- The paper demonstrates that the </think> token acts as a robust semantic anchor, enabling precise pruning in chain-of-thought reasoning.
- It introduces an attention-guided, search-and-refine pipeline that dynamically selects atomic operators to maintain logical coherence.
- The framework achieves over 50% token reduction and lowers computational costs without sacrificing accuracy across diverse datasets.
CRISP: Compressing Redundancy in Chain-of-Thought via Intrinsic Saliency Pruning
Motivation and Limitations of Existing Chain-of-Thought Compression Approaches
Recent reasoning-optimized LLMs, including DeepSeek-R1 and Qwen, have advanced reasoning by extending the length and detail of Chain-of-Thought (CoT) trajectories. However, protracted CoT introduces significant computational burdens, raising inference costs and latency. Prior compression techniques typically employ external models or prompt engineering to prune these trajectories but fail to align with the model-internal reasoning dynamics. This misalignment leads to inaccurate removal of semantically crucial steps and degrades logical coherence, especially when essential intermediate corrections or sub-goals are misclassified as redundant.
Empirical efficiency-accuracy analyses demonstrate that such externally-supervised pruning cannot attain high compression without sacrificing reasoning quality. The need for a framework that dynamically exploits the model's intrinsic understanding of logical saliency is evident.
Intrinsic Saliency: The </think> Token as a Semantic Anchor
The central analytic contribution of this work is the identification of the </think> token as a robust information anchor within the attention landscape of advanced reasoning LLMs. Detailed attention visualizations reveal that, as context propagates through successive transformer layers, attention becomes increasingly concentrated on the </think> token during final answer computation. This token serves not merely as a delimiter but as the principal aggregation site for all salient information from the CoT trajectory, effectively compressing contextual dependencies.
This phenomenon is illustrated by layer-wise heatmaps in DeepSeek-R1-Distill-Qwen-7B, where attention in shallow layers remains diffuse, while deep layers develop sharply focused columns at the </think> index.
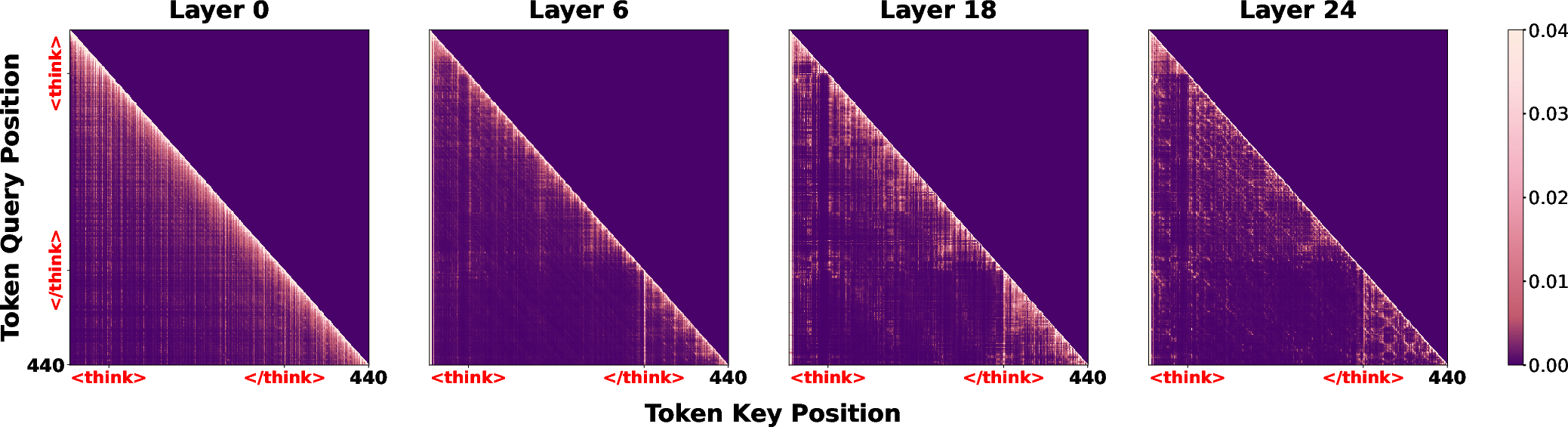
Figure 1: Layer-wise attention dynamics highlight the emergence of the </think> token as a dominant semantic anchor in deeper layers, aggregating information for answer derivation.
Empirical ablation confirms the hypothesis: pruning reasoning steps with high attention to </think> sharply increases perplexity of answer generation, while pruning low-attention steps incurs negligible degradation.
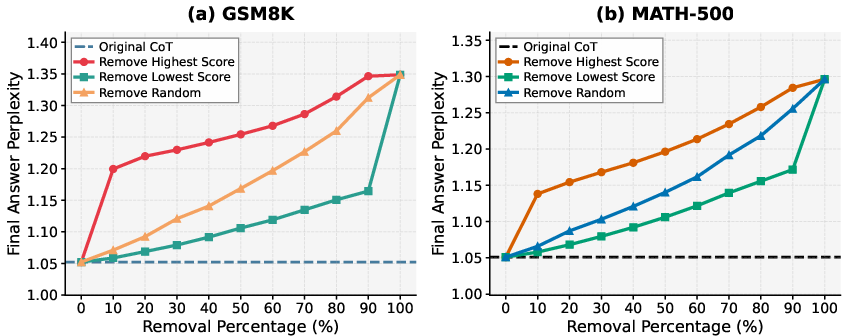
Figure 2: Pruning of high-attention steps at the </think> anchor correlates with a spike in perplexity, demonstrating their causal saliency.
CRISP Framework: Architecture and Compression Pipeline
CRISP operationalizes intrinsic saliency through an attention-guided, atomic-operator-based search over reasoning chains. The framework proceeds in three core stages:
- CoT Generation: The base model generates the initial, verbose reasoning trajectory for each input.
- Critical Reasoning Path Search: The chain is decomposed into atomic steps. For each step, a multi-layer, multi-head aggregation of attention weights from </think> to step tokens yields a normalized saliency score Si. Four atomic operators (Keep, Prune, Rewrite, Fuse) are available at each step, with operator selection governed by a dynamic, condition-dependent action set and an explicit reward balancing marginal answer likelihood improvement and token reduction.
- Refinement: A dedicated LLM-based refiner smooths the compressed skeleton to recover linguistic and syntactic coherence while preserving logical fidelity.
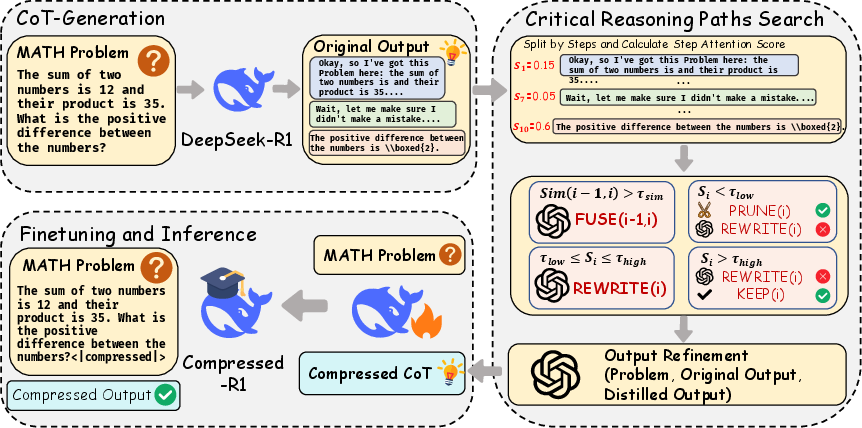
Figure 3: CRISP architecture: generation of raw CoT, critical path identification via atomic operators, and refinement for coherence.
Step-level analysis of saliency shows only a minority of reasoning steps receive high anchor-attention, further justifying compression.
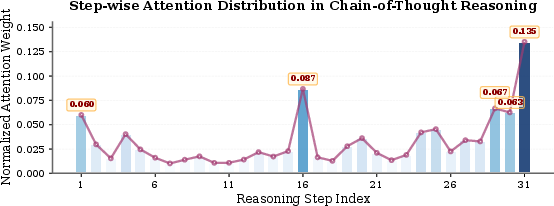
Figure 4: Distribution of step-wise attention scores Si points to sparse localization of crucial logical information.
CRISP actively applies generation-based synthesis (59% Rewrite, 18% Fuse) rather than mere extraction, reducing step count by 62% and moderately increasing average step length by 22.5%, thus yielding semantically denser units.
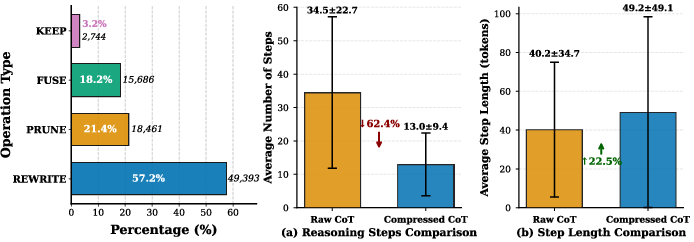
Figure 5: CRISP's compression character: steep reduction in reasoning steps, paired with moderate elongation of remaining steps.
Experimental Results and Analysis
Empirical validation is conducted on DeepSeek-R1-Distill-Qwen models (1.5B/7B) across GSM8K, MATH-500, and AMC23. Three metrics are reported: Accuracy (Acc.), average token count (Tok.), and Token Efficiency (TE = Acc/Length × 100).
CRISP consistently achieves over 50% token reduction with no compromise—and occasionally an improvement—in accuracy, surpassing strong baselines (TALE, TokenSkip, A*-Thought) especially on computationally demanding datasets.
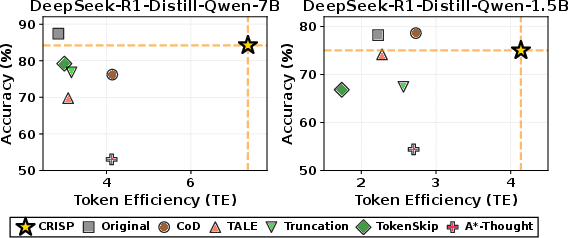
Figure 6: Token efficiency and accuracy trade-off for Qwen models. CRISP achieves state-of-the-art efficiency with negligible loss in accuracy.
Ablation studies underscore the necessity of both the search and refinement stages. When refinement is omitted, token counts remain low but accuracy suffers due to linguistic fragmentation.
Efficiency gains are further dissected by reasoning trajectory statistics. On MATH-500, CRISP-tuned models reduce the average correct answer trajectory length from 69 to 15 steps yet maintain 80%+ accuracy—a reduction of approximately 36 steps required for equivalent performance.
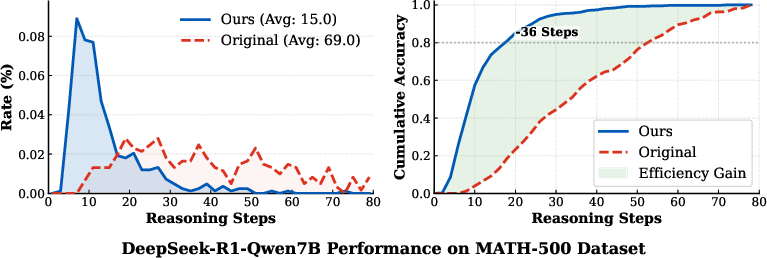
Figure 7: Trajectory length distributions and cumulative accuracy show dramatic efficiency gains for CRISP.
Additional breakdown across scales and tasks confirms the generality of the effect: CRISP achieves 10–15 step reductions to reach 80% cumulative accuracy in all model-dataset combinations.
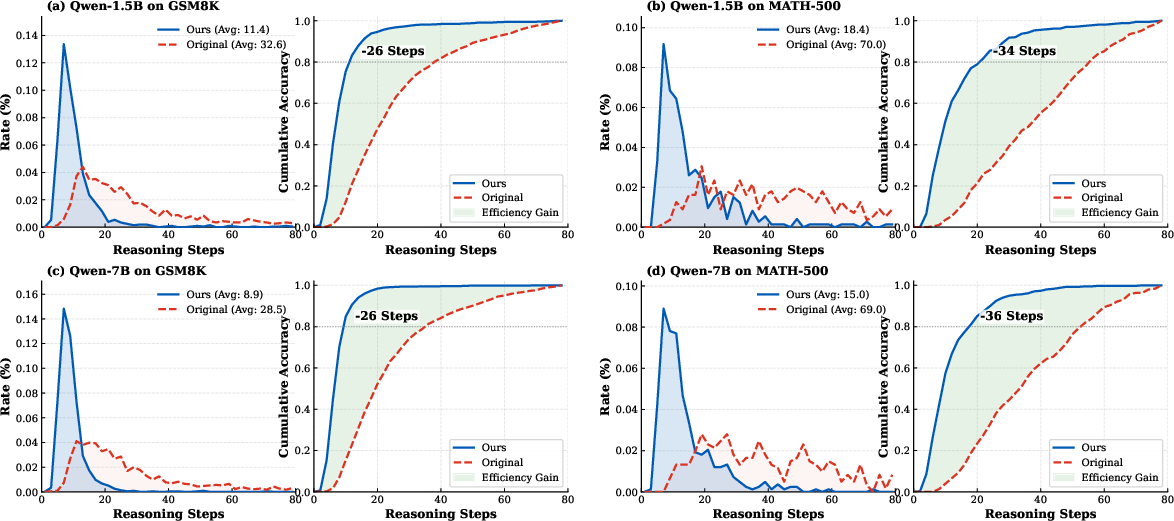
Figure 8: Across models and datasets, CRISP consistently shifts reasoning distributions towards shorter, denser chains with similar or superior accuracy.
Full-layer visualizations establish that anchor-based aggregation via the </think> token is a generalizable architectural behavior in both 1.5B and 7B variants.

Figure 9: DeepSeek-R1-Distill-Qwen-1.5B: pronounced aggregation at </think> in deep layers.
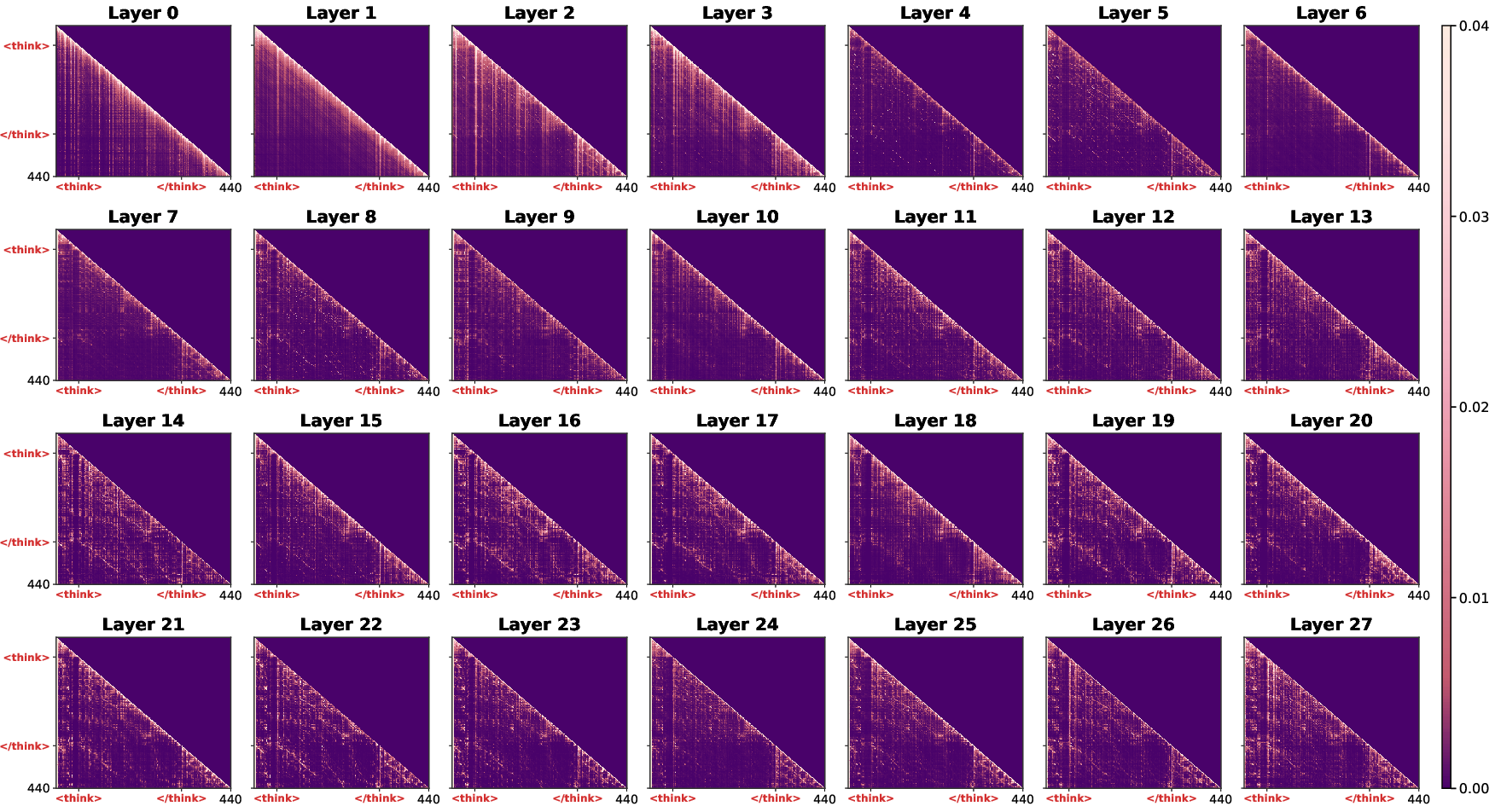
Figure 10: DeepSeek-R1-Distill-Qwen-7B: similar depth-dependent anchoring.
Theoretical and Practical Implications
CRISP demonstrates that CoT reasoning redundancy, a hallmark of advanced LLMs trained using self-consistency, is not irreducible. The framework establishes that attention-based introspection enables compression tightly coupled to the model's own logical corpus callosum, rather than unreliable external metrics. The results highlight the importance of semantic anchoring in transformer architectures—specifically, the learned role of boundary tokens as high-capacity state aggregators.
From a deployment perspective, CRISP's large token savings translate into significant reductions in inference cost, latency, and memory footprint, enabling high-performance reasoning in constrained environments. The decoupled search-and-refine pipeline allows the adaptation of CRISP to heterogeneous model architectures and domains, though generalization to unstructured tasks remains an open question. The requirement for offline search and reward-guided synthesis presents a data construction bottleneck for large-scale applications.
Conclusion
CRISP introduces attention-based, semantics-preserving compression of Chain-of-Thought reasoning in LLMs, leveraging the internal saliency landscape centered on the </think> anchor. Systematic experimental evidence confirms that this approach enables order-of-magnitude improvements in inference efficiency without degrading accuracy, fundamentally advancing the deployability of reasoning-oriented LLMs. Future directions include adaptive anchor discovery in open-domain settings, improved reward learning in low-resource environments, and exploration of anchor-based compression in non-mathematical reasoning contexts.

