Generalization of Diffusion Models Arises with a Balanced Representation Space
Abstract: Diffusion models excel at generating high-quality, diverse samples, yet they risk memorizing training data when overfit to the training objective. We analyze the distinctions between memorization and generalization in diffusion models through the lens of representation learning. By investigating a two-layer ReLU denoising autoencoder (DAE), we prove that (i) memorization corresponds to the model storing raw training samples in the learned weights for encoding and decoding, yielding localized "spiky" representations, whereas (ii) generalization arises when the model captures local data statistics, producing "balanced" representations. Furthermore, we validate these theoretical findings on real-world unconditional and text-to-image diffusion models, demonstrating that the same representation structures emerge in deep generative models with significant practical implications. Building on these insights, we propose a representation-based method for detecting memorization and a training-free editing technique that allows precise control via representation steering. Together, our results highlight that learning good representations is central to novel and meaningful generative modeling.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tries to explain why modern image-making AI systems called diffusion models sometimes “memorize” exact training pictures, and other times “generalize” by creating new, original images that still look like they belong to the same category. The authors show that the difference comes from the “representations” the model learns inside—basically the internal codes or features the model uses to think about images. They prove that when the model memorizes, these codes are spiky (only a few parts light up). When the model generalizes, the codes are balanced (many parts share the work). They also show how to use these codes to detect memorization and to steer edits in generated images.
What questions does the paper ask?
- Why do diffusion models sometimes memorize training data instead of truly learning patterns?
- What does “generalization” look like inside the model?
- Can we tell if a model is memorizing by looking at its internal codes?
- Can we use these codes to control and edit images without retraining the model?
How did the researchers study the problem?
A quick primer on diffusion models
Diffusion models make images by starting with random noise and then slowly “denoising” it step by step to produce a picture. To do this well, the model needs to learn a function that takes a noisy image and predicts the clean version.
The simple network they analyzed
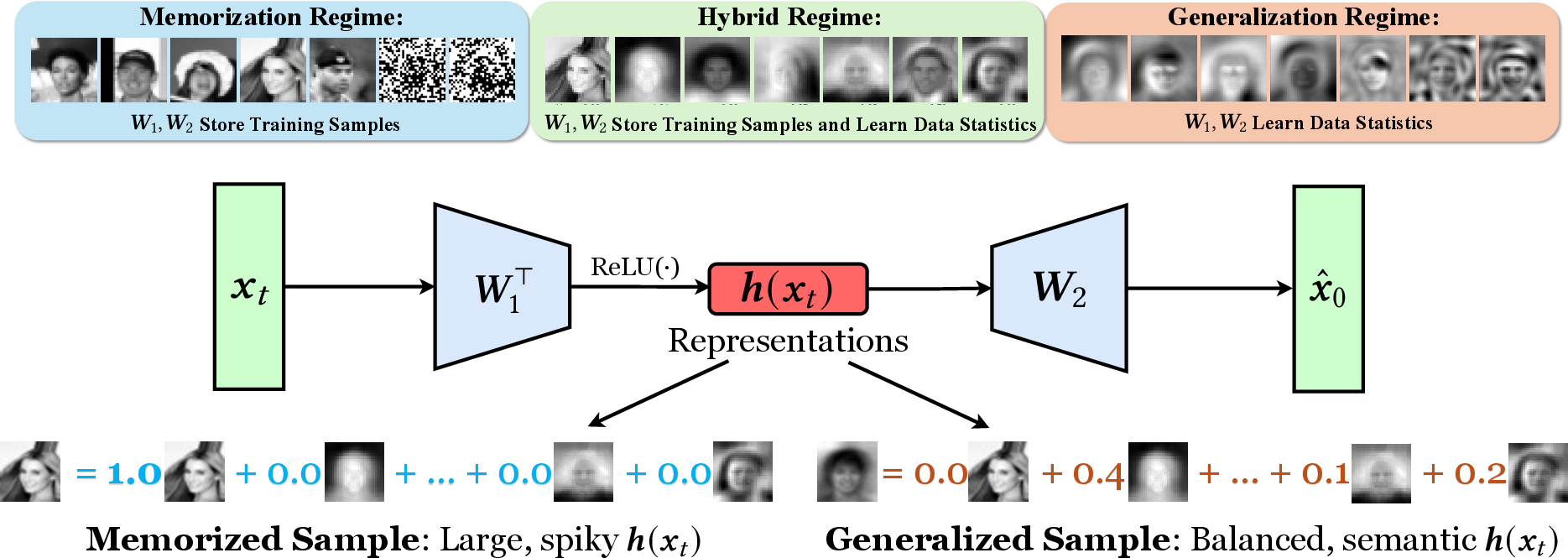
To understand what’s going on, the authors studied a very simple version of the model: a two-layer denoising autoencoder with ReLU activations (think of it as a basic two-step brain that:
- encodes the input into a shorter “code,” and
- decodes that code back toward a clean image).
ReLU is a standard “on/off” switch used in neural networks. Studying this small model lets them write clear math proofs and see the core behaviors without getting lost in complexity.
The kind of data they assumed
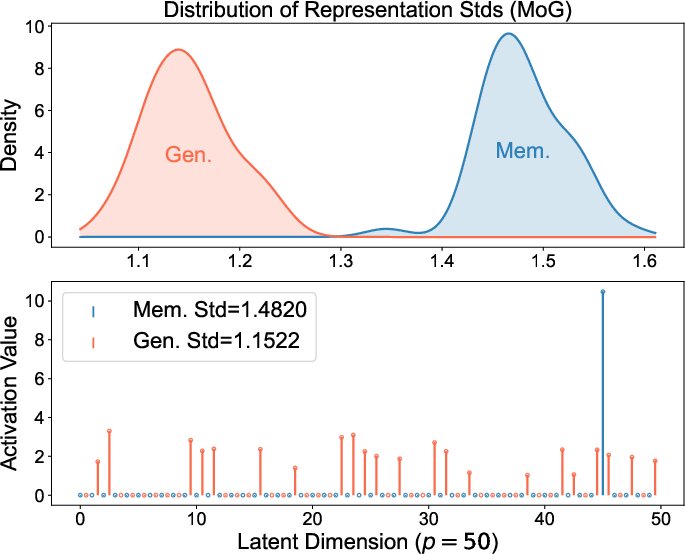
They assume the training data comes in “clusters” (like groups of similar faces or objects). Mathematically, they model these clusters as a mixture of Gaussians (which just means “lots of examples around some center, with some spread”). This is a common way to describe real-world datasets.
What does “representation space” mean?
Inside the model, the middle layer produces a “representation” (a vector of numbers) that summarizes the input. You can imagine it like a set of lights: each light turns on a bit depending on what the model sees. If only one or two lights flash strongly, that’s a spiky code. If many lights glow moderately, that’s a balanced code.
What did they find?
Memorization: storing exact training images
If the model is very big compared to how much data it sees (more hidden units than training images), it can end up storing the raw training pictures directly in its weights. In this case:
- The internal codes become spiky—one or a few neurons light up strongly for a memorized picture.
- When you generate images, you tend to get near-duplicates of training examples.
- This is “overfitting” in plain terms.
Generalization: learning patterns and statistics
If the model is smaller or the data is rich (many examples in each cluster), it can’t store everything. Instead, it learns the local statistics of the data (like the average look and main directions of variation in a cluster). In this case:
- The internal codes are balanced—multiple neurons share the work.
- The model can produce new images that look like they belong to the same category but aren’t copies.
- This is “generalization.”
Hybrid: real-world mixes
Real datasets often have imbalances and duplicates (some images appear many times). In those parts, the model tends to memorize. In other, well-sampled parts, it generalizes. So the same model can show a mix of both behaviors, depending on the data.
Evidence in real models
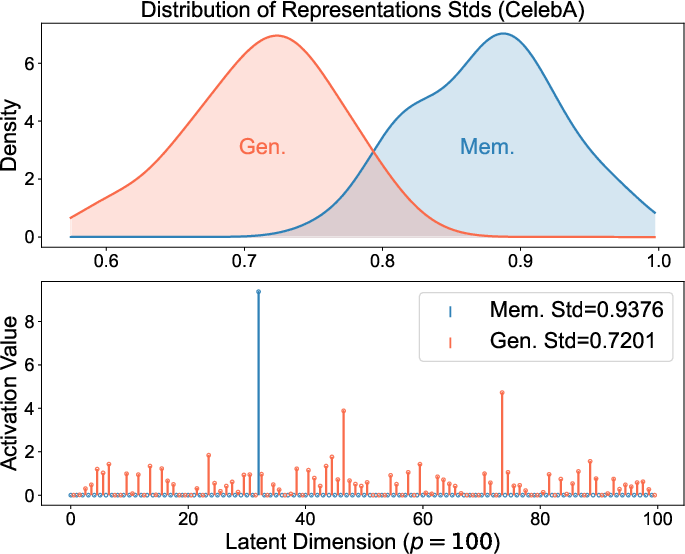
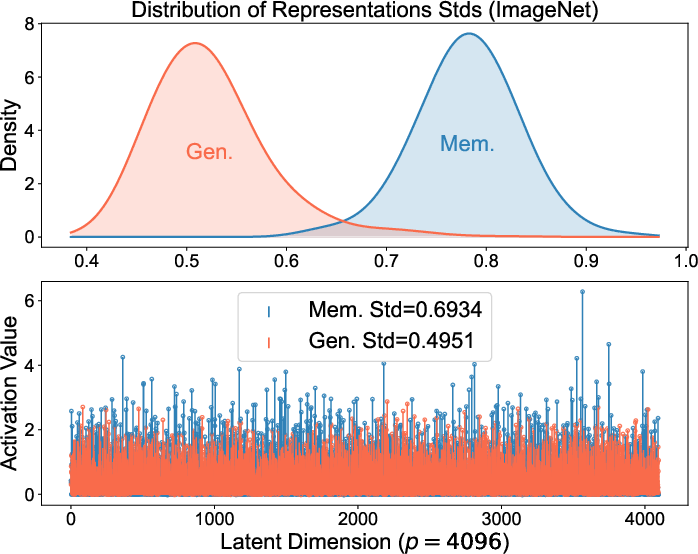
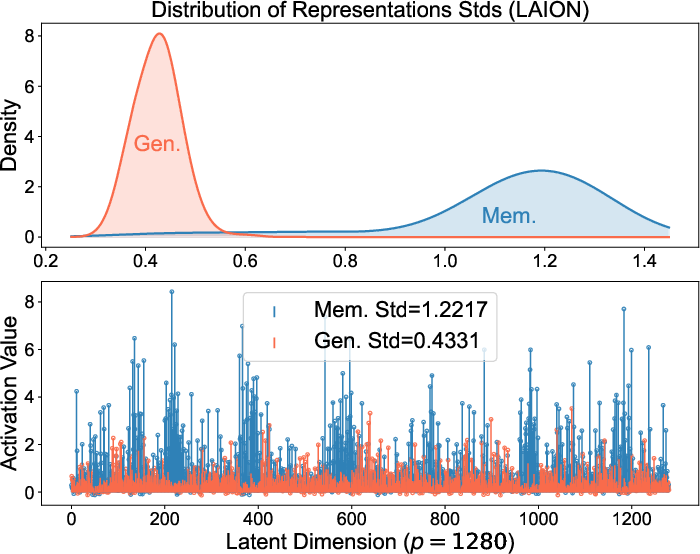
These patterns aren’t just theoretical. The authors checked popular, real-world diffusion models (like Stable Diffusion and Diffusion Transformers) and found the same internal code behaviors:
- Memorized samples have spiky representations.
- Generalized samples have balanced representations.
Why do these results matter?
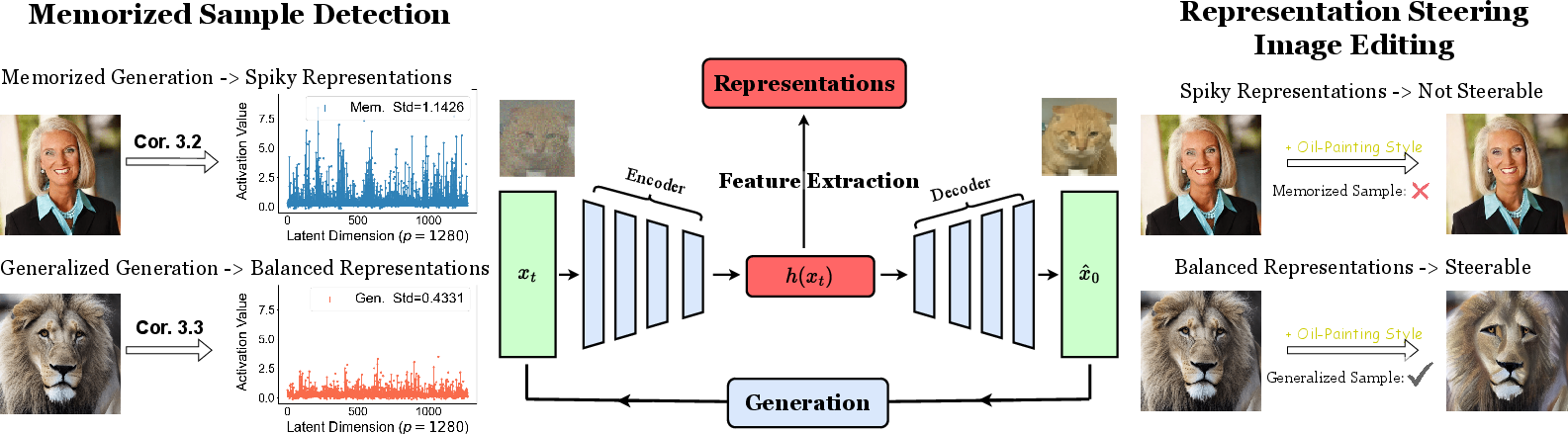
Detecting memorization
Because spiky codes are a clear sign of memorization, you can detect it by measuring how “uneven” the internal representation is. The authors propose a simple, prompt-free detector: compute the spread (standard deviation) of the features in a middle layer. High spread means likely memorization; lower spread means generalization. Their method is fast and accurate compared to existing approaches.
Steering and editing images
Balanced representations hold meaningful, controllable “directions” in feature space (like “more old” or “more oil-painting style”). The authors show a training-free way to edit images by nudging the internal code in the direction of a desired concept (for example, adding a vector that represents “old age” features). This works smoothly for generalized samples but barely affects memorized samples (their codes are too spiky and fragile), making edits choppy or threshold-like.
Broader impact
- Privacy: Detecting memorization helps ensure models aren’t leaking training data.
- Trust and safety: Understanding when a model generalizes vs. memorizes helps with responsible deployment.
- Interpretability and control: Balanced representations make edits and content control easier without retraining.
- Big picture: The paper argues that learning good internal representations is central to making generative models produce meaningful, novel outputs.
Summary in simple terms
Think of a diffusion model’s inner workings like a set of light bulbs forming a “code” for each image:
- If the model memorizes, one big bulb blazes while others stay dark—easy to recognize, hard to edit.
- If the model generalizes, many bulbs glow together—harder to copy exact images but easier to make new ones and to steer style or content.
The authors prove when and why each mode happens, show it in real systems, and use this to build tools to detect memorization and steer images safely and smoothly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain or unexplored, framed to guide concrete future research.
- Extension beyond toy model
- Formal extension from a two-layer, bias-free ReLU DAE to deep architectures with residual connections, normalization, attention (e.g., U-Nets, DiTs) remains open; which parts of the theory provably survive depth, skip-connections, LayerNorm/GroupNorm, and self/cross-attention?
- Impact of alternative activations (GELU, SiLU) and biases on the block-structured optima and representation “spikiness vs balance” is uncharacterized.
- Training dynamics and optimizer bias
- Conditions under which standard optimizers (Adam/AdamW/SGD with momentum, EMA, weight decay) reliably converge to the theorized local minimizers are not proved; characterize basins of attraction, implicit bias, and dependence on initialization and learning-rate schedules.
- Quantify how optimizer choices and training heuristics (gradient clipping, warmups, EMA decay, dropout) shift the memorization–generalization boundary.
- Noise schedules and objectives
- Theory treats a fixed noise level; extend to time-varying noise schedules and coupled multi-timestep training, including how solutions co-adapt across timesteps.
- Generalize from x0-prediction DAEs to epsilon- and v-prediction objectives, and analyze whether “spiky vs balanced” signatures persist across objectives and guidance strategies (e.g., classifier-free guidance).
- Data model assumptions
- The mixture-of-Gaussians and (α, β)-separability assumptions are strong; establish results under non-Gaussian, heavy-tailed, manifold, or multi-scale data with overlapping/curved supports and long-range dependencies.
- Replace the “negative cosine between cluster means” assumption with more realistic separability notions (e.g., margin in learned feature space), and quantify robustness to near-separability and overlapping modes.
- Characterize near-duplicates rather than perfect duplicates, and quantify how similarity/augmentation strength drives transitions to memorization.
- Global vs local optimality
- The results concern existence of local minimizers; provide conditions for global optimality or tight suboptimality gaps, and whether training reliably reaches these solutions in practice.
- Phase transitions and sample complexity
- Precisely locate and quantify the memorization↔generalization phase transition as functions of model width p, mode counts K, per-mode sample sizes n_k, noise level σ, and weight decay λ, including finite-sample rates and double-descent behavior.
- Provide explicit sample complexity bounds for avoiding memorization under realistic spectra and mode imbalance.
- Representation signatures: robustness and metrics
- Validate whether “spikiness” (Std of activations) is layer-invariant, timestep-invariant, and robust to feature scaling/normalization; identify which layers/timesteps are most diagnostic across architectures.
- Compare spikiness to alternative representation statistics (e.g., sparsity L0/L1, kurtosis, Gini coefficient, participation ratio, top-k energy concentration) and derive theory-backed thresholds.
- Establish causal directionality: are spiky codes a cause or a consequence of memorization?
- Detection method: generality and limitations
- Assess prompt-free detection under distribution shift, unseen prompts, varied guidance scales, and different text encoders; analyze false positives on rare or high-contrast but non-memorized concepts.
- Black-box setting: can detection work without internal activations (e.g., using intermediate latents, gradients, or output-space probes only)?
- Adversarial evasion: can models be trained to “smooth” activations while still memorizing? Propose and test attack/defense protocols.
- Calibrate detection under strong augmentations and cropping; quantify robustness to image resolution and tokenization differences (patch sizes, token mixing in DiTs).
- Privacy guarantees and leakage
- Translate representation-based findings into formal privacy guarantees/attacks (membership inference, reconstruction, distribution inference); derive bounds linking spikiness to leakage risk.
- Study interactions with differential privacy or regularizers that constrain representation spikiness; quantify utility–privacy trade-offs.
- Steering method: scope and metrics
- The steering uses average representations of a concept set S; analyze sample efficiency, choice of S, and generalization to multi-concept composition, negation, and disentanglement.
- Provide quantitative editing metrics (identity preservation, CLIP alignment, attribute strength, photorealism) and compare to SOTA steering/editing approaches across concepts and domains.
- Explore steering in unconditional models, video/audio diffusion, and 3D generative models; characterize failure modes and brittleness for memorized samples.
- Conditional generation and cross-attention
- Characterize how text conditioning and cross-attention modulate representation spikiness and the memorization boundary; analyze prompt sensitivity, rare-token effects, and prompt leakage.
- Study whether cross-attention layers themselves exhibit spiky vs balanced internal codes correlated with memorization.
- Empirical scope and reproducibility
- Broaden empirical validation across datasets (faces, medical, satellite, long-tailed data), resolutions, and larger modern models (e.g., SDXL, SD3, latest DiTs/Flow-Matching variants); standardize benchmarks for “memorized vs generalized” ground truth.
- Provide ablations on data imbalance, duplicates, and cleaning pipelines; quantify how curation practices shift representation statistics and memorization rates.
- Architectural identifiability of block structure
- Test whether the predicted block-wise structure of weights/representations can be reliably identified in deep networks given symmetries (permutation, scaling) and normalization; develop canonicalization procedures for comparisons.
- Early vs late timesteps
- Analyze representation structure and memorization propensity at early high-noise timesteps (large σ), not just low-noise regimes critical to sampling; identify if and when spikiness emerges during sampling.
- Regularization and mitigation
- Design and test training-time regularizers that directly penalize representation spikiness or encourage balanced codes, and quantify effects on fidelity/diversity/controllability.
- Investigate curriculum schedules over σ, λ, and data augmentation strength to prevent memorization while preserving controllability.
- Guidance and sampling strategies
- Study how classifier-free guidance, temperature, ancestral vs deterministic samplers, and step counts influence representation structure and memorization behavior.
- Theoretical links to attention and transformers
- Build an analogous theory for token-wise representations in DiTs/Transformers (self-attention dynamics, token mixing, residual pathways), and relate attention sparsity to memorization.
- Out-of-distribution and adversarial triggers
- Evaluate whether OOD inputs or adversarial prompts induce spiky codes and memorized outputs, and whether representation-based detectors remain reliable under such shifts.
- Practical deployment constraints
- Evaluate runtime/memory overheads of representation-based detection in large-scale systems; design lightweight proxies that require minimal hooks into the model.
- Generalization to other modalities
- Extend the analysis to text, audio, video, and multimodal diffusion; test whether “spiky vs balanced” representations characterize memorization in language and speech models as hypothesized.
- Formalization of hybrid regimes
- Provide quantitative models predicting the fraction of modes/samples that will be memorized under given duplication/imbalance statistics; validate on curated synthetic and real datasets.
- Coupling across layers
- Examine how early vs mid vs late layers contribute to spikiness; determine whether steering or detection should target specific layers for best effect and stability.
- Identifiability and uniqueness
- Address non-uniqueness due to rotational/permute symmetries (and W2≈W1 tying) in mapping representations to semantics; propose identifiable parameterizations or invariants for analysis.
Glossary
- Adam: A stochastic optimization algorithm that adapts learning rates per-parameter using estimates of first and second moments of gradients. "standard optimizers such as Adam \autocite{kingma2014adam} bias training toward \ell_\infty-smooth solutions of the DAE loss"
- AUROC: Area Under the Receiver Operating Characteristic; a metric summarizing binary classification performance across thresholds. "We report AUROC, true positive rate (TPR) at 1\% false positive rate, and runtime (s)."
- Block-wise structure: A weight or parameter organization where matrices are partitioned into contiguous blocks, each corresponding to data clusters or subproblems. "there exists a local minimizer with a block-wise structure"
- Cross-attention: An attention mechanism that conditions one sequence’s representations on another (e.g., text-to-image), used to align modalities. "locating anomaly in the cross-attention induced by memorized prompts"
- DDIM: Denoising Diffusion Implicit Models; a deterministic or semi-deterministic sampling variant for diffusion models. "the reverse process (e.g., DDIM~\autocite{song2020denoising}) removes noise to generate data:"
- Denoising Autoencoder (DAE): A neural autoencoder trained to reconstruct clean data from noisy inputs, often used to estimate score functions. "By investigating a two-layer ReLU denoising autoencoder (DAE)"
- Denoising score matching: A training objective where the model learns the gradient of the log-density (score) of noisy data. "the standard training objective (e.g., denoising score matching) admits a closed-form solution"
- DiT (Diffusion Transformers): Transformer-based architectures adapted to diffusion modeling for image generation. "including EDM~\autocite{karras2022elucidating}, Diffusion Transformers (DiT)~\autocite{peebles2023scalable}, and Stable Diffusion v1.4~\autocite{Rombach_2022_CVPR} (SD1.4)"
- EDM (Elucidated Diffusion Models): A family of diffusion models with improved training and sampling schemes for high-quality generation. "including EDM~\autocite{karras2022elucidating}"
- Empirical denoiser: The denoiser obtained by minimizing empirical loss over finite samples, often mapping to nearest training examples. "Minimizing this empirical loss leads to the nonparametric empirical denoiser"
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries; used to quantify matrix magnitude. "whose Frobenius norm is bounded by"
- Gram matrix: A matrix of inner products (X XT) capturing pairwise similarities and used in spectral analyses. "constructed from the Gram matrix "
- Incoherent: A condition indicating low alignment between vectors (e.g., cluster means), used to ensure separability. "If the component means are incoherent"
- Jacobian: The matrix of first-order partial derivatives of a vector-valued function, describing local linearization. "via an SVD analysis of denoiser Jacobians"
- KL divergence: Kullback–Leibler divergence; a measure of discrepancy between probability distributions. "we find that the KL divergence between the sampled and empirical distributions is bounded by"
- Measure concentration: Probabilistic phenomena where functions of many random variables sharply concentrate around expectations. "using standard measure concentration tools \autocite{Vershynin2018HDP}"
- Mixture of Gaussians (MoG): A probabilistic model where data are generated from a weighted sum of Gaussian components. "We assume a -component mixture of Gaussians (MoG) for the data distribution"
- Nonparametric: Methods that do not assume a fixed parametric form for the underlying distribution or function. "nonparametric empirical denoiser"
- Orthogonal matrix: A square matrix whose columns (and rows) are orthonormal; preserves norms and angles. " is an orthogonal matrix accounting for rotational symmetry."
- Overparameterized model: A model with more parameters (or capacity) than the number of training samples, often prone to memorization. "overparameterized with hidden units"
- Power method: An iterative algorithm to find the dominant eigenvector/eigenvalue of a matrix. "effectively act as a power method, recovering memorized training data"
- Principal components: Directions of maximum variance obtained via eigen-decomposition (PCA), used for dimensionality reduction. "captures the principal components of the empirical Gram matrix"
- Representation steering: Editing or controlling model outputs by manipulating internal feature representations. "a training-free editing technique that allows precise control via representation steering"
- Rotational symmetry: Invariance of a solution under rotations in feature space, often reflected by orthogonal transformations. "accounting for rotational symmetry"
- Score function: The gradient of the log-probability density; central to score-based diffusion models. "is the score function of the marginal distribution of the noisy sample at time ."
- SVD (Singular Value Decomposition): A factorization of a matrix into singular vectors and singular values, used for spectral analysis. "via an SVD analysis of denoiser Jacobians"
- Tweedie’s formula: A result linking the posterior mean under Gaussian noise to the score function, enabling denoising. "via Tweedie's formula \autocite{efron2011tweedie}"
- Under-parameterized model: A model with fewer parameters than samples, encouraging generalization by capturing shared statistics. "under-parameterized with "
- U-Net: A convolutional architecture with skip connections, widely used in diffusion models for image synthesis. "approximate U-Net performance"
- Weight decay: ℓ2 regularization on weights to prevent overfitting by penalizing large parameters. "trained with weight decay "
Practical Applications
Immediate Applications
Below are applications that can be deployed with today’s diffusion models and standard tooling, leveraging the paper’s representation-centric findings (spiky vs. balanced codes), the prompt-free memorization detector, and representation-space steering.
- Memorization risk auditing for generative AI deployments
- Sectors: software, media/creative, healthcare, education, legal/compliance, platforms
- Tools/products/workflows:
- An SDK and CLI to compute a “Memorization Risk Score” from intermediate activations (e.g., Std/variance of layer representations at low-noise timesteps)
- Batch auditors for pre-release model validation; CI checks in MLOps; inference-time gating that resamples or refuses outputs flagged as memorized
- Dashboards for risk trend monitoring across prompts, seeds, and time
- Assumptions/dependencies: Requires access to intermediate activations (or a thin wrapper around the U-Net/DiT backbone); thresholds must be calibrated per architecture/timestep; best sensitivity achieved at low-noise steps
- Privacy and copyright compliance checks in content pipelines
- Sectors: media/creative, platforms, legal/compliance, healthcare (PHI-sensitive imagery)
- Tools/products/workflows:
- Pre-publish checker that flags likely regurgitations; automated re-seeding or prompt perturbation on detection
- Vendor risk assessments for third-party generative services; attachments in model cards documenting memorization metrics
- Assumptions/dependencies: Regulatory acceptance requires transparent metrics and reproducibility; closed API models may need “feature-access” partnerships or local replicas
- Dataset curation: duplicate detection and balancing to avoid hybrid memorization
- Sectors: software (ML teams), data vendors, research
- Tools/products/workflows:
- Pretraining data QA to identify duplicates/sparse clusters that trigger spiky codes
- Re-clustering/oversampling/augmentation of underrepresented modes; deduplication workflows
- Assumptions/dependencies: Representations are most informative when taken from a trained or partially trained model; requires scalable data processing and approximate nearest neighbor indexing
- Training-time early warning for overfitting via representation spikiness
- Sectors: software (MLOps/ML engineering), academia
- Tools/products/workflows:
- Training hooks that log per-batch spikiness distributions; alerts when spiky codes rise
- Adaptive training: adjust weight decay, noise schedule, data augmentation, or stop early when memorization signals surge
- Assumptions/dependencies: Minimal training overhead to extract and aggregate statistics; hyperparameter policies must be pre-defined to react to alerts
- Prompt-free provenance triage for platform moderation
- Sectors: platforms, media, legal/compliance
- Tools/products/workflows:
- Server-side post-generation scan of representation spikiness; triage queue for suspected near-copies
- Evidence pack (activation signature, seed/noise logs) to support copyright dispute workflows
- Assumptions/dependencies: Must operate at platform scale with tight latency budgets; may require sampling at a specific diffusion step
- Training-free representation steering for creative editing
- Sectors: media/creative, advertising/branding, software (creative apps)
- Tools/products/workflows:
- “Concept vector bank” built from small reference sets (e.g., +old, +oil-painting); UI sliders to adjust steering strength a
- Plug-ins for Stable Diffusion/ComfyUI/AUTOMATIC1111 to enable feature-space edits without finetuning
- Assumptions/dependencies: Works best for generalized (balanced) representations; requires access to an encoder/decoder split and layer hooks; quality depends on curated exemplars for concept vectors
- Safe content steering (steer away from restricted attributes)
- Sectors: platform safety, policy/compliance, education
- Tools/products/workflows:
- Negative concept vectors (e.g., -violence, -nudity) applied during sampling to reduce policy-violating content
- Complementary to keyword-based prompt filters; auditable control logs
- Assumptions/dependencies: Requires carefully curated negative exemplars; risk of unintended attribute shifts if vectors are entangled
- “Originality indicators” for end-user apps
- Sectors: daily life (consumer creative tools), education
- Tools/products/workflows:
- On-device/desktop indicator that visualizes an originality score per image; suggests re-generation if high memorization risk
- Assumptions/dependencies: Lightweight inference or cached layer features; understandable UX to avoid over-warning and user fatigue
- Academic benchmarks and protocols for memorization vs. generalization
- Sectors: academia, standards organizations
- Tools/products/workflows:
- Standardized test suites with duplicated and balanced clusters; shared metrics (AUROC/TPR) on representation-based detectors
- Open leaderboards and reproducible evaluation scripts
- Assumptions/dependencies: Community agreement on splits, duplication levels, and scoring rules
- Sector-specific privacy audits (e.g., medical imaging, education datasets)
- Sectors: healthcare, education
- Tools/products/workflows:
- Periodic audits of diffusion models to ensure no identifiable regurgitation of sensitive examples
- Reports for IRBs/oversight boards; integration with dataset use agreements
- Assumptions/dependencies: Strict governance for handling sensitive data; requirement to run audits in secure enclaves
Long-Term Applications
These opportunities require further research, scaling, model/vendor cooperation, or standardization.
- Regulatory standards and certification for “memorization risk”
- Sectors: policy/regulation, legal/compliance, platforms
- Tools/products/workflows:
- NIST/ISO-like test protocols for generative models; third-party certification labels on model cards
- Procurement checklists for public-sector AI adoption
- Assumptions/dependencies: Regulator buy-in; standardized access to model internals or proxy tests for closed models; legal frameworks recognizing representation-based evidence
- Privacy-preserving training regimes guided by representation spikiness
- Sectors: software (ML), healthcare, finance, government
- Tools/products/workflows:
- Training objectives that penalize spiky activations; dynamic regularization/underparameterization to promote balanced representations
- Joint use with DP-SGD or unlearning methods; automated memorization monitors during training
- Assumptions/dependencies: Trade-offs between fidelity and privacy; rigorous proofs of privacy gains; integration with large-scale training stacks
- Systematic “Right to be Forgotten” via representation-space targeting
- Sectors: policy/compliance, platforms, software
- Tools/products/workflows:
- Identify and attenuate memorized columns/features linked to specific items; localized unlearning pipelines that reduce spikiness for targeted samples
- Assumptions/dependencies: Robust mapping between spiky features and specific training items; methods to unlearn without degrading unrelated capabilities
- Representation-API-first generative platforms
- Sectors: software (developer platforms), media/creative
- Tools/products/workflows:
- Public APIs exposing safe, constrained feature-space hooks for steering, concept composition, and diagnostics
- Libraries for composing multiple semantic vectors with guardrails and conflict resolution
- Assumptions/dependencies: Vendor willingness to expose internals; secure sandboxes to prevent misuse; model-agnostic abstractions
- Architecture and objective design for “balanced representation” by construction
- Sectors: software (foundation model R&D), academia
- Tools/products/workflows:
- Inductive biases (e.g., architectural constraints, regularizers) that avoid spiky codes; noise schedules optimized for generalization
- Training curricula that increase local data density in sparse modes
- Assumptions/dependencies: Extensive empirical validation across modalities; maintaining sample quality and diversity
- Cross-domain extension to LLMs and audio/video generators
- Sectors: software, platforms, media, education
- Tools/products/workflows:
- Adapt spikiness-based memorization detection to language/audio/video transformers; prompt-free leakage tests for text generation
- Feature-space steering for controllable narration/style in multimodal models
- Assumptions/dependencies: Identification of analogous representation layers; calibration across tokenization and temporal structures; evaluation datasets for leakage
- Data valuation and collection strategy informed by hybrid regime analysis
- Sectors: data vendors, enterprise ML, academia
- Tools/products/workflows:
- Tools to detect sparse (memorization-prone) regions; cost–benefit planners for targeted data collection to densify local statistics
- Assumptions/dependencies: Robust mapping from spikiness to data sparsity; budget-aware acquisition strategies
- Legal forensics and evidence standards for regurgitation disputes
- Sectors: legal/compliance, policy, platforms
- Tools/products/workflows:
- Forensic kits that package representation signatures, seeds, noise schedules, and matched outputs as court-ready evidence
- Assumptions/dependencies: Jurisprudence recognizing technical evidence; chain-of-custody for model and inference logs
- Safety controls via negative steering in high-stakes domains
- Sectors: education, public-sector communications, platforms
- Tools/products/workflows:
- “Safety vector” repositories maintained by standards bodies; certified steering policies integrated into public-facing generators
- Assumptions/dependencies: Governance for defining and updating safety concepts; auditability and public oversight
- Curriculum and public literacy tools on memorization vs. generalization
- Sectors: education, public policy
- Tools/products/workflows:
- Interactive demos showing spiky vs. balanced representations and their effects on originality and control
- Assumptions/dependencies: Simplified, safe models for classroom use; partnerships with educational institutions
Notes on feasibility and dependencies across applications
- Access to model internals: Many applications assume read/write access to intermediate representations; closed APIs may need vendor partnerships or local deployment.
- Timestep/noise schedule: Detection and steering are most reliable at low-noise timesteps; pipelines must standardize the schedule.
- Calibration: Model-specific thresholds for spikiness metrics are required; ideally packaged with per-model presets and validation scripts.
- Concept vector curation: Steering depends on curated positive/negative sets; building and maintaining vetted libraries is non-trivial.
- Distributional coverage: Balanced representations assume locally abundant data; sparse domains may require data collection or augmentation to avoid the hybrid regime.
- Governance and standards: Policy-facing use cases need consensus on tests, disclosures (model cards), and acceptable evidence for memorization.
Collections
Sign up for free to add this paper to one or more collections.

