- The paper introduces the Humanoid-X dataset of over 20 million poses mined from human videos for text-to-action mapping.
- The UH-1 model employs a Transformer architecture to tokenize and decode natural language commands into precise humanoid actions.
- Experiments in simulation and real-world settings demonstrate robust control with nearly 100% success rate.
Universal Humanoid Pose Control via Learning from Massive Human Videos
This paper introduces Humanoid-X, a large-scale dataset of over 20 million humanoid robot poses with corresponding text-based motion descriptions, and UH-1, a large humanoid model for universal language-conditioned pose control of humanoid robots. The approach leverages human videos mined from the Internet to train a Transformer-based model that maps text instructions to robot actions. The authors demonstrate the effectiveness of their approach through extensive simulations and real-world experiments on a humanoid robot.
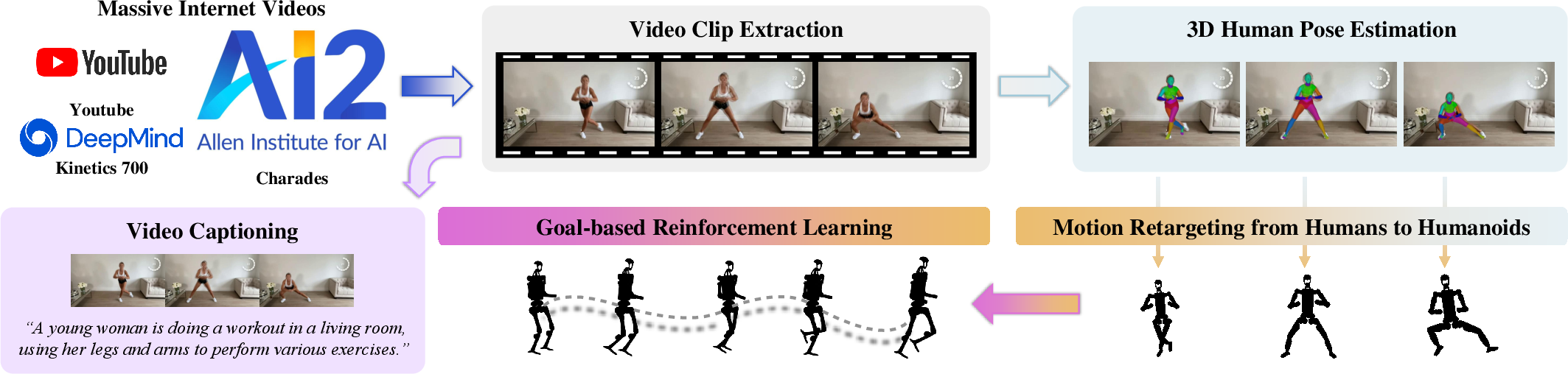
Figure 1: Learning Humanoid Pose Control from Massive Videos. We mine massive human-centric video clips V from the Internet.
Humanoid-X Dataset Creation
The Humanoid-X dataset is constructed using a comprehensive pipeline involving data mining from the Internet, video caption generation using Video-LLaMA (Cheng et al., 2024), motion retargeting of humans to humanoid robots, and policy learning for real-world deployment (Figure 1). The data encompasses a diverse range of human actions, with corresponding text descriptions generated using a video captioning model. The dataset includes both robotic keypoints for high-level control and robotic target DoF positions for direct position control. Humanoid-X contains 163,800 motion samples and covers approximately 240 hours of data.
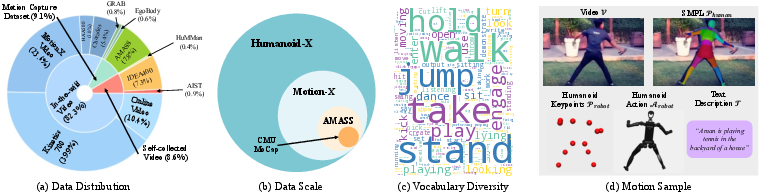
Figure 2: Dataset Statistics. Humanoid-X features extensive scale, diverse sources, a rich action vocabulary, and multiple data modalities.
UH-1 Model Architecture and Training
The UH-1 model employs a Transformer architecture to map text commands to humanoid actions (Figure 3). The approach involves discretizing humanoid actions into action tokens, creating a vocabulary of motion primitives. The Transformer model then auto-regressively decodes a sequence of these tokenized humanoid robotic actions given a text command as input. The model supports two control modes: text-to-keypoint, where the model generates high-level humanoid keypoints, and text-to-action, where the model generates robotic actions directly (Figure 4).
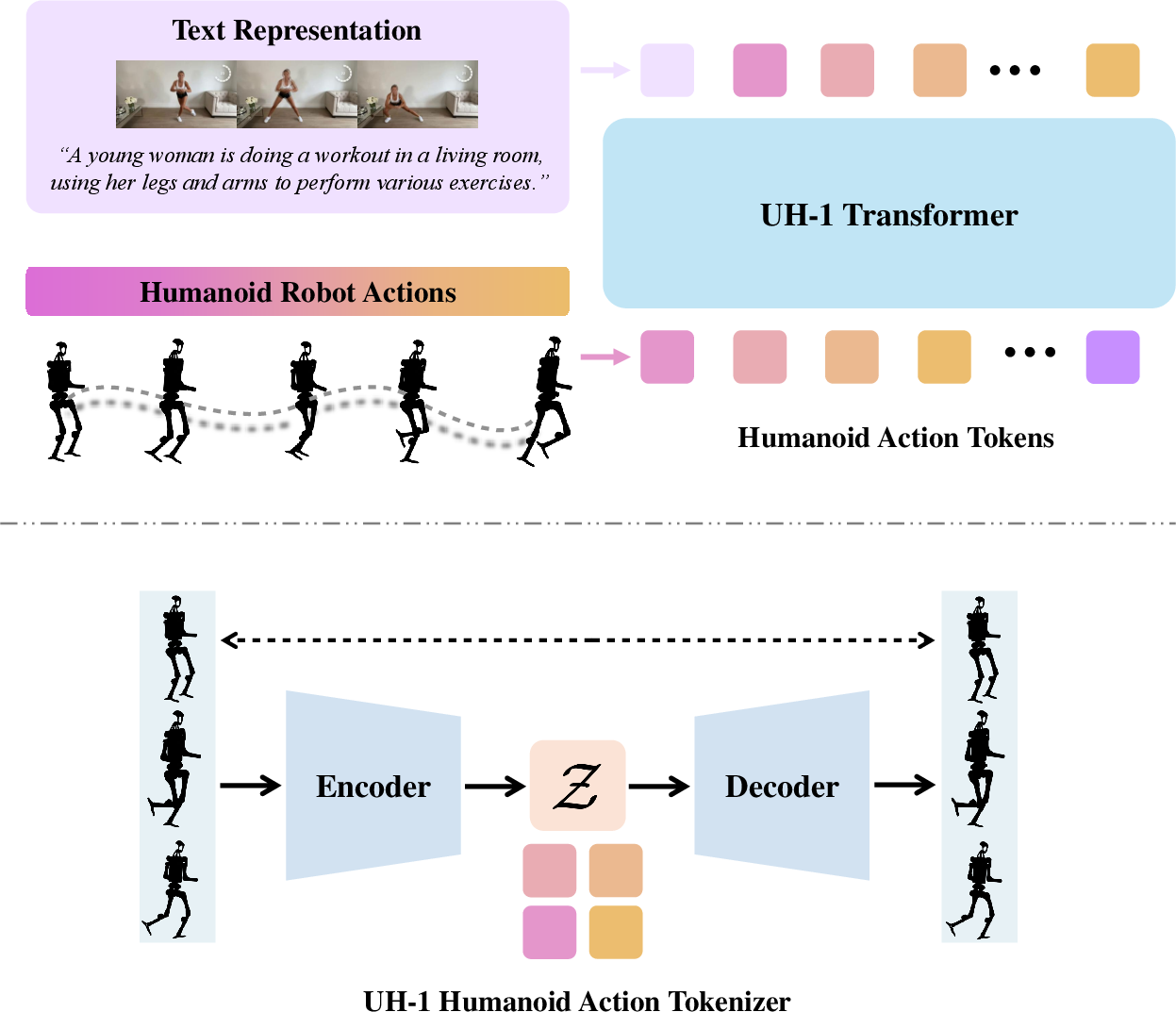
Figure 3: UH-1 Model Architecture. UH-1 leverages the Transformer for scalable learning. Humanoid actions are first tokenized into discrete action tokens. Then, we train the UH-1 Transformer that takes text commands as inputs and auto-regressively generates the corresponding humanoid action tokens.
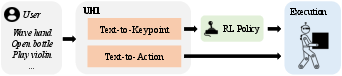
Figure 4: Text-to-keypoint and text-to-action control modes. UH-1 can either generate high-level humanoid keypoints (text-to-keypoint) for the goal-conditioned policy pi to control the humanoid robot in closed-loop, or generate robotic actions A for direct open-loop control.
Experimental Results
The authors conducted experiments in both simulated and real-world environments to validate the effectiveness of the Humanoid-X dataset and the UH-1 model. Results show that the model can translate textual commands into diverse and contextually accurate humanoid actions. The UH-1 model demonstrates strong robustness and can be reliably deployed in real-world scenarios with a high success rate (Figure 5). The experiments also demonstrate that increasing the dataset size leads to significant improvements in both FID and Diversity metrics (Figure 6). The paper includes ablation studies on the vocabulary sizes of the UH-1 action tokenizer (Figure 7), and a comparison of Transformer and diffusion model architectures.

Figure 5: Real robot experiment. UH-1 model can be reliably deployed on the real humanoid robot with a nearly 100\% success rate.
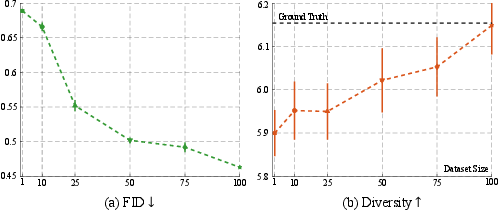
Figure 6: Effectiveness of scaling up training data. Points indicate the mean values, and error bars indicate the 95\% confidence interval. Increasing the dataset size from 1\% to 100\% leads to significant improvements in both FID and Diversity metric.
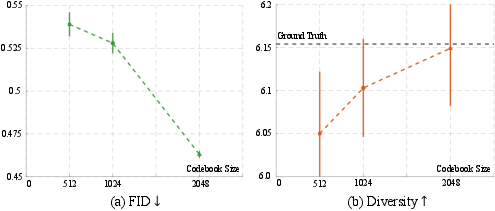
Figure 7: Ablation on the vocabulary sizes of the UH-1 action tokenizer. Increasing the vocabulary size of the action tokenizer provides more motion primitives for humanoid robots and thus leads to an improvement in both FID and Diversity metric.
Implications and Future Directions
This research demonstrates a scalable approach to training humanoid robots using large amounts of readily available video data. The Humanoid-X dataset and the UH-1 model provide a foundation for developing more adaptable, real-world-ready humanoid robots. The ability to control humanoid robots with natural language commands opens up new possibilities for human-robot interaction and collaboration. Future work could explore learning humanoid loco-manipulation from Internet videos and extending the approach to more complex tasks and environments.

