UniMesh: Unifying 3D Mesh Understanding and Generation
Abstract: Recent advances in 3D vision have led to specialized models for either 3D understanding (e.g., shape classification, segmentation, reconstruction) or 3D generation (e.g., synthesis, completion, and editing). However, these tasks are often tackled in isolation, resulting in fragmented architectures and representations that hinder knowledge transfer and holistic scene modeling. To address these challenges, we propose UniMesh, a unified framework that jointly learns 3D generation and understanding within a single architecture. First, we introduce a novel Mesh Head that acts as a cross model interface, bridging diffusion based image generation with implicit shape decoders. Second, we develop Chain of Mesh (CoM), a geometric instantiation of iterative reasoning that enables user driven semantic mesh editing through a closed loop latent, prompting, and re generation cycle. Third, we incorporate a self reflection mechanism based on an Actor Evaluator Self reflection triad to diagnose and correct failures in high level tasks like 3D captioning. Experimental results demonstrate that UniMesh not only achieves competitive performance on standard benchmarks but also unlocks novel capabilities in iterative editing and mutual enhancement between generation and understanding. Code: https://github.com/AIGeeksGroup/UniMesh. Website: https://aigeeksgroup.github.io/UniMesh.

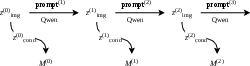
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces UniMesh, a single system that can both understand 3D objects (like recognizing parts and describing them) and create or edit them (like building a 3D model from a text prompt or changing its color). Instead of using separate tools for “making” and “thinking,” UniMesh connects them so they can help each other.
What questions did the researchers ask?
The team focused on three simple questions:
- Can we build one system that both understands 3D objects and generates them, instead of keeping those skills separate?
- Can we make 3D editing as easy as telling the computer what to change (for example, “make the car red” or “add wings”), and have it refine the model step by step?
- Can the system judge its own mistakes (like a teacher giving feedback) and use that to improve its descriptions and understanding of 3D objects?
How did they do it? (Explained in everyday language)
To connect 3D understanding and 3D creation, they designed three key parts:
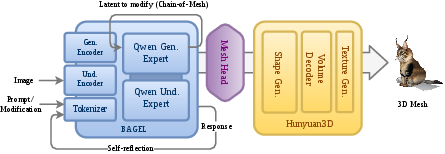
- Mesh Head (the “translator”): Think of two people speaking different languages—one is great at making images, and the other is great at building 3D shapes. The Mesh Head is like a translator that turns the “hidden code” (called a latent) from the image-making side into instructions the 3D shape builder understands. This avoids saving and reloading images in between, keeping details crisp.
- Chain-of-Mesh (the “edit loop”): Imagine you 3D-print a model, look at it, then tell the printer, “Make it blue,” and it updates the model without starting over. Chain-of-Mesh works like that: it reuses the original hidden code plus your new instruction (like “add a crown”), then regenerates an updated 3D mesh. You can repeat this as many times as you want—no retraining, just smart re-prompting.
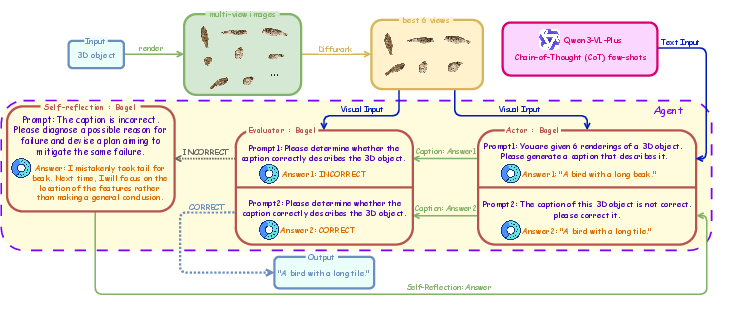
- Self-Reflection (the “coach”): For tasks like writing a caption about a 3D object, the system plays three roles: Actor (writes the caption), Evaluator (checks if it’s good), and Self-Reflection (explains what went wrong and how to fix it). The Actor reads this advice and tries again, improving the caption over a few rounds—similar to revising an essay with teacher feedback.
How they trained and tested the system (in simple terms):
- They used a big 3D dataset (Cap3D) to teach the Mesh Head translator to map image information directly into 3D shape instructions.
- They chose the best viewpoints of each 3D object (so the system sees the most helpful angles).
- They added realistic shadows and backgrounds to match the “look” of images produced by modern image generators.
- To judge text-to-3D results, they compared how well the generated 3D models matched the input text using standard measures of text–image similarity.
Helpful definitions:
- 3D mesh: a wireframe “cage” of triangles that forms the surface of a 3D object.
- Latent: a compressed, hidden code the model uses internally to represent an image or idea.
- Diffusion model: a kind of image generator that starts from noise and “denoises” it into a picture that matches a prompt.
What did they find?
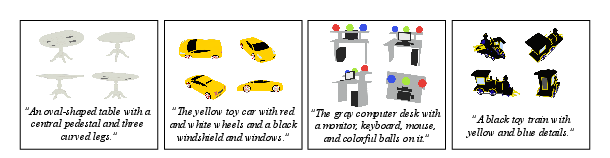
- Strong text-to-3D generation: UniMesh produced 3D models that matched input text very well, scoring as good as or better than many recent methods on standard benchmarks.
- Easy, language-driven editing: With Chain-of-Mesh, users could edit a 3D mesh by simply giving new text instructions—like changing colors, adding accessories, or tweaking structure—without retraining the model. The system kept the original shape consistent while applying the requested changes.
- Better 3D understanding through self-feedback: The self-reflection loop improved tasks like 3D captioning. By checking and correcting itself, the system produced more accurate, more detailed descriptions over time.
- Mutual boost between “making” and “thinking”: Because generation and understanding live in the same system, they help each other: understanding guides better edits, and high-quality generations give clearer material to understand.
Why this matters:
- It shows that one unified setup can handle both creation and comprehension of 3D objects, unlocking features (like iterative text edits) that are awkward or impossible with separate, one-pass tools.
Why does this matter, and what’s the impact?
- Easier creativity and design: Artists, game developers, and students could sketch 3D ideas with simple text and tweak them quickly (“shorter legs,” “glossy paint,” “add a logo”), speeding up prototyping and learning.
- Smarter 3D assistants: A system that can build, describe, and then improve itself based on feedback is closer to a true 3D “assistant” that understands your intent and refines results.
- A step toward holistic 3D AI: UniMesh offers a path where 3D creation and 3D understanding are not separate silos. This could lead to better AR/VR content, educational tools, robotics (grasping shapes and parts), and more.
Limitations and future work:
- The current feedback relies heavily on 2D views and image-based reasoning rather than full 3D-native understanding.
- The “coach” part can sometimes misjudge. Future versions aim to reason more directly from 3D data and improve the evaluation loop.
In short, UniMesh is like a 3D lab partner that can build objects, explain them, take your suggestions, and try again—bringing us closer to 3D tools that are both creative and thoughtful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed to guide follow-up research:
- Lack of 3D-native latent coupling: Mesh Head maps 2D image latents to a 3D shape conditioner; no direct 3D-aware latent or unified cross-modal latent space is learned or evaluated.
- Single-view supervision: Mesh Head is trained from the “best” single view; no multi-view or view-aggregated training to improve back-side geometry, occlusion handling, or view-invariance.
- Geometry-centric evaluation is missing: No reporting of Chamfer/F-score/normal consistency/mesh manifoldness/watertightness/self-intersections; geometric fidelity and mesh quality are not quantified.
- Materials and relightability: The pipeline does not provide a unified mapping to PBR materials or evaluate texture/material quality, relightability, or normal/roughness consistency across views.
- Editing metrics and benchmarks: CoM is only qualitatively demonstrated; there is no quantitative evaluation of edit success, attribute preservation, identity consistency, locality of edits, or cumulative drift across edit iterations.
- State consistency in CoM: The loop uses a “reference image latent” rather than features derived from the current mesh; it is unclear how edited mesh state is fed back (without re-rendering/re-encoding), raising desynchronization risks across iterations.
- Localized/part-aware control: No mechanism for spatially targeted or part-specific edits (masks, part IDs, or language-to-part grounding); global text prompts may induce unintended global changes.
- Physical plausibility and topology safety: Edits that change structure (e.g., “add wings”) lack constraints for attachment plausibility, thickness, collision, or symmetry; non-manifold or unstable topology may result without guarantees.
- SDF correctness and regularization: Training omits standard SDF regularizers (e.g., Eikonal/gradient penalties); implications for watertightness, signedness, and surface smoothness are unreported.
- Supervision alignment sensitivity: The GeDi + ICP alignment procedure could introduce bias; sensitivity to misalignment and comparisons with alternative alignment/supervision strategies are not analyzed.
- Self-reflection circularity: Actor, Evaluator, and Reflector are all BAGEL-based, risking circular bias and error reinforcement; the need for independent, 3D-native evaluators/critics remains open.
- Understanding tasks breadth: Evaluation focuses on captioning; there is no evidence on segmentation, part recognition, affordance, classification, or 3D QA, nor on whether unification helps these tasks.
- Mutual enhancement claim: Cross-task transfer (understanding → generation and vice versa) is asserted but not quantitatively validated beyond captioning ablations; controlled studies of mutual gains are needed.
- Domain generalization: Trained on Cap3D renders with shadow/gradient augmentation; robustness to real photos, noisy scans, CAD-like/stylized assets, or out-of-domain categories is untested.
- Component portability: The approach is tied to BAGEL (Qwen/FLUX) and Hunyuan3D; generality to other diffusion/3D backbones and interface specifications for drop-in replacement are not demonstrated.
- Scaling laws and data efficiency: No analysis of performance scaling with dataset size, LoRA rank, Mesh Head capacity, or backbone variants; sample efficiency and compute trade-offs remain unknown.
- Inference cost and latency: Runtime/memory for generation, multi-iteration CoM, and Reflexion loops are not reported; efficiency strategies and quality–latency trade-offs are unexplored.
- Robustness to prompt complexity: Failure modes under long, compositional, negation, or adversarial prompts are not characterized; prompt safety guardrails and calibration are absent.
- Multi-view/temporal consistency: Despite high CLIP score, ViCLIP lags some baselines; the causes (viewing trajectory, temporal coherence, multi-view consistency) are not investigated.
- Topology-changing edit validation: No metrics for the plausibility and stability of topology-altering edits (attachment continuity, re-meshing quality, stress points); benchmarks are needed.
- Human studies: No user evaluation of perceptual quality, edit satisfaction, or prompt alignment; human-in-the-loop assessments could validate practical usefulness.
- Baseline comparisons for editing: CoM is not compared against optimization-based or diffusion-based 3D editors on standardized edit tasks; relative strengths/weaknesses remain unclear.
- Scene-level extension: The method targets single, isolated objects; extensions to multi-object scenes, layout reasoning, occlusion, lighting, and interactions are not addressed.
- Pose and canonicalization: Control over camera/pose/canonical frames and scale normalization is not studied; consistent pose-aware conditioning remains open.
- Interpretability of Mesh Head: No analysis of what semantic/geometric attributes are carried in latents, disentanglement, or editability axes; tools for latent inspection/control are missing.
- Data/process ablations: Photorealistic augmentations (drop shadow, gradient) are not ablated; their necessity and generalization effects are unquantified.
- Reproducibility and dependencies: Stability depends on evolving external backbones; frozen checkpoints, deterministic configs, and alternatives for closed/unstable components are not detailed.
- Reflexion overheads: The computational/latency cost of Reflexion (rendering, view selection, iterative loops, CoT generation) is not quantified or optimized.
- Cross-dataset validation: DiffuRank and Reflexion gains are shown on limited subsets; broader, cross-dataset validations and larger-scale ablations are needed.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now by leveraging UniMesh’s Mesh Head (latent-to-3D interface), Chain-of-Mesh (CoM) iterative editing, and self-reflection for 3D understanding/captioning.
- Text-to-3D Asset Studio for Games, VFX, and AR/VR
- Sectors: Software, Media & Entertainment, XR
- What it does: Generate high-fidelity meshes from text prompts; iteratively refine with natural language (e.g., “add wings,” “make it red”) without retraining.
- Tools/products/workflows:
- Unity/Unreal/Blender plugins that call a UniMesh API for prompt→mesh→language edit cycles.
- “Semantic Mesh Editor” panels that track edit history via CoM.
- Assumptions/dependencies: Access to BAGEL/Qwen and Hunyuan3D backbones, GPU inference, commercial licensing for integrated backbones, prompt engineering expertise, and tolerance for single-object bias (scene generation is limited).
- 3D E-commerce Cataloging and Auto-Description
- Sectors: Retail, E-commerce
- What it does: Auto-generate 3D product models from merchandiser descriptions; produce attribute-rich captions for listings and search via the self-reflection-enabled captioner.
- Tools/products/workflows:
- “Catalog Mesh Generator” that outputs meshes + multi-view renders + captions/tags.
- CLIP-based auto-QA to filter off-spec assets before publishing.
- Assumptions/dependencies: Legal rights to represent products; verification that geometry and materials are sufficiently accurate for consumer expectations; branding/SKU-specific constraints may require manual checks.
- Rapid Robotic Simulation Asset Generation
- Sectors: Robotics, Automation
- What it does: Generate diverse object meshes for simulation and domain randomization; edit meshes semantically to vary shapes, colors, and parts for training robustness.
- Tools/products/workflows:
- “Sim Asset Forge” that batch-generates parameterized variants using CoM (e.g., “add handle,” “increase height”).
- Assumptions/dependencies: Physics/material annotations are not natively included; meshes may need cleanup/retopology and material tagging for accurate physics.
- Design Prototyping and Concept Iteration
- Sectors: Industrial Design, Manufacturing (early concept)
- What it does: Fast-turnaround form studies from textual spec; iterative, zero-shot semantic edits for stakeholder review.
- Tools/products/workflows:
- “Brief-to-Concept Mesh” pipeline integrated with CAD viewers for early review (not full CAD).
- Assumptions/dependencies: Precision tolerances and engineering constraints are not guaranteed; conversion to CAD/parametric models may require downstream tools.
- 3D Printing Personalization
- Sectors: Consumer, Maker Ecosystem
- What it does: Users create and tweak printable objects (figurines, accessories) via language prompts and CoM.
- Tools/products/workflows:
- Maker platform integration that generates watertight meshes for slicers; simple semantic edit widgets.
- Assumptions/dependencies: Postprocessing for watertightness/manifoldness; safety checks for printability and material constraints.
- 3D Asset QA and Curation Assistant
- Sectors: Media, E-commerce, Asset Marketplaces
- What it does: Use UniMesh’s captioning + CLIP scores to summarize, tag, and verify semantic alignment of assets; flag low-alignment outputs.
- Tools/products/workflows:
- Batch triage dashboards reporting CLIP/ViCLIP scores; automated rejection criteria and routing for human review.
- Assumptions/dependencies: CLIP-like metrics correlate imperfectly with human judgment; evaluator quality limits misclassification risk.
- Educational Content Generation (STEM and Art)
- Sectors: Education
- What it does: Generate classroom-ready 3D objects and labeled captions for teaching (e.g., simple machines, molecules at conceptual level, historical artifacts).
- Tools/products/workflows:
- “Lesson Mesh Pack” generator that outputs models + captions + multi-view render slides.
- Assumptions/dependencies: Domain accuracy varies; not suitable for high-stakes scientific accuracy without expert review.
- AR Product Visualization and Prototyping
- Sectors: Retail, Marketing, Real Estate
- What it does: Quickly produce 3D objects for try-before-you-buy AR experiences, with language-driven edits to match brand variants.
- Tools/products/workflows:
- Web AR pipelines that convert generated meshes to glTF/USDZ with PBR materials; live CoM tweaks for campaign A/B tests.
- Assumptions/dependencies: Material realism may require additional texture/material refinement; performance constraints on mobile AR devices.
- Synthetic Data Generation for Vision Research
- Sectors: Academia, R&D
- What it does: Generate labeled 3D meshes and multi-view renders with captions for training and evaluation of VLMs/3D models.
- Tools/products/workflows:
- Dataset scripts producing mesh+caption pairs; Self-reflection to iteratively refine captions to reduce label noise.
- Assumptions/dependencies: Synthetic-to-real domain gap; dataset license compliance; ensure diversity to avoid bias amplification.
- Compliance/Localization Support for Product Lines
- Sectors: Global Retail, Marketing
- What it does: Produce localized captions for 3D assets; use CoM to adjust geometry for regional variants (e.g., “add side marker lights”).
- Tools/products/workflows:
- Integrated captioner with language localization pipeline and variant tracking.
- Assumptions/dependencies: Legal compliance requires human sign-off; geometry edits may not reflect regulatory-grade detail.
- 3D Asset Search and Retrieval Enhancement
- Sectors: Asset Repositories, Software
- What it does: Auto-caption existing 3D collections to improve search indices and semantic retrieval.
- Tools/products/workflows:
- Batch captioning and tagging pipeline; embedding-based retrieval services using CLIP embeddings from multi-view renders.
- Assumptions/dependencies: View selection (e.g., DiffuRank) quality impacts description accuracy; captions may need manual normalization.
- Creative Storyboarding with 3D Props
- Sectors: Media Production, Advertising
- What it does: Quickly assemble 3D props via text and refine them semantically for pitch decks and animatics.
- Tools/products/workflows:
- “Prompt-to-Prop” tool integrated with previz software; CoM-based iterative briefing.
- Assumptions/dependencies: Not production-grade topology/materials; intended for ideation speed over final asset polish.
- 3D Evaluation Research Testbed
- Sectors: Academia
- What it does: Study the interplay between understanding and generation using the Actor–Evaluator–Self-reflection triad for 3D tasks.
- Tools/products/workflows:
- Reproducible benchmarks for caption refinement and iterative editing; ablation frameworks leveraging DiffuRank and CoT examples.
- Assumptions/dependencies: Current triad relies on 2D views; evaluator weaknesses can bias reflection dynamics.
Long-Term Applications
These use cases require further research, scaling, or ecosystem development due to precision, physics, regulatory, or integration challenges highlighted in the paper’s limitations.
- Parametric CAD-Level Co-Design via Natural Language
- Sectors: Manufacturing, Automotive, Aerospace
- What it could do: Convert textual requirements to constrained CAD; perform semantically coherent structural edits (e.g., fillets, tolerances) using a CoM-like loop grounded in true 3D/parametric representations.
- Dependencies/assumptions: Native 3D geometric reasoning (beyond 2D latents), CAD kernel integration, constraint solvers, verification against engineering specs.
- Scene-Level Generation and Editing with Physical Consistency
- Sectors: XR, Robotics, Digital Twins
- What it could do: Generate/edit multi-object scenes with spatial relations, materials, and physics (layout-aware CoM).
- Dependencies/assumptions: Robust scene graphs, differentiable physics/material models, reliable multi-object semantics, improved evaluator for 3D reasoning.
- Medical/Anatomical 3D Assistants
- Sectors: Healthcare, Medical Education
- What it could do: Generate/edit anatomically precise models for education, planning simulations, or patient-specific counseling; language-guided edits (e.g., “increase tumor margin by 2mm”).
- Dependencies/assumptions: Training on medical-grade 3D data; strict regulatory compliance; validation against imaging modalities; clinician-in-the-loop workflows.
- Robotics Task Planning with On-the-Fly 3D Understanding/Editing
- Sectors: Robotics, Warehousing, Field Ops
- What it could do: Agents that perceive objects, generate/edit hypothesized 3D models for planning (grasp points, tool attachments) and self-reflect to correct misrecognitions.
- Dependencies/assumptions: Real-time inference on-device/edge, robust 3D-to-action interfaces, physics-aware grasping and constraints.
- Standards and Policy for 3D Content Provenance and Safety
- Sectors: Policy, Standards Bodies, Marketplaces
- What it could do: Adopt provenance metadata (watermarks), licensing tags, and safety checks for generated meshes and captions; auditing CoM edit histories.
- Dependencies/assumptions: Industry consensus on 3D metadata schemas (e.g., USD extensions), regulatory interest, watermarking robustness.
- Enterprise Digital Twin Tooling
- Sectors: Energy, Manufacturing, Infrastructure
- What it could do: Rapid generation and semantic editing of twin components; auto-captioning for inventory and maintenance documentation; self-reflective QA on asset–spec alignment.
- Dependencies/assumptions: Integration with asset management systems; high-fidelity materials and physics; lifecycle/version control and compliance.
- Personalized AR Shopping and Configurators with Conversational Editing
- Sectors: Retail, Automotive, Appliances
- What it could do: End-user, in-AR semantic edits (colors, options, add-ons) with immediate 3D updates; persistent configurations tied to SKUs.
- Dependencies/assumptions: Mobile performance optimizations; robust UVs/materials; online inference cost control; alignment with manufacturing options.
- Self-Improving 3D Agents for Content Pipelines
- Sectors: Media, Software, 3D Marketplaces
- What it could do: Autonomous agents that generate/edit assets, critique outputs (Actor–Evaluator–Self-reflection), and learn preferences over time with human feedback.
- Dependencies/assumptions: More reliable 3D evaluators, preference learning, safety/guardrails to prevent drift, auditability.
- Safety-Critical Training Data Generation (Synthetic)
- Sectors: Autonomous Driving, Defense, Industrial Safety
- What it could do: Controlled generation of edge cases with precise 3D annotations and captions; iterative refinement to match scenario taxonomies.
- Dependencies/assumptions: Scene-level control, calibrated sensor simulation (LiDAR/cameras), rigorous validation pipelines.
- Finance/Insurance 3D Risk Assessment Aids
- Sectors: Finance, InsurTech, Real Estate
- What it could do: Generate hypothetical 3D models/scenarios (e.g., property layouts, equipment setups) for premium modeling and claims triage; auto-captioning for documentation consistency.
- Dependencies/assumptions: Reliable scene geometry and materials; industry acceptance; data privacy and provenance guarantees.
- Sustainability-Aware 3D Generation
- Sectors: Energy, Green Tech, Sustainability Analytics
- What it could do: Create/edit equipment models for sustainability scenarios (e.g., retrofits, component swaps) with associated metadata for simulation.
- Dependencies/assumptions: Integration with energy simulation tools; credible materials and parameterization; validated links from semantic edits to performance models.
- Cross-Institution 3D Benchmarking and Governance Frameworks
- Sectors: Academia, Policy, Open-Source Ecosystem
- What it could do: Benchmark suites for unified generation-understanding systems; governance practices for dataset licenses, bias detection, and synthetic data disclosure.
- Dependencies/assumptions: Community adoption; shared evaluation metrics for 3D semantics and geometry; clear IP policies.
Notes on Feasibility and Dependencies
- Technical dependencies:
- Access/licensing for BAGEL/Qwen and Hunyuan3D; GPU resources for inference.
- Current pipeline favors single-object meshes; scene-level support requires research.
- CoM edits operate in latent/image space; geometry/material precision and watertightness may require postprocessing.
- Evaluator quality limits self-reflection effectiveness; improved native 3D understanding modules are needed for high-stakes use.
- Organizational and legal considerations:
- IP/licensing for training data (e.g., Cap3D) and generated assets.
- Provenance, watermarking, and metadata standards for 3D distributions.
- Human-in-the-loop review for regulated or safety-critical domains.
- Performance and cost:
- Latency and compute cost may constrain real-time and edge applications; batching and caching can mitigate.
- Quality-control pipelines (CLIP/ViCLIP, human review) recommended for customer-facing outputs.
These applications map directly to UniMesh’s contributions: direct latent-to-3D mapping (Mesh Head) for efficient, high-fidelity generation; iterative, language-driven editing (CoM) for fast design cycles; and self-reflection for stronger 3D understanding and QA.
Glossary
- 3D Gaussians: A point-based 3D representation where objects are modeled as collections of anisotropic Gaussian primitives for fast, differentiable rendering. "generate 512-resolution 3D Gaussians \cite{kerbl20233dgs} in seconds."
- ActorâEvaluatorâSelf-reflection triad: A three-role loop where a model generates an output (Actor), judges it (Evaluator), and then critiques itself to improve (Self-reflection). "we incorporate a self-reflection mechanism based on an ActorâEvaluatorâSelf-reflection triad to diagnose and correct failures in high-level tasks like 3D captioning."
- Asymmetric U-Net: A U-Net variant with differing encoder/decoder capacities or structures, used here to better handle multi-view features for 3D generation. "coupled with an asymmetric U-Net \cite{ronneberger2015unet} backbone to generate 512-resolution 3D Gaussians \cite{kerbl20233dgs} in seconds."
- BAGEL: A unified multimodal pretraining framework providing diffusion-based image latents and language grounding used as part of the pipeline. "bridges BAGELâs diffusion-based image generation pipeline and Hunyuan3Dâs implicit shape decoder."
- Chain-of-Mesh (CoM): An iterative, prompting-based editing loop that feeds image latents and new prompts back into the model to refine 3D meshes without retraining. "Then we introduce Chain-of-Mesh (CoM), a geometric instantiation of iterative reasoning inspired by language-based Chain-of-Thought \cite{wei2022chain}."
- Chain-of-Thought (CoT): An approach that makes models generate intermediate reasoning steps to improve results; used here for better captioning and editing decisions. "We employ the Qwen3-VL-Plus model to generate high-quality Chain-of-Thought (CoT) \cite{wei2022chain} few-shot examples that guide subsequent reasoning."
- CLIP (Image-Text Similarity): A metric measuring alignment between images and text using CLIP embeddings, used to evaluate semantic fidelity of generated 3D content. "CLIP \cite{radford2021learning_clip} Image-Text Similarity"
- Conditioning latent: A learned latent vector that conditions the 3D shape generator, derived from an image latent to drive mesh synthesis. "which outputs a conditioning latent $z_{\text{cond}$."
- DINOv2 (conditioner): A strong visual encoder whose features are used to condition downstream components—in this case as part of the Mesh Head integration. "unifies the FLUX \cite{labs2025flux1kontextflowmatching} decoder from BAGEL and the DINOv2 \cite{oquab2023dinov2} conditioner from Hunyuan3D."
- DiffuRank: A diffusion-based ranking method to select the most informative views for tasks like captioning or training. "we select the best view from multi-view images using DiffuRank \cite{luo2024view}"
- Diffusion priors (multi-view): Learned diffusion-model priors over multiple views that guide consistent image/geometry generation. "the advent of large vision-LLMs and multi-view diffusion priors has enabled generalizable, high-fidelity 3D synthesis from diverse inputs."
- DiT-based (Diffusion Transformer) shape generator: A diffusion model architecture built on transformers to generate shapes or shape features. "introduces a modular pipeline comprising a DiT-based \cite{peebles2023scalable_dit} shape generator and a texture synthesizer"
- FLUX decoder: A component from BAGEL that decodes images into latents/features used to bridge to 3D shape generation. "we introduce a dedicated Mesh Head module that unifies the FLUX \cite{labs2025flux1kontextflowmatching} decoder from BAGEL and the DINOv2 \cite{oquab2023dinov2} conditioner from Hunyuan3D."
- GeDi alignment algorithm: A geometric alignment method used to align ground-truth point clouds with predicted implicit fields before computing losses. "using the GeDi \cite{Poiesi2021Gedi} alignment algorithm"
- Hunyuan3D: A 3D generation framework providing an implicit shape decoder and texture synthesizer used for high-fidelity mesh creation. "Hunyuan3Dâs implicit shape decoder."
- ICP (Iterative Closest Point): An algorithm for rigid alignment of point clouds by iteratively minimizing distances between corresponding points. "using ICP (Iterative Closest Point)."
- Image latent: The latent representation produced by a diffusion/vision module from an image or prompt, used to condition 3D generation. "BAGEL with Qwen generates an image latent"
- Implicit shape decoder: A decoder that represents shapes as continuous fields (e.g., SDFs) instead of explicit meshes, enabling flexible geometry prediction. "Hunyuan3Dâs implicit shape decoder."
- Iso-surface extraction (differentiable): The process of extracting a mesh surface from an implicit field in a differentiable manner to enable end-to-end supervision. "incorporating differentiable iso-surface extraction to directly supervise mesh outputsâenabling scalable training with geometric cues like depth and normals."
- Large reconstruction models (LRMs): Large-capacity models trained on massive 3D data to reconstruct or generate 3D assets quickly and accurately. "large reconstruction models (LRMs) \cite{hong2024lrmlargereconstructionmodel}"
- Latent space (image latent space): The feature space where encoded images (or prompts) reside and from which conditioning signals for 3D generation are derived. "BAGELâs image latent space"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that inserts low-rank adapters into existing layers to adapt models with few additional parameters. "we adopt LoRA (Low-Rank Adaptation) \cite{hu2022lora}"
- Mesh Head: The cross-model interface module that maps image latents to conditioning latents compatible with the 3D shape generator. "a novel Mesh Head â a cross-model interface"
- Multi-view consistency: The property that generated images or reconstructions remain coherent across different viewpoints. "highlighting the value of multi-view consistency for reconstruction quality."
- NeRF (Neural Radiance Fields): A neural representation that models 3D scenes by learning a radiance field for volumetric rendering from images. "to directly regress a NeRF \cite{mildenhall2021nerf} from a single image"
- Normal maps: Texture maps encoding per-pixel surface normals to add fine detail to rendered objects without increasing mesh complexity. "explicitly predicting UV-mapped textures, material parameters, and normal maps"
- Orbital multi-view videos: Videos captured or generated by orbiting a camera around an object to provide consistent multi-view observations. "generate temporally consistent orbital multi-view videos"
- Point-to-SDF loss: A supervision signal that penalizes discrepancies between ground-truth surface samples (points) and the predicted signed distance values. "compute a point-to-SDF loss"
- Reflexion: A self-improvement framework where a model uses verbal feedback about its own errors to iteratively refine outputs. "we build UniMesh upon the Reflexion \cite{shinn2023reflexionlanguageagentsverbal} framework"
- Signed Distance Field (SDF): An implicit representation giving the distance to the nearest surface with sign indicating inside/outside, used to define 3D geometry. "to produce a signed distance field (SDF) prediction."
- UV-mapped textures: Textures parameterized over a 2D UV coordinate map, enabling consistent application of images to 3D surfaces. "explicitly predicting UV-mapped textures, material parameters, and normal maps"
- ViCLIP: A video-text similarity model used to evaluate spatiotemporal alignment (e.g., across multi-view or orbital renders). "ViCLIP \cite{wang2023internvid_viclip} Text Similarity"
- Vision-LLMs (VLMs): Models jointly trained on images and text that can align and reason across modalities. "pretrained Vision-LLMs (VLMs)"
- Zero-shot (text-guided editing): Performing a task on new instructions without additional training or fine-tuning, relying on generalization from pretrained capabilities. "enabling zero-shot, text-guided 3D object modification without retraining."
- FlashVDM: An efficiency optimization used to reduce memory or accelerate diffusion/variational modules during training or inference. "enable FlashVDM \cite{lai2025unleashing}"
- Delighting module: A component that removes baked-in lighting from textures so assets can be correctly relit in new scenes. "along with a delighting module to ensure relighting compatibility."
Collections
Sign up for free to add this paper to one or more collections.