- The paper introduces T2I-CoReBench, a benchmark that systematically evaluates both compositional and reasoning capabilities of text-to-image models using a 12-dimensional taxonomy.
- Experimental results show that while compositional performance is advancing, a substantial performance gap remains in multi-step and abductive reasoning tasks.
- The study highlights a trade-off between explicit intermediate reasoning and compositional accuracy, emphasizing the need for robust, checklist-based evaluation protocols.
Comprehensive Evaluation of Text-to-Image Models: T2I-CoReBench and the Limits of Reasoning
Introduction
The paper "Easier Painting Than Thinking: Can Text-to-Image Models Set the Stage, but Not Direct the Play?" (2509.03516) presents T2I-CoReBench, a benchmark designed to systematically evaluate both compositional and reasoning capabilities of text-to-image (T2I) generative models. The work addresses the lack of comprehensive and complex evaluation protocols in existing benchmarks, particularly in scenarios requiring high compositional density and multi-step reasoning. The authors introduce a 12-dimensional taxonomy, covering explicit scene composition and a broad spectrum of reasoning types, and provide a large-scale, fine-grained evaluation protocol using checklist-based questions and automated MLLM-based assessment.
Benchmark Design: Taxonomy and Complexity
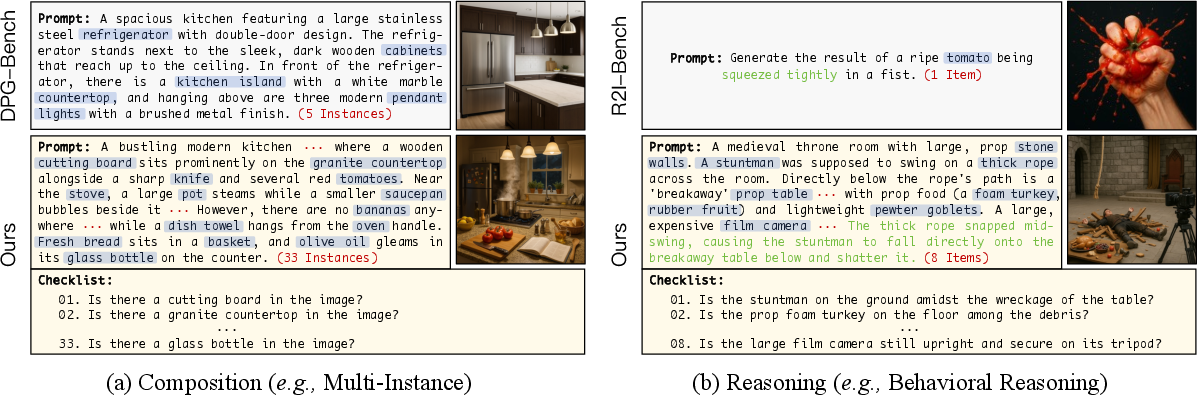
T2I-CoReBench is constructed to address two core limitations in prior benchmarks: insufficient coverage of both composition and reasoning, and inadequate complexity in prompt design. The benchmark is structured around a 12-dimensional taxonomy, split between composition (multi-instance, multi-attribute, multi-relation, text rendering) and reasoning (deductive, inductive, abductive, each with multiple subtypes).
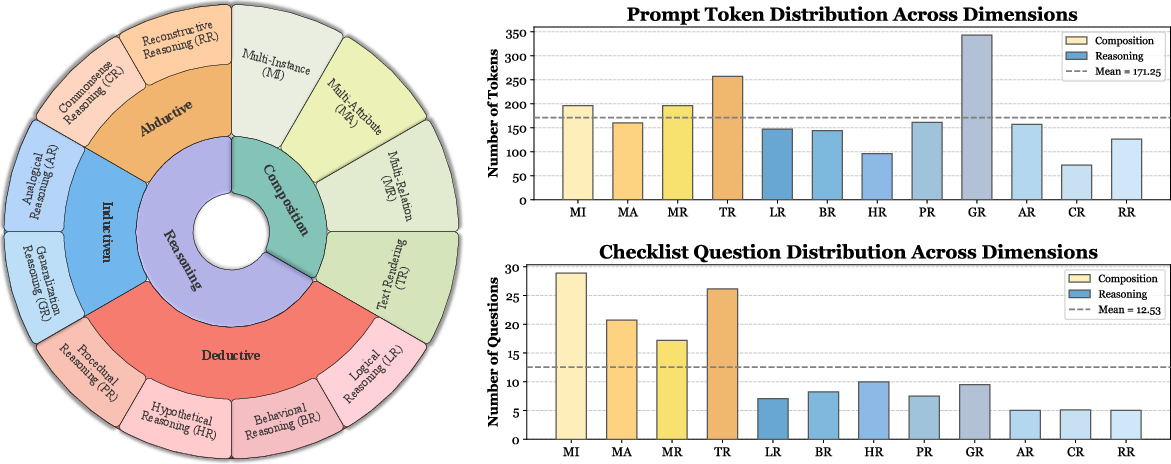
Figure 2: The T2I-CoReBench taxonomy spans composition and reasoning, with high prompt complexity and checklist granularity.
Composition dimensions are grounded in scene graph theory, requiring models to generate images with numerous explicit elements, attributes, and relations, as well as complex text rendering. Reasoning dimensions are based on philosophical frameworks, including deductive (logical, behavioral, hypothetical, procedural), inductive (generalization, analogical), and abductive (commonsense, reconstructive) reasoning. Each prompt is paired with a checklist of atomic yes/no questions, enabling fine-grained, interpretable evaluation.
To ensure complexity, prompts are constructed with high scene density (e.g., ~20 instances per prompt), multi-step inference, and one-to-many or many-to-one causal chains. Data generation leverages multiple SOTA large reasoning models (LRMs) for diversity, followed by rigorous human verification.




Figure 3: T2I-CoReBench provides challenging examples across all 12 dimensions, including dense composition and multi-step reasoning.
Evaluation Protocol and Automation
The evaluation protocol is centered on checklist-based verification, where each generated image is assessed against a set of objective, atomic questions. This approach overcomes the limitations of CLIPScore and direct MLLM-based scoring, which are unreliable for complex, multi-element scenes and implicit reasoning. The authors employ Gemini 2.5 Flash as the primary MLLM evaluator, selected for its strong human alignment and cost efficiency, and validate results with open-source MLLMs for reproducibility.
The protocol enforces strict visual evidence requirements: a "yes" is only assigned if the queried element is unambiguously present in the image, independent of the prompt. This design ensures that evaluation is robust to hallucinations and prompt-image mismatches.
Experimental Results and Analysis
The benchmark is used to evaluate 27 T2I models (21 open-source, 6 closed-source) spanning diffusion, autoregressive, and unified architectures. The results reveal several key findings:
A human alignment study demonstrates that closed-source MLLMs (e.g., Gemini 2.5 Pro, OpenAI o3) outperform open-source models in checklist evaluation, but the best open-source MLLMs (e.g., Qwen2.5-VL-72B) provide reliable, reproducible results.
Implications and Future Directions
The findings have several implications for the development and evaluation of T2I models:
- Benchmarking must address both explicit and implicit generation: Faithful image synthesis requires not only compositional accuracy but also the ability to infer and render implicit, contextually appropriate elements.
- Reasoning remains a critical research frontier: Current architectures, even with LLM/MLLM integration, are insufficient for robust multi-step and abductive reasoning. Progress will require new training data, architectures, and possibly explicit reasoning modules.
- Automated, fine-grained evaluation is essential: Checklist-based protocols, combined with strong MLLM evaluators, provide scalable, interpretable, and reproducible assessment, enabling rapid iteration and fair comparison across models.
- Integration of LLM-style reasoning paradigms: Techniques such as chain-of-thought, self-consistency, and retrieval-augmented generation should be explored within T2I pipelines to improve implicit inference and compositional control.
Conclusion
T2I-CoReBench establishes a new standard for comprehensive, complex evaluation of T2I models, revealing that while compositional capabilities are advancing, reasoning remains a significant bottleneck. The benchmark's design and findings underscore the need for future research on reasoning-aware architectures, richer training data, and advanced evaluation protocols. Addressing these challenges is essential for T2I models to move beyond "setting the stage" to "directing the play" in real-world generative tasks.