- The paper introduces ASAP, a two-stage CoT pruning framework combining anchor-guided coarse pruning and surprisal-based fine pruning to retain essential reasoning steps.
- It demonstrates improved code generation performance by reducing token generation and inference latency while increasing accuracy.
- ASAP efficiently compresses CoT traces and enhances training efficiency, achieving significant reductions in tokens and training time through targeted pruning.
Efficient Code Reasoning via First-Token Surprisal: The ASAP Framework
Introduction
The paper "Pruning the Unsurprising: Efficient Code Reasoning via First-Token Surprisal" (2508.05988) addresses the inefficiency and redundancy inherent in long Chain-of-Thought (CoT) traces generated by Large Reasoning Models (LRMs) for code generation tasks. While extended CoTs can improve reasoning accuracy, they introduce significant computational overhead and often contain superfluous or logically irrelevant steps. The authors propose ASAP (Anchor-guided, Surprisal-based Pruning), a two-stage CoT compression framework that combines anchor-guided coarse pruning with a novel fine-grained step selection based on first-token surprisal. This approach aims to retain only the logically essential reasoning steps, thereby improving both inference efficiency and model performance.
LRMs, such as DeepSeek-R1 and OpenAI's o1, have demonstrated strong performance in code reasoning by leveraging long CoT traces. However, these traces frequently include redundant branches, self-debugging detours, and alternative solution paths, especially in competitive programming contexts. Token-level compression methods (e.g., Selective Context, LLMLingua-2) often disrupt syntactic and logical coherence, while step-level methods based on perplexity (e.g., SPIRIT) fail to reliably capture logical salience. The core challenge is to identify and retain only those reasoning steps that are logically indispensable for deriving the correct answer, without sacrificing the interpretability or structure of the CoT.
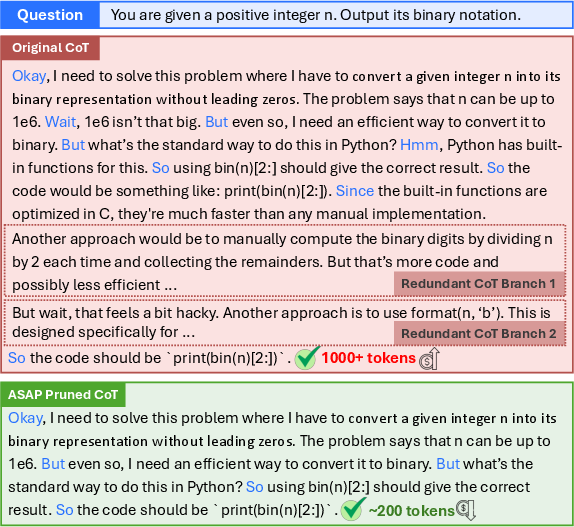
Figure 1: ASAP prunes redundant branches from the original CoT and identifies the first tokens of reasoning steps for surprisal-based selection.
ASAP: Coarse-to-Fine Pruning Framework
Stage 1: Anchor-Guided Coarse Pruning
ASAP first generates a concise "Direct CoT" (Cdirect) using an LLM, conditioned on the question and answer. This anchor trace represents the minimal logical backbone required to solve the problem. The original, verbose CoT (Corigin) is then pruned by aligning its steps to Cdirect using Gestalt Pattern Matching, ensuring that only steps structurally and semantically consistent with the anchor are retained. This process eliminates digressions and alternative solution paths while preserving the original wording and order.
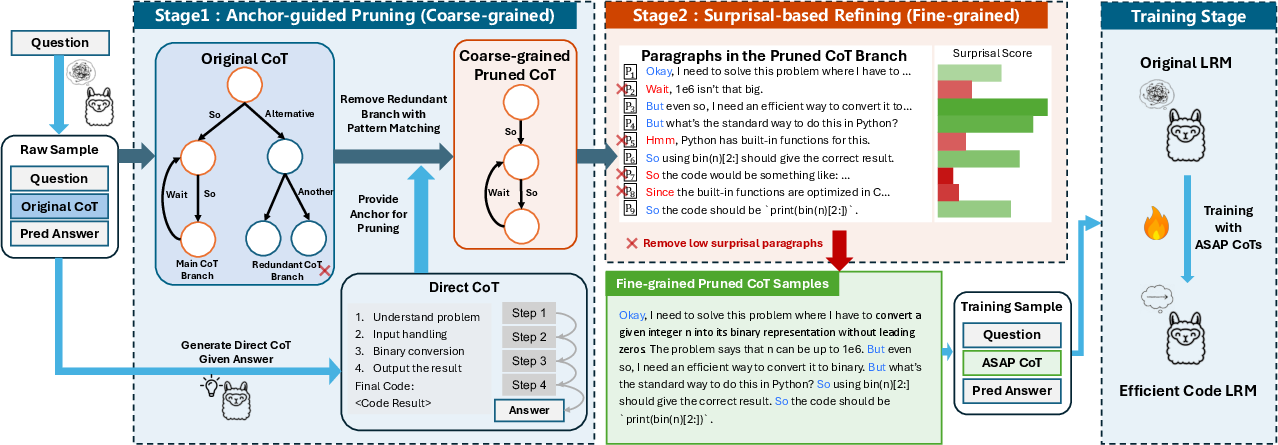
Figure 2: ASAP's two-stage framework: anchor-guided coarse pruning followed by surprisal-based fine pruning.
Stage 2: Surprisal-Based Fine Pruning
The coarse-pruned CoT (Ccoarse) is further refined by evaluating the logical importance of each step using first-token surprisal. For each reasoning step, the surprisal of its initial token is computed as S(xt∣x<n)=−logp(xt∣x<n), where xt is the first token and x<n is the preceding context. High surprisal indicates that the step introduces novel or unexpected information, while low surprisal suggests redundancy or predictable continuation. ASAP iteratively removes steps with the lowest surprisal until a target token budget is met, yielding a highly compressed, logically salient CoT.
Supervised Fine-Tuning
The final pruned CoTs are used to fine-tune the LRM via standard negative log-likelihood minimization. This process distills efficient reasoning patterns into the model, enabling it to generate concise and effective CoTs at inference time.
Empirical Evaluation
Experimental Setup
ASAP is evaluated on DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B across multiple code generation benchmarks: HumanEval, HumanEval+, LiveCodeBench (v1_v3 and v4_v5), and LeetCodeDataset. Baselines include zero-shot, original (uncompressed) CoTs, token-level compressors (Selective Context, LLMLingua-2, TokenSkip), and step-level pruning (SPIRIT). Metrics include Pass@1 accuracy, average generated tokens, and inference latency.
Main Results
ASAP consistently achieves the best trade-off between accuracy and efficiency. On LiveCodeBench v4_v5, ASAP reduces token generation by 23.5% and inference latency by 43.5% compared to SPIRIT, while improving Pass@1 accuracy from 33.58% to 36.19%. Token-level methods degrade performance due to loss of syntactic and logical structure, while step-level perplexity-based pruning is less effective than surprisal-based selection.
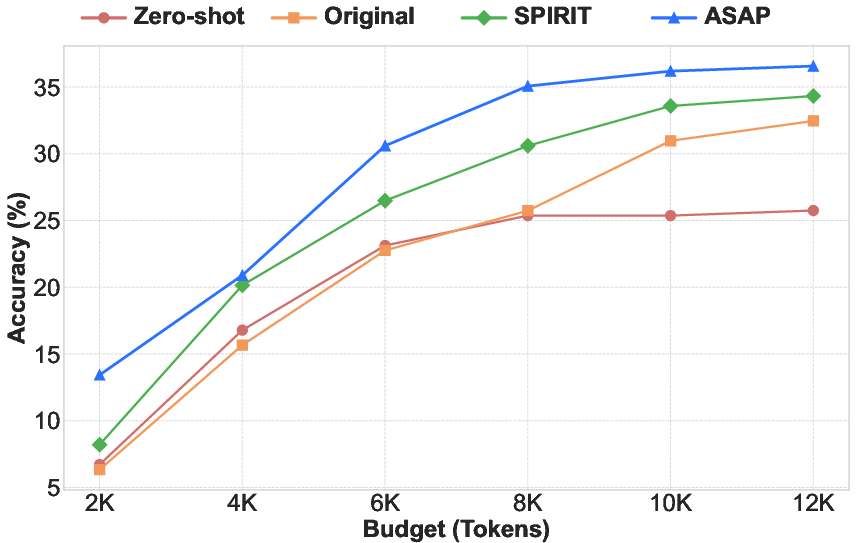
Figure 3: ASAP's performance on LiveCodeBench v4_v5 under varying token budgets, demonstrating robust scaling and efficiency.
Ablation and Analysis
Ablation studies confirm that both anchor-guided coarse pruning and surprisal-based fine pruning are essential. Removing either stage degrades both accuracy and efficiency, with the fine-grained surprisal-based pruning being particularly critical for logical step selection. ASAP's improvements are robust across different model architectures and token budgets, with predictable scaling and superior performance-efficiency trade-offs.
Training Efficiency
ASAP achieves a 75.6% reduction in training tokens and a 60.7% reduction in training time per step compared to the uncompressed baseline, substantially exceeding the efficiency gains of all other baselines.
Implementation Considerations
- Pattern Matching: Gestalt Pattern Matching is used to ensure that pruned steps are structurally aligned with the original CoT, minimizing hallucination and preserving logical order.
- Surprisal Computation: Efficient batch computation of first-token surprisal is required for scalability. This can be implemented using the LLM's logits and a tokenizer to identify step boundaries.
- Token Budget Control: The iterative pruning algorithm allows for explicit control over the final CoT length, enabling deployment under varying resource constraints.
- Fine-Tuning: Full-parameter fine-tuning is recommended for maximal performance, but parameter-efficient methods (e.g., LoRA) may be explored for further resource savings.
- Deployment: ASAP is compatible with any LLM capable of CoT reasoning and can be integrated into existing code generation pipelines with minimal modification.
Theoretical and Practical Implications
ASAP demonstrates that first-token surprisal is a more reliable indicator of logical salience in CoT reasoning than perplexity or token-level importance. This insight has implications for both model interpretability and efficient reasoning, suggesting that LLMs can be guided to focus on genuinely informative steps. The framework is general and can be extended to other domains requiring stepwise reasoning, such as mathematical problem solving or scientific question answering.
Future Directions
Potential extensions include:
- Adapting ASAP for multi-modal or non-code reasoning tasks.
- Exploring reinforcement learning objectives that directly optimize for surprisal-based CoT efficiency.
- Integrating ASAP with retrieval-augmented generation or program synthesis pipelines.
- Investigating the relationship between surprisal, entropy, and human-perceived logical importance in broader reasoning contexts.
Conclusion
ASAP provides a principled, empirically validated approach for compressing CoT traces in code reasoning tasks, achieving state-of-the-art accuracy and efficiency. By leveraging anchor-guided pruning and first-token surprisal, ASAP enables LRMs to internalize and generate concise, logically essential reasoning patterns, with significant implications for scalable and interpretable AI reasoning systems.

