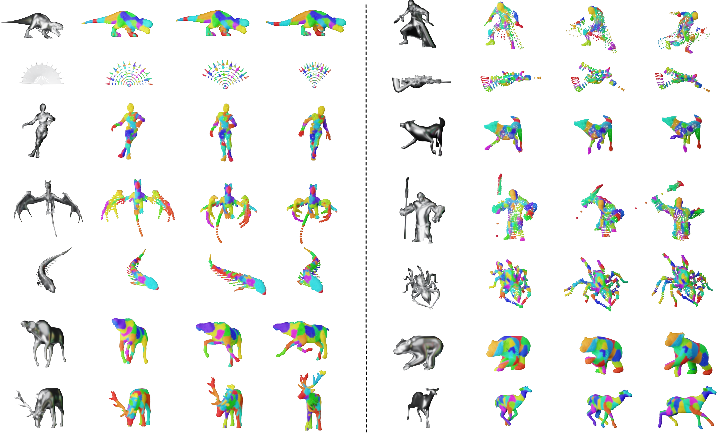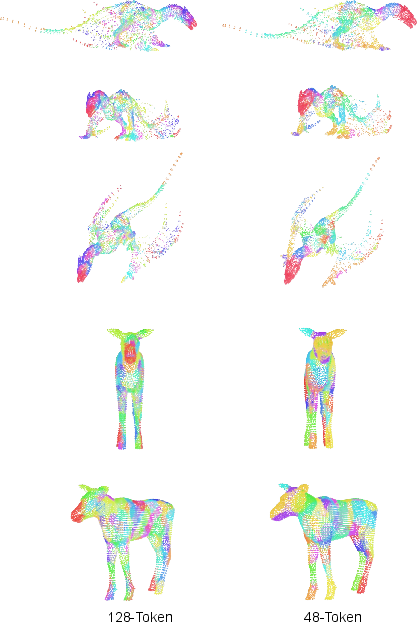- The paper introduces RigMo, a unified framework that learns rig structures and motion dynamics directly from mesh deformations without requiring manual rig annotations.
- It employs a topology-aware dual-path encoder and Gaussian-based skinning to achieve state-of-the-art reconstruction accuracy and efficient inference.
- The method generalizes across diverse shapes and animations, enabling scalable, controllable, and interpretable generative animation for various applications.
RigMo: Unified Rig and Motion Learning for Generative Animation
Introduction and Motivation
Generative animation in graphics hinges on the interplay between static rigging structures (defining permissible deformations) and dynamic motion trajectories (articulating temporal evolution). Existing paradigms silo these two aspects: auto-rigging systems depend on artist-annotated skeletons and skinning weights, while motion generators operate under the assumption of fixed ground-truth rigs. This separation curtails scalability, interpretability, and cross-category generalization, especially for objects lacking established rigging conventions. Moreover, state-of-the-art motion generators in vertex or Gaussian primitive space yield deformations without structurally meaningful parameterization, impeding control and reusability in downstream tasks.
RigMo (2601.06378) introduces a fundamentally unified framework capable of learning both rig structures and motion dynamics directly from raw mesh deformations, bypassing all rig annotation requirements. The approach is entirely self-supervised and generalizes seamlessly across diverse morphologies and motion patterns.
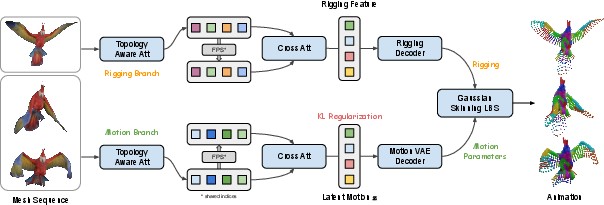
Figure 1: RigMo-VAE architecture disentangles rig structure and motion dynamics from mesh trajectories into interpretable latent factors and Gaussian bone regions.
RigMo-VAE: Architecture and Representation
RigMo employs a topology-aware dual-path encoder to factorize mesh sequence input into two complementary latent spaces:
- Rig latent: Encodes static geometry, decodes to explicit Gaussian bones and geodesic-aware skinning weights. Each bone parametrizes its region's influence via spatial coordinates, anisotropic scaling, and rotation quaternion, defining a soft ellipsoid in vertex space.
- Motion latent: Encodes per-frame vertex displacements, decodes to temporal SE(3) bone transformations (local and root). These together enable full articulation and motion synthesis.
The decoder reconstructs the mesh by applying Gaussian-based LBS, leveraging geodesic-aware refinement to respect mesh topology and suppress erroneous cross-region influences. Key design elements include sparse anchor sampling for bone tokens and efficient attention mechanisms to preserve spatial coherence and minimize token cardinality without loss of rigging fidelity.
RigMo Motion DiT: Structure-Aware Motion Synthesis
Building upon the learned rig-motion latents, RigMo introduces a Motion DiT—a diffusion transformer conditioned on static rigging tokens and global priors, operating in the motion-latent space. It generates temporally plausible motion trajectories by denoising motion latent tokens subjected to frame-wise sparsity and mask scheduling. This process produces bone transformations and vertex sequences via Gaussian skinning, enabling conditional, controllable long-horizon animation synthesis.
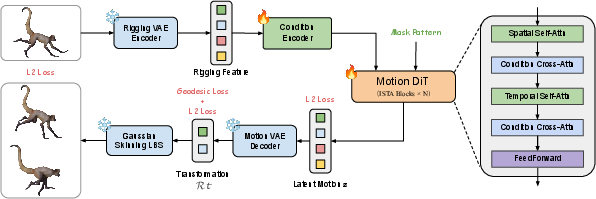
Figure 2: Motion DiT schematic—conditional transformer with cross-attention on anchor and global tokens enabling denoising in RigMo’s motion-latent space.
Experimental Evaluation
Datasets and Topology Normalization
RigMo’s robustness is evaluated on three datasets: DeformingThings4D (organic non-rigid shapes), Objaverse-XL (diverse synthetic objects), and TrueBones (articulated animations). All meshes are normalized to a common vertex resolution using topology-preserving farthest point sampling and geodesic neighborhood maintenance, ensuring architecture resolution-agnosticism.
Quantitative Results: Rigging and Reconstruction
RigMo demonstrates substantial improvements over baselines:
Comparative and Qualitative Analysis
RigMo’s learned rigs are robust and transferable—visually and kinetically—against methods such as UniRig and MagicArticulate. Qualitative comparisons reveal that static geometry-based rigging often collapses under dynamic motion, whereas RigMo produces anatomically coherent bones and stable skinning with no ground-truth supervision required.

Figure 4: RigMo’s rigging generalizes robustly across motions and categories; baseline methods fail under animation, yielding severe artifacts.
Diagnostics and Ablation
Implications and Future Directions
RigMo represents a paradigm shift: joint rig-motion learning unlocks scalable, structure-aware animation modeling for any deformable object, nullifying reliance on category-specific rig annotations. The Gaussian bone abstraction and latent motion synthesis enable explicit, physically plausible, and manipulable asset generation, interfacing directly with downstream tasks (e.g., motion editing, interpolation, cross-object retargeting).
Applications can be extended to human, animal, and non-humanoid shape animation in AR/VR, film, and gaming. With end-to-end differentiability and feed-forward inference, RigMo can be integrated with generative 4D pipelines or unified with conditional controls, such as text-driven animation or physics-guided synthesis. Future investigation may include:
- Differentiable physical priors in rig/motion factorization (e.g., elasticity/material modeling)
- Mesh topology self-discovery for rig-vs-nonrig separation
- Domain-adaptive rig learning for procedural asset creation
- Extension toward multi-agent or crowd animation with shared motion-latent spaces
Conclusion
RigMo advances the field of generative animation through explicit, unified rig and motion learning, eschewing annotation dependencies and demonstrating state-of-the-art accuracy, efficiency, and generalization. The framework establishes a basis for scalable, controllable, and interpretable dynamic 3D modeling, with implications for practical graphics workflows and theoretical exploration of motion/rig-factorized representations in generative AI.