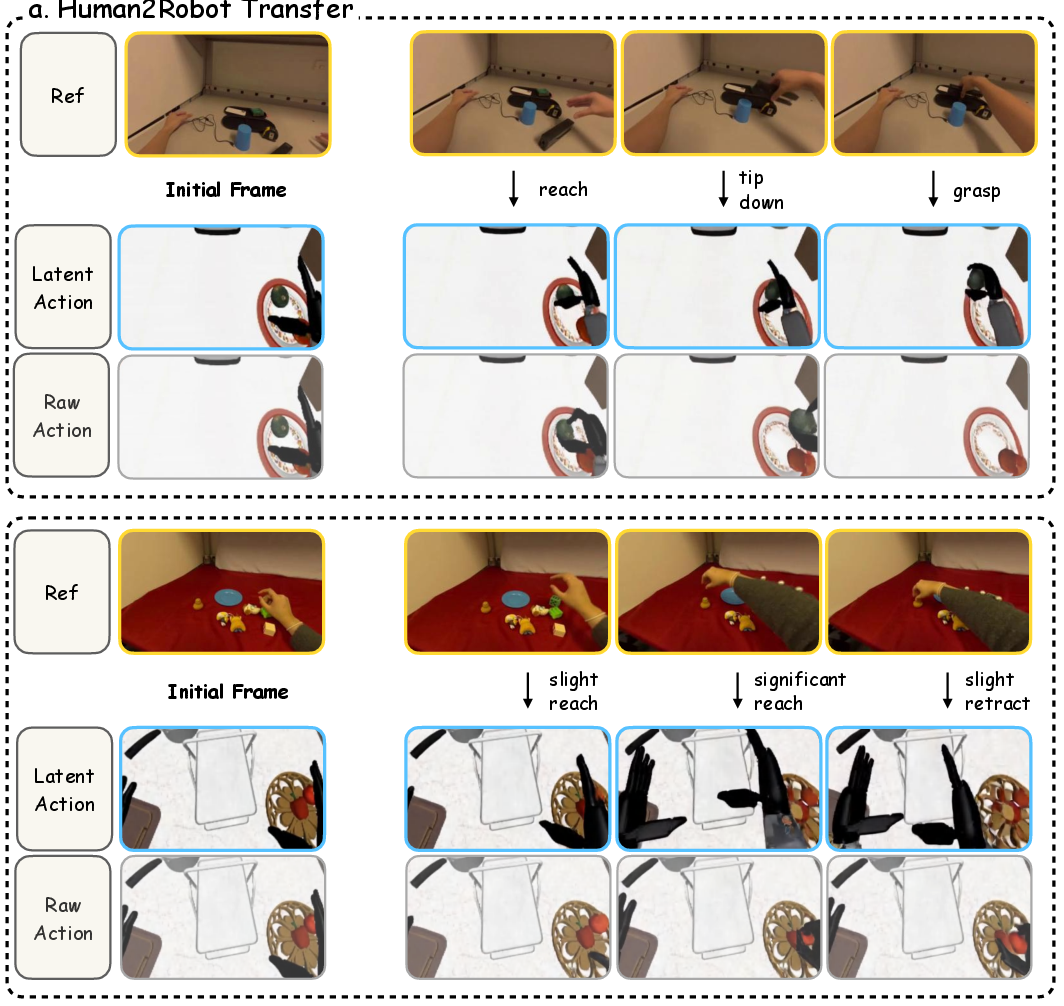
Figure 9: Human-to-robot conditioning yields accurate cross-embodiment video generation compared to raw action conditioning.
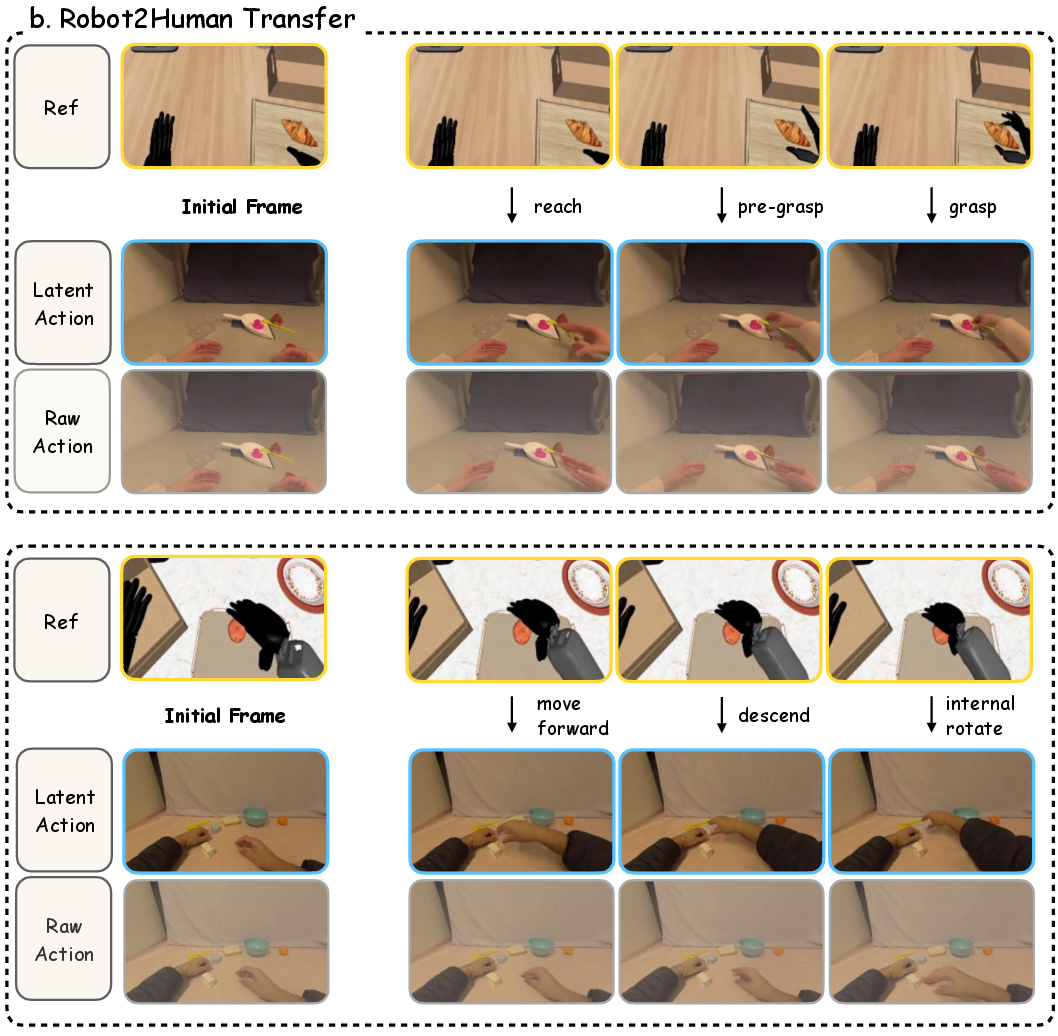
Figure 10: Robot-to-human conditioning illustrating preservation of fine-grained pose and action semantics.
Empirical Evaluation and Ablation
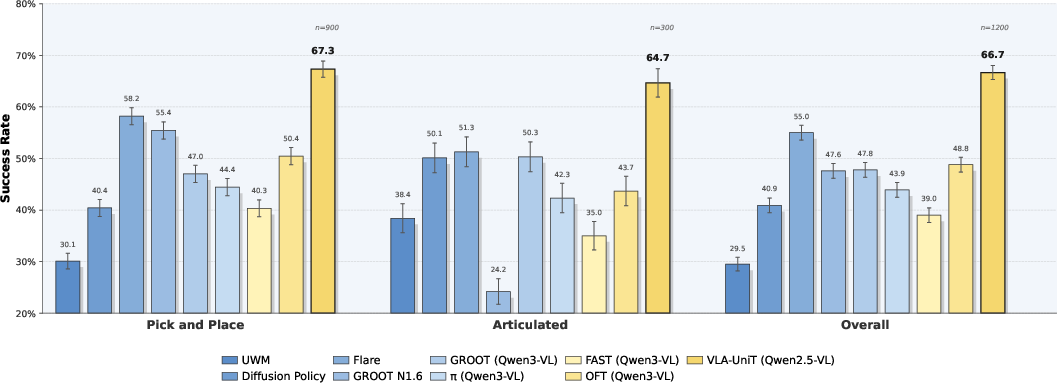
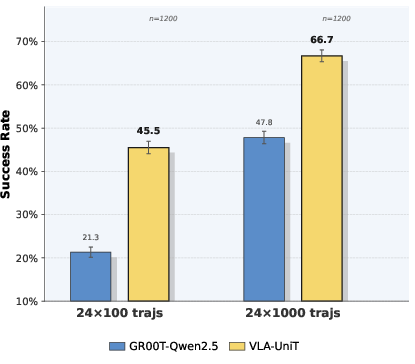
VLA-UniT achieves superior policy success rates on RoboCasa GR1, outperforming baselines by margin (66.7% overall, +18.9% over GR00T) and requiring ∼10× less data for competitive performance. Human demonstrations boost both in-domain and OOD success, enabling zero-shot transfer and emergent upper-body coordination in unseen tasks.
Ablations validate UniT's architectural claims:
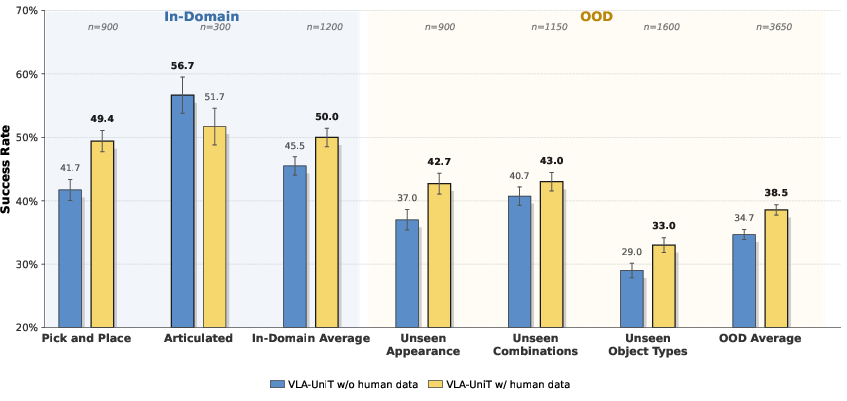
Figure 12: Sample efficiency and impact of human co-training—substantial gains in few-shot scenarios.
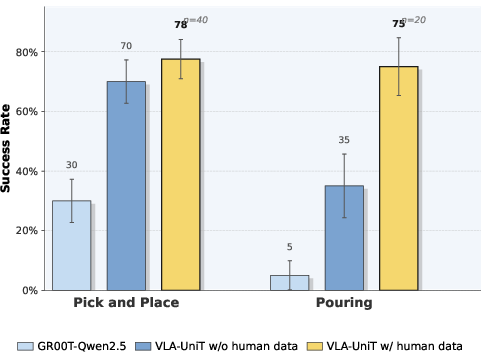
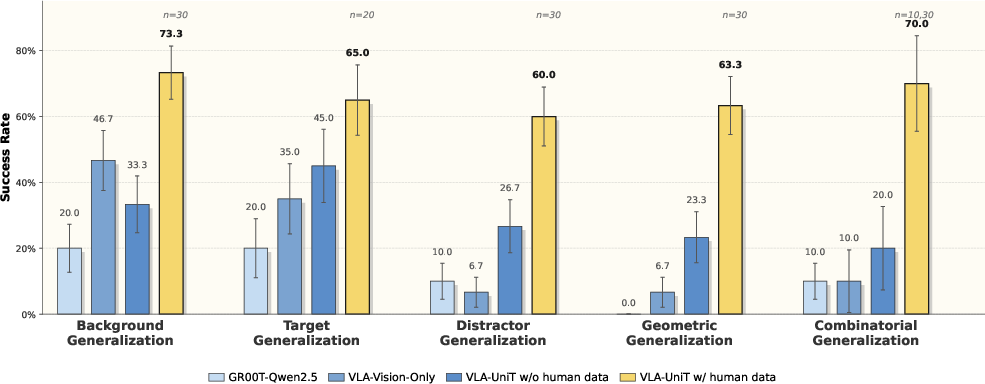
Figure 13: Real-world deployment: boosting both execution and OOD robustness via human demonstration.
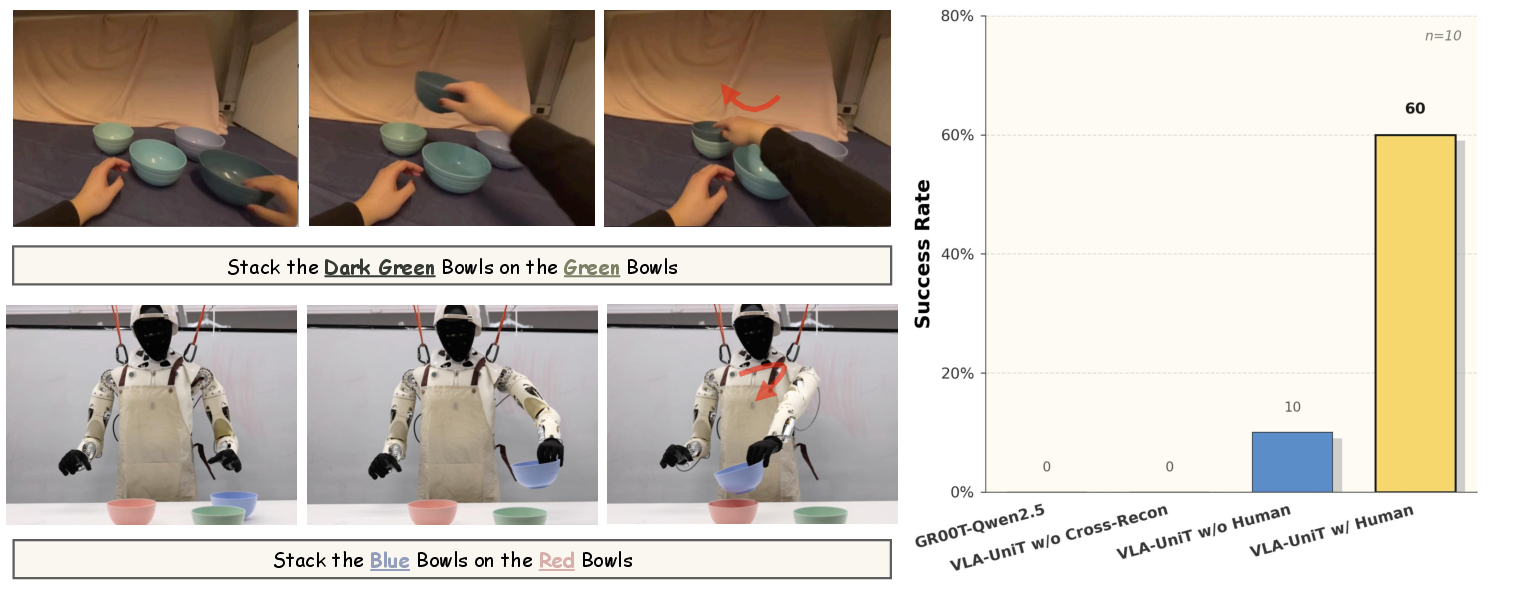
Figure 14: Zero-shot transfer on unseen stacking task—uniquely enabled by UniT's shared latent space.
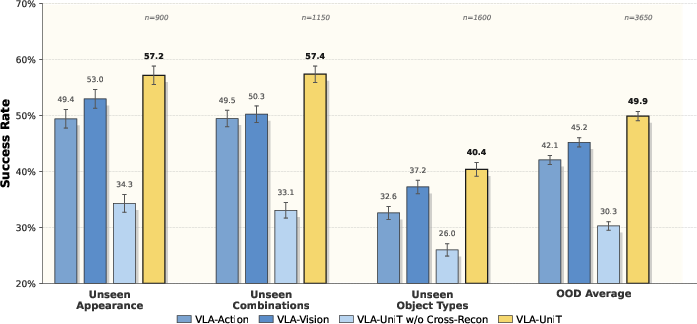
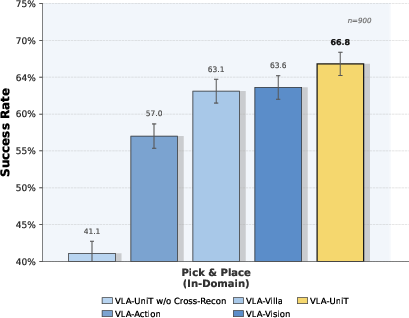
Figure 15: Tokenizer ablation demonstrating effectiveness of vision-action cross-reconstruction in policy generalization.
Theoretical and Practical Implications
UniT formalizes a scalable, data-driven unified physical language, circumventing manual retargeting and domain-specific solvers. This framework offers a universal tokenization interface for both policy and world modeling, facilitating co-evolution of imagined rollouts, test-time planning, and reinforcement learning within a single latent action space.
The visual branch's ability to encode physical transitions without paired action labels suggests that vast internet-scale human video datasets can be harnessed, augmenting physical priors and broadening embodied intelligence coverage. This approach is poised to unlock dexterous coordination, robust generalization, and compositional reasoning directly from multimodal human demonstrations.
Conclusion
UniT advances the state of the art in cross-embodiment policy learning and world modeling for humanoids, backed by strong empirical results and architectural ablations. Visual-anchored latent tokenization and bidirectional cross-reconstruction are fundamental for producing robust, transferable action representations. Future work should scale UniT to internet-scale video, explore joint policy/world-model planning, and further exploit compositional generalization by leveraging diverse and unstructured human demonstrations.