- The paper introduces a novel commit-open protocol using Merkle commitments of SAE feature traces to bind model computations pre-query, ensuring detection of substitution attacks.
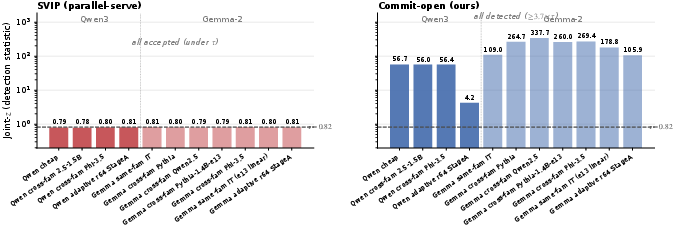
- It experimentally validates detection across various attack classes, demonstrating scale-stable thresholds and significant rejection margins compared to probe-after-return methods.
- The protocol achieves robust statistical binding with minimal overhead while offering integration potential with hardware attestation and adaptive security enhancements.
Sparse Autoencoder Feature Commitments for Hosted LLM Substitution Detection
Introduction and Motivation
The paper "Committed SAE-Feature Traces for Audited-Session Substitution Detection in Hosted LLMs" (2604.18179) addresses the problem of silent substitution by hosted-LM providers, where a weaker and cheaper substitute model is served in place of the advertised stronger LLM, undermining identity and integrity guarantees for API consumers. Previous response-side fingerprinting or probe-after-return protocols, such as SVIP, fail to close the parallel-serve side-channel, allowing providers to answer auditor probes from the correct model while serving end-users from a substitute. Cryptographic proof-of-inference schemes achieve robust guarantees but incur impractical 103–104× computational overhead. This necessitates a scalable, auditable protocol that binds the provider, before any audit probe, to the specific computation carried out.
Protocol Design
The proposed commit-open protocol leverages Merkle-tree commitments to sparse autoencoder (SAE) feature traces of the residual stream at a published probe layer. For each token position, the provider encodes the residual ht using a public SAE encoder E, retaining the top-32 features per position with bf16 quantization. A Merkle root is constructed over leaves containing metadata, position, and the top-k features. The root is published alongside the output tokens (x,y).
Upon audit, the verifier requests Merkle openings at random positions and scores the SAE-trace at each opened position against a public library of 96 named circuit probes spanning 8 circuit classes. The scoring is performed via a fixed-threshold joint-consistency z-score, aggregating per-probe standardised deviations weighted by empirically calibrated per-feature noise statistics.
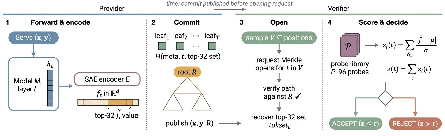
Figure 1: Commit-open protocol mechanics—SAE trace encoding, Merkle leaf construction, commitment publication, probe-based scoring, and threshold decision.
This protocol precludes after-the-fact side-channels, as commitments are made before any verifier query. The only way for a dishonest provider to evade detection is to either perform a full pass of the honest model (paying nearly the honest compute cost) or attempt adaptive distillation under constrained budgets. Feature-forgery, i.e., fabricating SAE traces without running M, is shown structurally infeasible beyond an intrinsic dimension bound set by probe coverage.
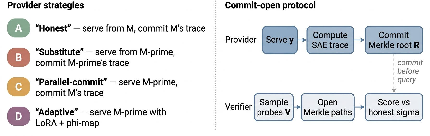
Figure 2: Commit-open verification: provider strategies and binding via Merkle root, closing SVIP’s parallel-serve gap.
Empirical Evaluation
Three backbones are tested: Qwen3-1.7B, Gemma-2-2B, and Gemma-2-9B ($131$k-feature SAE, layer-20). Attackers include lifted (same-family) substitutes, cross-family substitutes (fit via public-corpus alignment), rank-constrained and library-aware LoRA adapters, and white-box variants with gradient access through the frozen SAE encoder.
Detection results:
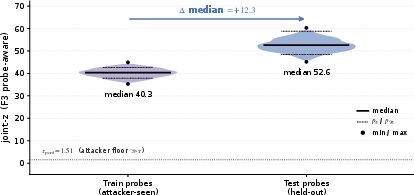
Figure 4: Feature-forgery ladder, showing strong separation against fabrication attacks.
Overhead: Commitment adds 104×7 to forward-only wall-clock at batch size 32, with a per-request payload of 224 bytes. Parallel-commit deception costs at most a single-stack 104×8 the honest compute.
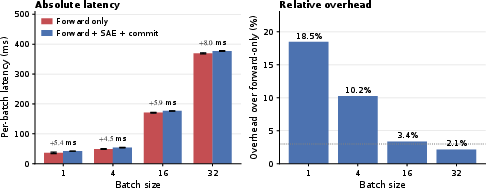
Figure 5: Batched commit overhead: latency collapses from 104×9 at ht0 to ht1 at ht2.
Scalability and Separability
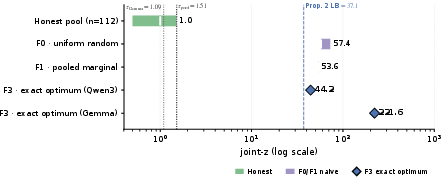
The protocol's threshold and detection margin are empirically shown to be robust across three backbone--SAE pairs (1.7–9B). The honest pool, cross-family, and adaptive LoRA attackers replicate separability margins at 9B parameters, with no evidence of threshold drift:
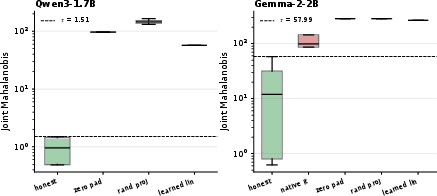
Figure 6: Two-backbone separability, per-probe Mahalanobis diagnostic across Qwen3 and Gemma.
Adaptive attackers incur catastrophic utility loss (Pile perplexity inflation up to ht3); higher utility-preserving attacks, longer training, or full-model retraining remain untested, but the established margins suggest structural robustness.
Structural Limits and Protocol Hardening
Feature-forgery is analytically bounded by intrinsic probe library coverage. Library rotation, mask-flip sensitivity, and secret-probe splits further reinforce detection, with empirical gaps maintained even under adversarial probe selection. The scoring rule is compatible with secret probe rotation, DP noise, and hardware-rooted attestation, enabling protocol hardening without altering the verification primitive.
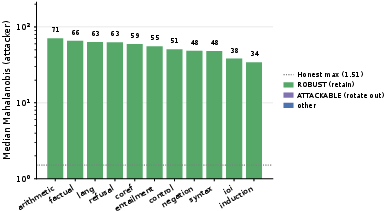
Figure 7: Per-category attackability: library rotation and selection for robust high-assurance regimes.
Practical and Theoretical Implications
This protocol yields the first low-overhead, pre-query binding scheme for hosted-LLM verification, closing the parallel-serve side-channel. It demonstrates that public SAE-feature traces, committed via Merkle trees, provide a statistical identity guarantee robust to practical substitution and adaptive distillation attacks. Empirical separation scales with SAE width, supporting transfer to larger models and varied architectures. Auditability is enhanced for end-users lacking access to on-prem inference.
Theoretical implications include the reduction of substitution detection to intrinsic-dimension covering arguments, and a practical demonstration that mechanistic interpretability artifacts (named circuits in SAE space) can serve as cryptographic payloads in real-time verification.
Hardware-rooted primitives (TDX, H100 confidential computing) and proof-of-inference/ZK protocols (LegoSNARK) are orthogonal deployments, though pairing with attestation could further strengthen guarantees against privileged adversaries.
Future Directions
Future work should address adaptive-frontier expansion, including longer and higher-rank LoRA adaptive attacks, secret-probe-aware variants, and full-model retraining. Integration with hardware attestation, DP probe sketches, and more aggressive probe selection would further mitigate sophisticated threats. Expansion to flagship-class (≥70B) models is needed once suitable SAEs are released. Robust session-level FPR estimation under correlated openings, and dynamic probe library construction/rotation, are recommended.
Conclusion
The commit-open protocol demonstrates statistical binding and robust separation for hosted LLM identity audits, closing the critical parallel-serve gap present in probe-after-return schemes. With minimal overhead, empirical separability across attacker classes, scale-stable thresholds, and analytic structural bounds on fabrication, the protocol offers a practical, transferable, and theoretically grounded solution for integrity verification in hosted LLM inference environments.