- The paper introduces a unified benchmarking framework for 3D representations by isolating variables like model architecture and preprocessing.
- It quantitatively evaluates generation and reconstruction performance across methods such as voxel grids, SDFs, and NeRFs using metrics like Chamfer Distance and F-score.
- Experimental results highlight trade-offs, with DualOctree excelling in generation metrics and SDFs achieving superior reconstruction fidelity.
Unifi3D: Unified Benchmarking of 3D Representations for Generation and Reconstruction
Introduction
The paper "Unifi3D: A Study on 3D Representations for Generation and Reconstruction in a Common Framework" (2509.02474) presents a comprehensive, modular benchmarking framework for evaluating 3D representations in both generative and reconstructive tasks. Unlike the standardized pixel-based representations in 2D image synthesis, 3D generative modeling remains fragmented, with diverse representations such as voxel grids, signed distance functions (SDFs), point clouds, octrees, triplanes, and neural radiance fields (NeRFs). The Unifi3D framework enables controlled, quantitative comparison of these representations by integrating them into a unified pipeline, isolating the effects of representation from confounding factors such as model architecture and preprocessing.
Figure 1: Overview of the steps involved in a standard 3D generation pipeline: mesh conversion, encoder compression, latent diffusion, decoder reconstruction, and mesh post-processing.
Unified Pipeline and Representations
The pipeline consists of four stages: mesh-to-representation conversion, representation compression via autoencoders (AE, VAE, VQ-VAE), latent generation using diffusion models (DiT, U-Net), and mesh reconstruction (e.g., Marching Cubes). The framework supports plug-and-play integration of multiple representations, including:
- Voxel Grids: Dense or sparse occupancy grids, compatible with CNNs but memory-intensive.
- SDF Grids: Scalar fields encoding signed distances, enabling smooth surface modeling and efficient grid-based processing.
- Point Clouds: Sets of 3D points, often used as intermediate representations.
- Dual Octree Graphs: Hierarchical, adaptive volumetric encoding using GNNs for efficient high-resolution geometry.
- Triplanes: Three orthogonal 2D feature planes, balancing memory efficiency and spatial expressiveness.
- NeRFs: Implicit neural fields for view synthesis, parameterized by MLPs.
Each representation is paired with a suitable encoder/decoder architecture and a generative model, ensuring fair comparison by controlling for model capacity and training protocol.
Evaluation Protocol
The framework advocates joint evaluation of reconstruction and generation, recognizing that reconstruction errors (from mesh conversion and compression) upper-bound generative performance. The protocol includes:
- Reconstruction Quality: Mesh → representation → mesh, measured by Chamfer Distance (CD), F-score, and Normal Consistency (NC).
- Compression Performance: Mesh → representation → latent → representation → mesh.
- Generalization: Out-of-distribution (OOD) reconstruction, e.g., encoder trained on one category, tested on another.
- Generation Metrics: Unconditional generation assessed by Coverage (COV), Minimum Matching Distance (MMD), and 1-Nearest Neighbor Accuracy (1-NNA), all based on CD between generated and reference meshes.
- Human Preference: User study with Bradley-Terry modeling to capture perceptual quality.
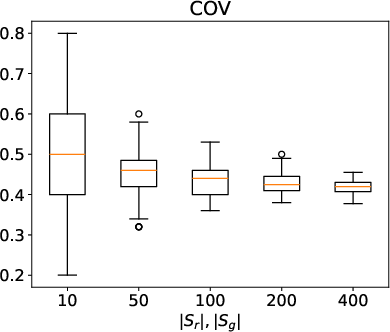
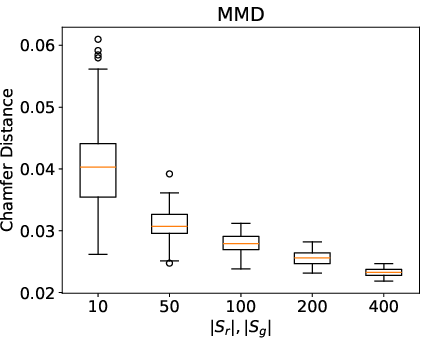
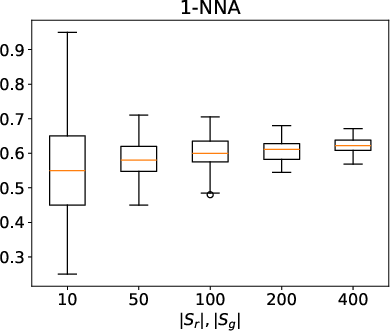
Figure 2: Distributional metrics (COV, MMD, 1-NNA) for random subsets of ShapeNet airplane category, illustrating metric sensitivity to sample size and dataset bias.
Experimental Results
The DualOctree VAE with U-Net diffusion achieves the best quantitative generation metrics (COV=0.365, MMD=0.031, 1-NNA=0.824), outperforming SDF, Shape2VecSet, Triplane, and Voxel representations. However, user studies rank SDF-generated meshes highest in perceptual quality, likely due to their smooth surfaces, while DualOctree tends to produce more complex but artifact-prone assets.
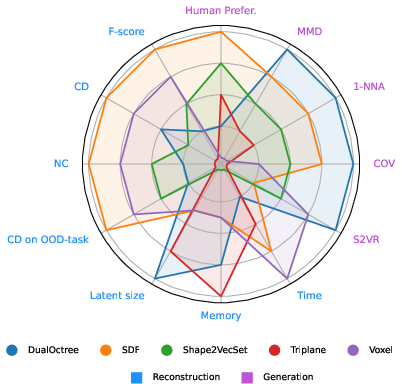
Figure 3: Rankings of 3D representations based on generation and reconstruction metrics, including user study scores and surface-to-volume ratio.

Figure 4: Qualitative results for mesh generation across representations, highlighting differences in surface smoothness and complexity.
SDF and Voxel grid encodings with AE/VAEs yield the highest reconstruction fidelity (F-score ≈ 88%), with SDF AE achieving the best overall scores. NeRF encoding performs worst, attributed to architectural modifications for comparability. DualOctree achieves competitive results with minimal latent size, demonstrating the efficiency of adaptive hierarchical encoding.
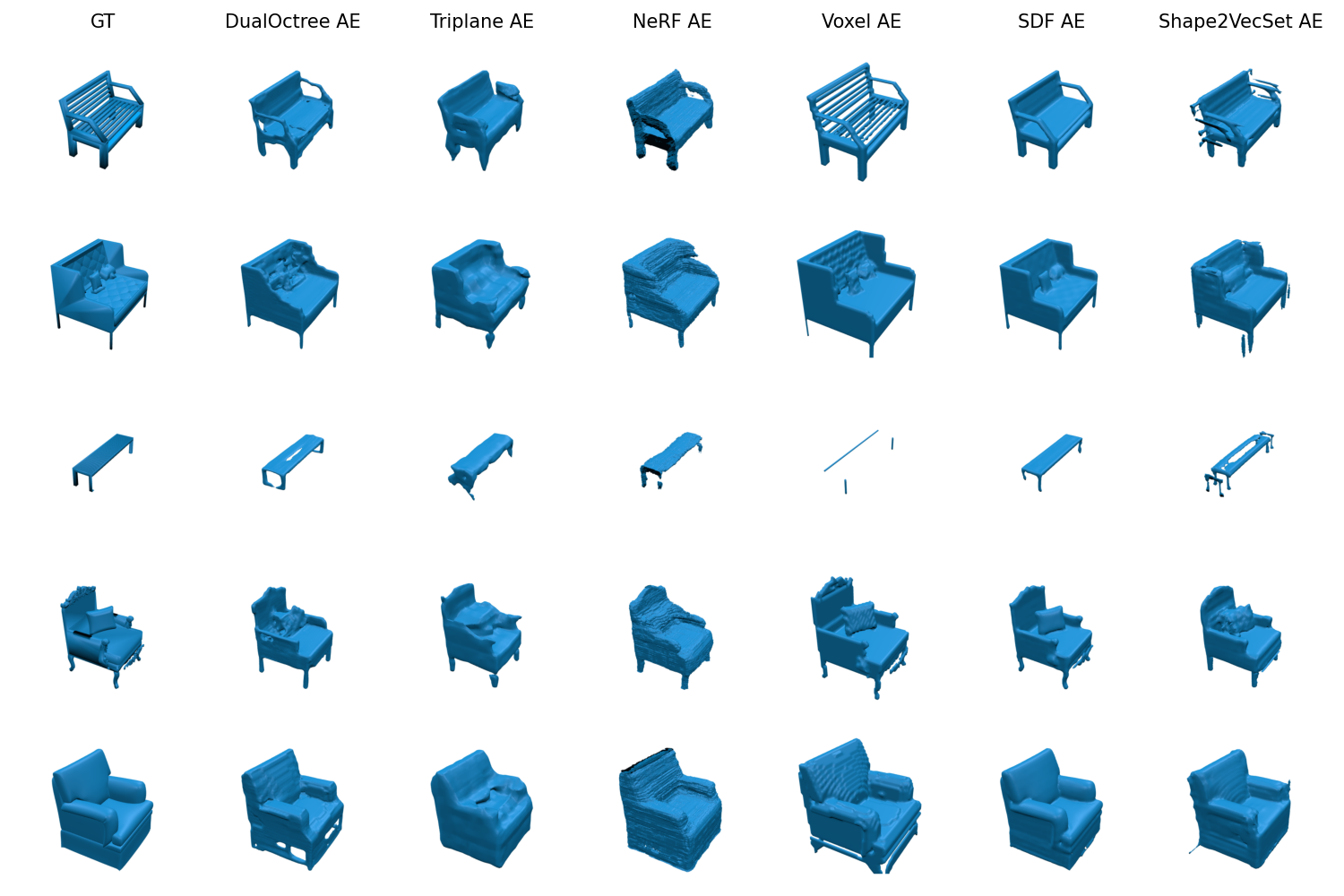
Figure 5: Qualitative results for mesh reconstruction, showing error modes such as loss of thin structures and surface artifacts.
Generalization and Scalability
Most encoders generalize well to OOD categories, except NeRF and DualOctree, which struggle due to overfitting and low latent dimensionality, respectively. The trade-off between latent size, reconstruction error, and runtime is evident: DualOctree achieves good accuracy with small latent size, while Voxel grids require larger latents for high fidelity.
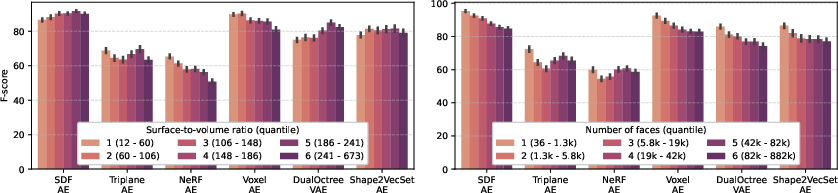
Figure 6: Complexity analysis, relating reconstruction quality to runtime and latent size.
Preprocessing and Error Decomposition
Mesh preprocessing (e.g., manifoldization) significantly affects reconstruction and generation. The proposed flood-fill SDF conversion avoids artificial thickening, preserving original geometry better than Mesh2SDF or ManifoldPlus. Reconstruction and compression errors constitute up to 39% of the total generative error, underscoring the necessity of joint evaluation.
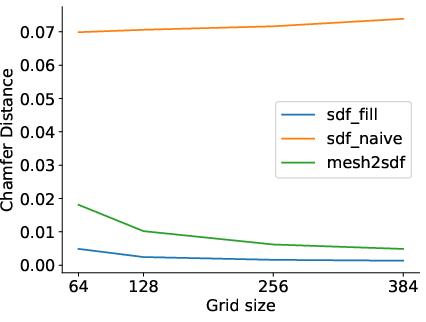
Figure 7: Comparison of mesh conversion methods in terms of Chamfer distance, demonstrating the impact of preprocessing on reconstruction error.
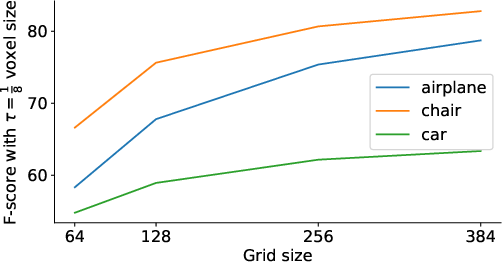
Figure 8: Effect of grid resolution on round-trip conversion errors, highlighting the trade-off between fidelity and computational cost.
Implications and Best Practices
The study establishes several best practices for 3D generative modeling:
- Joint Evaluation: Report both reconstruction and generation errors, as reconstruction quality upper-bounds generative performance.
- Direct Mesh Comparison: Use metrics computed on original meshes, avoiding distortions from preprocessing or derivative representations.
- Sample Size: Use sufficiently large sample sets (>200) for robust distributional metrics.
- Human Evaluation: Incorporate user studies to capture perceptual quality not reflected in geometric metrics.
The modular, open-source codebase facilitates rapid prototyping and benchmarking of new representations and generative models, promoting reproducibility and fair comparison.
Limitations and Future Directions
The framework focuses on direct 3D generation, excluding optimization-based methods (e.g., Score Distillation Sampling) and Gaussian Splatting approaches, which are prevalent in text-to-3D and view synthesis but have different computational and output characteristics. Future work could extend the analysis to autoregressive models, additional datasets (e.g., ObjaverseXL), and more complex object categories (e.g., articulated or scene-level generation).
Open challenges remain in modeling interior structures, scaling to scene-level synthesis, and enabling controllable articulation. The presented pipeline provides a foundation for systematic exploration of these directions.
Conclusion
Unifi3D delivers a rigorous, unified framework for benchmarking 3D representations in generative and reconstructive tasks. The results demonstrate that representation choice critically affects both quantitative and perceptual outcomes, with SDF and DualOctree offering complementary strengths. The study's recommendations and open-source tools set a new standard for reproducible, transparent evaluation in 3D generative modeling, enabling informed selection and development of representations for diverse applications.