- The paper demonstrates that trajectory-level supervision with Groupwise Ranking Reward yields simultaneous improvements in answer accuracy and reasoning faithfulness.
- The study systematically compares reward models, generative rewards, and groupwise ranking to address the limitations of outcome-only reinforcement learning.
- Empirical results on multimodal benchmarks show that the novel approach significantly reduces reasoning inconsistency rates while boosting reliability-conditioned accuracy.
Incentivizing Reliable Multimodal Reasoning Beyond Outcome Correctness
Problem Overview and Motivation
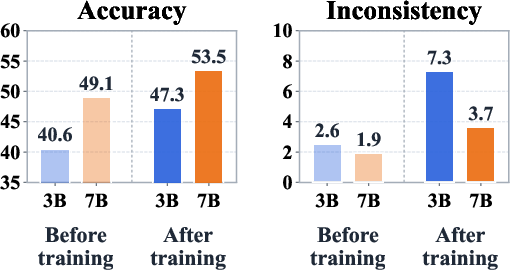
Standard reinforcement learning with verifiable rewards (RLVR) methods optimize multimodal LLMs (MLLMs) toward answer correctness by rewarding model-generated responses that attain the correct final answer under a rule-based verification process. However, this outcome-centric protocol neglects the quality and faithfulness of the reasoning trajectories that precede the answer. Empirical analysis demonstrates that, as RLVR training progresses, MLLMs increasingly generate answers supported by incomplete, weakly justified, or outright inconsistent chains of thought, leading to an undesirable escalation in what the authors term reasoning-answer inconsistency: responses where the answer is verifiably correct but the reasoning is misaligned or contradictory.
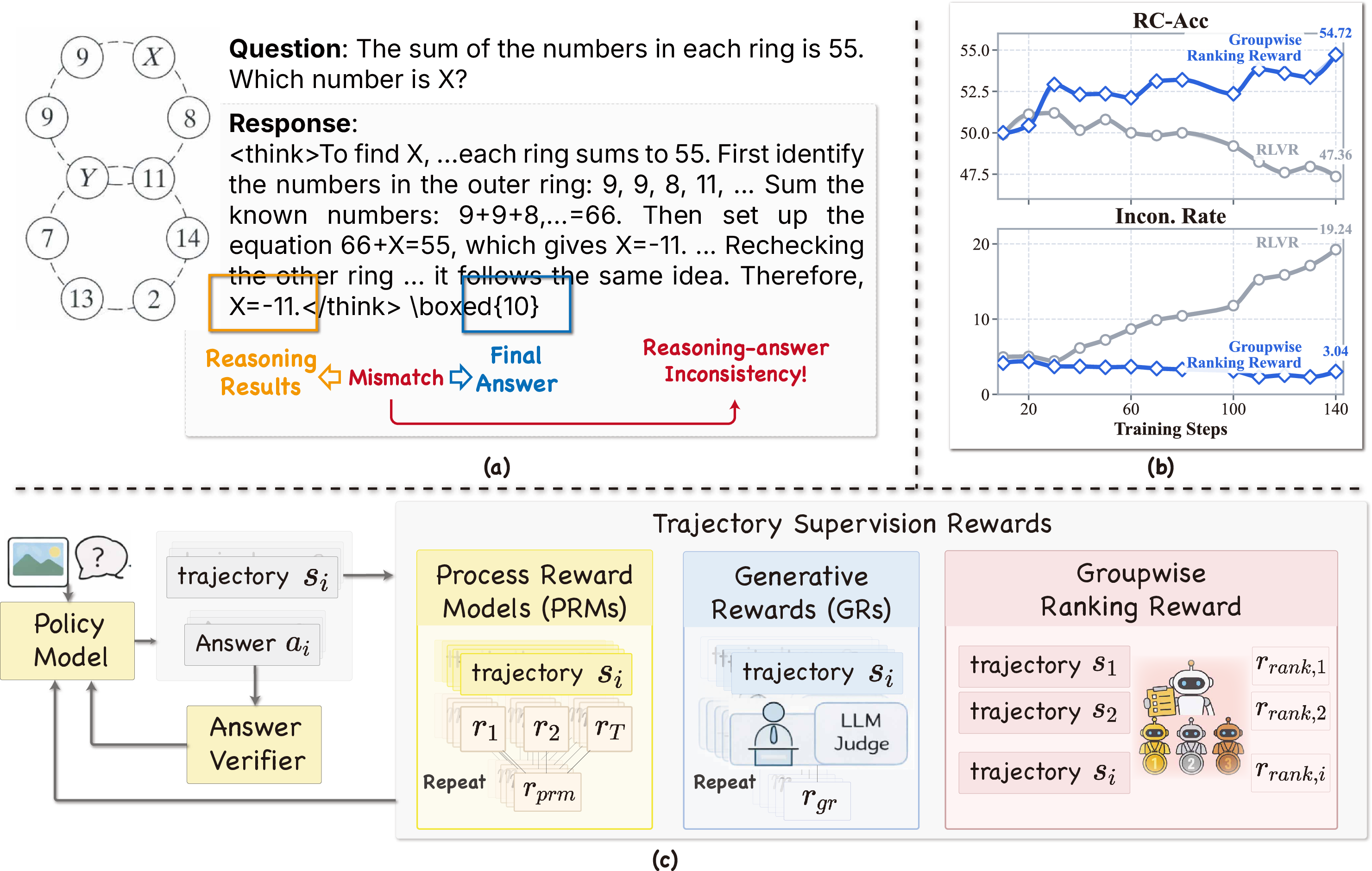
Figure 1: Illustrative case of reasoning-answer inconsistency under outcome-only RLVR and a preview of Groupwise Ranking Reward’s effect on training dynamics and reward structure.
This phenomenon is particularly problematic in high-stakes applications—such as medical diagnosis or scientific computation—where reliable, interpretable reasoning is required. The core insight is that answer correctness is a poor surrogate for mechanistic reasoning quality, and optimization on outcome alone amplifies the likelihood of unfaithful reasoning trajectories. Thus, the challenge addressed is how to efficiently and effectively inject trajectory-level supervision signals into the training of MLLMs for robust, faithful multimodal reasoning.
To address this limitation, the paper systematically analyzes three distinct approaches to trajectory supervision that supplement standard RLVR pipelines:
- Reward Models (RMs): These offer direct scalar rewards, applied at either the step or trajectory level. In this work, a Vision-Language Process Reward Model (PRM) is used to assign true/false rewards to each step, aggregated to a per-trajectory score via simple averaging. This provides computationally efficient, dense supervision but is susceptible to policy distribution shift and limited generalization.
- Generative Rewards (GRs): A LLM-as-a-judge is prompted to evaluate each rollout independently using rubric-based natural language feedback and explicit scalar scores. This pointwise generative reward mechanism is richer and less static than fixed reward models but introduces significant judge overhead and reward noise due to repeated, isolated evaluations.
- Groupwise Ranking Reward: The novel contribution of the paper, this approach generalizes GRs from independent scoring to comparative evaluation across all verifier-passed rollouts from the same prompt. The judge is instructed to assign tie-aware ranking tiers instead of absolute scores, which are then mapped to normalized, zero-centered scalar rewards reflecting the relative merits of each reasoning trajectory. This enables efficient batch judging and accentuates the difference between stronger and weaker correct trajectories, thereby providing a more discriminative signal for learning.
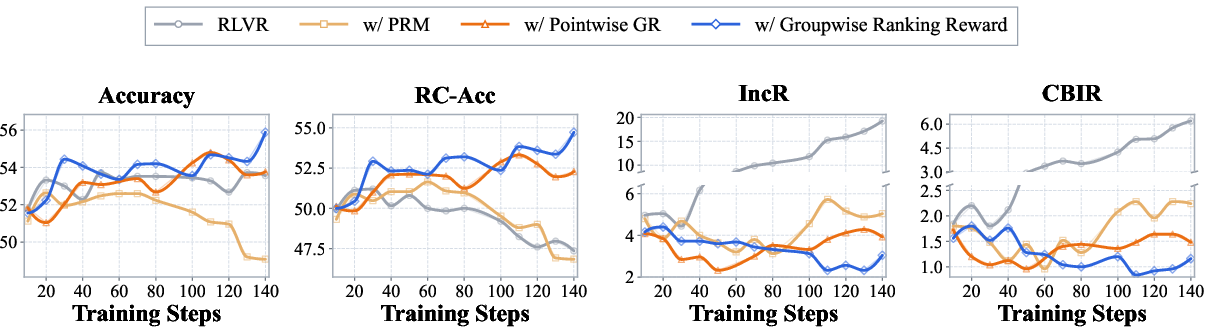
Figure 2: Training dynamics for RLVR, PRM, pointwise GR, and Groupwise Ranking. Groupwise Ranking simultaneously improves answer accuracy and reliability-conditioned accuracy, while suppressing both overall and correct-but-inconsistent reasoning rates.
Experimental Results
Setup and Metrics
Extensive experiments are conducted using Qwen2.5-VL models (7B), trained with each trajectory supervision variant on the ViRL multimodal corpus and evaluated on five benchmarks spanning mathematical reasoning and general-purpose visual question answering. The primary evaluation metrics include:
- Accuracy (Acc): Standard answer correctness.
- Reliability-Conditioned Accuracy (RC-Acc): Correct answers with fully consistent reasoning, discounting any correct-but-inconsistent cases.
- IncR: Overall inconsistency rate.
- CBIR: Correct-but-inconsistent rate.
Empirical Findings
The experimental findings delineate profound differences among the evaluated reward structures:
The gains from Groupwise Ranking Reward are broad-based, holding across all evaluated benchmarks and both multiple-choice and open-ended question types. Detailed ablation confirms that the specific mapping from ranks to reward has only a minor effect relative to the benefit of groupwise comparison itself.
Theoretical and Practical Implications
The central implication is that answer correctness is insufficient as a reinforcement learning objective for MLLMs, since outcome-only rewards encourage policies to exploit any path to the answer—regardless of interpretability or consistency. Trajectory supervision changes the credit assignment structure in RL, enabling the model to distinguish and prefer trajectories that are not only answer-correct but also logically valid and faithful.
From a systems perspective, Groupwise Ranking Reward offers substantial computational gains: batch-based, tie-aware ranking reduces the number of judge calls and variance in assigned rewards, making the training process more stable. Furthermore, groupwise reward assignment is more robust to fluctuations in the judge’s intrinsic scoring calibration, as intra-prompt comparison ensures a fixed reference standard for the evaluation.
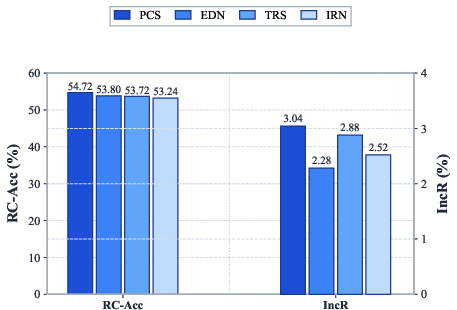
Figure 4: Ablation study across four rank-to-score mapping variants confirms negligible sensitivity, with the main gain accruing from groupwise comparison itself.
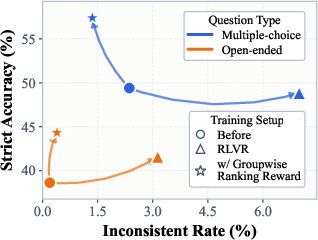
Figure 5: Consistency-accuracy trade-off trajectories by question type and training method; Groupwise Ranking closes the faithfulness gap for both open-ended and multiple-choice settings.
This trajectory-level supervision framework is readily extensible to other RL pipelines optimizing for faithful multistep reasoning, and is especially pertinent for multimodal domains where the alignment between visual/textual evidence and final predictions cannot be assumed.
Limitations and Future Directions
The scope of this analysis is confined to tasks for which final answer correctness is verifiable and trajectory-level pathologies are well-defined. Applications involving subjective, creative, or unstructured outputs may require new consistency metrics and reward paradigms. Additionally, while groupwise comparison is shown to be highly effective, its reliability is contingent on the robustness of the judge model to adversarial or out-of-distribution reasoning chains.
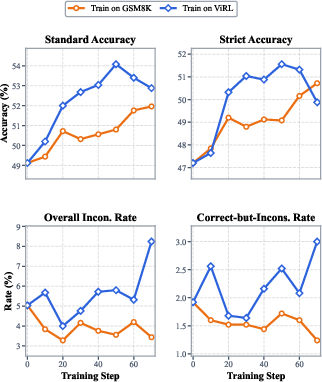
Figure 6: Models trained on text-only arithmetic (GSM8K) maintain low reasoning inconsistency, while multimodal ViRL training achieves stronger accuracy but at increased risk of spurious reasoning.
Open directions include generalizing ranking-based reward frameworks to non-verifiable or open-ended multimodal tasks, investigating judge robustness against prompt distribution shift, and designing scalable, adaptive judge policies that can better audit and incentivize faithful reasoning under adversarial conditions.
Conclusion
This study demonstrates that trajectory-level reward assignment, especially via groupwise ranking, is critical for closing the gap between answer correctness and reliable reasoning in MLLMs. By redistributing reward among verifier-passed rollouts according to relative reasoning quality, Groupwise Ranking Reward offers both theoretical and empirical advances—improving the training signal’s faithfulness and the ultimate trustworthiness of model-generated rationales. This line of work motivates a reorientation of RL training objectives in MLLMs toward comprehensive, consistency-aware supervision paradigms for high-assurance reasoning.