ViSA: 3D-Aware Video Shading for Real-Time Upper-Body Avatar Creation (2512.07720v1)
Abstract: Generating high-fidelity upper-body 3D avatars from one-shot input image remains a significant challenge. Current 3D avatar generation methods, which rely on large reconstruction models, are fast and capable of producing stable body structures, but they often suffer from artifacts such as blurry textures and stiff, unnatural motion. In contrast, generative video models show promising performance by synthesizing photorealistic and dynamic results, but they frequently struggle with unstable behavior, including body structural errors and identity drift. To address these limitations, we propose a novel approach that combines the strengths of both paradigms. Our framework employs a 3D reconstruction model to provide robust structural and appearance priors, which in turn guides a real-time autoregressive video diffusion model for rendering. This process enables the model to synthesize high-frequency, photorealistic details and fluid dynamics in real time, effectively reducing texture blur and motion stiffness while preventing the structural inconsistencies common in video generation methods. By uniting the geometric stability of 3D reconstruction with the generative capabilities of video models, our method produces high-fidelity digital avatars with realistic appearance and dynamic, temporally coherent motion. Experiments demonstrate that our approach significantly reduces artifacts and achieves substantial improvements in visual quality over leading methods, providing a robust and efficient solution for real-time applications such as gaming and virtual reality. Project page: https://lhyfst.github.io/visa
Sponsor






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “ViSA: 3D-Aware Video Shading for Real-Time Upper-Body Avatar Creation”
What is this paper about?
This paper introduces ViSA, a new way to create a realistic, moving digital character (an “avatar”) of a person’s upper body using just a single photo. The goal is to make the avatar look like the person, move naturally, and run fast enough for real-time use (like live video calls, games, or VR).
What questions are the authors trying to answer?
The authors focus on three simple questions:
- How can we turn one picture of a person into a 3D avatar that keeps their identity (their exact face and clothing details) without looking blurry?
- How can we make that avatar move smoothly and realistically in a video without glitches or weird body shapes?
- Can we make this fast enough to run in real time on common hardware?
How does their method work?
Think of ViSA as a two-part system: a “builder” and a “painter.”
- The “builder” makes a stable 3D version of the person from the single photo. This gives a reliable structure, like a digital mannequin that looks like the person.
- The “painter” is a smart video model that renders (colors and shades) each video frame so it looks photorealistic and moves fluidly, like a film.
Here’s the approach in everyday terms:
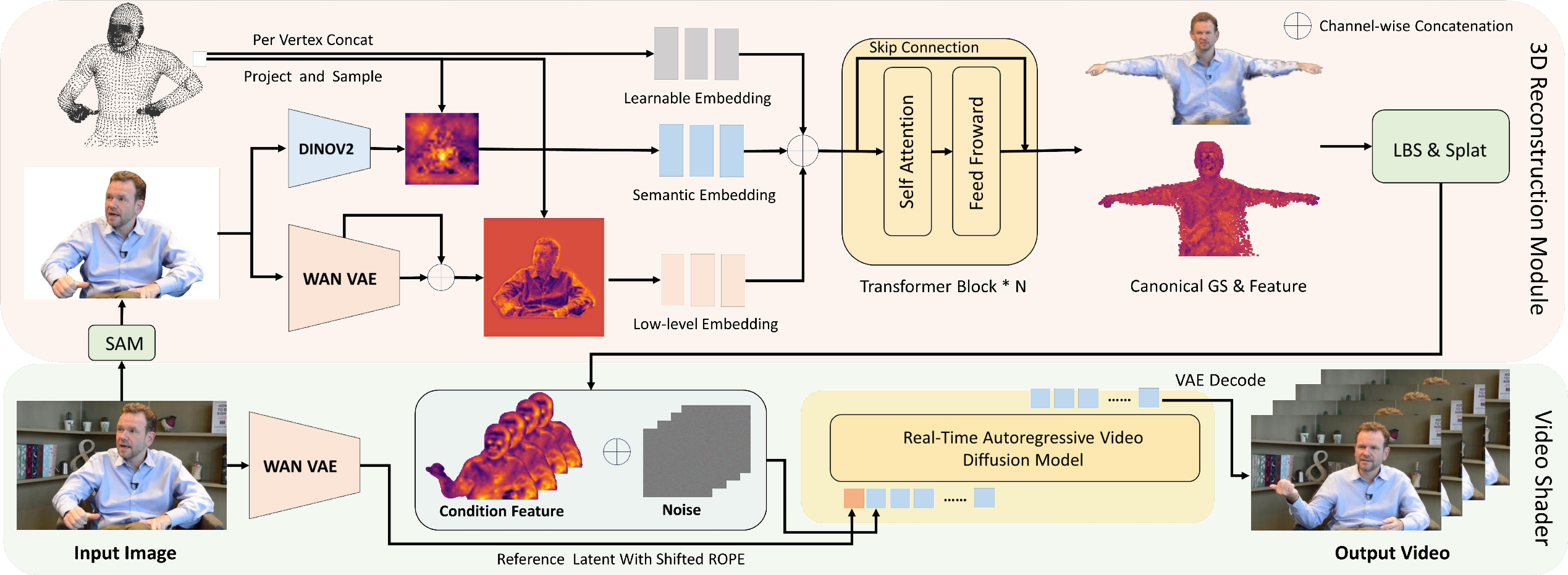
Step 1: Reconstruct a 3D avatar (the “builder”)
- The system looks at the input photo and extracts different types of clues:
- High-level meaning (what’s a face, hair, clothing) using a vision model.
- Fine details (like fabric textures and small features) using a model trained to keep image details.
- A general human “template” (a standard digital body called SMPL-X, and a detailed head model called FLAME), which acts like a well-made mannequin for posing.
- It “lifts” the 2D clues from the photo into 3D space using the mannequin as a guide.
- It represents the person with many tiny, soft 3D blobs (called “3D Gaussian splats”)—imagine building a sculpture from thousands of small, colored cotton puffs. This is a fast way to render realistic 3D scenes.
- A small transformer network refines this 3D model so it matches the person’s look and can be posed (moved) for animation.
Why this helps: The 3D “builder” gives solid structure and keeps the person’s identity consistent, which prevents weird body shapes and face changes later.
Step 2: Render videos in real time (the “painter”)
- The “painter” is a fast video generator (an autoregressive diffusion model). “Autoregressive” means it makes the video one frame at a time, reusing what it just created—like writing a story one sentence after the last.
- Instead of vague hints like stick-figure keypoints, the painter is given dense, 3D-aware features from the builder. This is like giving the painter a precise 3D blueprint for every frame.
- It also uses the original photo as a constant identity anchor (like keeping a reference portrait on the desk). Internally, it stores “memory” from this photo so the face and clothes remain consistent across the video.
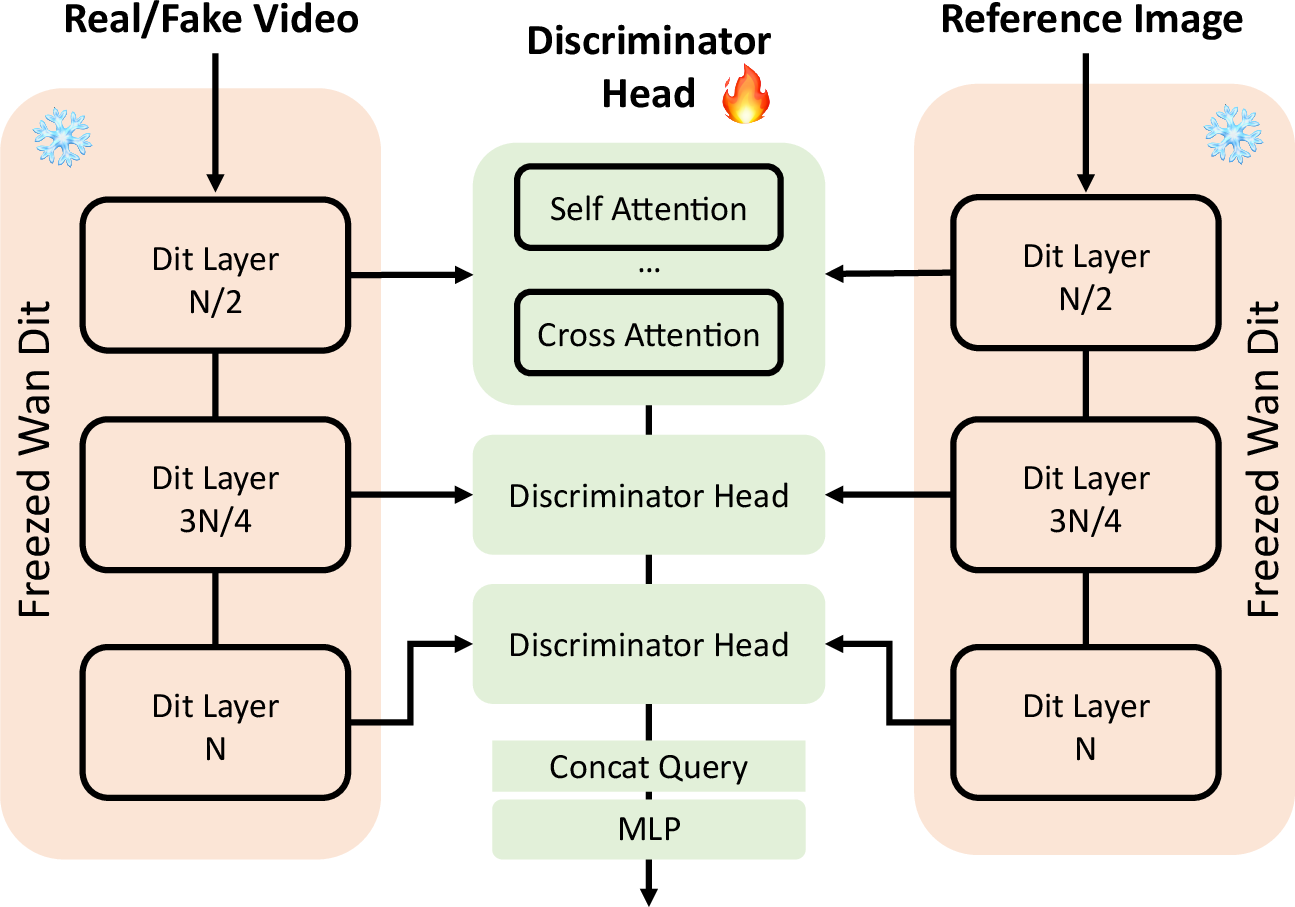
- Training trick for sharpness: When you fine-tune a fast video model, results can get blurry. The authors add an “adversarial critic”—think of a strict art teacher who has seen many real videos—to push the model to keep videos crisp and realistic. This “critic” uses a big, pretrained video model to judge quality.
- Training schedule: First, train both parts together on short clips to make them cooperate. Then, freeze the builder and train the painter longer so it becomes great at smooth, long videos.
Key technical ideas in plain words:
- Diffusion model: a method that starts with noisy images and learns to remove the noise step by step to reveal a clean picture.
- Autoregressive: generates frame 1, then uses that to help generate frame 2, and so on.
- 3D Gaussian splats: a fast way to draw 3D scenes with lots of tiny fuzzy balls that carry color and size.
- Identity drift: when a character’s face slowly changes into a different person across frames. ViSA is designed to avoid this.
What did they find?
Here are the main results and why they matter:
- Better visual quality: ViSA’s videos are sharper, with clearer facial features, hair, and clothing textures than previous methods.
- More stable bodies and faces: It avoids twisted limbs or faces changing over time (no identity drift), thanks to the 3D structure and the reference-photo memory.
- Natural motion: Movements look less stiff than pure 3D methods and more reliable than pure video methods.
- Real-time speed: It can generate around 15 frames per second on a single high-end GPU—fast enough for interactive use.
- Strong numbers: On common quality metrics (like PSNR, SSIM, LPIPS) and identity tests, ViSA beats popular alternatives, including video-only methods (which can be unstable and slow) and 3D-only methods (which can look stiff or bland).
Why this is important: It shows you can get the best of both worlds—3D stability and video realism—while staying fast.
What does this mean for the future?
This research can make digital characters much more usable in:
- Video calls and streaming with personalized avatars that look like you and move smoothly.
- Games and VR, where you can be “present” as yourself with a single photo.
- Virtual presenters, teachers, or influencers created quickly and controlled live.
It also gives a blueprint for mixing 3D structure with fast video generation—useful beyond avatars, like in filmmaking or virtual try-on. In the future, this could expand to full-body avatars, work with different clothes and lighting, connect to speech or hand gestures, and run on more devices.
Overall, ViSA shows a practical, fast, and high-quality path to turn a single picture into a lifelike, controllable, upper-body avatar video.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of missing pieces, uncertainties, and unexplored aspects that future work could address to make the approach more robust, generalizable, and practically deployable.
- Upper-body focus and limited motion diversity:
- The pipeline targets upper-body avatars; capabilities and failure modes for full-body animation (legs, feet, complex locomotion) are untested.
- Robustness to extreme poses and body orientations (e.g., wide yaw/turning, crouching, occlusions) is not evaluated.
- Camera motion and novel-view control:
- The method does not demonstrate controllable camera motion or novel-view synthesis; how 3D-aware features interact with viewpoint changes is unclear.
- It remains unknown whether the video shader maintains identity and geometry under simulated or real camera motion (pan/tilt/zoom).
- Real-time constraints beyond A100:
- Reported speed (≈15 FPS) is on A100; performance, latency, and memory footprint on consumer GPUs, laptops, or mobile hardware are not analyzed.
- End-to-end latency accounting for pose tracking, conditioning preparation, and streaming I/O is not reported.
- Dependence on external pose/parameter estimation:
- The pipeline assumes access to SMPL-X/FLAME parameters at inference; a real-time, integrated tracking solution (body, face, hands) is not provided or evaluated.
- Sensitivity to pose estimation errors and how inaccuracies propagate through the 3D-aware conditioning to the video shader are not quantified.
- Single-image reconstruction ambiguities:
- Backside geometry and textures (self-occluded regions) from a single view remain ill-posed; no explicit strategy or evaluation for resolving unseen regions is included.
- Failure cases with heavy occlusions (e.g., hands covering face, props, long hair) and complex apparel (e.g., loose clothing, flowing garments) are not studied.
- Expressiveness of cloth and hair dynamics:
- The approach does not explicitly model physically plausible cloth/hair dynamics; whether the generative shader produces temporally consistent and physically plausible non-rigid motion is unknown.
- Identity preservation beyond facial features:
- Identity is evaluated via ArcFace (face region), leaving clothing texture fidelity, hairstyle, accessories, and body-shape consistency unmeasured.
- Long-term identity drift over multi-minute sequences is not quantified.
- Temporal stability metrics and long-sequence behavior:
- No standard video metrics (e.g., FVD, tLPIPS, flicker measures) are reported; error accumulation in autoregressive rollouts over long durations is not addressed.
- Robustness to temporal artifacts (ghosting, jitter, hallucinated details) under extended generation remains untested.
- Audio-driven lip-sync and affect:
- Given speaking-focused data, the method does not integrate or evaluate audio-conditioned lip motions, speech sync accuracy, or affective gesture control.
- Background generation and control:
- While backgrounds are mentioned, there is no explicit control mechanism or evaluation for background realism, stability, or safety (e.g., scene consistency, content filtering).
- Compositing with user-provided backgrounds and multi-layer editing is unexplored.
- Lighting and shading control:
- “3D-aware video shading” is not physically-based; no explicit estimation or control of lighting conditions, relighting, or environment illumination is provided or evaluated.
- Generalization to multi-person interactions:
- The system assumes a single subject; multi-person scenes, occlusions, and interpersonal interactions are not supported or evaluated.
- Dataset bias, ethics, and misuse:
- Bias analysis (demographics, skin tones, age groups, attire) of Speaker-5M-derived training set is absent.
- Ethical considerations (consent, identity cloning, deepfake misuse), content safety, and watermarking/detection mechanisms are not discussed.
- Reproducibility and dependency on proprietary backbones:
- The discriminator leverages a frozen WAN backbone; feasibility with open-source or smaller discriminators, and the effect of backbone choice, are not studied.
- Detailed hyperparameters for the adversarial training (e.g., regularization terms, stability tricks) and ablations are limited; reproducibility may be constrained.
- Adversarial Distribution Preservation (ADP) analysis:
- ADP’s theoretical grounding and generalization across different diffusion backbones are not explored.
- Quantitative gains from ADP beyond qualitative examples (e.g., improvements in LPIPS/SSIM/FVD) are not reported; comparisons with alternative GAN objectives or feature-level perceptual discriminators are missing.
- Component-wise ablations and contributions:
- Limited ablations on reference-image KV cache conditioning (including shifted RoPE variants), DINOv2 vs. VAE feature contributions, and the reconstruction transformer capacity.
- The tiny decoder substitution during training is claimed to have “minimal performance degradation,” but quantitative impact on supervision and final quality is not provided.
- Scalability of the reconstruction stage:
- The number of Gaussians, memory usage, and trade-offs between Gaussian count vs. visual fidelity vs. speed are not documented.
- How reconstruction errors affect downstream video rendering quality and temporal stability is not quantified.
- Control interfaces and user interaction:
- Beyond SMPL-X pose sequences, interactive controls for expressions, gaze, gestures, and high-level commands (text/audio) are not supported or evaluated.
- Tools for editing identity attributes (e.g., changing clothes or hairstyle) or live-driven performance capture are not integrated.
- Robustness to domain shift:
- Performance on out-of-domain content (non-speaking videos, sports, extreme lighting, stylized inputs, synthetic or artistic portraits) is unknown.
- Cross-dataset generalization and zero-shot robustness are not assessed.
- Evaluation breadth:
- No user studies or perceptual ratings to validate realism and preference against baselines.
- Safety and failure case documentation (when/why the model breaks) is lacking.
Addressing these gaps would improve the model’s reliability, controllability, fairness, and deployability across real-world applications such as live streaming, VR, and gaming.
Glossary
- 3D-aware features: Dense per-pixel feature maps encoding geometry/appearance from a 3D reconstruction used to guide rendering. "3D-aware features rendered from our reconstruction model."
- 3D Gaussian Splatting (GS): A 3D representation that uses many Gaussian primitives with attributes for fast, photorealistic rendering. "the 3D Gaussian Splatting (GS) representation"
- Adversarial Distribution Preservation loss: An adversarial objective to keep a finetuned diffusion model within the distribution of real videos, improving sharpness and fidelity. "The effects of Adversarial Distribution Preservation loss."
- ArcFace: A face-recognition model producing embeddings for measuring identity similarity. "ArcFace features"
- Autoregressive video diffusion model: A diffusion-based generator that synthesizes video frame-by-frame using causal conditioning on previous frames. "a real-time autoregressive video diffusion model"
- Canonical space: A fixed reference pose/coordinate system where an avatar is reconstructed before animation. "predefined canonical space"
- Causal autoregressive structure: A model design that enforces temporal causality by conditioning only on past frames. "its causal autoregressive structure offers an elegant solution."
- Causal video diffusion model: A diffusion model whose temporal attention/conditioning respects causality for sequential generation. "few-step causal video diffusion model"
- DensePose: A method mapping image pixels to 3D human surface coordinates for dense pose control. "such as keypoints~\cite{hu2024animate}, DensePose~\cite{guler2018densepose, xu2024magicanimate}, and rendered SMPL meshes~\cite{zhu2024champ}"
- Denoising objective: The diffusion training loss that predicts clean data (or noise) from noised inputs; naïve use can cause blur in finetuning. "naively finetuning the distilled model with a standard denoising objective leads to blurry outputs"
- DINOv2: A self-supervised vision transformer used to extract high-level semantic image features. "We employ a pretrained DINOv2 encoder"
- FLAME: A parametric 3D head/face model for expressive facial geometry and animation. "parametric head model FLAME"
- GAGATracker: A tracker/estimator used to obtain initial FLAME (facial) parameters from videos. "We employ Multi-HMR~\cite{multi-hmr2024} and GAGATracker~\cite{chu2024gagavatar} to obtain initial estimates for SMPL-X and FLAME parameters"
- Identity drift: Undesired change of a generated subject’s identity over time in video synthesis. "including body structural errors and identity drift."
- Identity Preservation Score (IPS-cross): A metric computing average face-embedding similarity between the reference image and all generated frames in cross-reenactment. "we assess identity consistency using the Identity Preservation Score (IPS-cross), defined as the average cosine similarity between ArcFace features of the reference image and all frames in the generated video."
- Identity Preservation Score (IPS-self): A metric computing face-embedding similarity between generated frames and their ground-truth counterparts in self-reenactment. "Additionally, we measure Identity Preservation Score (IPS-self) by computing the cosine distance between ArcFace features extracted from the face regions of the generated and their corresponding original frames."
- Inverse texture mapping: A rendering technique projecting appearance from images into canonical surface/texture space. "leverages inverse texture mapping and projection sampling"
- Key-Value (KV) cache: Stored attention keys/values reused across steps/frames to condition generation efficiently. "We perform a single forward pass to compute its Key-Value (KV) cache within the model's attention layers."
- LPIPS: A learned perceptual metric that correlates with human judgments of visual similarity. "we compute PSNR, SSIM, and LPIPS"
- Multi-HMR: A model for multi-view/temporal human mesh recovery used to estimate SMPL-X body parameters. "We employ Multi-HMR~\cite{multi-hmr2024} and GAGATracker~\cite{chu2024gagavatar} to obtain initial estimates for SMPL-X and FLAME parameters"
- Neural Radiance Fields: Neural volumetric representations modeling view-dependent appearance for novel view synthesis. "Neural Radiance Fields or 3D Gaussian Splatting"
- Neural shader: A learned renderer that maps conditioning features to photorealistic images, akin to a shader. "we repurpose it as a powerful neural shader"
- Projection sampling: Sampling-based technique to project/aggregate features between image and 3D domains. "leverages inverse texture mapping and projection sampling"
- R1, R2 regularization: Gradient-penalty regularizers for stabilizing adversarial training. "We also adopt the approximate R1, R2 regularization"
- Relativistic loss: A GAN loss that compares real and fake logits relatively to stabilize training. "we employ a relativistic loss"
- Rotary Position Embedding (RoPE): A positional encoding method (with a shifted variant) enabling spatially coherent attention under motion. "shifted Rotary Position Embedding (RoPE)"
- Self-rollout: Training where the model conditions on its own generated frames to reduce exposure bias. "with a self-rollout training strategy."
- SMPL: A skinned parametric human body model controlling pose and shape for rendering/generation. "rendered SMPL meshes"
- SMPL-X: An expressive SMPL variant including hands and face for full-body articulation. "SMPL-X parameters"
- Speaker-5M: A large-scale dataset of human speaking videos used for training/curation. "We construct our training dataset from Speaker-5M"
- Variational Autoencoder (VAE): A generative encoder–decoder used to map images/videos to a latent space for diffusion models. "the pretrained VAE encoder from a video diffusion model"
Practical Applications
Overview
ViSA presents a two-stage system for creating photorealistic, identity-consistent, and temporally coherent upper-body avatars in real time from a single reference image. It combines: (1) a lightweight one-shot 3D reconstruction module (predicting 3D Gaussian avatars and dense 3D-aware features from DINOv2, VAE multi-scale features, and SMPL-X/FLAME priors), and (2) a few-step autoregressive video diffusion “neural shader” conditioned on those 3D-aware features and a cached reference frame. A novel adversarial distribution preservation (ADP) loss preserves sharpness during finetuning. The system runs at about 15 FPS on an A100 and significantly improves identity stability and detail retention over prior work.
Below are practical, real-world applications derived from these findings, methods, and innovations, grouped into immediate and long-term opportunities.
Immediate Applications
The following applications can be deployed now or with modest engineering, leveraging the paper’s real-time, one-shot upper-body avatar pipeline.
- Bold, photoreal VTubing and live streaming avatars [Industry; Daily life]
- Description: Streamers can go live with a realistic upper-body avatar created from one selfie, preserving identity under expressive movements while maintaining temporal coherence.
- Tools/Workflow: OBS/Streamlabs plugin; webcam or phone-based pose/face trackers driving SMPL-X/FLAME parameters; cloud or local GPU backend; ViSA SDK for real-time rendering overlay.
- Assumptions/Dependencies: Requires a capable GPU (e.g., A100-class cloud GPU for 15 FPS, or desktop RTX with potential optimization); robust live pose/expression tracking; content policies for disclosure and moderation.
- Privacy-preserving telepresence in video conferencing [Industry; Daily life]
- Description: Replace a participant’s live camera feed with a photorealistic avatar that preserves identity but protects raw video (de-identification via avatar rendering, background control).
- Tools/Workflow: Zoom/Teams plugin; real-time SMPL-X/FLAME parameter stream from webcam; ViSA neural shader to video feed; optional background synthesis.
- Assumptions/Dependencies: Corporate IT acceptance; latency <200 ms end-to-end; user consent and clear disclosure; licensing for SMPL-X/FLAME models.
- Virtual presenters for broadcast, marketing, and commerce [Industry]
- Description: Generate real-time photoreal hosts/spokespersons for product demos, live shopping, news recaps, and support videos from a single image.
- Tools/Workflow: Studio controller feeding scripted motion/expression tracks; ViSA runtime to synthesize presenter video; integration into broadcast switchers or e-commerce platforms.
- Assumptions/Dependencies: Legal approvals for likeness use; brand safety and watermarking; controlled lighting/storyboards to minimize visual drift.
- Customer-service and kiosk agents [Industry]
- Description: Interactive avatars for banks/airports/retail kiosks with consistent identity, lip and upper-body expressiveness, and controlled backgrounds.
- Tools/Workflow: ASR/TTS + dialog manager; audio-to-expression model driving FLAME/SMPL-X; ViSA real-time renderer to screen or web canvas; edge GPU (or cloud).
- Assumptions/Dependencies: Audio-to-expression driver not included in ViSA but readily integrated; strong connectivity or edge compute; privacy compliance.
- Selfie-to-NPC/character creation for prototyping in games [Industry; Software]
- Description: Rapidly turn user selfies into in-game upper-body digital doubles for prototypes, cutscenes, or social hubs with expressive control.
- Tools/Workflow: Unity/Unreal plugin; import selfie; ViSA reconstructs canonical avatar and renders sequences for cutscenes; live motion capture for previews.
- Assumptions/Dependencies: Upper-body focus; integration with engine pipelines; licensing for pretrained backbones (WAN/Self-forcing).
- Real-time dubbing/localization overlays for content previews [Industry; Media]
- Description: For quick localization previews, render the performer’s avatar synchronized to target language audio and expression curves, avoiding time-consuming reshoots.
- Tools/Workflow: Audio-to-phoneme/expression tool (e.g., viseme predictor) driving FLAME; ViSA for identity-consistent rendering; quick iteration loop.
- Assumptions/Dependencies: High-quality audio-to-expression model; editorial acceptance for “preview” quality; IP rights for likeness.
- Synthetic data generation for human-centric CV tasks [Academia; Industry]
- Description: Generate long, identity-stable, expression-rich upper-body video datasets to train/evaluate face/pose/expression models and trackers.
- Tools/Workflow: Batch driving of SMPL-X/FLAME sequences; ViSA renderer producing labeled videos; paired ground-truth parameters; dataset curation scripts.
- Assumptions/Dependencies: Domain-gap considerations; ethical dataset governance; compute for large-scale rendering.
- Research testbed for few-step diffusion finetuning and neural shading [Academia]
- Description: Use the ADP loss and 3D-aware conditioning as a reproducible testbed for studying distribution preservation, causal autoregressive decoding, and neural rendering.
- Tools/Workflow: Open-source ViSA checkpoints; ablation runners comparing denoising vs. ADP; evaluation on identity preservation and temporal metrics.
- Assumptions/Dependencies: Access to WAN/Self-forcing backbones and VAE; reproducible training scripts; dataset licensing.
- Avatar-mediated telehealth triage and counseling (privacy-first) [Industry; Daily life]
- Description: For intake or counseling sessions where video is sensitive, use a photoreal avatar that preserves expression while obscuring the real feed.
- Tools/Workflow: Clinic portal with avatar toggle; live expression/pose capture; ViSA rendering with secure streaming; audit logs.
- Assumptions/Dependencies: Regulatory compliance (HIPAA/GDPR); clear patient consent; clinical validation for communication quality.
- On-the-fly video content cleanup and background control [Industry; Daily life]
- Description: Generate an avatar feed with stable backgrounds (avoid clutter), useful for remote work recordings or learning content without green screens.
- Tools/Workflow: Desktop recorder (OBS/Camtasia) ingesting ViSA output; background style presets; pose/expression driver from webcam.
- Assumptions/Dependencies: Lighting invariance and camera angle consistency; user training for best results.
Long-Term Applications
These applications require further research, scaling, or development (e.g., mobile deployment, full-body fidelity, broader safety measures, or standardization).
- Full-body, multi-person, and multi-view telepresence for AR/VR [Industry; Academia; Robotics]
- Description: Extend ViSA beyond upper body to full-body, multi-user sessions with consistent occlusions and wide-angle turns in head-mounted or mixed reality.
- Tools/Workflow: Multi-sensor/IMU/VR trackers driving SMPL-X; multi-view neural shading; spatial anchors in AR; adaptive ADP for varied scenes.
- Assumptions/Dependencies: Improved body/hand fidelity and cloth dynamics; better long-horizon temporal control; user comfort in HMDs.
- On-device/mobile/WebGPU real-time avatars [Industry; Daily life]
- Description: Run avatars locally on laptops/phones/AR glasses for low-latency calls and privacy.
- Tools/Workflow: Model compression (quantization, distillation), efficient VAEs, hardware acceleration (NPUs/WebGPU), streaming-friendly pipelines.
- Assumptions/Dependencies: Significant optimization beyond A100-class performance; energy constraints; variable camera quality.
- End-to-end speech-driven avatars with nuanced affect [Industry; Academia]
- Description: Seamlessly map audio to FLAME/SMPL-X parameters and render expressive avatars (news, education, customer support).
- Tools/Workflow: Joint training of audio-to-expression with ViSA; prosody control; controllable emotion conditioning; safety filters.
- Assumptions/Dependencies: Robust audio-to-expression models; cross-lingual generalization; safeguards against deceptive speech synthesis.
- Digital retail try-on for accessories and apparel [Industry]
- Description: Realistic upper-body try-on for glasses, earrings, hats, and tops with view consistency and identity preservation.
- Tools/Workflow: Asset-fitting pipeline; physics- or data-driven cloth/occlusion models; ViSA rendering under varied poses; lighting estimation.
- Assumptions/Dependencies: Non-rigid clothing dynamics and self-occlusion handling; product 3D assets; accurate size/fit inference.
- Scalable NPC generation and performance capture for AAA titles [Industry; Software]
- Description: Large-scale generation of distinct, expressive NPCs from single images, with live performance capture for in-game events.
- Tools/Workflow: Asset pipeline integration; batch avatarization; in-engine ViSA-like neural shaders; LOD management; behavior systems.
- Assumptions/Dependencies: Runtime efficiency on consoles/PC; robust content moderation; IP/law compliance for source images.
- Studio-grade previsualization and “AI shading” for production [Industry; Media]
- Description: Replace early previz renders with fast, photoreal “neural shaders” guided by coarse 3D and storyboards, accelerating iterations.
- Tools/Workflow: DCC plugins (Maya, Blender, Unreal); scene blocking to SMPL-X/props; ViSA-like shading passes; editorial review tools.
- Assumptions/Dependencies: Multi-character occlusion and lighting control; legal frameworks for synthetic likeness; color pipeline integration.
- Telemedicine and remote care with clinically validated avatars [Industry; Policy]
- Description: Physician–patient interaction via avatars that preserve nonverbal cues while protecting privacy.
- Tools/Workflow: Medical-grade capture modules; calibration for clinical signals; EHR integration; audit and consent UIs; provenance watermarking.
- Assumptions/Dependencies: Clinical trials validating communication efficacy; regulatory approvals; robust identity verification.
- Education: personalized, culturally adaptive tutors at scale [Industry; Academia; Policy]
- Description: Learner-specific tutors that maintain identity consistency and expressiveness across languages and cultural contexts.
- Tools/Workflow: Pedagogical policy engine; multilingual audio-to-expression; safety filters; fairness auditing; LMS integration.
- Assumptions/Dependencies: Bias mitigation; privacy safeguards for minors; teacher-of-record policies and disclosure.
- Content provenance, watermarking, and disclosure standards [Policy; Industry]
- Description: Standardize disclosure/watermarking of avatar-generated media and verification protocols for platforms and regulators.
- Tools/Workflow: Built-in cryptographic provenance (C2PA-style), invisible watermarking of ViSA outputs, platform-level detection APIs, audit logs.
- Assumptions/Dependencies: Cross-industry adoption; updates to platform ToS; interoperability with other generative systems.
- Generalized “neural video shader” for other domains [Academia; Industry]
- Description: Apply the 3D-aware conditioning + ADP finetuning recipe to other real-time rendering tasks (robots with face screens, sports analysis, teleoperation UIs).
- Tools/Workflow: Domain-specific 3D priors and render cues; causal AR diffusion backbones; task-aligned ADP critics; latency-aware pipelines.
- Assumptions/Dependencies: Availability of structured 3D priors; domain data for finetuning; real-time constraints.
Cross-Cutting Assumptions and Dependencies
- Hardware: Real-time 15 FPS demonstrated on an A100; consumer deployment needs optimization (quantization, pruning, efficient VAEs/UNets, or cloud offload).
- Drivers: Live control requires reliable SMPL-X/FLAME parameter estimation from webcams, IMUs, or audio (external modules not in ViSA).
- Licenses and IP: SMPL-X/FLAME licenses, pretrained backbones (WAN/Self-forcing/VAEs), and dataset rights must be secured.
- Safety and Governance: Explicit user consent, disclosure/watermarking of synthetic feeds, identity verification to mitigate impersonation, and moderation tools are recommended.
- Scope: Current system is upper-body focused; complex non-rigid clothing and wide-angle/full-body motions may require further research.
- Networking and Latency: For remote/cloud setups, ensure low-latency streaming and fallbacks to maintain interaction quality.
Collections
Sign up for free to add this paper to one or more collections.