- The paper introduces a backbone–action-head framework that unifies vision-language and world-model paradigms for robotic manipulation.
- It employs a modular design with standardized data interfaces and supports four distinct action decoding methods for systematic evaluation.
- Empirical results show significant data efficiency, cross-benchmark generalization, and scalable training up to 256 GPUs.
StarVLA: A Unified, Modular Framework for Vision-Language-Action Model Development
Motivation and Context
StarVLA addresses core challenges in Vision-Language-Action (VLA) research—fragmented codebases, heterogeneous architectural paradigms, non-uniform protocols, and irreproducibility—by providing a modular, open-source platform for VLA model development and benchmarking. The proliferation of vision-language and world models has rapidly advanced embodied policy learning, but the lack of standardization in model abstraction, training, and evaluation hinders systematic comparison and the principled exploration of design trade-offs. StarVLA proposes a backbone–action-head architecture with unified data representation, training, and inference interfaces, supporting both Vision-LLM (VLM)-based and world-model-based policies across major robotic manipulation benchmarks.
Framework Abstraction and System Architecture
The central abstraction in StarVLA is the separation of a vision-language backbone (e.g., Qwen-VL, Cosmos) from a pluggable action head, enabling controlled experiments where architectural or data differences can be isolated while keeping the rest of the pipeline invariant. Input and output are specified at the environment-observation and normalized-action chunk level, respectively, consistent with real-world deployment interfaces. This compositional interface supports a variety of action-decoding paradigms: autoregressive tokenization, parallel regression, iterative flow-matching denoising, and dual-system reasoning.

Figure 1: The unified VLA policy maps visual observations and language instructions to action chunks; the training objective accommodates both action supervision and auxiliary losses for language grounding or dynamic modeling.
Modularity extends through reusable pluggable dataloaders and direct compatibility with diverse vision-language backbones, minimizing code-specific preprocessing and train/test distribution shifts. This invariant-driven design allows any foundation model with a conformant inference path to be immediately integrated, evaluated, or deployed.
Supported VLA Paradigms
StarVLA implements four canonical VLA instantiations within this backbone–head framework:
- FAST: Autoregressive tokenization using a fixed discrete vocabulary sampled via next-token prediction.
- OFT: Lightweight MLP regression of actions from hidden states.
- π: Flow-matching action prediction via iterative denoising using a DiT-based expert, cross-attended to VL representations.
- GR00T: Dual-system reasoning where the backbone handles slow, contextual reasoning and an additional DiT-based head handles fast action generation.
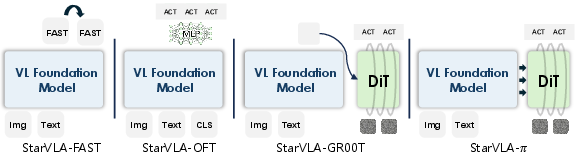
Figure 2: The four principal decoding paradigms (FAST, OFT, π, GR00T) operate over a shared unified interface and backbone, enabling systematic ablation and comparison.
This compositional spectrum covers VLM-native decoding, generative denoising, and dual-inference architectures, demonstrating the unifying capacity of the backbone–action-head abstraction.
Dataflow, Co-Training, and Generalization
The training and inference stack in StarVLA is fully modular, with compositional dataloaders and fully declarative configuration. The framework supports standard supervised behavior cloning, multi-objective co-training (combining web-scale VLM data and robot trajectory data), and cross-embodiment mixtures. Each training regime is supported for all paradigm variants without code modifications. The evaluation protocol is fixture-based with unified server–client communication, supporting seamless switching between simulation, benchmark, and real-robot deployment.
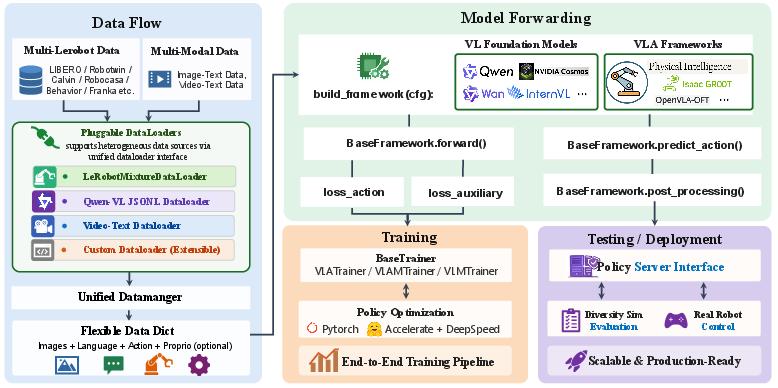
Figure 3: The StarVLA pipeline combines heterogeneous data streams, pluggable dataloader infrastructure, and a standardized model forwarding interface to support flexible training and deployment.
Notably, cross-embodiment training is implemented as a configuration option rather than a method-specific code path, and multimodal co-training can be activated for any paradigm to mitigate catastrophic forgetting of language and perception priors.
Unified Benchmark Integration
StarVLA natively supports multiple major robot manipulation and language-guided control benchmarks, including LIBERO, SimplerEnv, RoboTwin 2.0, RoboCasa-GR1, and BEHAVIOR-1K. Each environment is integrated via lightweight adapters that convert environment observations/actions into the StarVLA example schema, enabling direct, reproducible comparison across tasks, hardware platforms, and action spaces. Model training, checkpointing, and evaluation strictly follow the official protocols of each benchmark. The server–client abstraction decouples policy internals from benchmark logic, supporting real-robot deployment without code-level changes.
Empirical Results and Efficiency
StarVLA reports strong, data-efficient results across all major benchmarks under minimal fine-tuning protocols. On LIBERO, StarVLA-OFT (Qwen3-VL backbone) matches or slightly underperforms OpenVLA-OFT with ∼6× fewer steps and ∼23× fewer epochs. Analogous data efficiency and backbone-agnostic generalization are demonstrated on SimplerEnv, RoboCasa-GR1, and RoboTwin 2.0. In cross-benchmark “generalist” settings with unified action spaces, a single model maintains competitive performance and often improves transfer, with RoboCasa-GR1 success increasing from 48.8% (specialist) to 57.3% (generalist).
StarVLA supports multiobjective co-training, yielding large improvements in multimodal understanding, spatial grounding, and manipulation success over conventional fine-tuning. The “spatially guided co-training” configuration achieves strong gradient alignment between perception and action streams and counteracts the catastrophic forgetting common in single-objective training.
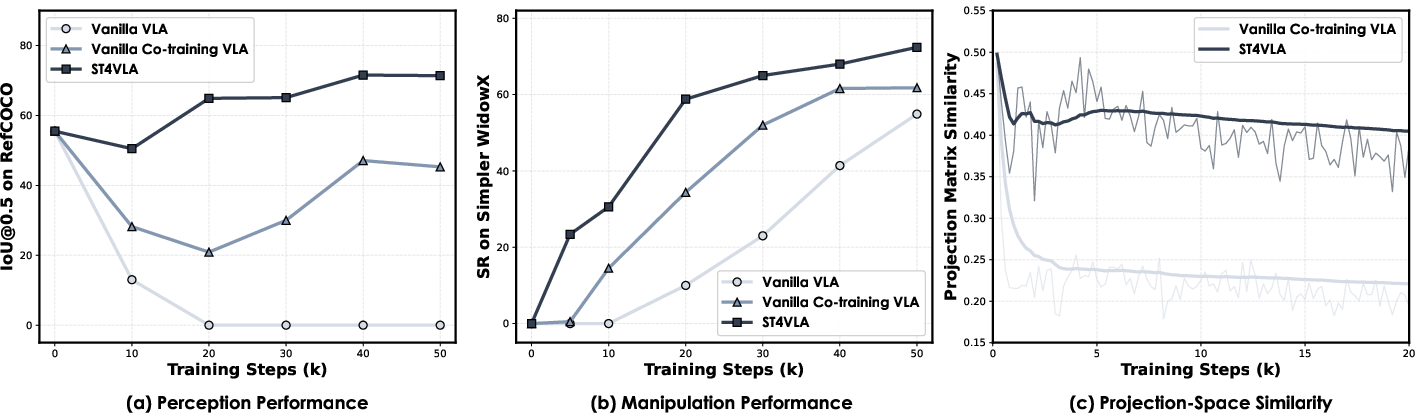
Figure 4: Co-optimization dynamics reveal that spatially guided co-training stabilizes perception and action learning, maintaining high spatial grounding and manipulation performance.
The codebase is engineered for computational efficiency, supporting scalable distributed training to 256 GPUs with ∼80% parallel efficiency—crucially, multi-node communication overhead plateaus, and moderate per-GPU batch sizes maximize GPU utilization and wall-clock throughput.
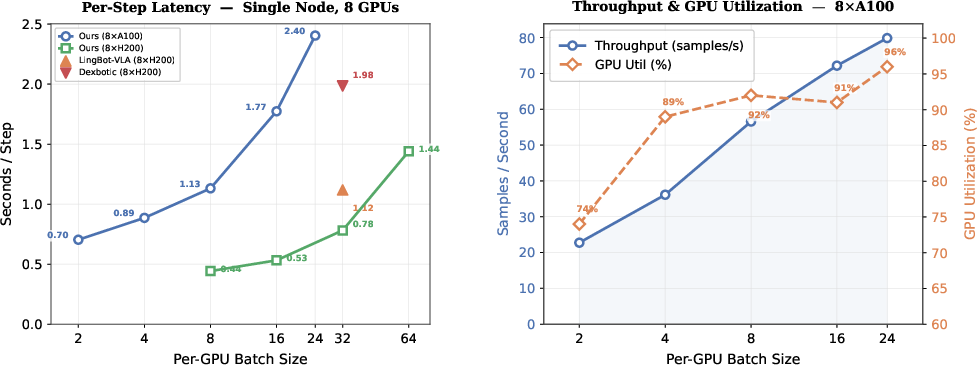
Figure 5: StarVLA exhibits efficient scaling on a single node, with step latency and GPU utilization increasing with per-GPU batch size.
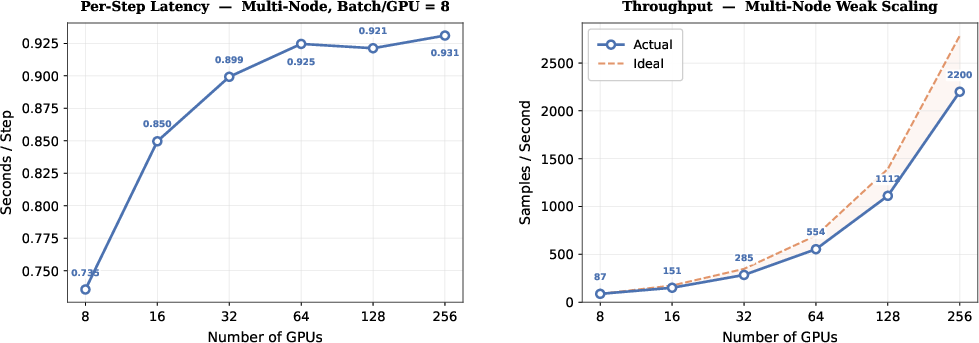
Figure 6: Multi-node scaling is near-linear in sample throughput, with parallel efficiency stabilizing above 79% beyond 32 GPUs.
Implications and Theoretical Perspectives
StarVLA demonstrates that VLM-based and world-model-based VLA systems are not fundamentally disjoint paradigms; when codebase and interface differences are minimized, their design space is unified under the backbone–action-head abstraction. This “generalized VLA perspective” reframes auxiliaries such as language grounding or future observation prediction as instantiations of the same inductive bias, permitting systematic study of architectural and data-driven variations. Practically, StarVLA closes the gap between research prototyping and deployment, and theoretically, it motivates the study of compositional, declarative interfaces that abstract away underlying model complexity. The codebase also positions VLA research to pursue larger-scale, all-in-one pretraining analogous to current LLM scaling regimes.
Conclusion
StarVLA provides a comprehensive, engineering- and research-oriented unification of the Vision-Language-Action paradigm. The modular backbone–action-head abstraction, compositional data and training infrastructure, and strict adherence to official evaluation protocols enable systematic, reproducible, cross-benchmark and cross-embodiment research. With state-of-the-art or competitive results, plug-and-play extensibility, and robust real-robot deployment support, StarVLA is positioned as the reference codebase for VLA research, setting the agenda for future work on robotic generalist policies, unified scaling, and theory-driven architecture search.
Reference: "StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing" (2604.05014)

