- The paper demonstrates that phase-wise RoPE scaling with logit-based KD enables small transformers to acquire long-context abilities from short-context data.
- The paper reveals that structured, dimension-specific adaptations in hidden states are crucial for effectively encoding long-range positional information.
- The paper underscores the efficiency of knowledge distillation as a low-resource alternative to direct long-context pre-training, significantly boosting retrieval benchmarks.
Positional Knowledge Distillation for Long-Context Transformers: Mechanisms and Implications
Introduction and Motivation
The paper "Short Data, Long Context: Distilling Positional Knowledge in Transformers" (2604.06070) addresses a central bottleneck in transformer-based language modeling: extending the context window for efficient long-context processing without incurring prohibitive computational or data curation costs. The core challenge arises from both the quadratic memory footprint of self-attention relative to context length and the scarcity of large-scale, high-quality long-sequence datasets. The study focuses on the implicit transfer of long-context capabilities to student models using knowledge distillation (KD) from long-context-capable teacher models, even when trained exclusively on short-context data.
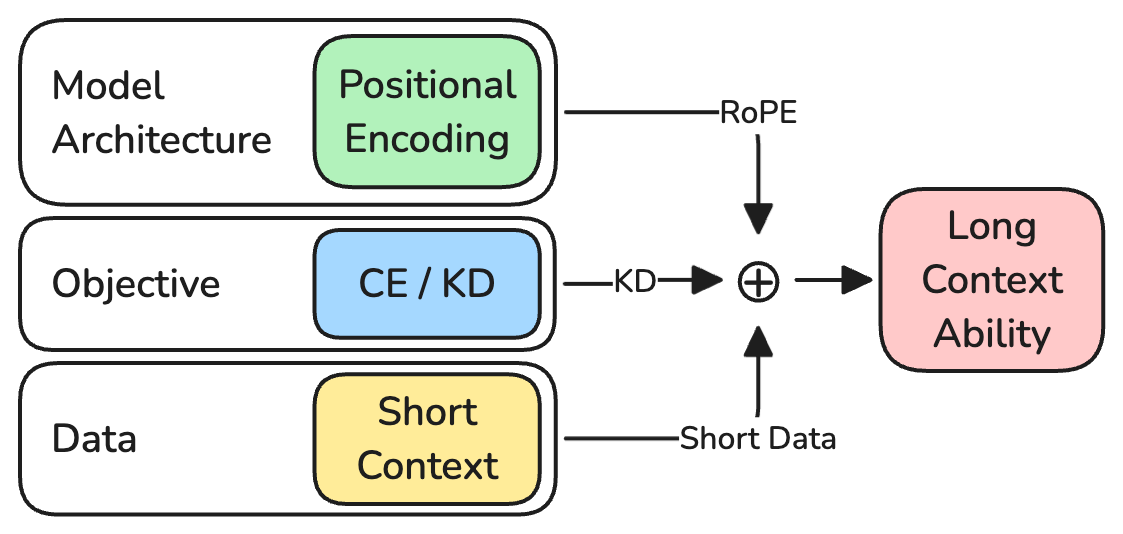
Figure 1: The three axes explored: RoPE embeddings, KD objective, and short-context-packed training data. Combined, these enable long-context abilities in the student.
Rotary Position Embeddings and Context Scaling
RoPE Fundamentals and Frequency Spectrum
RoPE encodes absolute position by rotating hidden representations in two-dimensional subspaces with frequency components determined by the base parameter θ. The frequency spectrum, defined as θi=θ−2i/d, allows fast-rotating dimensions to distinguish short-range positions and slow-rotating ones to encode long-range information. The design of θ is thus crucial for context window extension: too small, and rotational frequencies wrap, inducing ambiguity; too large, and position resolution is lost.
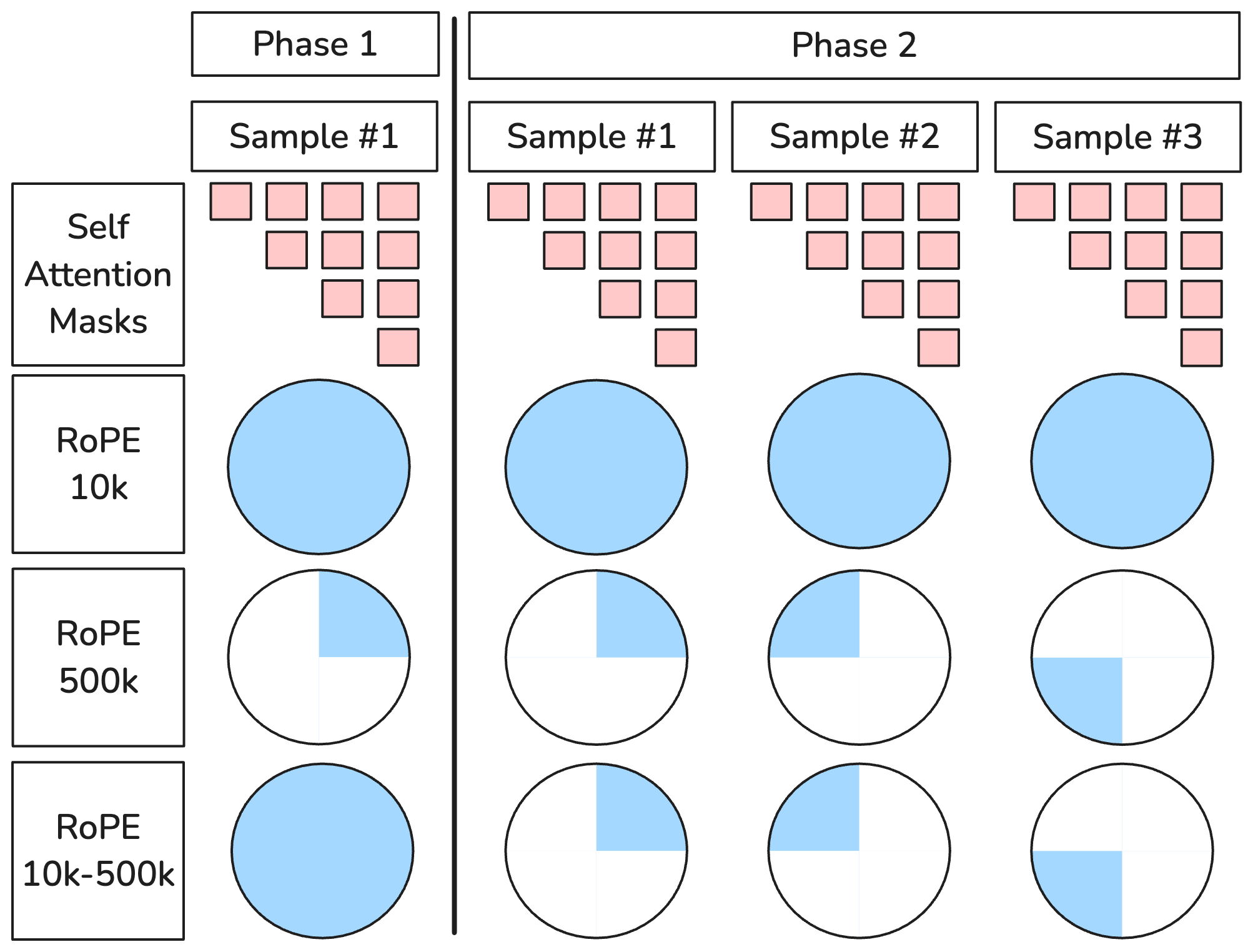
Figure 2: Scaled and unscaled RoPE θ across short (Phase 1) and long (Phase 2) pre-training phases.
Context Extension via RoPE Scaling
The empirical study systematically compares three strategies for RoPE context scaling in the KD setup: (1) fixed teacher-aligned θ (500k), (2) fixed literature-aligned θ (10k), and (3) phase-wise scaling (10k → 500k). The phase-wise strategy leverages finer positional resolution for short sequences in the early phase and expands the spectrum for long-range distinction in the later phase where the training context extends to 128k tokens. The results statistically favor phase-wise scaling, with strong performance on long-context retrieval benchmarks, confirming prior theoretical intuition about maximizing spectral utilization at each pre-training phase.
Mechanisms of Implicit Positional Knowledge Transfer
Isolating RoPE-Induced Positional Effects
The authors engineer an experimental setup where a fixed 2,048-token segment is repeated 64 times, filling the context to 128k tokens. This controlled scenario ensures that any difference in internal representations is attributable to RoPE-induced perturbations rather than semantic or syntactic variance.

Figure 3: Visual schematic of the experiment: Repeating fixed blocks fills the context and isolates positional effects.
Propagation and Amplification in the Model Stack
Analysis reveals that, prior to RoPE application, the model's hidden states are strictly position-invariant across all repetitions. Post-RoPE, even for identical inputs, each segment's embedded representation diverges with non-monotonic oscillatory structure reflecting the interaction of RoPE's multi-frequency sinusoidal rotations. Cosine similarity between positions drops sharply after RoPE and is progressively amplified through the stack of transformer layers, as shown by per-layer similarity profiles.
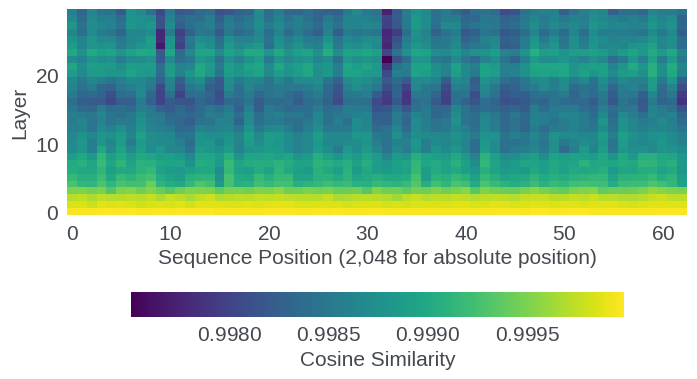
Figure 4: Per-layer cosine similarity—RoPE-induced divergence amplifies through successive layers.
This strongly suggests that RoPE's positional information is not merely a shallow perturbation but propagates nontrivially through feedforward and attention computations. At the output layer, the distribution over the vocabulary (token ranking and probability mass) is consistently modulated by sequence position, even absent cross-document attention. These shifts in output logits constitute the "signal" by which KD can induce long-range positional competence in the student model.
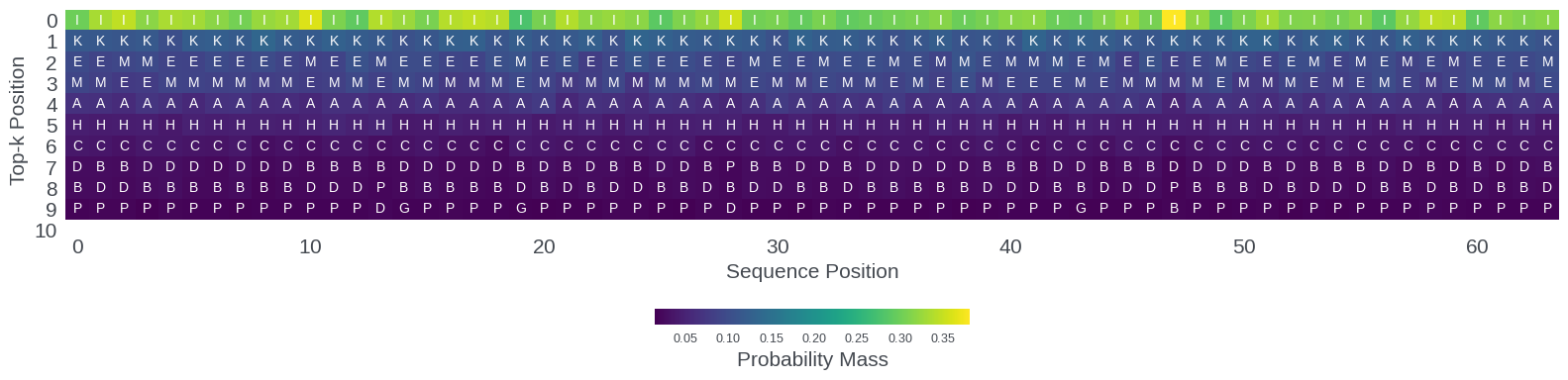
Figure 5: Output layer top-10 token rankings and probability mass, showing systematic positional modulation.
Evolution of Internal Representations During Long-Context KD
Structured, Dimension-Specific Parameter Updates
Comparing checkpoints before and after long-context training, the most significant adaptation occurs within specific higher-index hidden-state dimensions, corresponding to low-frequency (long-range) RoPE components. This finding is robust across both shallow and deep layers: not all dimensions or sequence positions are equivalently updated, but instead, structured spans of the representation space targeted for long-range encoding undergo pronounced changes.
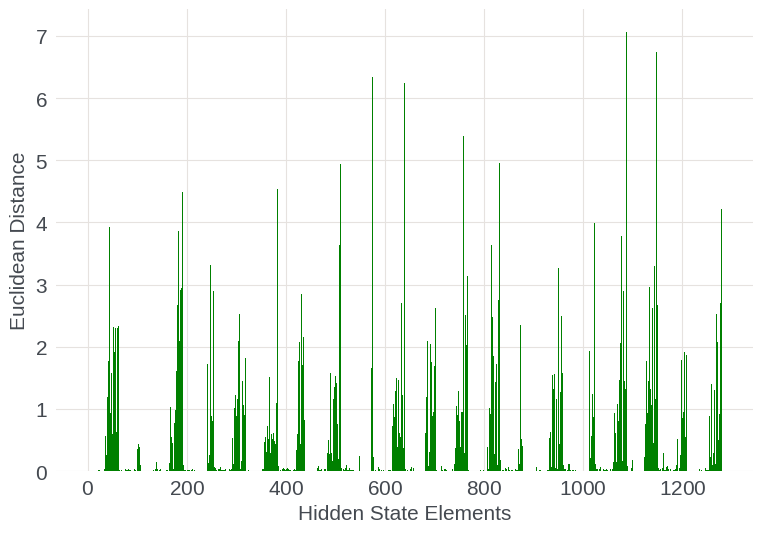
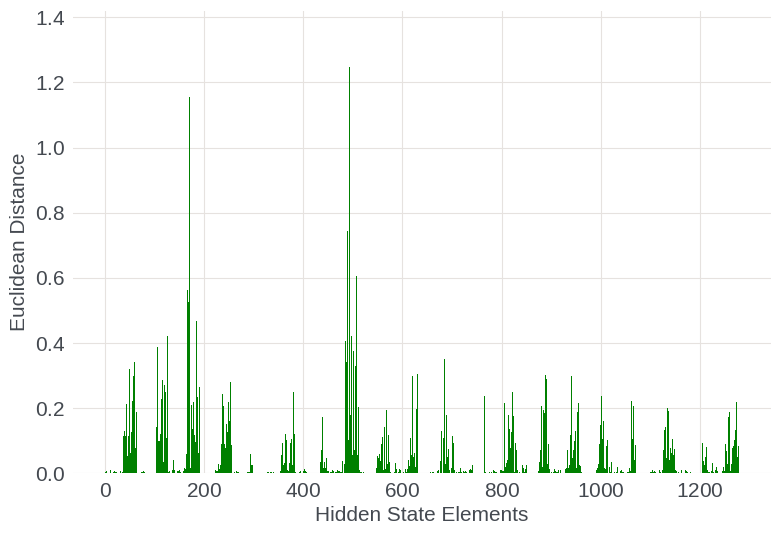
Figure 6: Per-dimension Euclidean distance between pre- and post-extension model states for early (top) and late (bottom) layers, illustrating localized adaptation.
Conversely, sequence position does not systematically encode for greater adaptation at later positions: the model does not simply memorize long-range offsets but refines a subset of features associated with position encoding, indicating generalization rather than rote memorization.
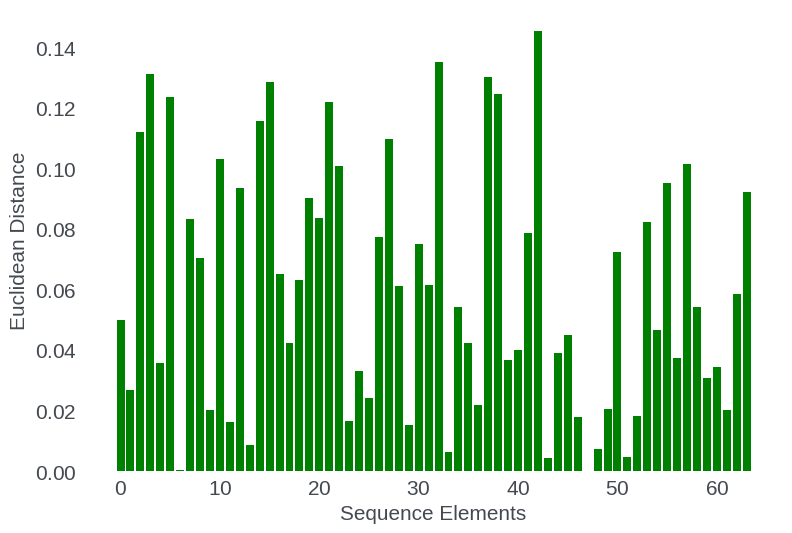
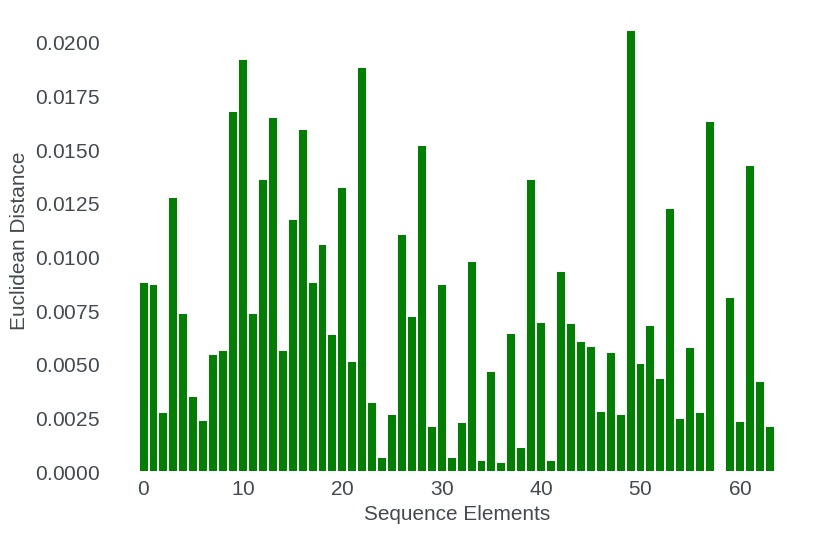
Figure 7: Per-position Euclidean distance between pre- and post-extension hidden states; adaptation is not position-specific.
Theoretical and Practical Implications
These findings support a mechanistic interpretation: the teacher's output logits, implicitly modulated by cross-layer, RoPE-induced positional trajectories, serve as a dense target for student learning—enabling long-range, position-aware modeling from short-context data alone. This positions logit-based KD, when coupled with careful RoPE scaling, as a low-resource, data-efficient alternative to direct long-context pre-training for compact models.
Numerical results on retrieval benchmarks show a clear KD-over-cross-entropy (CE) gap for all RoPE configurations, with maximal performance under phase-wise scaling. Notably, student models distilled on packed short-context data alone acquire long-context retrieval accuracies unattainable by CE-trained counterparts. This claim is well supported by head-to-head performance across multiple context extension strategies and loss functions.
Strong Claims:
- Phase-wise RoPE scaling is the most effective for long-context ability via KD.
- Logit-based KD enables the transfer of long-range positional knowledge, even if the student never observes such dependencies directly in pre-training data.
- Student adaptation during context extension is localized to specific hidden-state dimensions corresponding to long-range frequency bands.
Limitations and Open Questions
The scope of generalization is circumscribed by the single teacher-student pairing (Llama-4 Scout → 1.1B RoPE-only student) and synthetic retrieval tasks as evaluation. While the data conclusively demonstrate implicit positional knowledge transfer in this setup, the results may not automatically extend to other architectures, scales, or real-world tasks such as long-form QA or summarization. Moreover, causality (i.e., KD as the sole source of long-context capability) is not definitively isolated due to the absence of teacher ablations with position-invariant outputs or short-context-only teachers.
Conclusion
This paper provides the first systematic, mechanistic account of how knowledge distillation with logit targets can endow small transformer-based LLMs with long-context retrieval abilities using only short-context, packed training data, when positional encodings (RoPE) are properly manipulated. The study highlights the importance of phase-wise spectral scaling, tracks the propagation and amplification of RoPE perturbations, and uncovers structured, dimension-specific model adaptations underlying successful context extension. These insights inform the principled design of on-device, data- and compute-efficient long-context models and motivate future examination of this phenomenon across architectures, loss functions, and deployment domains.