- The paper demonstrates that diffusion models exhibit grokking on modular addition by developing explicit trigonometric periodic circuits.
- It employs a flow-matching loss with a single-layer Diffusion Transformer and a pre-attention FFN bottleneck to induce abstraction from visual symbols.
- Temporal decomposition reveals a critical phase transition where entropy peaks in spectral representations correspond to lost capacity for algorithmic computation.
Mechanistic Grokking in Diffusion Models on Modular Addition
The paper "Grokking of Diffusion Models: Case Study on Modular Addition" (2604.17673) conducts a mechanistic examination of how diffusion models, specifically trained with flow-matching objectives, generalize discrete algorithmic rules using modular addition as the canonical testbed. Prior studies have established that transformer-based sequence models exhibit grokking—marked by delayed sharp generalization following extended overfitting—when trained on algorithmic tasks like modular addition. However, it has remained unclear if, and how, generative diffusion models build similar algorithmic circuits, especially when the task is expressed in a high-dimensional image manifold rather than discrete tokens. The work empirically demonstrates that, under the right settings, diffusion models do exhibit grokking, and it dissects the representational and temporal structure of this process to expose when and where algorithmic computation emerges.
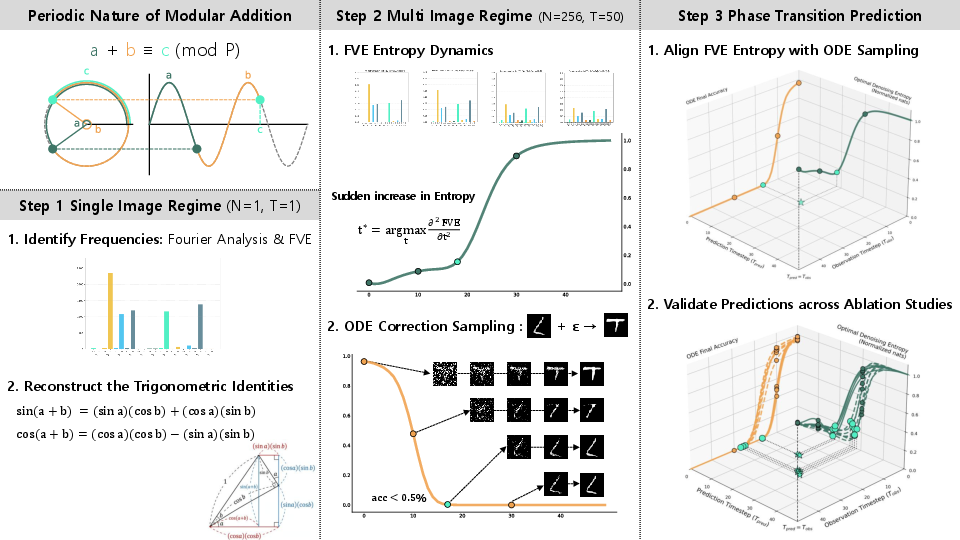
Figure 1: Overview of the analysis pipeline: mechanistic periodic structure detection (left), phase transition analysis in multi-image regimes (middle), and FVE entropy alignment with ODE sampling accuracy (right).
Experimental Setup and Model Architecture
The study defines modular addition a+b=c(modP) using visual symbols, where the operands and result are rendered as EMNIST or KMNIST images for various moduli P. Both unary (single image per class) and highly diverse (e.g., N=256 images per class) regimes are considered to elucidate the evolution of algorithmic abstraction.
A single-layer Diffusion Transformer (DiT) serves as the backbone, receiving concatenated visual operands and Gaussian noise as input, and tasked with directly reconstructing the image of c. The architecture supports flexible ablation (e.g., standard vs FFN-sandwich variants) to isolate representational bottlenecks. The flow-matching training loss is adopted, with x0-parameterization to interpret latent structure. For quantitative evaluation, a high-accuracy ResNet18 classifier tags model outputs in all regimes.
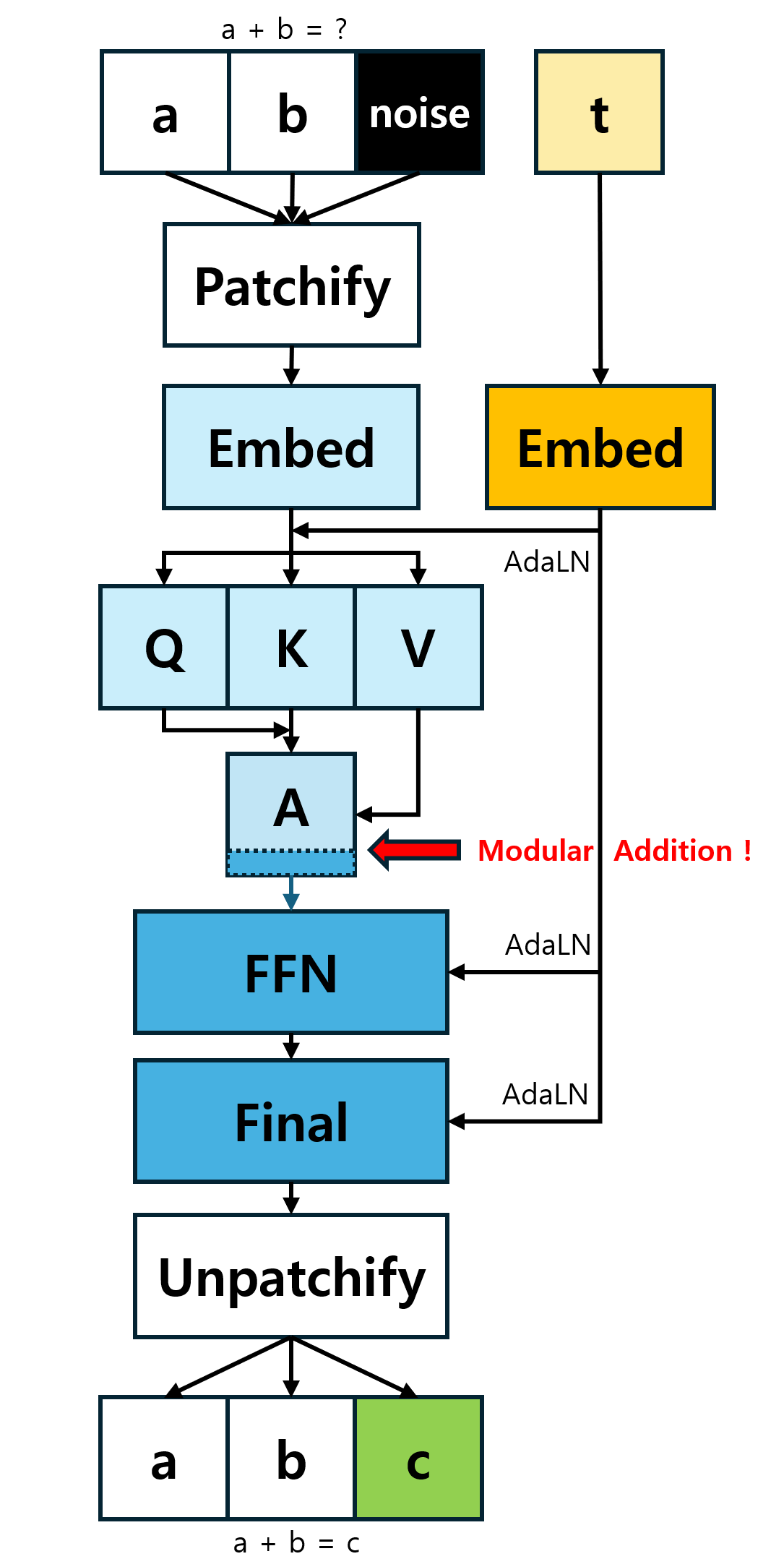
Figure 3: Schematic of the single-layer Diffusion Transformer architecture—the operand images and Gaussian noise are patchified, concatenated, and processed through SA and FFN blocks, with Adaptive LayerNorm for timestep conditioning.
Grokking Phenomenon and Spectral Mechanistic Analysis
In the token-like, single-image regime (N=1), classic grokking is reproduced. The model achieves prompt training accuracy while validation accuracy remains at chance for an extended period, followed by a sudden phase where perfect generalization is apparent.
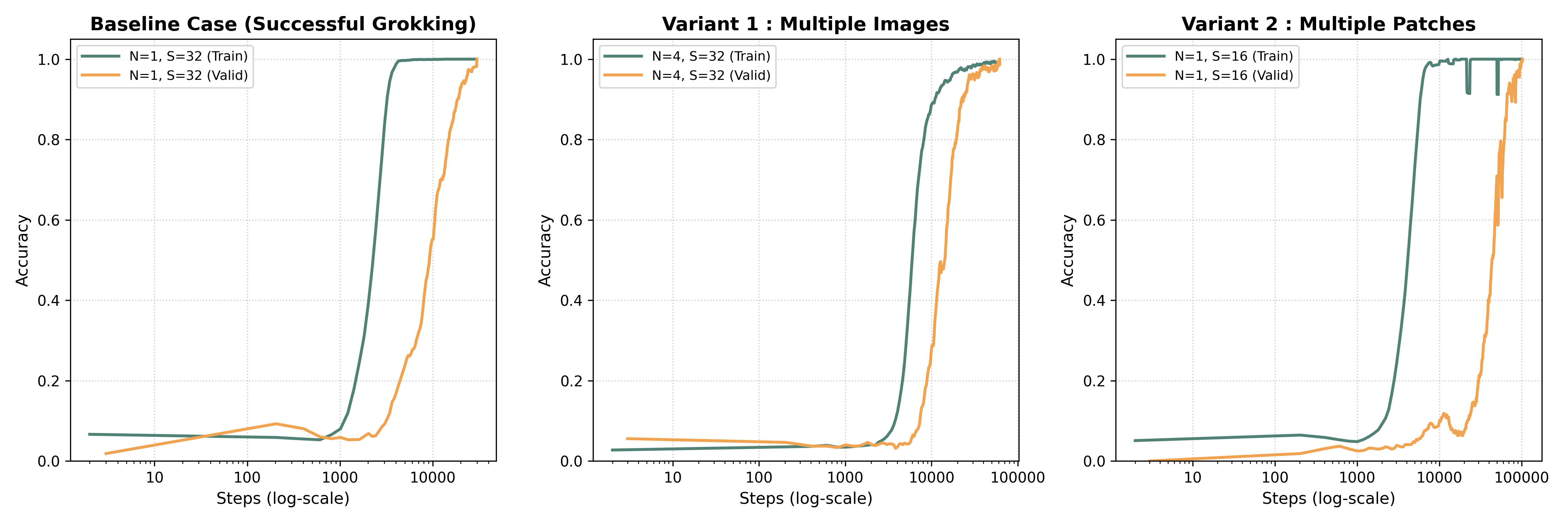
Figure 4: Grokking dynamics for N=1,4, showing lagged validation improvement; increased visual diversity reduces the generalization lag.
A critical mechanistic discovery is made via a Fourier basis analysis of activations in the self-attention and feedforward layers. Immediately after attaining perfect generalization (i.e., after grokking), distinct periodic encodings emerge: model features are sharply concentrated on specific frequencies (wk) tied to trigonometric representations of each operand. At the key computational bottleneck (the pre-FFN layer at the result position c), 1D components disappear and the activation is dominated by 2D terms corresponding to the theoretical trigonometric addition identities for modular arithmetic. These 2D frequency interactions confirm that the model has constructed an explicit, compositional algorithmic solution analogous to transformer circuits seen in discrete models.
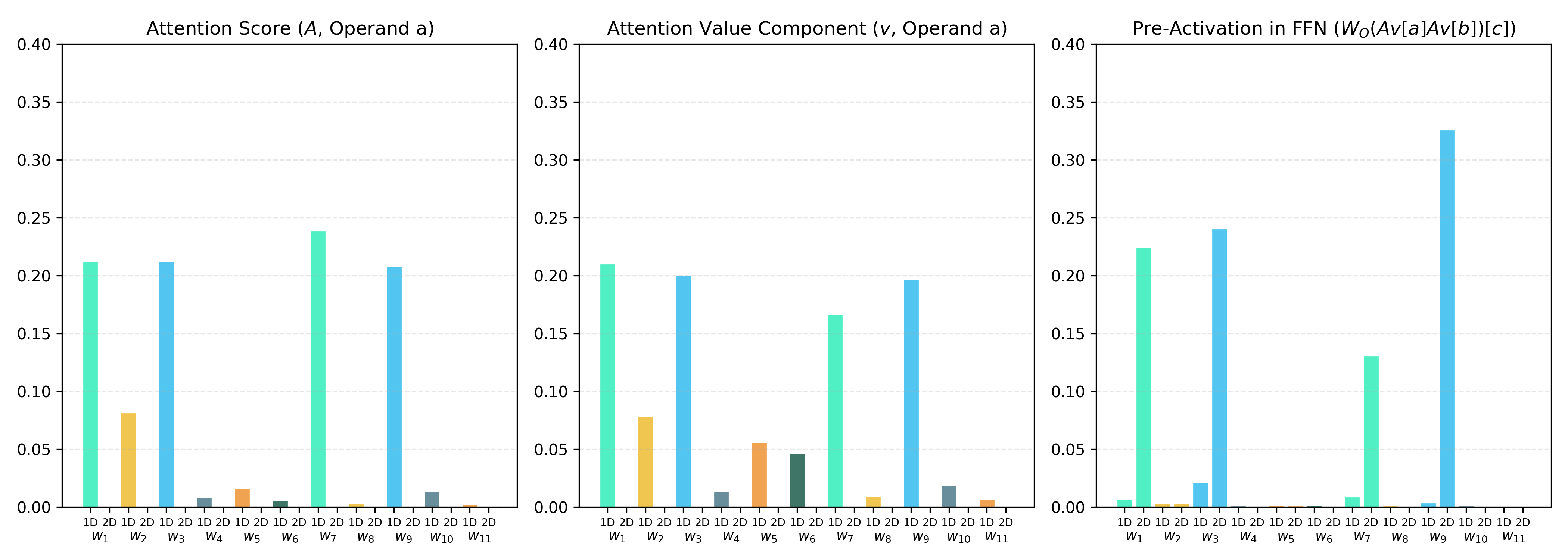
Figure 5: Fractional Variance Explained (FVE) spectral analysis showing the emergence of dominant periodic frequencies in attention and FFN blocks; 2D components dominate in the result composition.
Transitioning to the N=256 regime introduces large intra-class variability, converting the task from rote symbol prediction to abstract algorithmic induction over visual manifolds. The ability to grok in this setting is not preserved under a naїve architecture; rather, a representational bottleneck is required before attention—achieved with an additional pre-attention FFN layer (the sandwich architecture). PCA analysis confirms this design's necessity: Only after the pre-SA FFN do latent clusters become linearly separable by result class, enabling the subsequent SA block to effectuate arithmetic abstraction.
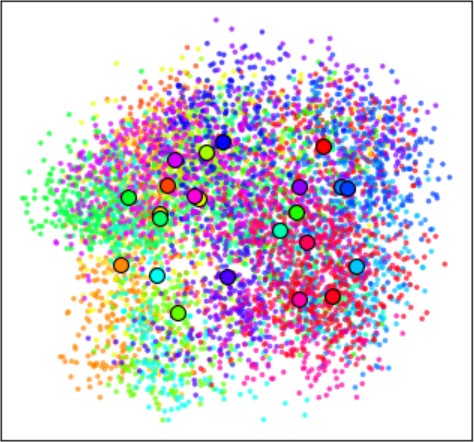
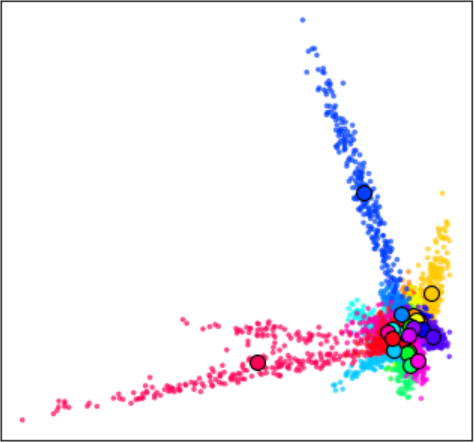
Figure 6: PCA on pre-SA-FFN activations—raw continuous visual features (left) become discrete class clusters (right) after this layer, confirming abstraction to a symbolic space.
In this high-diversity regime, validation accuracy approaches 94–95% (ResNet18 upper bound), demonstrating the emergence of robust non-memorization-based generalization.
Temporal Decomposition: Sampling Phase Transition and Entropy Analysis
Leveraging the multistep sampling trajectory unique to diffusion models, the paper introduces a temporal decomposition of the denoising process. Through causal interventions (manipulating the result image's initialization at various timesteps), it is shown that early denoising stages (high noise) enable the model to overwrite even incorrect results via algorithmic computation; whereas, once a critical timestep P0 is passed—corresponding to a sudden rise in FVE entropy—this capacity is lost, and the model transitions to simple visual denoising.
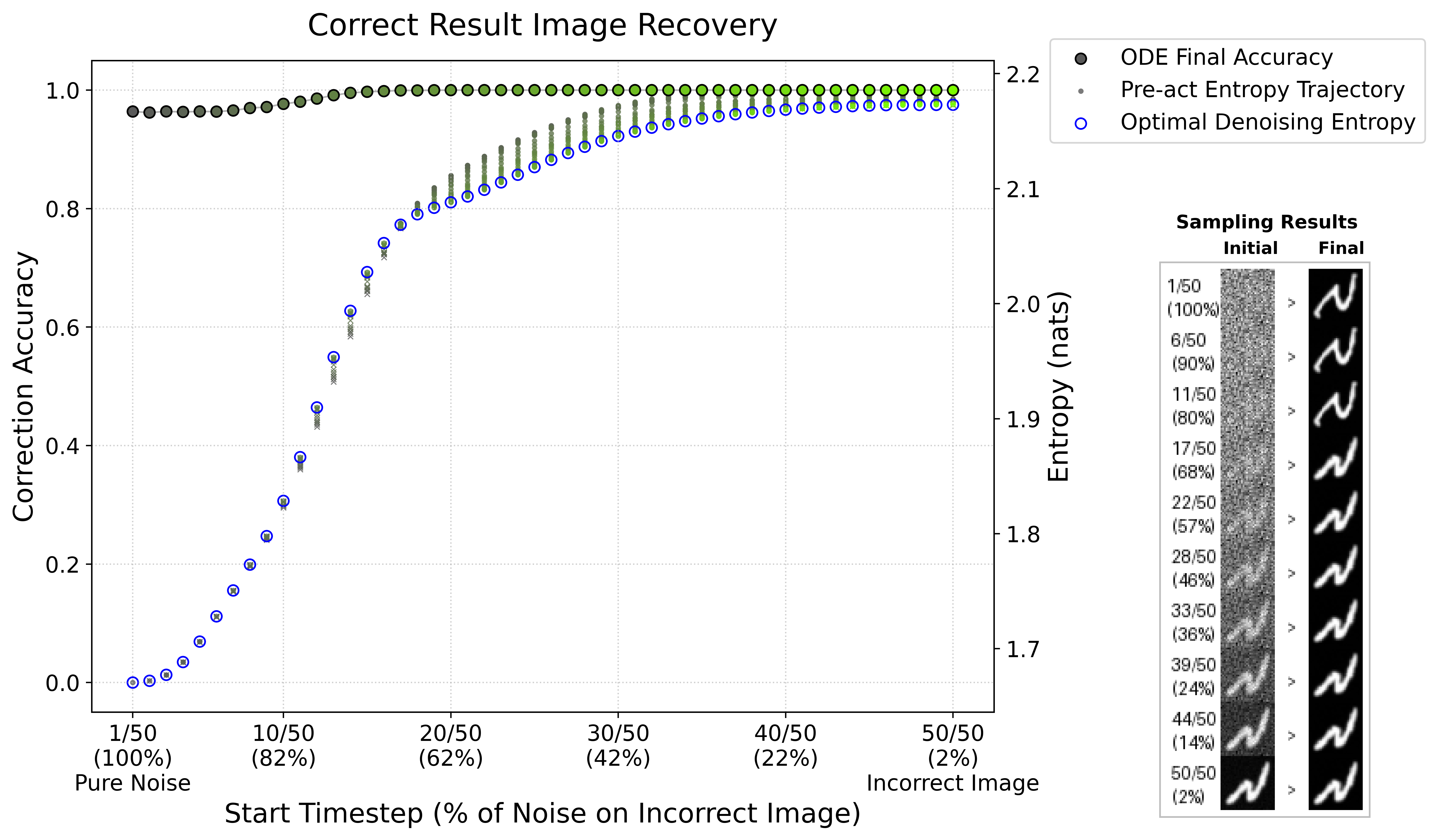
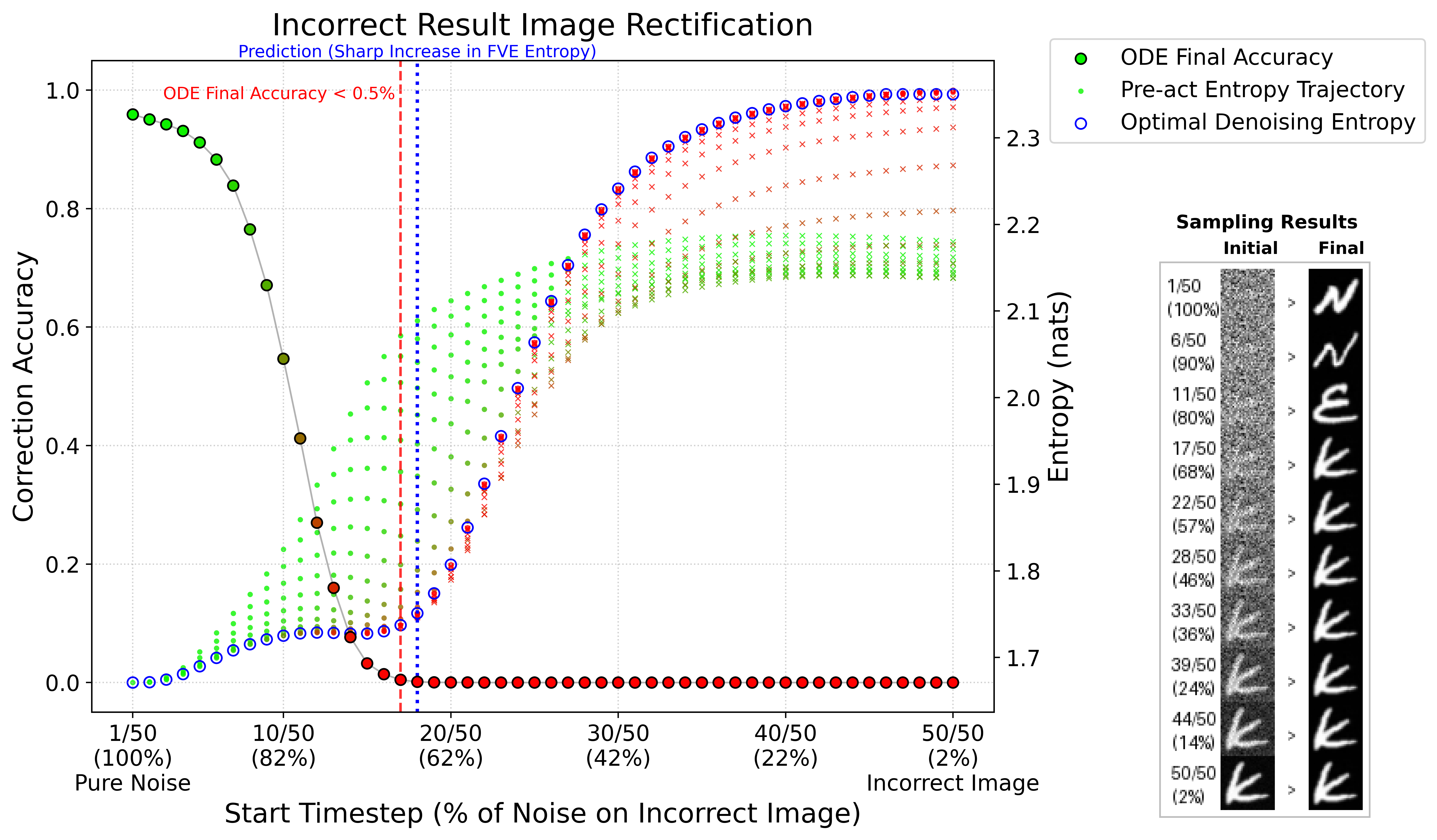
Figure 2: Causal intervention: model can rectify incorrect result images starting from high noise states (green), but fails below the critical entropy threshold (red).
This phase transition is robustly tracked by the entropy of the model's internal spectral representation. The critical point aligns precisely with the loss of ODE sampling accuracy, with P1 across all dataset and modulus ablations, validating that internal module structure (spectral focus) emerges and then collapses in sharp correspondence with external outputs.
Generalization and Ablation: Robustness to Modulus, Dataset, Depth
Ablations demonstrate that mechanistic periodic circuits and the two-phase temporal sampling partition persist for various moduli P2 (23, 27, 31, 35) and on the more visually complex KMNIST dataset. Generalization is also robust to multi-layer network depth: a depth-2 vanilla DiT (with an implicit bottleneck between SA blocks) also exhibits grokking and algorithmic representational emergence.
Implications and Outlook
The identification of explicit trigonometric periodicity, matched to the group-theoretic structure of modular addition, in the latent features of a diffusion model bridges the gap between discrete sequence learning and visual generation. The finding that algorithmic circuits in diffusion models are not merely possible but are temporally localized—with arithmetic processing preceding abstract-to-concrete transitions—is critical for interpretability, debugging, and future research in hybrid neuro-symbolic generative modeling.
Practically, this mechanistic resolution enables formal monitoring and potential control of model computation during generation, suggesting avenues for the design of more reliably reasoning-generative joint systems. Theoretically, it positions diffusion models as bona-fide candidates for algorithmic reasoning tasks previously thought to be the domain of LLMs and transformers, provided architectural interventions impose suitable abstraction bottlenecks.
Prospects for future work include extending mechanistic dissection tools (e.g., geometric analysis, circuit cutting) from language to continuous generative domains, studying compositionality and hierarchy in diffusion models, and formalizing phase transitions between abstract and concrete computation modes across diverse generative objectives.
Conclusion
This work conclusively demonstrates that diffusion models can exhibit grokking and algorithmic generalization on modular arithmetic in pixel space when supported by architectural mechanisms that promote abstraction. The study delivers a precise characterization of the internal circuits, their spectral signatures, and the critical temporal transitions underlying generative reasoning in these models, supporting both mechanistic interpretability research and the broader theoretical unification of reasoning in diffusion-based and transformer-based neural architectures.