Agentic Forecasting using Sequential Bayesian Updating of Linguistic Beliefs
Abstract: We present BLF (Bayesian Linguistic Forecaster), an agentic system for binary forecasting that achieves state-of-the-art performance on the ForecastBench benchmark. The system is built on three ideas. (1) A linguistic belief state: a semi-structured representation combining numerical probability estimates with natural-language evidence summaries, updated by the LLM at each step of an iterative tool-use loop. This contrasts with the common approach of appending all retrieved evidence to an ever-growing context. (2) Hierarchical multi-trial aggregation: running $K$ independent trials and combining them using logit-space shrinkage with a data-dependent prior. (3) Hierarchical calibration: Platt scaling with a hierarchical prior, which avoids over-shrinking extreme predictions for sources with skewed base rates. On 400 backtesting questions from the ForecastBench leaderboard, BLF outperforms all the top public methods, including Cassi, GPT-5, Grok~4.20, and Foresight-32B. Ablation studies show that the structured belief state is almost as impactful as web search access, and that shrinkage aggregation and hierarchical calibration each provide significant additional gains. In addition, we develop a robust back-testing framework with a leakage rate below 1.5\%, and use rigorous statistical methodology to compare different methods while controlling for various sources of noise.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces BLF (Bayesian Linguistic Forecaster), an AI system that predicts yes/no outcomes, like “Will X happen by date Y?” It uses a smart loop of searching, reading, and updating its own “beliefs” step by step. On a popular forecasting benchmark (ForecastBench), BLF beats other top systems and even matches human “superforecasters” on one key score. The authors also show careful testing to avoid “cheating” by accidentally seeing future information.
What Questions Did the Paper Try to Answer?
In simple terms, the authors wanted to know:
- Can an AI that thinks in steps (like a careful detective) predict future yes/no events better than current best methods?
- Does keeping a tidy “belief notebook” (mixing numbers and short summaries of evidence) help more than dumping all text into memory?
- If we run the forecaster several times and combine the answers, can we get a more reliable result?
- How do we fix (calibrate) the AI’s confidence so that “70% likely” really happens about 70% of the time?
- How can we test all this without accidentally letting the AI peek at future info?
How Did They Do It?
The system focuses on binary questions (answer is yes or no), like:
- Judgment questions: “Will person X have job Y by date Z?”
- Data questions turned into yes/no: “Will this number (like a stock price) be higher than today’s by a future date?”
Here are the main parts, explained with everyday ideas:
1) A “linguistic belief state” (a tidy belief notebook)
- Instead of stuffing every search result into a giant text blob, the AI keeps a neat, short record after each step:
- A probability (e.g., 0.62 means 62% chance)
- A few bullet points for evidence for and against
- What it’s still unsure about
- Think of it like a detective updating a case file after each clue, not just piling papers on the desk. This helps the AI focus and avoid getting lost.
2) Multi-trial aggregation (ask multiple times, then combine)
- The forecaster can give slightly different answers each run. So they run it K=5 times independently and then average the probabilities in a special way that handles extremes better (called “logit-space” averaging).
- Analogy: You ask five smart friends, then combine their opinions. If they disagree a lot, the final answer is pulled toward 50% (less overconfident).
3) Hierarchical calibration (make confidence match reality)
- “Calibration” means if the AI says 80% often, about 8 out of 10 of those should be right.
- They use a method called Platt scaling to adjust raw probabilities so they match real outcomes better.
- “Hierarchical” here means different data sources (like markets vs. time-series datasets) get small, source-specific adjustments. This avoids unfairly shrinking strong, well-supported predictions.
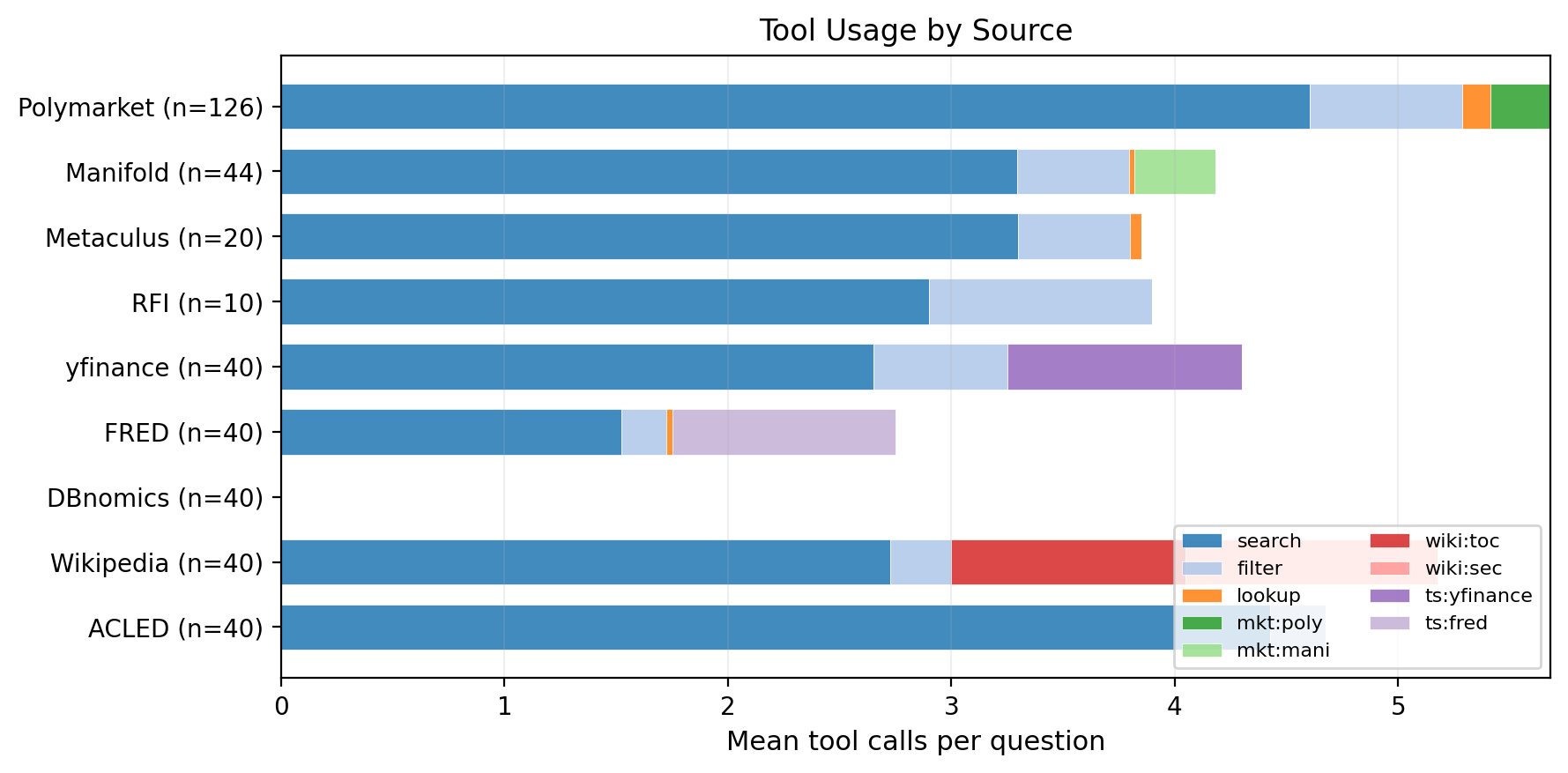
4) Agent loop with tools (search, fetch, summarize)
- The AI works in steps:
- Decide an action (search the web, open a link, fetch data, summarize, or submit a final probability)
- Get results (with strict date limits so it can’t see beyond the forecast date)
- Update the belief notebook (probability + evidence)
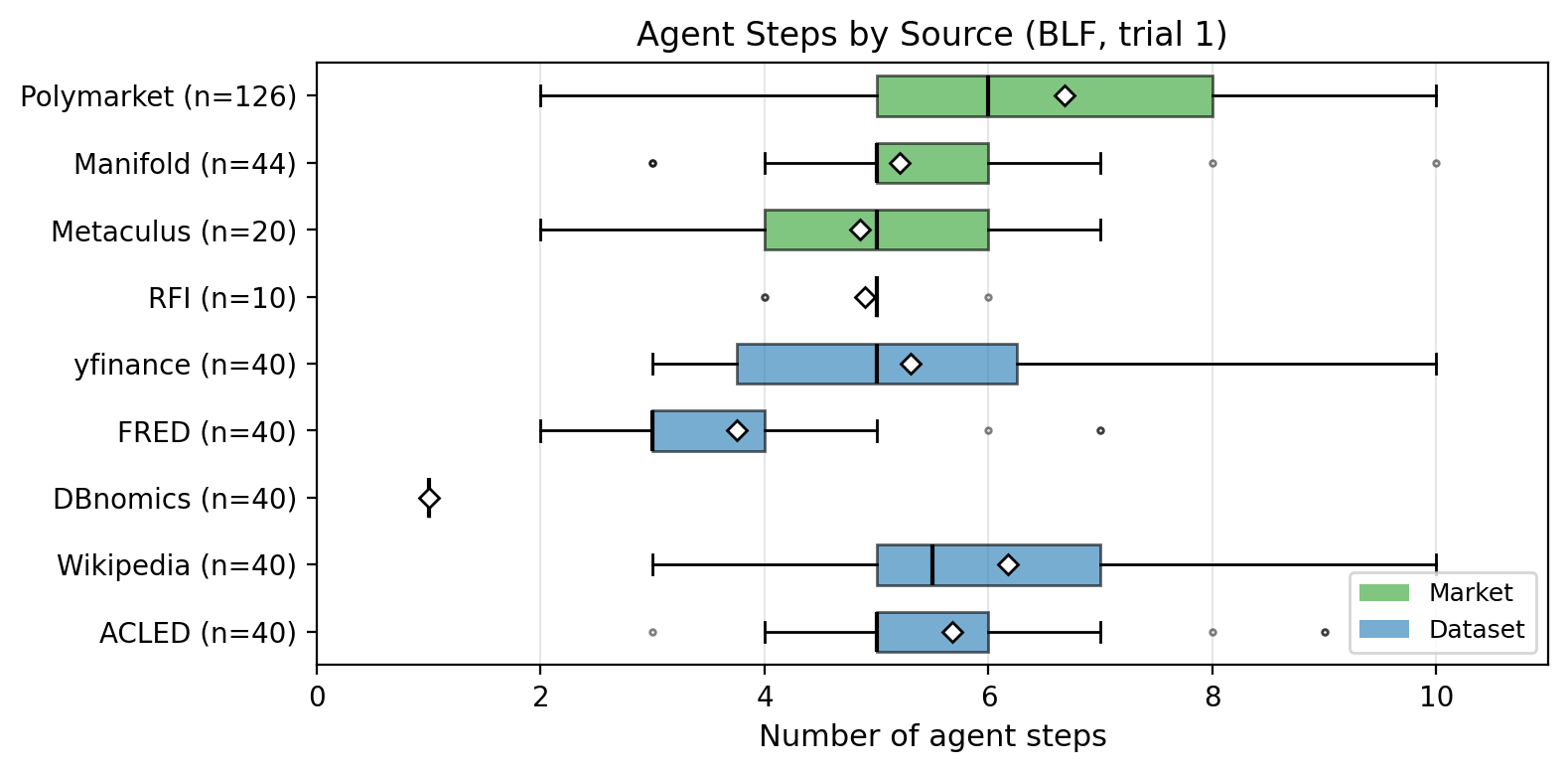
- Repeat up to 10 steps, then submit
- They also built a four-layer “no time travel” defense to avoid future leaks:
- Filter search results by date
- An extra leak check to catch late-dated info
- Data tools locked to past dates
- Block certain URLs that could reveal outcomes
5) Evaluation and metrics (how they scored it)
- Main score: Brier Index (BI). Higher is better. 100 = perfect; 50 = just guessing 50/50.
- Tested on 400 forecasting questions (with 791 total yes/no outcomes) from ForecastBench, across two time windows. They also compared against top public systems.
What Did They Find?
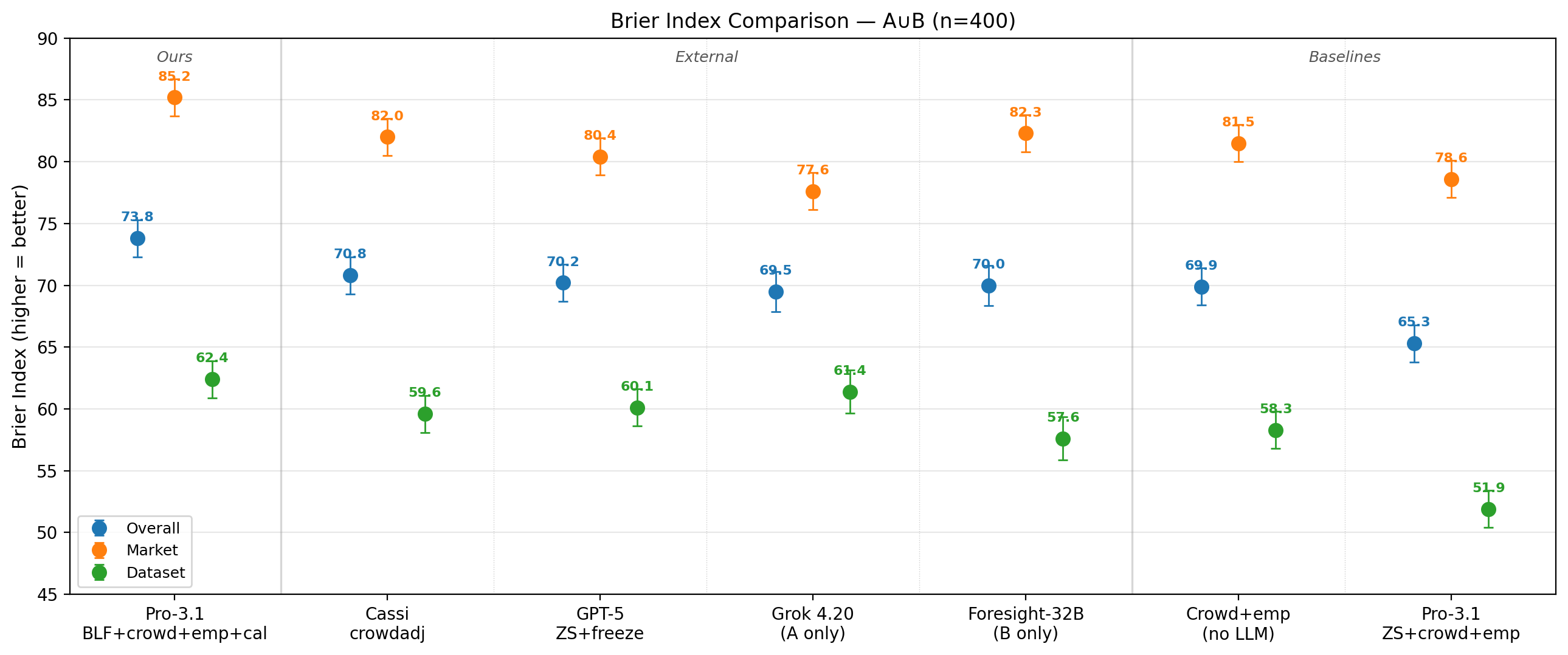
- BLF outperformed all listed top methods (like Cassi, GPT-5 zero-shot, Grok 4.20, and Foresight-32B) on the combined ForecastBench tests.
- On market questions, BLF was the only method that clearly beat the “crowd” baseline (the market price), which is a very strong starting point.
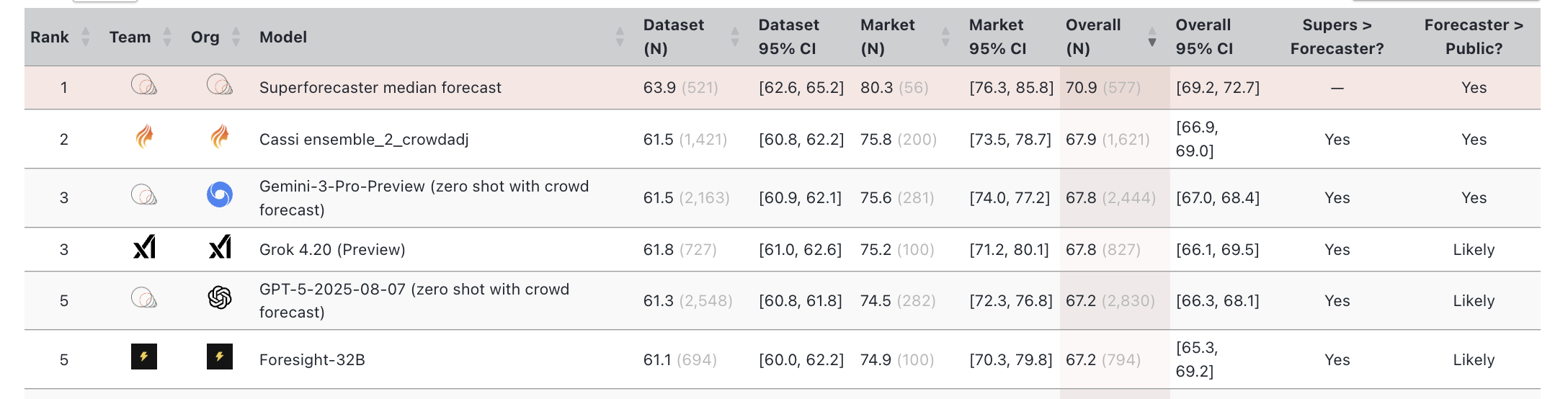
- Their difficulty-adjusted Brier Index matched the human superforecaster median on the leaderboard (a big deal, though they warn direct comparisons need caution).
- Important pieces that boosted accuracy:
- Web search helped a lot.
- The “belief notebook” (linguistic belief state) helped almost as much as web search.
- Doing several runs and averaging helped.
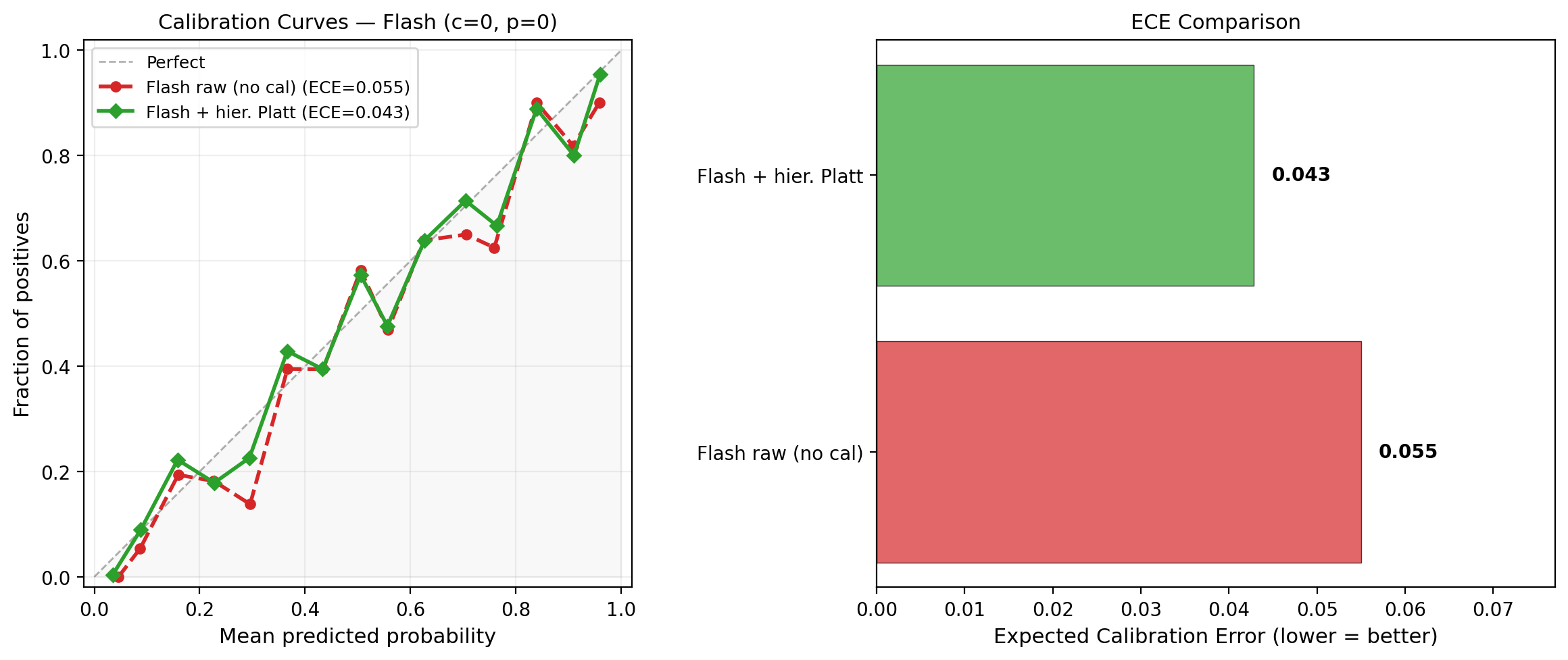
- Hierarchical calibration improved probability realism without squashing justified extreme predictions.
- Running the agent step-by-step (search then reason then update) worked better than doing one big batch of searches and reasoning once.
- They found strong evidence that more trials (e.g., 5 vs. 1) consistently improve reliability.
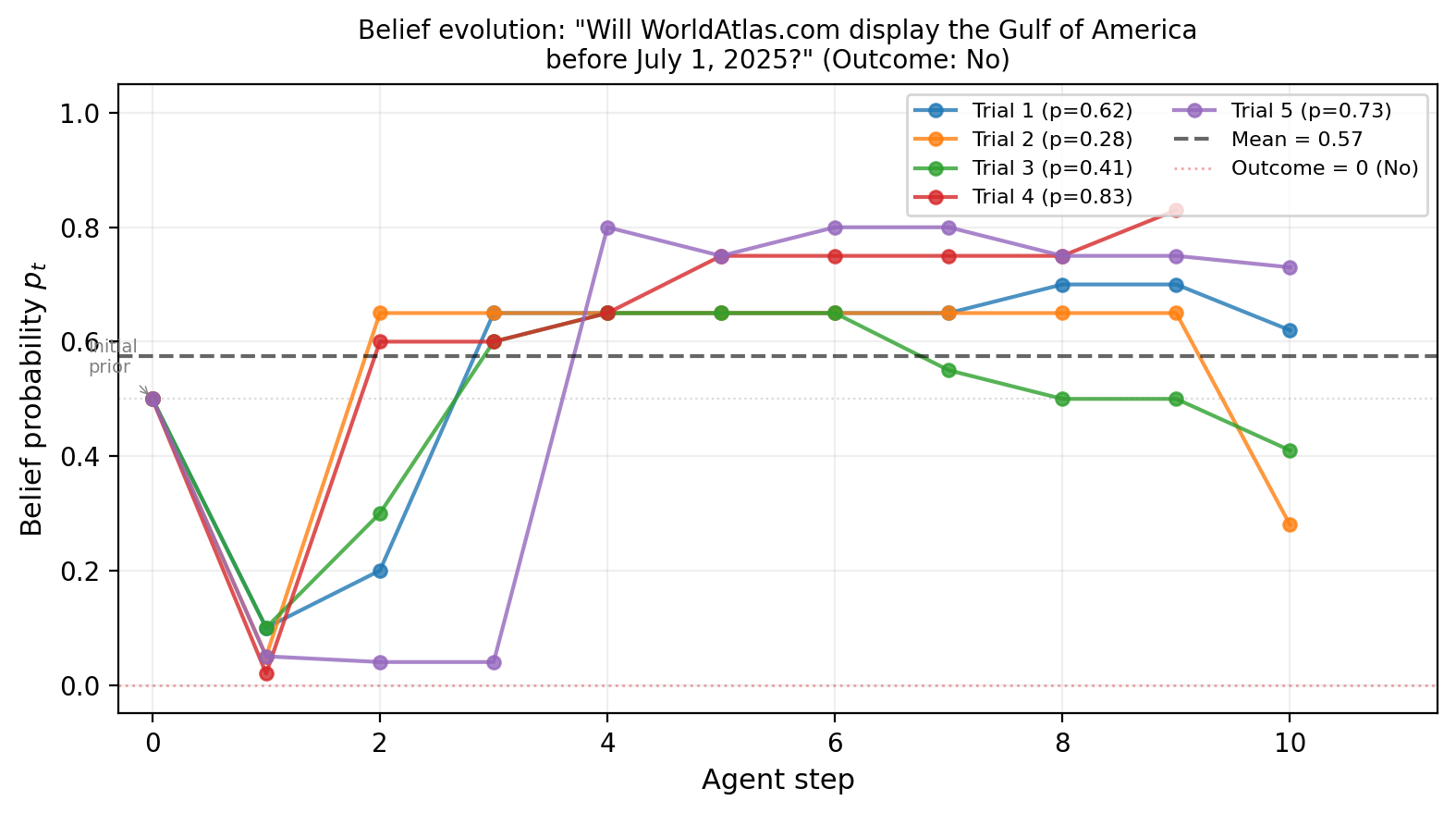
A concrete example: For a question about whether a website would switch “Gulf of Mexico” to “Gulf of America” before a date, one trial discovered the site uses static images (slow to update), which pushed the probability down. Other trials missed that. This shows why multiple independent tries and combining them is useful.
Why Does This Matter?
- Better forecasting can help in many areas: public health, elections, markets, weather, and policy planning. Knowing not just an answer but a well-calibrated probability helps people make smarter decisions.
- The “belief notebook” idea shows that tidy, focused reasoning beats just dumping more text into the model’s context. This could improve many AI agents, not just forecasters.
- Their careful “no time travel” testing helps the community trust reported results and adopt stronger evaluation practices.
Takeaway and Future Directions
- Takeaway: An agent that searches step-by-step, keeps a clean belief record, combines multiple runs wisely, and calibrates its confidence can beat strong baselines and top methods on a tough forecasting benchmark.
- Possible next steps:
- Go beyond yes/no to multiple-choice and predicting exact numbers.
- Add better, domain-specific tools (for finance, climate, etc.).
- Learn how much to trust the crowd signal based on market quality (like trade volume).
- Improve the base model with training (reinforcement learning) and test live on ongoing benchmarks.
In short, BLF shows that careful, structured thinking plus good statistics can make AI forecasters more accurate and trustworthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps, uncertainties, and unresolved questions that future researchers could address:
- Live validity vs backtesting: The system is only validated via backtesting on two tranches (A, B); no prospective/live evaluation shows whether backtested rankings correlate with live ForecastBench performance. Design a preregistered live study measuring rank correlations, stability over time, and robustness to evolving news cycles.
- Leakage defense residual risk: The four-layer leakage defense still shows 1.5% residual leakage without quantifying its impact on scores. Run sensitivity analyses by (i) removing all flagged-at-risk items, (ii) re-running with stricter/looser filters, and (iii) estimating upper/lower bounds on BI changes attributable to leakage.
- Search engine dependence: Results rely on Brave search; effects of engine choice (Google/Bing/Perplexity/API constraints) on retrieval quality and BI are unreported. Benchmark retrieval recall/precision, leakage incidence, and forecasting accuracy across engines.
- Prompt injection and adversarial content: The system does not report defenses against prompt injection or adversarial pages found via search. Evaluate robustness to red-teamed pages and implement/measure sandboxing, content sanitization, and provenance checks.
- Evidence reliability modeling: The belief state records textual evidence but lacks a principled model of source credibility or fact verifiability. Add trust-weighted evidence aggregation (e.g., learned or rule-based source priors) and quantify improvements in calibration and Brier components.
- Faithfulness to Bayesian updating: The “approximate sequential Bayesian inference” claim is descriptive; there is no test of Bayes-consistency of updates. Measure whether step-to-step updates approximate likelihood-ratio accumulation on controlled synthetic tasks with known likelihoods, and develop prompts/constraints that enforce Bayes-like consistency.
- Hallucination and evidence quality audits: No audit quantifies hallucination rates, unsupported claims, or citation correctness within belief states. Introduce external fact-checking (LLM or retrieval-based), report error taxonomy, and measure impact on forecasts when filtering low-verifiability evidence.
- Utility of “open questions” field: The belief state tracks open questions, but there is no causal test that these shape tool choices or improve accuracy. A/B test policies that (i) force actions tied to open questions vs (ii) ignore them, measuring action diversity and BI.
- Tool policy learning: The meta-controller is rule-based and static. Explore bandit/RL policies that learn tool availability, step budgets, and termination criteria per question type and horizon, reporting cost–accuracy trade-offs.
- Cost, latency, and scalability: Running K=5 trials with up to T=10 steps per trial has unknown token, time, and dollar costs. Report per-question cost breakdowns, latency distributions, and marginal BI gains vs tokens to enable budget-aware deployment and adaptive stopping.
- Inter-trial dependence: Multi-trial aggregation assumes helpful variance but does not quantify correlation among trials (same model/prompt). Measure correlation structures, test variance-reduction techniques (antithetic sampling, diverse temperatures/seeds), and compare to diversity via distinct base models.
- Optimal trial allocation: K is fixed at 5; no adaptive allocation based on observed inter-trial variance or question difficulty. Develop on-the-fly stopping rules and budget allocation policies that maximize BI per token.
- Aggregation diversity: Only logit-mean averaging (with LOO shrinkage) is explored; no comparison to stacking/meta-learners, Bayesian model averaging with between-trial variance, or mixture-of-experts using belief-state features.
- Calibration scope and structure: Hierarchical Platt uses per-source intercepts; slope heterogeneity, horizon-specific effects, temporal drift, and per-market regime shifts are not modeled. Evaluate richer hierarchical calibration (per-source slope, horizon terms, time-varying priors) and out-of-time validation.
- Calibrate-before vs after aggregation: Only post-aggregation calibration is reported. Compare calibrating each trial first, then aggregating, vs the current order; also compare Platt to isotonic regression and Bayesian calibration on disjoint time splits.
- Crowd prior integration: The crowd is “anchored” via prompting, not combined via a principled Bayesian fusion or learned weighting. Develop a model that learns crowd weights from market metadata (liquidity, spread, trade count, recency) and stress-test when crowd is stale/manipulated.
- When does the crowd hurt/help?: The paper reports average gains from crowd priors but no subgroup analysis of failure modes. Identify market categories (e.g., thin liquidity, political vs science vs sports) where crowd anchoring degrades performance and devise detection/mitigation rules.
- Time-series (dataset) modeling: Dataset questions rely on search and simple tools; there is no explicit forecasting model (e.g., ARIMA/state space/Prophet/neural TS). Integrate classical/neural TS baselines, quantify additive gains over BLF, and analyze horizon-dependent errors.
- Base model generalization: Most results rely on Gemini-3.1-Pro; limited comparisons (Flash, Kimi) suggest sensitivity. Systematically evaluate across multiple frontier and open-source models with the same harness, controlling for token limits, inference settings, and knowledge cutoffs.
- Knowledge cutoff integrity: Although tranches post-date model cutoffs, post-cutoff supervised/RL updates of base LLMs could encode relevant facts. Validate with strictly open models with verified training cutoffs, or use “simulated ignorance” stress tests to detect latent contamination.
- Misinformation robustness: No analysis on questions where high-quality sources conflict or misinformation is prevalent. Curate a stress set of contested topics, add source-consistency checks, and measure degradation vs neutral topics.
- Per-question failure analysis: The paper mentions per-source tables in the appendix but not a systematic taxonomy of errors. Release labeled error sets (misread resolution criteria, spurious evidence, over/under-confidence, wrong base rates) and target interventions per category.
- Resolution criteria parsing: Many market questions hinge on platform-specific resolution rules; no tool explicitly models these. Add rule parsers/checkers per platform (Polymarket, Manifold, Metaculus) and evaluate gains on “ambiguous wording” subsets.
- Reproducibility and randomness: Variance across repeated full runs (with the same seeds) and reproducibility across API versions are not reported. Publish seeds, decoding params, and harness code; quantify between-run BI variance to bound uncertainty in reported deltas.
- Metric–utility gap: The study centers BI; economic utility (ROI, Kelly growth) and decision-centric metrics are not evaluated. Run simulated and small-scale real-money trading to test whether BI gains translate into improved utility.
- Extension beyond binary outcomes: Categorical and continuous forecasts are listed as future work without a design. Specify belief-state schemas (e.g., categorical logits, discretized CDFs), calibration methods (multinomial Platt, CRPS), and evaluation protocols.
- Interaction between empirical priors and calibration: For dataset questions, empirical priors can hurt zero-shot baselines and are mitigated by hierarchical calibration; the joint behavior under domain shift is unquantified. Test stability across new sources/subtypes and shift-robust calibration.
- Effect of leak classifier false positives: The LLM-based leak filter could remove legitimate pre-cutoff content; no recall trade-off analysis is provided. Quantify precision–recall of the leak filter and its downstream impact on retrieval coverage and BI.
- Partial overlap with external methods: Some comparators appear only in one tranche (Grok, Foresight), weakening pairwise conclusions. Expand paired comparisons across more dates or apply hierarchical meta-analysis that accounts for missingness.
- Token/context management: The belief-state approach is said to avoid context bloat, but token usage and context windows are not measured vs text-accumulation baselines. Report context lengths over steps, truncation frequency, and their relation to accuracy.
Practical Applications
Overview
The paper introduces BLF (Bayesian Linguistic Forecaster), an agentic system for binary forecasting that combines a structured “linguistic belief state,” multi-trial aggregation in logit space (with optional shrinkage), and hierarchical Platt calibration. It also provides a robust backtesting pipeline with multi-layer leakage defenses and rigorous statistical comparisons. Below are practical applications that leverage these findings, methods, and innovations.
Immediate Applications
The following use cases can be deployed with current capabilities, using the paper’s workflow patterns (belief-state JSON, sequential tool-use, multi-trial logit aggregation, hierarchical calibration) and backtesting practices.
- Finance and Risk Management
- Use case: Event-risk dashboards for trading desks and risk teams (e.g., probabilities for policy changes, earnings surprises, regulatory actions, geopolitical shifts).
- Product/workflow: “Forecast Copilot” that runs K independent LLM trials, aggregates in logit space, and applies hierarchical calibration; integrates market priors when available and logs a belief-state JSON trace with evidence.
- Dependencies/assumptions: Access to high-quality, date-filtered search; availability of historical outcomes for calibration; compute budget for multi-trial runs (e.g., K=5); adherence to compliance constraints for web/data access.
- Prediction Markets and Research Platforms
- Use case: Enhanced question resolution support and research notes—automatically generate calibrated probability updates with transparent evidence summaries for market questions (Polymarket, Manifold, Metaculus).
- Product/workflow: Plug-in that anchors to crowd priors, iteratively updates belief states with search and domain tools, and publishes a structured audit trail to question pages.
- Dependencies/assumptions: API access to market prices and metadata; strict temporal leakage controls; moderation policies for publishing model outputs.
- Policy and Geopolitics
- Use case: Early-warning briefs (e.g., election outcomes, sanctions, legislation passage, conflict escalation) with auditable evidence trails.
- Product/workflow: Weekly “Forecast Briefing” pipeline for policy teams that aggregates multi-trial forecasts, shows per-source calibration, and includes pros/cons evidence from vetted sources.
- Dependencies/assumptions: Curated source lists and date clamping to avoid leakage; sensitivity review to avoid self-fulfilling or politically sensitive impacts; governance procedures for human oversight.
- Public Health Surveillance
- Use case: Probability estimates for near-term events (e.g., outbreak detection in specific regions, vaccine policy adoption, hospital capacity stress).
- Product/workflow: Belief-state updates incorporating official bulletins and vetted datasets; per-source hierarchical calibration to avoid over-shrinking extremes when base rates are skewed.
- Dependencies/assumptions: Reliable data connectors (e.g., to CDC/WHO/Ministries of Health); rapid content updating; institutional review for public health communications.
- Supply Chain and Operations
- Use case: Disruption risk predictions (port closures, strikes, severe weather impacts) driving risk registers and trigger-based mitigation.
- Product/workflow: Sequential agent loop with domain-specific tools (e.g., shipping news feeds, weather data) and structured belief states attached to “risk items” in enterprise planning tools.
- Dependencies/assumptions: API access to domain data; well-scoped tool policies; human-in-the-loop review for high-impact actions.
- Energy and Utilities
- Use case: Event-focused complements to numerical forecasting (e.g., probability of policy shifts impacting tariffs, infrastructure outages, or major supply changes).
- Product/workflow: Hybrid pipeline—LLM agent synthesizes event evidence, while numerical models handle pure time series; final probabilities calibrated with hierarchical Platt scaling per data source.
- Dependencies/assumptions: Clear division of labor between statistical models and the BLF agent; reliable historical labels for calibration.
- Cybersecurity
- Use case: Forecast probability that a high-severity CVE will be actively exploited within 30/90 days; likelihood of regulatory breach incidents.
- Product/workflow: Aggregated multi-trial forecasts that pull from CVE/NVD feeds and trusted threat intel; per-source calibration to adjust for skewed exploitation base rates.
- Dependencies/assumptions: High-precision source filtering; minimizing leakage from post-cutoff incident reports; continuous ground-truthing.
- Media and Fact-checking
- Use case: “Probability boxes” accompanying major stories (e.g., odds of a policy passing) with transparent rationale and source links.
- Product/workflow: Editorial tool that produces a belief-state JSON with evidence for/against and confidence, including an audit trace for ombud review.
- Dependencies/assumptions: Editorial standards for probability communication; careful handling of post-cutoff leakage and retractions.
- Education and Training
- Use case: Teaching Bayesian updating and calibration with stepwise belief-state traces; training analysts in evidence-based forecasting.
- Product/workflow: Classroom modules that replay belief evolution across trials and compare pre/post calibration; exercises on leakage-aware backtesting.
- Dependencies/assumptions: Access to resolved question sets; student-safe data connectors.
- Software and AI Agent Engineering
- Use case: Retrofitting existing tool-using agents with a “linguistic belief state” to curb context bloat and improve decision quality.
- Product/workflow: Drop-in components—(1) belief-state JSON schema and update prompts, (2) logit-space multi-trial aggregator, (3) hierarchical Platt calibrator service, (4) four-layer leak defense for evaluation.
- Dependencies/assumptions: Prompt/agent orchestration support; compute budget for K trials; availability of in-domain resolved data for calibration.
- Research Methods and Evaluation
- Use case: Robust backtesting for temporal tasks in academia and industry (economics, epidemiology, security), with leakage defense and paired bootstrap analyses.
- Product/workflow: Reproducible evaluation harness adopting the paper’s four-layer leakage defense, paired analysis controlling for question difficulty, and confidence intervals for ablations.
- Dependencies/assumptions: Clear timestamped datasets; adoption of standardized leakage rules; statistical expertise.
- Personal Decision Support
- Use case: Calibrated probabilities for travel disruptions, event cancellations, or price changes, with short textual evidence summaries.
- Product/workflow: Lightweight “Forecast Journal” app that runs a small K (e.g., 3–5) trial aggregation and presents a concise belief state.
- Dependencies/assumptions: Cost control for API usage; availability of consumer-grade, reliable sources; UX for uncertainty communication.
Long-Term Applications
These applications require further research, scaling, or development beyond the current paper (e.g., better tools, live deployment validation, or expanded modeling).
- Multi-outcome and Continuous Forecasting at Scale
- Use case: Forecast distributions over multiple outcomes (e.g., slate of candidates) or continuous variables (e.g., demand curves).
- Product/workflow: “Distribution Forecaster” that outputs discretized CDFs and categorical probabilities; integrates belief-state evidence per bin/category.
- Dependencies/assumptions: New training/evaluation pipelines for continuous targets; reliable binning strategies; sufficient resolved data for calibration.
- Liquidity-aware, Market-integrated Forecasting
- Use case: Dynamic weighting of crowd priors using market metadata (trades, volume, liquidity) to improve robustness.
- Product/workflow: A market-aware prior module that conditions on liquidity and recency; potentially feeds trading risk systems.
- Dependencies/assumptions: Access to market microstructure data; governance to avoid market manipulation; compliance with financial regulations.
- Domain-specialized Forecasters via RL/Continual Learning
- Use case: Fine-tuned BLF variants for finance, epidemiology, energy, or security with domain-specific tools and rewards (proper scoring rules).
- Product/workflow: RL-optimized agent that learns tool policies and calibration hyperparameters; online continual learning for the meta-controller.
- Dependencies/assumptions: Large, high-quality resolved datasets; safeguards against overfitting/backtesting leakage; compute and MLOps maturity.
- Advanced Time-series Tooling and Model Fusion
- Use case: Seamless fusion of numerical models (ARIMA/Prophet/ML) with agentic evidence synthesis for mixed quantitative–qualitative forecasts.
- Product/workflow: Toolchain that can justify numeric predictions with textual evidence in the belief state; routing policies to decide when to search vs. model.
- Dependencies/assumptions: Standard interfaces between TS models and belief-state updates; method for reconciling conflicting signals.
- Human–AI Hybrid Forecasting Platforms
- Use case: Teams of human analysts and BLF agents co-produce forecasts, with the agent providing calibrated baselines and explainable evidence.
- Product/workflow: Collaboration layer that supports human edits, comments, and acceptance testing of belief-state updates; tracks human–AI deltas and calibration.
- Dependencies/assumptions: UX and process design for trust and accountability; incentives for experts; organizational adoption.
- Institutional Governance and Standards for Temporal Evaluation
- Use case: Sector-wide adoption of leakage-aware backtesting and calibration standards for AI forecasting systems.
- Product/workflow: Guidance and compliance checklists (akin to NIST-style profiles) that include date clamping, leak detection, and paired evaluation.
- Dependencies/assumptions: Cross-institutional consensus; regulator engagement; auditing infrastructure.
- Causal/Structured Reasoning Extensions
- Use case: Integrate verbalized probabilistic graphical models (vPGMs) or causal schemas with the belief state to reduce spurious evidence aggregation.
- Product/workflow: Hybrid agents that induce latent-variable structures for complex questions and update posteriors via Bayesian computation.
- Dependencies/assumptions: Research into robust, scalable vPGM induction; evaluation datasets with causal ground truth.
- Real-time Decision Automation
- Use case: Threshold-triggered actions (e.g., hedges, inventory shifts, safety posture changes) driven by calibrated probabilities with documented evidence.
- Product/workflow: Policy engine that consumes calibrated forecasts and executes pre-approved playbooks; integrates audit trails from belief states.
- Dependencies/assumptions: Strong governance and override mechanisms; clear risk thresholds; reliability validations in live settings.
- Enterprise-wide Calibration Services for LLM Agents
- Use case: Calibrate probability-like outputs across many agents (search QA, safety triage, incident response).
- Product/workflow: Central “calibration service” offering hierarchical Platt scaling with per-source offsets and LOO cross-validation; standardized telemetry ingestion.
- Dependencies/assumptions: Continuous feedback loops with labeled outcomes; consistent telemetry schemas; privacy/security controls.
- Privacy-preserving and Cost-efficient Deployments
- Use case: On-prem or small-model variants for sensitive domains (healthcare, defense) balancing cost with performance (e.g., reduced K with informed shrinkage).
- Product/workflow: Distilled or domain-adapted models using the BLF harness; selective trial counts and shrinkage parameters based on variance profiles.
- Dependencies/assumptions: Adequate local compute; curated internal datasets; acceptance of performance–cost trade-offs.
- Knowledge-graph and Event-stream Integration
- Use case: Stronger retrieval and evidence linking by grounding belief states in entities and events with temporal attributes.
- Product/workflow: Event-driven agent that updates beliefs as new entries arrive, with leakage safeguards and temporal indexing.
- Dependencies/assumptions: High-quality, timestamped knowledge graphs; event standardization; streaming infrastructure.
Notes on Feasibility and Dependencies
- Multi-trial aggregation improves accuracy but increases cost; organizations may tune K based on observed trial variance and adopt shrinkage when variance is high.
- Hierarchical calibration assumes sufficient historical outcomes per source; cold-start sources may need shared priors or transfer from similar sources.
- Leakage defenses can reduce recall in search; precision–recall trade-offs must be managed, especially in backtesting vs. live use.
- Crowd priors are powerful for market questions but may encode biases; introducing liquidity/volume metadata (future work) can mitigate this.
- Belief-state transparency aids auditability but requires governance for sensitive topics; ensure clear human-in-the-loop checkpoints.
- Live performance may differ from backtested results due to distribution shift and changing information environments; staged rollouts and monitoring are recommended.
Glossary
- Adjusted Brier Index (ABI): A difficulty-adjusted version of the Brier Index obtained by transforming the adjusted Brier score; higher is better. "Adjusted Brier Index: $\text{ABI} = 100 \times (1 - \sqrt{\text{ABS})$."
- Adjusted Brier Score (ABS): A difficulty-adjusted Brier score that subtracts an estimate of question difficulty from the raw Brier score. "Adjusted Brier Score: is the difficulty adjusted Brier score for question~"
- Agentic system: An AI system that plans and acts over multiple steps (often with tools), rather than answering in one shot. "We present BLF (Bayesian Linguistic Forecaster), an agentic system for binary forecasting that achieves state-of-the-art performance on the ForecastBench benchmark."
- Approximate sequential Bayesian inference: Iteratively updating beliefs using Bayes-inspired reasoning as new evidence arrives, without an exact probabilistic model. "This can be viewed as approximate sequential Bayesian inference."
- Back-testing: Evaluating a forecasting method on past (resolved) questions to estimate performance while guarding against information leakage. "a robust back-testing framework with a leakage rate below 1.5\%"
- Bayesian Linguistic Forecaster (BLF): The proposed forecasting agent that maintains a linguistic belief state, aggregates multiple trials, and applies hierarchical calibration. "We present the Bayesian Linguistic Forecaster (BLF), an agentic system for binary question forecasting."
- Binarized: Converted from continuous or multi-class outcomes to binary (yes/no) form. "and (binarized) time series forecasting problems"
- Bootstrap confidence intervals: Uncertainty intervals computed via resampling the data, often used for paired comparisons. "paired analysis with bootstrap confidence intervals"
- Brier Index: A monotone transform of mean Brier score that maps performance to a 0–100 scale (higher is better). "In the main text, our primary metric is the Brier Index, proposed in ~\citep{BrierIndex}."
- Brier score: A proper scoring rule equal to squared error for probabilistic forecasts of binary outcomes. "showing that retrieval-augmented GPT-4 approaches the human crowd's Brier score."
- CDF (cumulative distribution function): A function giving the probability that a variable is less than or equal to a value; used for continuous-outcome forecasting. "cdf, as used in the Metaculus competition:"
- Clairvoyant mode: An oracle-like evaluation condition that allows access to future information by setting the cutoff date to the present. "(clairvoyant mode, that sets the cutoff date to today)"
- Crowd estimate: The aggregate market or community prediction used as a strong prior/anchor for market questions. "All methods use the crowd estimate as a strong prior (this is only available for market questions)."
- Data-dependent prior: A prior distribution whose parameters are informed by observed data, often used for shrinkage. "logit-space shrinkage with a data-dependent prior."
- Date clamping: Enforcing time filters on tools and data access so that no information beyond the forecast cutoff leaks into the model. "(3)~data tool date clamping,"
- Empirical Bayes: A Bayesian approach where prior hyperparameters are estimated from data rather than fixed a priori. "inspired by James-Stein / empirical Bayes"
- Empirical prior: A baseline probability computed from historical base rates for a source or question subtype. "For dataset questions, we provide an empirical prior --- the base rate for each source and question subtype."
- Expected Calibration Error (ECE): A scalar summary of how well predicted probabilities align with observed frequencies. "See Figure~\ref{fig:calibration} for a calibration (reliability) diagram and ECE plot."
- Forecast horizon: The time interval between the forecast date and the resolution date for which a prediction is made. "at multiple forecast horizons "
- GRPO: A reinforcement learning algorithm (Group/Generalized Relative Policy Optimization) used to train models with specific rewards. "uses GRPO with a composite accuracy+Brier reward"
- Hierarchical calibration: Calibrating predictions with models that include group/source-level parameters to avoid over-shrinking extremes. "Hierarchical calibration: Platt scaling with a hierarchical prior,"
- Hierarchical Platt scaling: Platt scaling extended with hierarchical (e.g., per-source) parameters to better handle varying base rates. "We use hierarchical Platt scaling with per-source intercept offsets"
- Hierarchical prior: A prior with parameters drawn from higher-level distributions, enabling partial pooling across groups. "Platt scaling with a hierarchical prior,"
- Intercept offsets: Per-group bias terms in a logistic calibration model to account for systematic differences between sources. "per-source intercept offsets"
- James–Stein: A shrinkage principle/estimator that pulls estimates toward a central value to reduce variance. "inspired by James-Stein / empirical Bayes"
- Jensen's inequality: A convexity result implying that averaging predictions can improve certain metrics. "Averaging provably improves all metrics due to Jensen's inequality"
- Knowledge cutoff: The latest date of training or allowed information; used to prevent contamination in backtests. "after the knowledge cutoff of current frontier LLMs;"
- Leave-One-Out cross-validation: A cross-validation scheme that tunes parameters by iteratively holding out each data point. "estimated by Leave-One-Out cross-validation"
- Leak classifier: A filter (often LLM-based) designed to detect and block post-cutoff information in retrieved content. "LLM-based leak classifier on results,"
- Logit-space averaging: Aggregating probabilities by averaging their logits (inverse sigmoid) to mitigate overconfidence. "aggregate by averaging in logit space."
- Metaculus Baseline Score (MBS): A logarithmic proper scoring rule used by Metaculus for probabilistic forecasts. "Metaculus Baseline Score (MBS): where"
- Meta-controller: A higher-level policy that selects which tools an agent can use based on the question type. "A meta-controller selects the set of tools available to the agent on a per-question-type basis."
- Multi-trial aggregation: Running several independent forecasting trials and combining their outputs to reduce variance. "Multi-trial aggregation."
- Non-Markovian: Depending on the entire history rather than only the current state, as in a belief state that summarizes past evidence. "maintains a non-Markovian natural-language belief state updated sequentially from tool-call evidence"
- Paired bootstrap tests: Bootstrap hypothesis tests that compare methods on the same set of questions to control for difficulty. "We use paired bootstrap tests which control for question difficulty"
- Platt scaling: A logistic regression-based calibration method mapping scores/probabilities to calibrated outputs. "Platt scaling~\citep{platt1999}."
- Proper scoring rules: Scoring functions that incentivize honest probability reporting by being maximized at the true distribution. "MBS and (A)BS metrics are proper scoring rules, which reward well-calibrated forecasts"
- Reliability diagram: A plot comparing predicted probabilities to empirical frequencies to visualize calibration. "calibration (reliability) diagram and ECE plot."
- Shrinkage: Pulling estimates toward a central value (e.g., 0.5) to reduce variance and overconfidence. "LOO-tuned shrinkage toward further helps"
- Stratified sampling: Sampling within predefined strata to preserve source proportions or characteristics. "(20 per source, via stratified sampling with a fixed seed)"
- Univariate (time series): Time series consisting of a single variable, often used in forecasting tasks. "assess the ability to do (univariate) time series forecasting."
- Zero-shot: Producing forecasts without search, tools, or multi-step reasoning—typically from a single prompt. "zero-shot LLM with crowd and empirical prior, but no tools or search"
Collections
Sign up for free to add this paper to one or more collections.