Reasoning Efficiently Through Adaptive Chain-of-Thought Compression: A Self-Optimizing Framework
Abstract: Chain-of-Thought (CoT) reasoning enhances LLMs by prompting intermediate steps, improving accuracy and robustness in arithmetic, logic, and commonsense tasks. However, this benefit comes with high computational costs: longer outputs increase latency, memory usage, and KV-cache demands. These issues are especially critical in software engineering tasks where concise and deterministic outputs are required. To investigate these trade-offs, we conduct an empirical study based on code generation benchmarks. The results reveal that longer CoT does not always help. Excessive reasoning often causes truncation, accuracy drops, and latency up to five times higher, with failed outputs consistently longer than successful ones. These findings challenge the assumption that longer reasoning is inherently better and highlight the need for adaptive CoT control. Motivated by this, we propose SEER (Self-Enhancing Efficient Reasoning), an adaptive framework that compresses CoT while preserving accuracy. SEER combines Best-of-N sampling with task-aware adaptive filtering, dynamically adjusting thresholds based on pre-inference outputs to reduce verbosity and computational overhead. We then evaluate SEER on three software engineering tasks and one math task. On average, SEER shortens CoT by 42.1%, improves accuracy by reducing truncation, and eliminates most infinite loops. These results demonstrate SEER as a practical method to make CoT-enhanced LLMs more efficient and robust, even under resource constraints.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑Language Summary of the Paper
What is this paper about?
This paper looks at how AI models “think out loud” when solving problems and how to make that thinking shorter, faster, and still correct. The “thinking out loud” part is called Chain‑of‑Thought (CoT). It’s like when your teacher says “show your work” in math: you write the steps, not just the final answer.
The problem: writing out lots of steps takes time and computer memory. The paper shows that longer explanations are not always better and can even hurt results. Then it introduces a new method, called SEER, to keep the reasoning short and clear without losing accuracy.
What questions did the researchers ask?
The paper focuses on four simple questions:
- Does making the AI write longer explanations actually help it get more answers right?
- How much do long explanations slow things down or make the AI run out of space (so its answer gets cut off)?
- Can we teach the AI to explain itself more briefly while staying correct?
- Will this work across different tasks, especially in coding, and stop bad habits like getting stuck repeating itself?
How did they study it? (In everyday terms)
They ran tests on problems where AIs write code, find bugs, search for matching code, and solve math word problems. Think of:
- HumanEval and Codeforces for coding challenges,
- Datasets for bug detection and code search,
- GSM‑8K for math reasoning.
They measured:
- Accuracy (did the AI get it right on the first try?),
- How many “tokens” it used (tokens are like chunks of words—longer explanations mean more tokens),
- Speed and whether the AI hit its “character limit” and got cut off (called truncation),
- Looping (when the AI gets stuck repeating itself, like “Wait, if… Wait, if…” over and over).
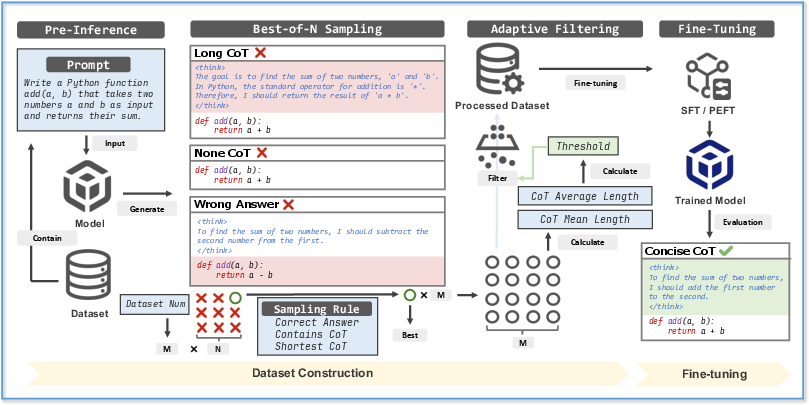
Then they introduced SEER, a new training method that teaches the AI to explain just enough:
- Best‑of‑N sampling: Ask the AI to write several solutions, keep only the correct one with the shortest clear explanation. Think of writing three drafts and saving the shortest correct one.
- Adaptive filtering: Set a smart length limit based on real examples. It looks at the usual length of explanations in a dataset and sets a fair cutoff so the AI doesn’t ramble but also doesn’t leave out important steps.
Importantly, SEER doesn’t need extra tools to compress text. The model learns to be concise by training on its own best, shortest correct answers.
What did they find, and why does it matter?
Key findings:
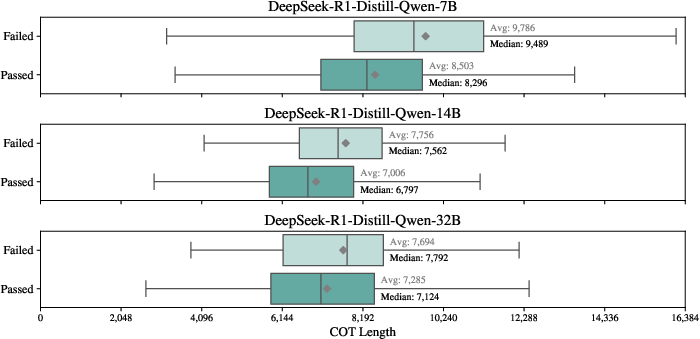
- Longer isn’t always better. Failed answers often had longer explanations than successful ones. Overthinking adds noise.
- Long reasoning can get the AI cut off. On smaller models, accuracy dropped a lot when the AI ran out of space mid‑answer (for one small model, pass@1 fell from about 60% to 46% with long CoT).
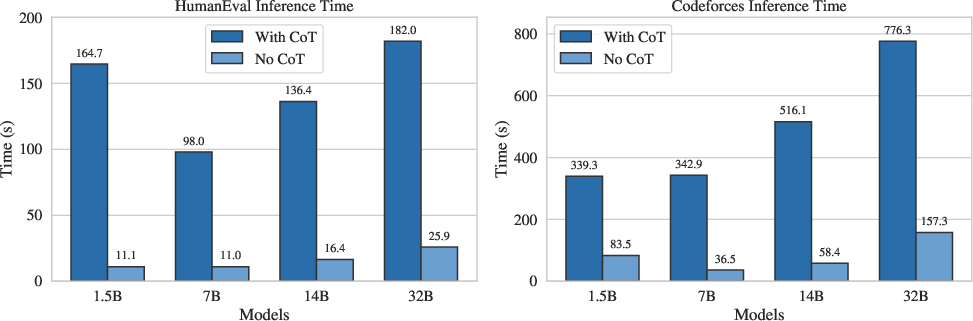
- Long explanations are slow. On a tough coding set, the biggest model took almost 5 times longer with long CoT than without. That’s bad for real‑time use.
- Looping is a big problem. Many failures happened because the AI got stuck repeating itself until it hit the maximum length.
What SEER achieved:
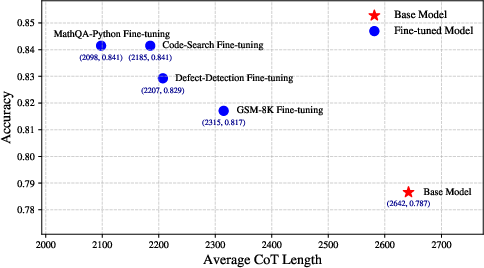
- On average, it shortened explanations by about 42% while keeping accuracy the same or even improving it (because fewer answers got cut off).
- It greatly reduced infinite loops (by up to about 98% in some tests).
- It worked across coding tasks and also on math reasoning, even though it was tuned on code first.
- Compared to other “compression” methods that sometimes broke code or damaged logic, SEER stayed stable and reliable.
Why this matters:
- Faster, cheaper, and more reliable AI tools for developers and students.
- Less waiting for answers and fewer crashes due to running out of space.
- Better behavior under limited resources (like smaller computers or strict time limits).
What could this change in the real world?
- Coding assistants that “explain just enough” can respond quicker and fit on smaller devices, helping more people use them effectively.
- Teams can avoid the myth that “more thinking text is always better.” Instead, they can aim for the right amount of reasoning.
- The SEER approach—try multiple answers, keep the shortest correct one, and learn from it—could be applied to many reasoning tasks, not just code.
In short: The paper shows that smart, shorter explanations can be just as accurate (or better), much faster, and more dependable. SEER gives AI a way to teach itself to be concise without losing the logic that makes explanations helpful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps the paper leaves unresolved that future work could address:
- Limited domain coverage: evaluation focuses on three software engineering tasks and one math dataset (GSM-8K); no assessment on broader reasoning domains (e.g., commonsense QA, multi-hop factual QA, planning/tool-use, scientific QA, instruction following), multilingual settings, or multimodal reasoning.
- Single model family: experiments center on DeepSeek-R1-Distill-Qwen variants; no cross-architecture validation (e.g., Llama/Mistral/Mixtral, Phi, Qwen non-R1, GPT-4o/Claude) to test generality of findings and the method’s portability.
- Fine-tuning scope: SEER is fine-tuned and evaluated primarily on a 7B model; no analysis of scaling behavior across sizes (1.5B–70B+), nor PEFT variants (LoRA/QLoRA) despite claiming compatibility.
- Dataset-level thresholding only: the adaptive CoT filter sets a single dataset-specific threshold λc; per-instance adaptivity (predicting instance-specific budget based on difficulty/uncertainty) is not explored.
- Unjustified threshold heuristic: λada is defined heuristically as an average of mean and median CoT lengths (the paper’s formula is malformed), with no theoretical grounding, sensitivity analysis, or comparison to alternatives (e.g., percentile-based caps, robust statistics, learned policies, cost/latency-aware objectives).
- No ablation of N in Best-of-N: BoN uses a fixed N=3; the paper (truncated) does not report sensitivity of accuracy/compression/compute cost to N, nor diminishing returns or optimal N under different domains.
- Pre-inference cost not quantified: the end-to-end compute/time/cost of generating multiple candidates per example for BoN and pre-inference profiling is not measured; net efficiency gains may be offset by data generation overhead.
- Reliance on correctness oracles: BoN selection assumes access to reliable verifiers (unit tests or exact-match answers). The approach is not instantiated for tasks without robust oracles or with many valid outputs (e.g., open-ended generation, refactoring, code review).
- Risk of shortcut learning: selecting the “shortest correct” rationale may bias the model toward spurious, shallow patterns. The paper does not measure faithfulness/causal sufficiency (e.g., counterfactual tests, consistency under perturbations) or assess whether compressed CoTs remain valid explanations.
- Loop detection methodology under-specified: “reasoning loops” are reported as dominant truncation cause, but detection criteria/algorithms, standard metrics, and robustness across decoding settings (temperature, top-p, repetition/presence penalties) are not detailed.
- Inference-time controls untested: the work fine-tunes to reduce loops/verbosity but does not compare against simple decoding-time baselines (stop sequences, anti-loop penalties, entropy-based early stopping, per-step confidence gating) that might achieve similar benefits with zero training.
- Latency/memory evaluation incomplete: latency is estimated from tokens/s on a single GPU; there is no reporting of KV-cache memory, peak VRAM, throughput under batching, or serving performance with modern inference stacks (vLLM, paged KV, FlashAttention), nor cost-per-request analyses.
- Baseline breadth: comparison omits several relevant methods (e.g., R1-Compress, GoGI-Skip/Adaptive GoGI-Skip, CoLaR, step-dropout, self-consistency with pruning, gating methods like “think selectively,” RL-for-brevity, prompt-level concision controls), and prompt-only baselines (“be concise”, “explain briefly”, “answer-then-justify”).
- Risk of over-compression on hard instances: no difficulty-conditioned analysis (e.g., stratifying by complexity or code length) to check whether caps harm truly hard problems needing long proofs/traces; no mechanism for expanding CoT on-demand for such cases.
- Cross-language/codebase generalization: code tasks are Python-centric; the method is not assessed on other programming languages, multi-file repositories, or realistic repository-scale contexts (e.g., RepoBench, SWE-bench, CodeContests-large).
- Context-length dependence: results are reported under 8K (training/eval) and 16K (empirical) limits; no study of behavior under tighter (4K) or longer (32K–1M) contexts, nor memory-limited devices or streaming scenarios.
- Impact on interpretability and developer utility: no human/user studies on whether compressed CoTs remain readable, useful for debugging, and conducive to trust/calibration in developer workflows.
- Statistical rigor and reproducibility: pass@1 is reported without confidence intervals, multiple seeds, or significance tests; some LaTeX/algorithm typos (e.g., malformed λ formula, brace mismatches) hinder unambiguous replication; details on released code, prompts, and data curation are missing.
- Potential data contamination: no analysis ensuring that base models or self-generated data did not leak evaluation benchmarks (HumanEval/GSM-8K), which could inflate accuracy.
- Catastrophic forgetting and capability drift: no assessment of broader capability retention (e.g., MMLU, BBH, coding beyond the target tasks) to check whether concision fine-tuning harms general performance.
- Calibration and abstention: the effect of CoT compression on confidence calibration (ECE), error detection, or abstention/deferral behavior is unexamined.
- Safety and policy compliance: no audit of whether compressed CoTs alter safety profiles (toxicity, privacy leakage, harmful instructions) or increase hallucination rates.
- Online/interactive settings: the method is not tested in multi-turn coding assistants or iterative debugging loops where reasoning length may vary with user feedback; no study of user satisfaction or task completion time.
- Integration with latency budgets: λc is not tied to target latency or cost constraints; there is no controller that optimizes an explicit accuracy–latency trade-off at inference time.
- Applicability to tasks without CoT norms: for classification/retrieval tasks (e.g., Code-Search), it remains unclear whether generating CoT is needed vs. harmful; per-task CoT-on/off gating is not explored.
- Alternative objective formulations: beyond “shortest correct,” no exploration of information-theoretic or minimal-sufficient-rationale objectives, compression via distillation/summarization of rationales, or contrastive training against verbose/looping traces.
Collections
Sign up for free to add this paper to one or more collections.

