- The paper proposes a geometric formalism for offline RL policy extraction by using a Fisher-metric constrained local transport map to align with the intrinsic data manifold.
- It introduces a tractable algorithm that leverages a residual neural field to perform local, anisotropic policy updates, overcoming the limitations of isotropic L2 penalties.
- Empirical results across OGBench, D4RL, and visual RL tasks demonstrate superior performance, robust support preservation, and reduced mode collapse in multimodal scenarios.
Fisher Decorator: Refining Flow Policy via A Local Transport Map
The paper proposes a new geometric formalism for policy optimization in offline reinforcement learning (RL), identifying a crucial discrepancy between the widely used L2 (2-Wasserstein, W2) regularization and the canonical KL-constrained trust-region objective. In standard practice, flow-based policy extraction methods such as FQL instantiate an L2 penalty, which corresponds to an upper bound of the W2 distance between the behavioral and refined policy. This isotropic metric fails to account for the highly anisotropic and density-sensitive structure of the behavioral policy, resulting in support drift, mode averaging, and ultimately suboptimal updates, particularly in multimodal action landscapes.
The central contribution is to frame policy extraction not as an unconstrained flow parameterization, but as a locally supported transport map over the behavioral distribution, governed by a Fisher information-induced quadratic form. This results in a tractable anisotropic trust-region update that explicitly aligns with the intrinsic geometry of the behavioral policy’s statistical manifold.
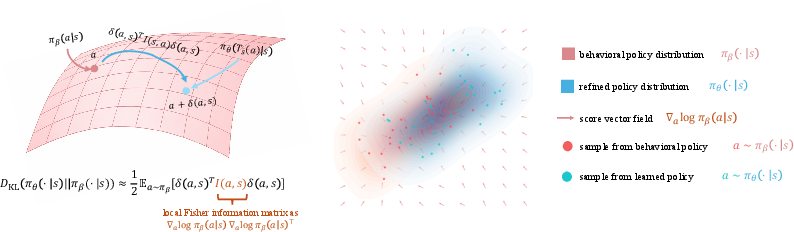
Figure 1: Each action in the behavioral support is refined via a local transport map, with the induced KL governed by a Fisher-metric quadratic form that respects manifold geometry.
Transport Map Parameterization and Fisher Metric Constraint
Rather than learning a new one-step policy, the refined policy is constructed as the pushforward of the behavioral policy through a learned residual transport, Ts(a)=a+δ(s,a), where δ is a neural residual field. The pushforward transformation preserves the statistical support of πβ and ensures that the refinement operates only within the manifold defined by the data. By Taylor expanding the KL-divergence under small δ, the constraint simplifies to a local Fisher-metric quadratic form:
DKL(πθ(⋅∣s)∥πβ(⋅∣s))≈21Ea∼πβ(⋅∣s)[δ(s,a)⊤I(s,a)δ(s,a)]
where I(s,a), the Fisher information, encodes the anisotropic sensitivity of the density at each sample. This formulation regularizes mass transport directions appropriately and penalizes displacements according to the local curvature of the data manifold.

Figure 2: Comparison: (left) flow Q-learning treats refinement as independent one-step mapping; (right) local transport map (FiDec) builds residual refinement upon the original flow, with Fisher-metric constraint.
Practical Algorithm and Quadratic Approximation
The practical learning algorithm, FiDec, alternates between critic fitting, behavioral flow pretraining, and local residual optimization under a Lagrangian incorporating the quadratic Fisher-metric constraint. Key to implementation is that the Fisher information at each point can be estimated efficiently by a stable local finite-difference via the flow model’s velocity field, avoiding numerical pathologies near boundary cases (see the provided derivations).
This reframes trust-region optimization in policy space as an explicit quadratic program: the optimal local residual is given by a natural gradient direction, scaling the value gradient by the inverse Fisher information. This provides the additional benefit of a closed analytic solution under the quadratic approximation, with well-quantified suboptimality if an isotropic (W20) penalty is used instead.
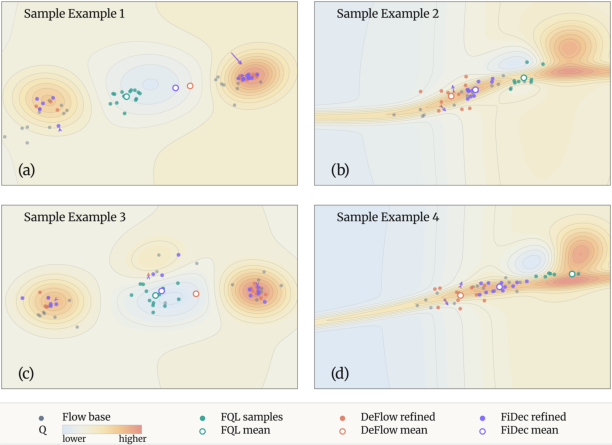
Figure 3: Isotropic (FQL, DeFlow) vs. anisotropic (FiDec) refinement—FiDec preserves multimodality and avoids off-support drift or mode interpolation, consistently shifting probability to high-value regions along the valid data manifold.
Empirical Evaluation
Comprehensive experiments on OGBench, D4RL, and vision-based offline RL tasks demonstrate that FiDec produces state-of-the-art performance, consistently outperforming Gaussian, diffusion, and isotropic flow-based policies. The improvements are most pronounced on environments with strong multimodality or thinly supported behavioral distributions, where mode averaging or drift commonly degrades baseline offline RL methods.
Comparisons show that FiDec strictly dominates DeFlow and FQL under matched architectures, with significant gains in final policy value, sample complexity, and robustness to distributional shift. The advantage persists when tuning the key hyperparameters, including the Fisher estimation's time perturbation; the theoretical analysis of bias-variance tradeoff yields optimal perturbation values matching empirical findings. The framework also translates seamlessly to offline-to-online RL, producing faster and higher-quality fine-tuning compared to all baselines.

Figure 4: The method is benchmarked across diverse OGBench tasks, covering challenging multimodal, navigation, dexterous manipulation, and visual RL domains.
Theoretical and Practical Implications
The analysis clarifies that the Fisher-metric trust region provides a locally support-preserving, geometry-aware constraint on policy improvement. The method provides a tractable instantiation of local natural-gradient updates in the action space. Importantly, experiments support the claim that anisotropic regularization according to the Fisher metric is always as good or better than isotropic (W21) penalties for any given architecture, while incurring negligible extra computation.
From a theory perspective, this establishes that the empirically observed mode-collapse and off-support drift in flow-based offline RL is a direct consequence of the geometric mismatch between isotropic W22 penalties and the true statistical manifold of KL-constrained policy update. The analytic formula for the optimal residual opens possibilities for even faster, potentially training-free, policy refinement via direct natural-gradient application, contingent on efficient Fisher estimation.
Conclusion
The Fisher Decorator framework addresses a structurally critical flaw in previous flow-based offline RL by enforcing anisotropic, Fisher-metric regularization compatible with the intrinsic geometry of the behavioral distribution. The method achieves superior expressivity, robustness, and training efficiency with a simple residual parameterization, and extends naturally to online fine-tuning. Future directions include exploring global closed-form refinement procedures and further extensions of geometry-aware policy updates in high-dimensional RL and generative modeling contexts.

