- The paper introduces AVA, a novel retrieval-augmented generation system that uses a curated corpus and multi-agent strategies to ensure citation verifiability in policy research.
- It employs reasoned abstention and multilingual retrieval to mitigate hallucinations and support precise, evidence-based decision-making.
- Empirical results from a five-month field study with over 2,200 professionals indicate significant efficiency gains and high trust in the system’s reliable outputs.
Early Lessons from AVA: A Curated, Trustworthy Generative AI for Policy and Development Research
Motivation and Problem Setting
The application of LLMs to policy and development research is fundamentally constrained by the risk of hallucinated information and unverifiable claims. Standard RAG and open-domain LLMs lack robust mechanisms for citation verifiability and epistemic humility, which are essential for high-stakes knowledge work in policy, governance, and development. The core innovation in "Learning from AVA: Early Lessons from a Curated and Trustworthy Generative AI for Policy and Development Research" (2604.17843) is the design, longitudinal deployment, and empirical analysis of AVA—a multi-agent, domain-bounded RAG system tailored for evidence-intensive workflows, operationalizing epistemic humility via both click-through verifiable citations and systematic, reasoned abstention.
System Architecture and Design Objectives
AVA is instantiated as a RAG pipeline over a curated, hierarchically indexed corpus of 4,000+ World Bank Reports, making it fundamentally different from open-web engines and user-supplied retrieval systems. Four design goals shape AVA: (1) all generation must be verifiable at the citation span level, (2) the system must decline to answer when grounding is insufficient ("reasoned abstention"), (3) multilingual retrieval and response are required, and (4) explicit, user-controlled personalization is supported, but never at the expense of evidence fidelity.
Central to this pipeline is a multi-agent retrieval and synthesis stack: (a) query decomposition with intent detection and sub-question mapping, (b) hybrid lexical-semantic retrieval planning, (c) hierarchical tree-walking over document structure and semantic neighborhoods, and (d) evidence packet structuring with fine-grained provenance tracking. The orchestration leverages specialized, fine-tuned transformer models for passage selection, response drafting, and verification. Sentence-level claim coverage and agreement thresholds are enforced, with abstention triggered when evidence is insufficient or contradictory. Multilingual user queries are natively supported via strong embedding models (Qwen3-Embedding-8B), and passage highlighting, in-context citation, and preview affordances operationalize interface-level trust.

Figure 1: Annotated AVA interface highlighting core modules for verifiable, evidence-centric generative QA tasks.
Large-Scale, Longitudinal Field Study
Over five months, AVA was deployed in-the-wild with 2,200+ professionals across 116 countries (Figure 2). Participants were predominantly external to the host institution (95.4%), ensuring discretionary, ecosystem-driven adoption. Mixed-methods evaluation integrated log analysis (7,000+ queries), in-app and endline surveys, and 20 semi-structured interviews.
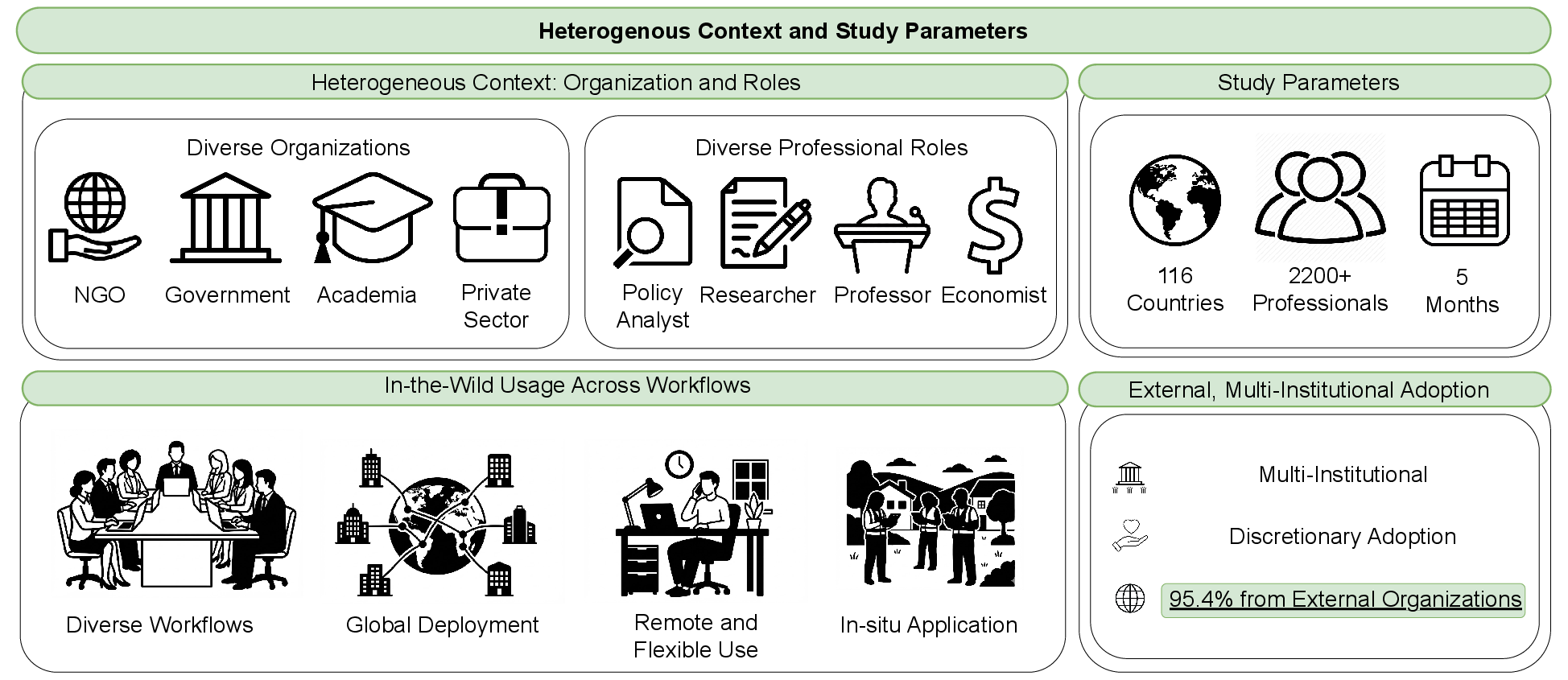
Figure 2: AVA's multi-institutional and international scale, with strong external uptake and voluntary, in-situ workflow integration across 116 countries.
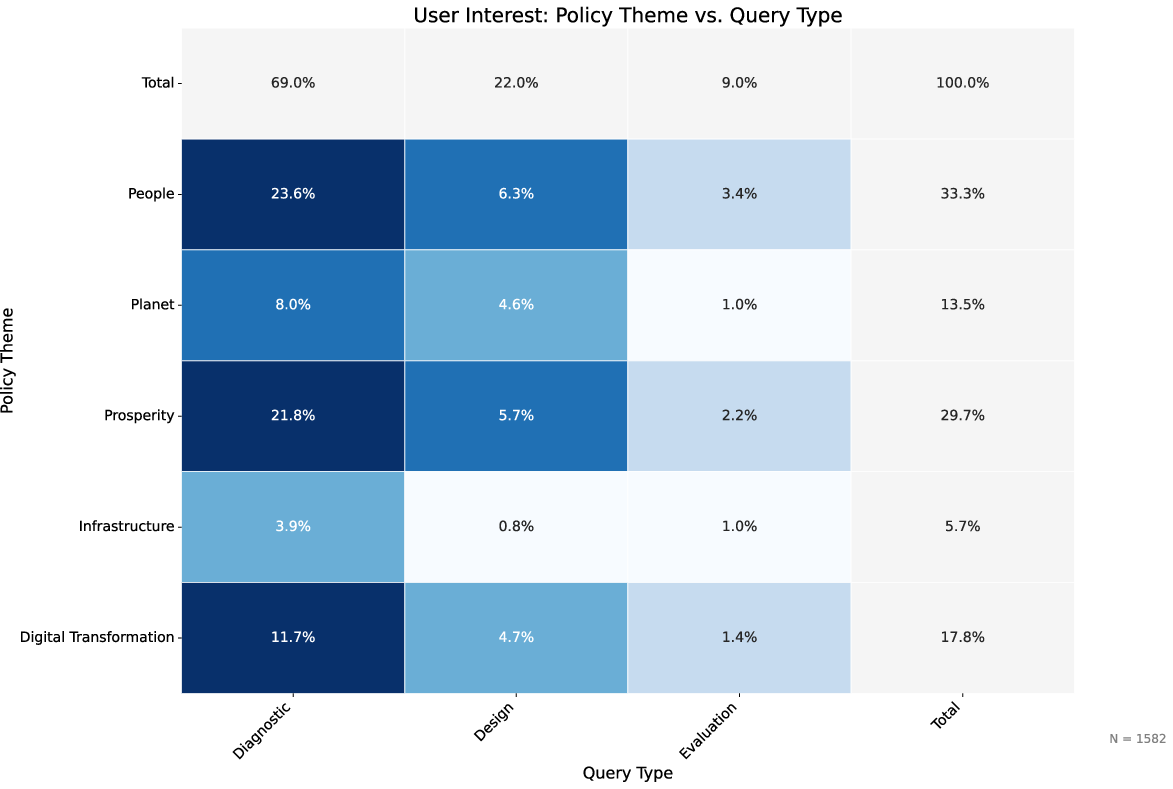
Study instrumentation included randomized encouragement with an 80:20 access-control assignment, yielding both ITT and difference-in-differences regression estimates on efficiency, workflow integration, and trust calibration. Detailed session-level log records enabled fine-grained behavioral analysis, coupled with query taxonomy mapping to policy themes and task types.
Empirical Findings
Macro User Behavior and Task Profile
Trust Calibration: Epistemic Humility in Action
- Page-anchored, interactive citations were identified as AVA's most valuable feature. Users relied on selective, claim-level citation checking as a shortcut for verification and trust calibration, especially for counterintuitive or numerical results.
- The abstention mechanism (explicit "I don't know" responses with rationale and reformulations) was generally interpreted as a signal of trustworthiness, setting clear bounds on system knowledge and reducing the likelihood of over-claiming.
- Users developed anthropomorphic mental models of AVA as a reserved, honest collaborator, contrasting it with generalist LLMs that "make things up" or provide ungrounded answers. Some user segments, however, expressed frustration at perceived workflow dead ends posed by abstention.
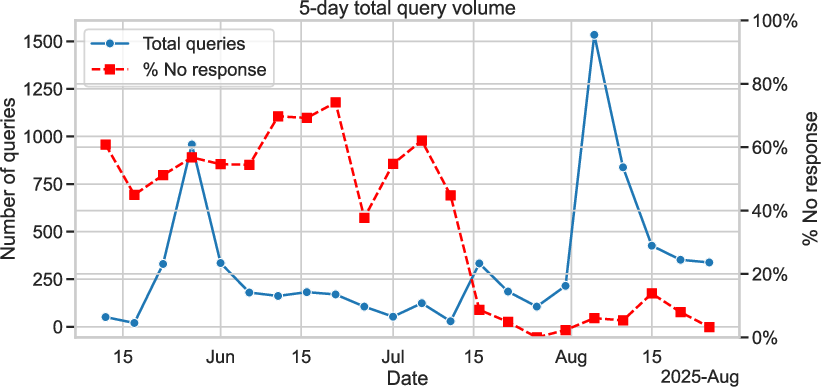
Figure 4: Query volume and abstention rates: abstention is high with limited coverage, but drops sharply after corpus expansion, stabilizing as a low-frequency, positive trust signal.
Strong Numerical and Behavioral Results
- Users engaging in multiple sessions (vs. single use) reported significant time savings—2.4 to 3.9 hours saved weekly (p<.10 in difference-in-differences regression)—with dose-response patterns observable in both log data and self-report.
- While ITT analysis showed no main-effect on productivity for all compliers, incremental gains accrued for those integrating AVA into sustained, multi-session workflows.
- Survey data indicated 80.5% of users rated AVA as enabling more efficient access to key insights, 82.2% as trustworthy, and 89% as recommending AVA to peers.
Comparative Robustness: Humility vs. Fluency
Benchmarking against Perplexity AI and Google NotebookLM using a constricted, standardized corpus, AVA achieved parity and in some dimensions outperformed on standard linguistic quality metrics (comprehensiveness, coherence, etc.). However, the critical divergence appeared in epistemic humility: AVA triggered abstention on 11.9% of queries (all distractors and unsupported prompts); Perplexity AI declined 0% of queries, hallucinating plausible content with fabricated citations for out-of-domain tasks (Figure 5). AVA's ability to "refuse" appropriately is highlighted as essential for professional adoption in high-stakes settings.
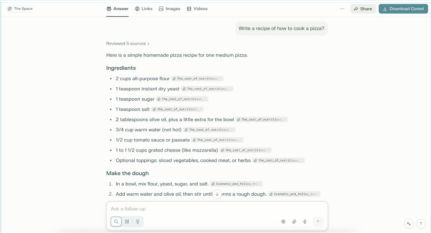
Figure 5: Perplexity AI fabricates a plausible recipe for out-of-domain prompt, indicating lack of epistemic humility and ungrounded content generation.
Implications and Design Lessons
- End-to-End Trust Pipeline: Reliability emerges from spanning corpus curation (inheriting institutional trust), model-level abstention (enforcing non-answer on insufficient evidence), and interface-level verification (enabling low-friction, claim-level inspection). User trust was calibrated at both the feature and corpus levels, with provenance and evidence orientation described as mutually reinforcing.
- Epistemic Humility as Reliability, Not Limitation: Once corpus coverage is adequate, conservative abstention signals caution, not failure. Abstention must be reasoned and service-oriented, balancing epistemic honesty with relational humility to avoid user frustration from perceived conversational dead ends.
- Verification Over Disclosure: Professional users prioritized low-friction evidence verification over blanket AI disclosure—placing accuracy and citation auditability at the core of practice, rather than transparency norms per se.
- Collaborative AI Ecosystems: The AVA deployment demonstrates that specialized, evidence-grounded agents and generalist LLMs are increasingly orchestrated as interdependent components within professional workflows. Design must prioritize trust-preserving, intelligent handoffs—avoiding reputation transfer from specialist to generalist when system boundaries are reached.
Limitations and Open Directions
Limitations include a deployment timescale insufficient to fully characterize long-term organizational impacts or adaptation; observed language use is skewed toward English (due to domain norms); and self-selection among survey/interview participants may bias attitudinal findings upward. Future research vectors include: (i) optimizing intelligent handoff and collaboration protocols between epistemically humble agents and open-domain LLMs, (ii) multi-domain transfer of the trust pipeline paradigm (notably in health/legal domains), and (iii) systematic evaluation of abstraction and refusal across broader language and user populations.
Conclusion
AVA represents a rigorous operationalization of epistemic humility in generative AI for high-stakes knowledge work. The system's enforced verifiability, reasoned refusal, and evidence-centric workflow integration yield both pragmatic efficiency gains and recalibrate trust relations between human professionals and AI. More broadly, the design and empirical trajectory of AVA argue for a paradigm of ecosystem-aware, specialized, and humble AI—where reliability, accountability, and verification are engineered throughout the full system pipeline and where the ability to say "I don't know" is realized as a primary virtue, not a defect.
References
For further technical details and empirical benchmarks, see the full text: "Learning from AVA: Early Lessons from a Curated and Trustworthy Generative AI for Policy and Development Research" (2604.17843)