- The paper introduces a trajectory-preserving order to merge autoregressive decoding steps, significantly reducing iterative sampling without losing output fidelity.
- It presents NI Sampling, a neural indicator framework that scores and selects tokens for simultaneous unmasking, optimizing parallel generation in dLLMs.
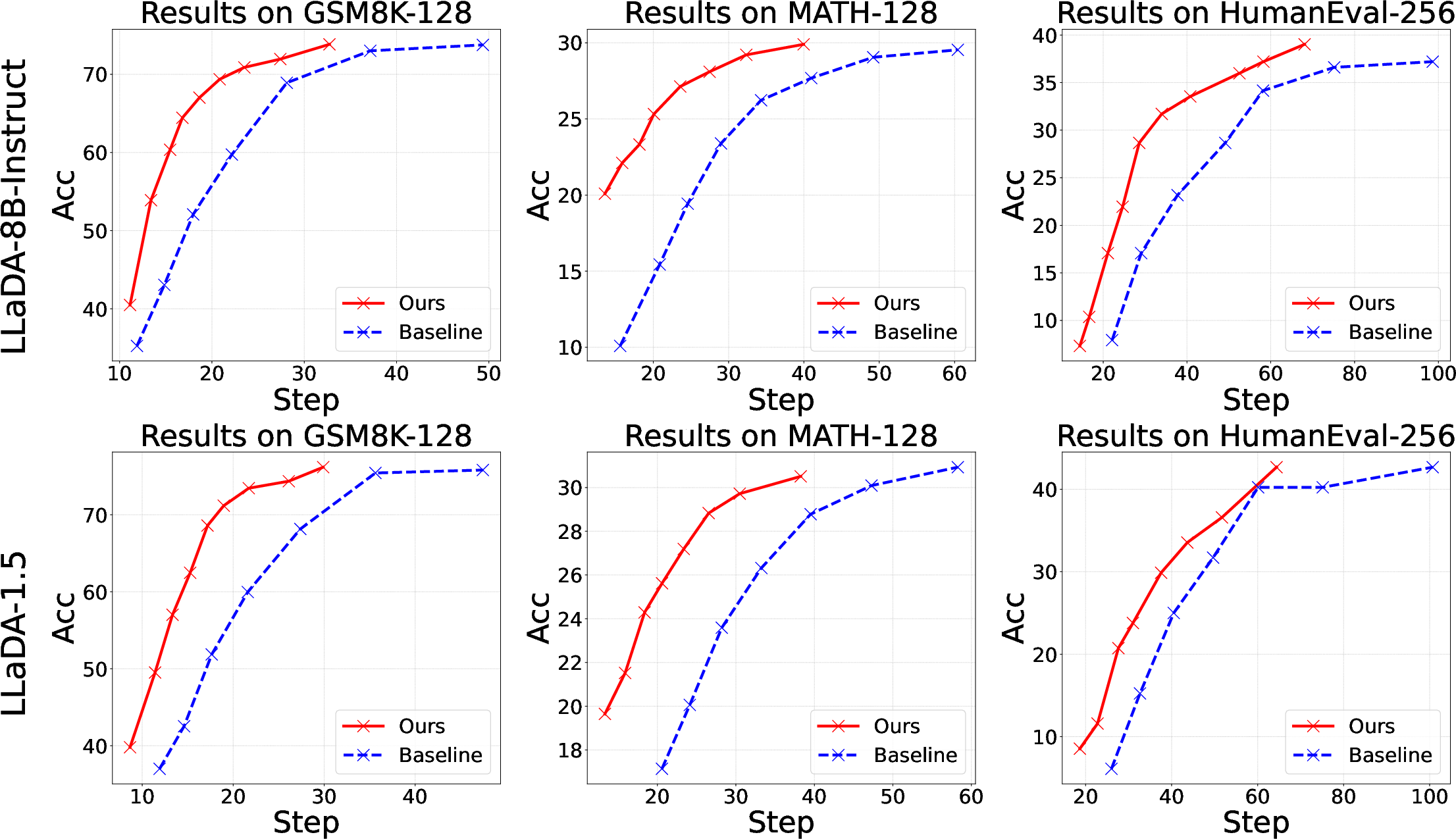
- Empirical results demonstrate up to 14.3× speedup on benchmarks while maintaining accuracy, underscoring its potential for efficient discrete diffusion modeling.
NI Sampling: Token Order Optimization for Accelerated Discrete Diffusion LLM Decoding
Motivation and Problem Setting
Discrete diffusion LLMs (dLLMs) provide an alternative to autoregressive (AR) language modeling, lifting the left-to-right decoding constraint and enabling parallel generation by iteratively denoising from an all-masked state. However, current dLLMs are bottlenecked by inefficient sampling schedules. Existing methods such as “full-step” decoding unmask only a single token per iteration, giving excellent quality but requiring O(N) iterative steps for a sequence of length N. “Confidence threshold” approaches partially address this by unmasking all tokens whose predicted probabilities exceed a set threshold, but fail to fully exploit model capacity in earlier steps—most correct predictions remain masked as their confidence is below threshold.
The core technical question addressed is: How can we optimally schedule token sampling orders in dLLMs to maximize parallelism—i.e., unmask as many correct tokens as possible per iteration—without degrading quality?
Trajectory-Preserving Order and Upper Bound Analysis
The paper reveals that if the model’s correct predictions could be leveraged fully, the number of sampling iterations can be substantially compressed without quality loss. They formalize this observation via a trajectory-preserving order—a schedule merging steps in the autoregressive reference trajectory, so that at each step, all consistently and correctly predicted tokens are revealed while preserving the correct final output.
On standard mathematical and code generation tasks using LLaDA-8B-Instruct and LLaDA-1.5, this strategy yields acceleration ratios up to 24.3× relative to naive full-step decoding, while exactly matching reference accuracy.
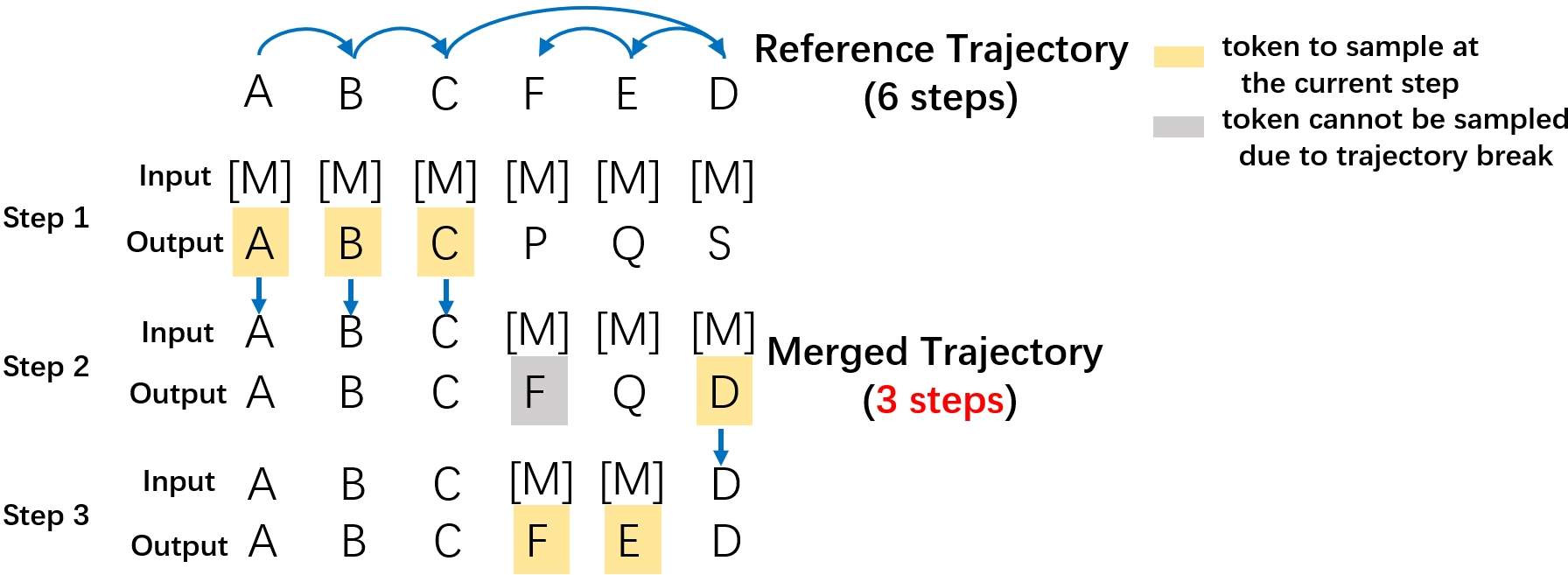
Figure 1: A step-by-step illustration of trajectory-preserving order, enabling maximally parallel and correct token reveals at each step without breaking dependencies.
This demonstrates a large theoretical headroom for sample efficiency improvements—current practices are highly suboptimal both in sample complexity and wall-clock time, even under conservative consistency constraints.
NI Sampling: Neural Indicator for Token Selection
To address the combinatorial selection problem, the authors introduce Neural Indicator (NI) Sampling, a general plug-in framework for token-wise sampling order optimization in dLLMs. At each iteration, a trainable lightweight neural network (the “indicator”) processes context embeddings, token logits, and other features for each masked position, producing a score interpreted as the readiness of that position for sampling.
The sampling pipeline is as follows:
- After each dLLM forward pass, the indicator assigns a score to every remaining masked position.
- All tokens exceeding an adjustable threshold are revealed in parallel.
- The indicator is jointly trained using a trajectory-preserving criterion: training data are produced by merging as many correct steps as possible from a high-quality reference trajectory.
See:
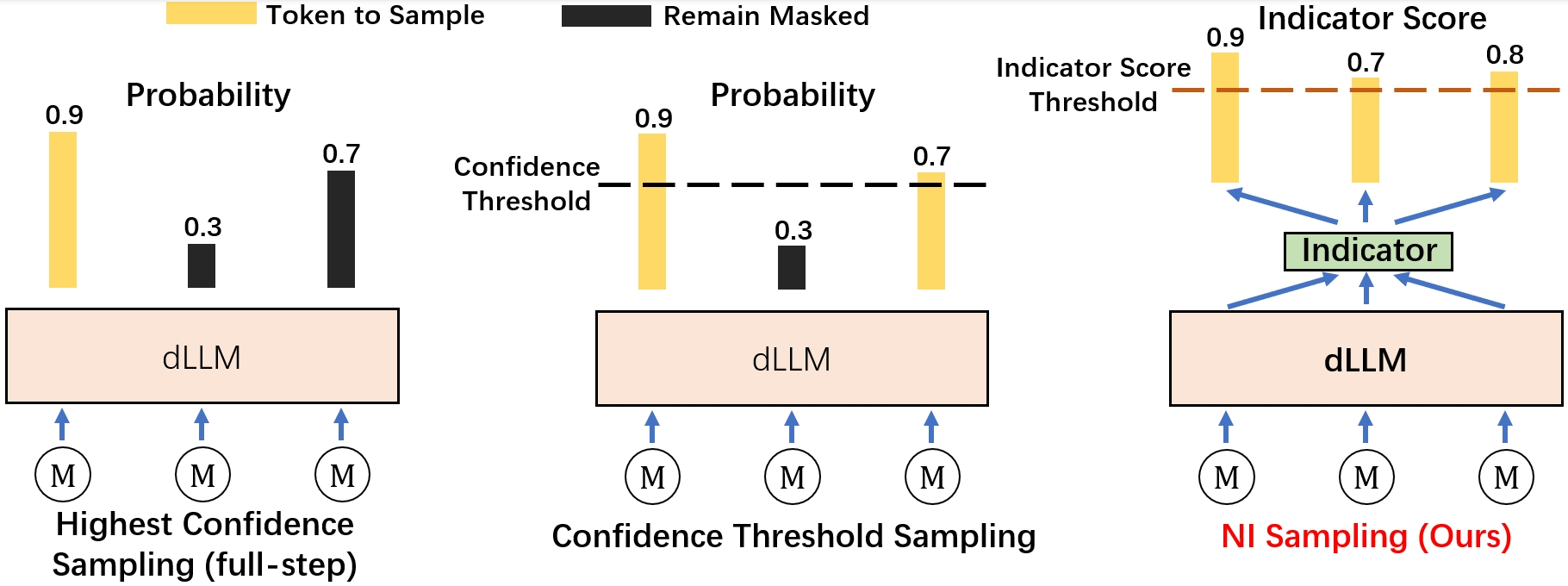
Figure 2: NI Sampling schematic—at each iteration, masked tokens are scored by the neural indicator and those exceeding threshold are sampled, maximizing both correctness and step compression.
The neural indicator is a position-wise MLP that ingests token and context representations; it can be trained on trajectories from any existing sampler, making the method compatible with all dLLM family designs.
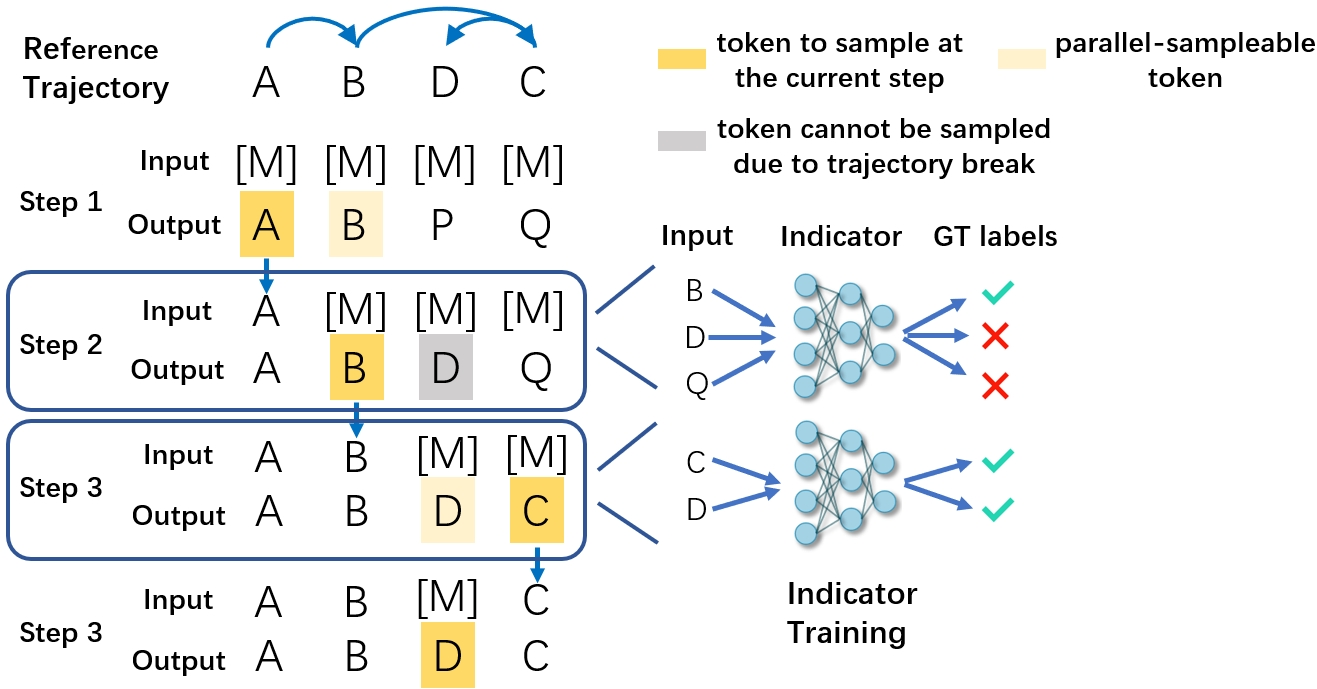
Figure 3: Training data assignment—reference trajectories are relabeled so that tokens eligible for step merges are marked positive and others are negative for indicator supervision.
Empirical Results
Experiments are conducted on LLaDA and Dream dLLM families, evaluated on GSM8K, MATH, HumanEval, and MBPP (code) datasets, at multiple sequence lengths.
Main findings include:
Additionally, NI Sampling is shown to be compatible with further system-level accelerators: integrating dual KV cache techniques yields combined speedups up to 25× over the baseline.
Robustness is further evidenced by transfer to models initialized from AR weights (e.g., Dream-7B-Base), where NI Sampling still improves step efficiency without additional training.
Ablations and Analysis
A series of experiments probe factors controlling NI Sampling performance:
- Training data distribution: Matching the indicator’s training data (e.g., code-only vs. general text) to the target task domain yields measurable accuracy gains, indicating sample distribution targeting is an effective lever.
- Input feature set: Removing logit features or top-k token embeddings from the indicator severely reduces efficacy, confirming the necessity of rich contextual signals for optimal selection.
- Indicator capacity: Increasing MLP size from 84M to 184M parameters gives diminishing returns, implying current bottlenecks arise from training or objective mismatch rather than underparameterization.
- Data scale: Indicator performance is tolerant to substantial reductions (↓75%) in training set size, provided critical supervision is retained.
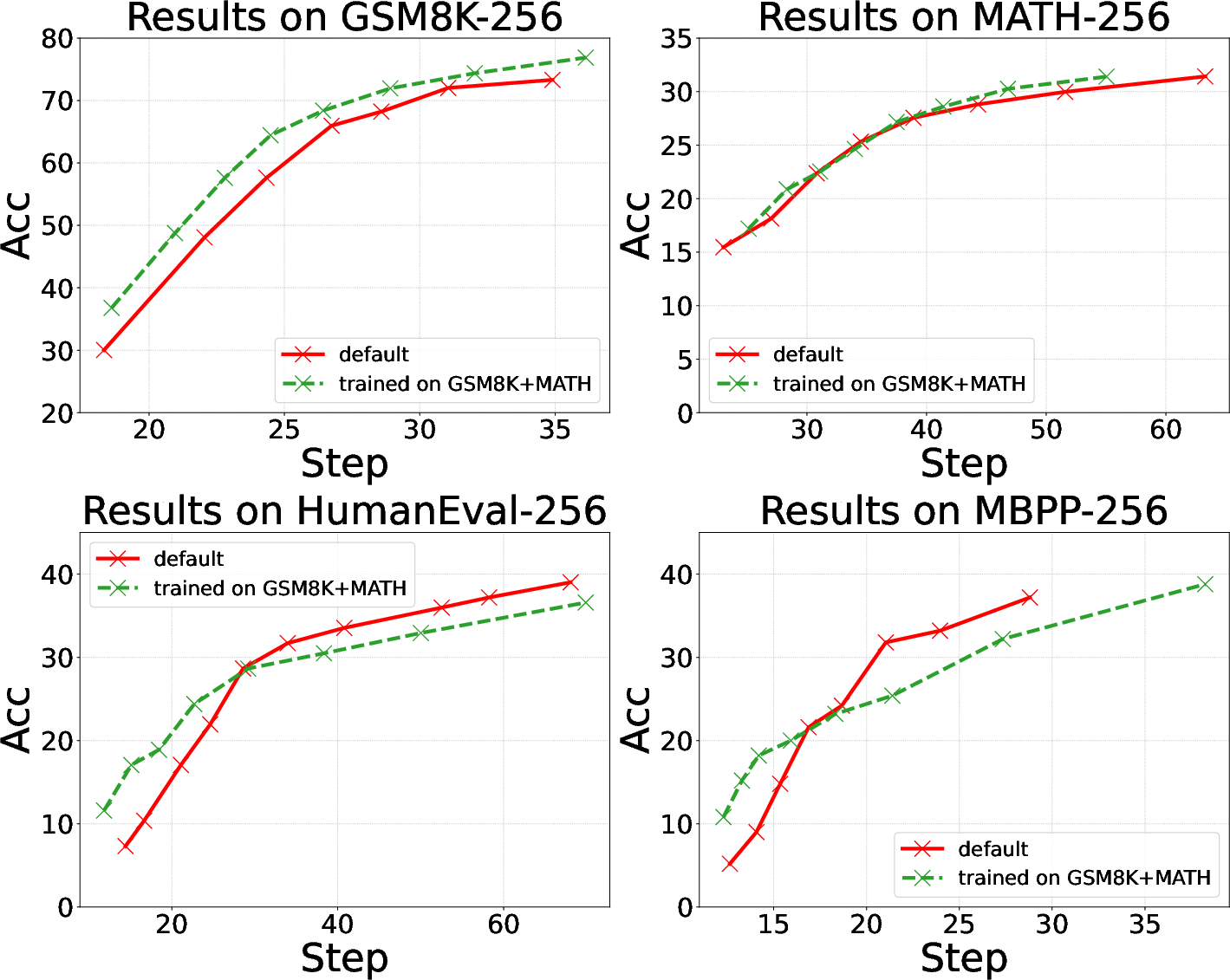
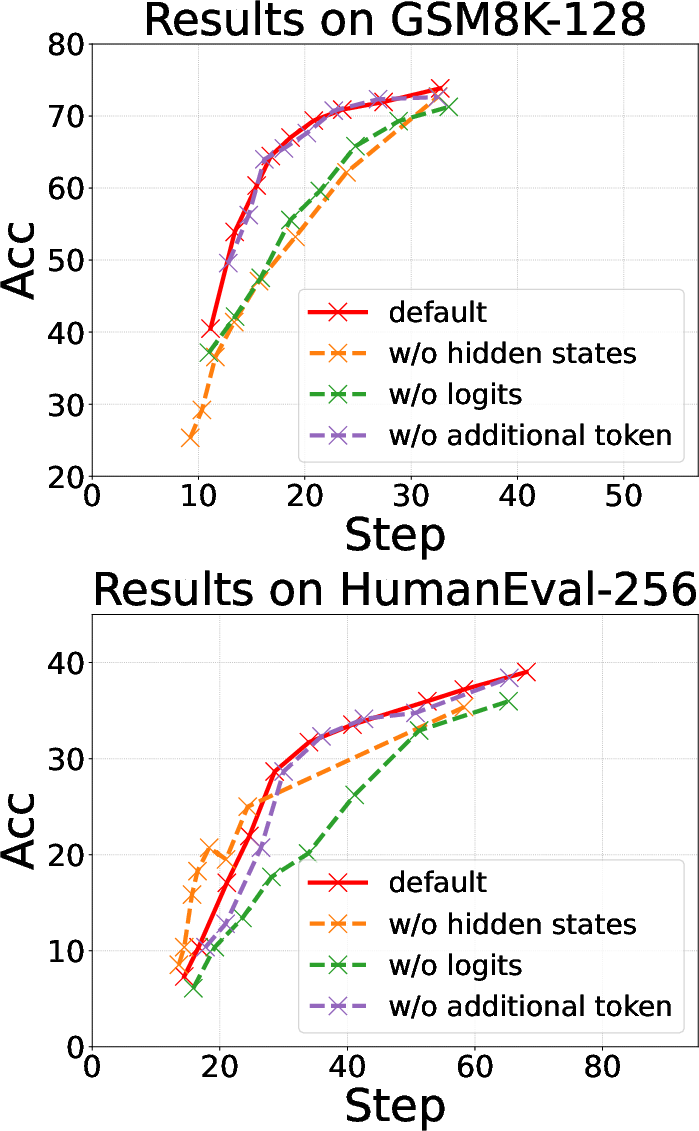
Figure 5: Changing indicator training set distribution reveals that specializing to the target domain further boosts speed/accuracy tradeoff on in-domain tasks.
While several parallelization or acceleration approaches exist for both AR and diffusion-based models—including speculative decoding, block-wise caching, and step distillation—these generally focus on sequence-level schedule optimization, or on model-agnostic, mostly heuristic methods (confidence threshold, entropy, etc.). NI Sampling exploits supervised, data-driven token-level policies grounded in high-quality reference trajectories, outperforming heuristic methods.
Notably, prior works on token-level selection in image MDMs (e.g., Token-Critic) serve different goals (primarily sample quality, not decoding speed) and fail to match NI Sampling on acceleration or accuracy metrics when ported to dLLMs.
Limitations and Future Directions
While the observed speedups are substantial, there remains a consistent gap to the theoretical upper bound set by trajectory-preserving optimal schedules. This is attributed to both indicator limitations (the policy tends toward local AR patterns, possibly due to training bias or model simplicity) and compounding error effects.
Enhancing the indicator via richer sequence modeling (e.g., position-aware transformers rather than position-wise MLPs), RL-based optimization with end rewards (beyond trajectory preservation), and incorporating rollouts to address error accumulation are suggested as next directions.
Conclusion
NI Sampling demonstrates that optimal, learnable, token-level orderings constitute a powerful means to compress dLLM sampling complexity. By leveraging a neural indicator trained with a trajectory-preserving criterion, the method dramatically reduces iterative steps—achieving up to 14.3× wall-clock acceleration—without loss of model fidelity or diversity. The approach is robust across dLLM families and domains, Pareto-dominates existing baselines, and can be composed with other acceleration methods. As diffusion-based text generation matures, such selection policies will be key for practical, deployment-ready dLLMs.