- The paper replaces supervised 3D/4D datasets with video diffusion priors to generate a manifold of valid and diverse poses for auto-rigged 3D meshes.
- It employs a generative diffusion model with skeletal attention and per-node semantic features to accurately model and refine realistic pose configurations.
- The approach enables manifold-constrained editing and inverse kinematics, producing physically plausible joint configurations with significant computational efficiency.
Motivation and Problem Statement
Authoring plausible pose spaces for auto-rigged 3D meshes remains a pressing problem in graphics and vision. Kinematic rigs, despite providing low-dimensional interfaces for mesh articulation, lack inherent information about plausible joint configurations, making naive sampling or manual control liable to produce physically or anatomically implausible outputs. Conventional approaches require curated, artist-animated 4D datasets for learning or constraining the pose distribution. The "ViPS: Video-informed Pose Spaces for Auto-Rigged Meshes" (2604.17623) paper introduces a data- and supervision-efficient framework that leverages foundational video diffusion model priors to induce a manifold of valid, diverse, and controllable poses for arbitrary (auto-)rigged shapes, including out-of-distribution topologies.

Figure 1: ViPS workflow: auto-rigged meshes are mapped to a pose manifold capturing plausible, editable joint configurations, with support for manifold-constrained editing and pose-driven conditional video synthesis.
The technical contribution is the replacement of supervised 3D/4D datasets with video-based priors as a supervision source, enabling both universalization across species/forms and a sharp reduction in reliance on skilled artist involvement.
Data Pipeline: Distilling Video Priors into Rigged Pose Data
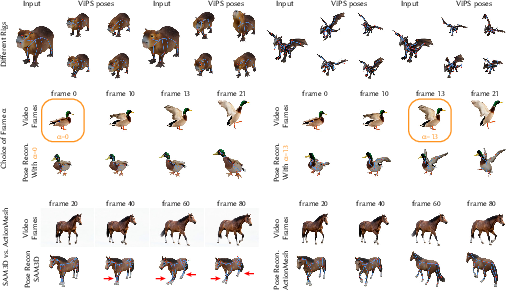
ViPS develops a novel data pipeline to transform unstructured video priors into explicit rigged pose data. For each target species or object:
- Prompted Image Synthesis: A visual LLM (VLM) generates high-quality single-object prompts, ensuring favorable conditions for downstream 3D reconstruction.
- Video Expansion: The still image is temporally expanded into a variety of plausible motions via a video diffusion model augmented with VLM-driven structured prompts, ensuring semantic motion diversity.
- 4D Reconstruction: Each video frame is reconstructed into a textured 3D mesh using SAM3D, and temporally matched using ActionMesh, resulting in a consistent topology across the sequence.
- Auto-Rigging and Pose Fitting: The mesh’s canonical frame is auto-rigged (RigAnything), and the skeletal pose per frame is recovered via rig optimization to match mesh deformations, constrained by geometric consistency and skeletal edge rigidity.

Figure 2: The ViPS pipeline generates diverse motion data from text-prompted images, expands into videos, reconstructs per-frame meshes, and fits consistent rigged skeletons for data generation.
This approach creates a 4D motion dataset spanning 127k plausible poses across 100+ species, extending pose space supervision beyond what curated assets provide.
Feed-forward Generative Manifold: Universal Pose Denoiser
ViPS formalizes the learned pose space as a conditional generative diffusion model over skeleton parameters, conditioned on mesh and rig features. Pose samples are generated by denoising iterative samples from an initial Gaussian. The key innovations in the architecture are:
- Semantic Node Features: Per-skeleton-node features are derived from mesh semantics (Diff3f, DINO-based descriptors) and skinning weights, obviating any requirement for explicit node labels or statistics at inference.
- Skeleton-awareness: The architecture uses skeletal attention mechanisms to directly model topological dependency across joints.
- Distributional Learning: Contrasts with previous methods focused on time-series or sequence generation, directly modeling the marginal pose distribution in normalized rig space.
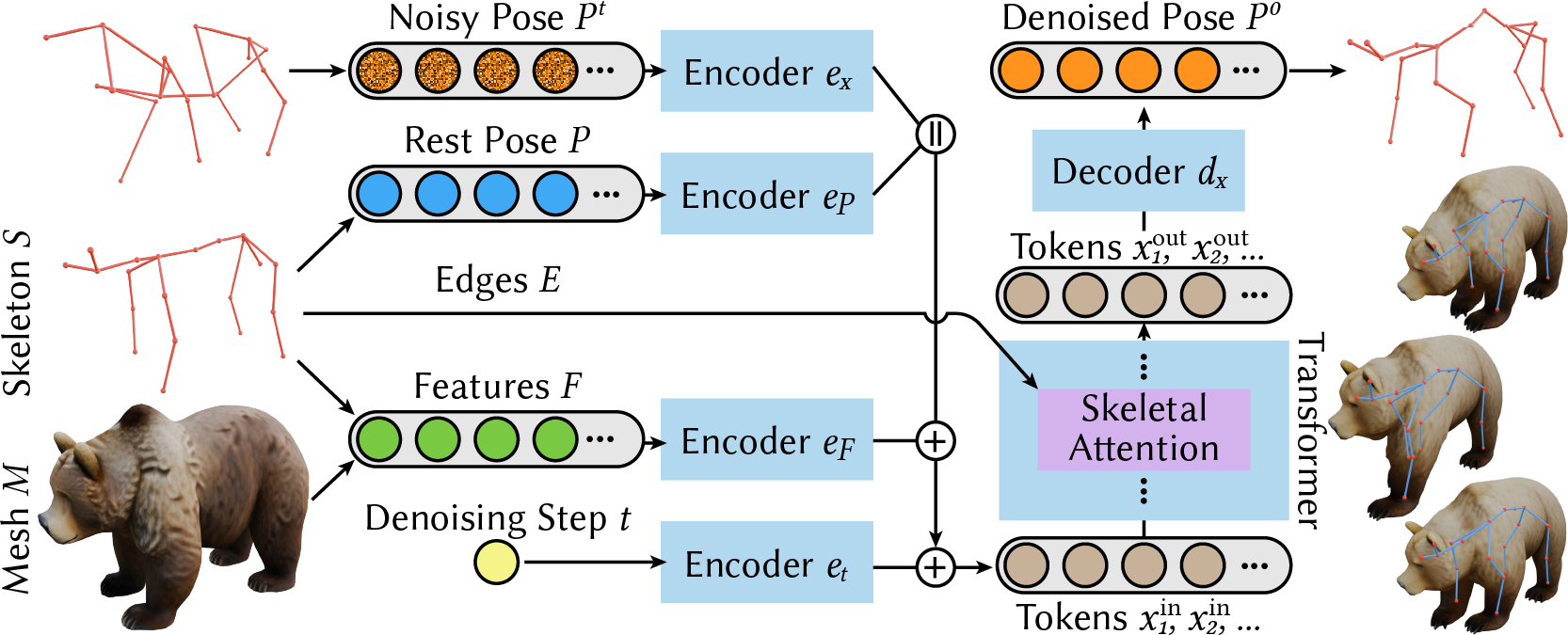
Figure 3: ViPS pose denoiser: Given mesh, skeleton, and reference pose, iterative denoising guided by semantic features produces plausible skeleton configurations, with topology-awareness via skeletal attention.
Empirically, ViPS denoiser not only matches but outperforms AnyTop-pose variants (which require node labels and statistics), even with oracle access, substantiating the advantages of per-node semantic embeddings derived directly from the geometry.

Figure 4: ViPS slightly exceeds oracle-enabled AnyTop in plausibility/diversity and significantly outperforms practical, label-free approximations.
Data Quality and Manifold Property Analysis
Quantitative and qualitative results demonstrate the superiority of the curated data and the resulting manifold:
- Sample Quality and Distribution: Random pose samples generated by ViPS are consistently plausible (i.e., free of anatomical or geometric artifacts) and display pose diversity matching or exceeding optimization-based baselines like Puppeteer, at a fraction of the compute.
- Pose Distribution Alignment: PCA analysis confirms ViPS-produced pose distributions track the ground truth Puppeteer distribution more closely than AnyTop-derived pose sets, without mode collapse or undue conservatism.

Figure 5: ViPS random pose samples generalize across species, matching expensive optimization methods and outperforming alternatives on diversity and plausibility.
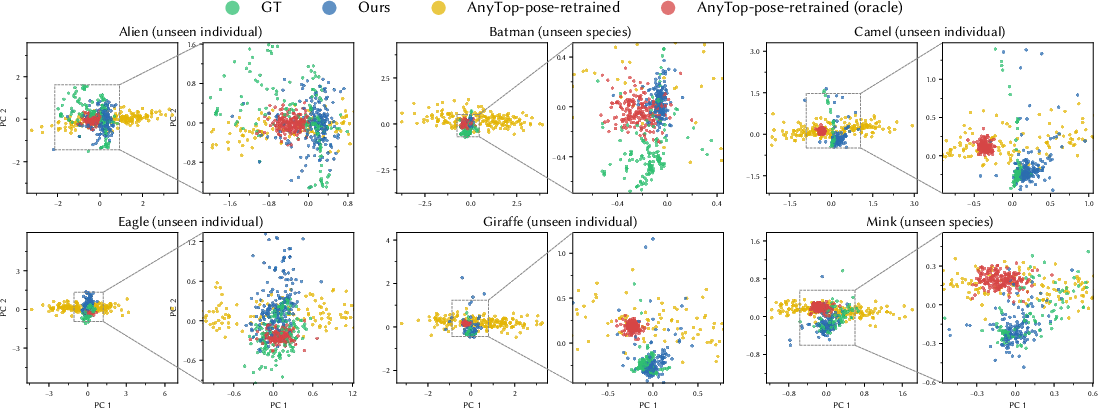
Figure 6: Visualization in PCA space shows the blue ViPS sample distribution nearly overlays the ground truth (green), while baselines (red/yellow) diverge.

Figure 7: The 4D reconstruction-based pipeline yields more accurate pose fitting than tracking-based Puppeteer, particularly for limb alignment, due to robust mesh correspondence.
Ablation studies show that:
Manifold-Constrained Editing and Applications
A critical practical outcome is that ViPS enables direct, semantically meaningful pose editing/inverse kinematics (IK) by projecting user edits onto the pose manifold. Sparse constraints (e.g., dragging a paw) are propagated over the skeleton, yielding valid, naturalistic configurations and eliminating classical IK artifacts such as bone hyperextension or self-intersection.

Figure 9: User handle edits are projected onto the plausible manifold, ensuring anatomical realism in the presence of sparse, underdetermined constraints.
Smooth pose trajectories can be constructed for keyframing and animation by interpolation within the manifold, yielding coherent motion sequences without blending artifacts. Furthermore, ViPS enables controllable video synthesis by using generated pose proxies as structural conditioning for video diffusion models, closing the loop between generative priors and structured control.
Comparative Metrics
ViPS outperforms AnyTop and sequence-extracting baselines on Fréchet Skeleton Distance (FSD) to Puppeteer samples, and achieves top Luce Spectral Ranking (LSR) user-study ranking, both on held-out in-domain individuals and zero-shot out-of-distribution species. Notably, this is accomplished with an order-of-magnitude speedup compared to optimization approaches (seconds versus tens of minutes per sample), and without privileged label/statistic input.
Limitations and Future Directions
- Rig Dependence: ViPS is bound to the structural adequacy of the input rig. Suboptimal autorigging can limit achievable pose diversity or induce artifacts.
- Prior Biases: The video diffusion prior encodes the distributional bias of the training corpus; rare motions (e.g., specialized non-human gaits, topology-changing events) may not be faithfully recovered.
- Rest-pose Sensitivity: Selection of the canonical mesh/pose, and initial alignment in video, impacts data fidelity and pose manifold coverage.
- Static Pose Limitation: Current modeling is restricted to the static pose manifold; temporal consistency and dynamical properties of motion families are not explicitly modeled.
Future work could involve joint rig and manifold discovery, direct modeling of pose sequence distributions for style/dynamics, integrating text-conditioned motion priors, and handling non-rigid topology (e.g., cloth, fluids, multi-part entities).
Conclusion
ViPS establishes a scalable paradigm for plausible pose manifold discovery, leveraging the semantic and temporal priors encoded in large video diffusion models and circumventing the need for expensive, artist-created 3D/4D datasets. The proposed universal pose denoiser, grounded in a robust video-informed data pipeline and advanced geometric/semantic conditioning, yields pose distributions and editing capabilities that match or surpass state-of-the-art alternatives in both accuracy and practical applicability. The implications span mesh animation, generative video synthesis, and potential applications in interactive modeling, vision-driven embodiment, and autonomous robotics, provided the underlying limitations are addressed in future work.