- The paper introduces MedPRMBench, a novel benchmark for process-level evaluation in medical reasoning using targeted error injection and clinical reasoning blueprints.
- It details a multi-phase methodology that aggregates diverse medical QA datasets and applies a 14-type error taxonomy with 4-level severity grading.
- Empirical results show that the Qwen3-8B PRM baseline significantly outperforms competitors, enhancing error detection and model robustness for safer clinical applications.
MedPRMBench: Process-Level Reward Model Benchmark for Fine-Grained Medical Reasoning Evaluation
Rigorous process-level verification is critical for LLMs operating in medical contexts due to the domain’s high stakes, unique error modalities, and need for safety and interpretability. Existing PRM benchmarks emphasize domains such as mathematics and general reasoning, offering only limited error categories and lacking metrics for the impact severity. These constraints preclude reliable assessment of PRM error detection in real-world clinical scenarios, which span a broad landscape including errors of evidence citation, context misapplication, omitting prerequisites, and safety violations. "MedPRMBench: A Fine-grained Benchmark for Process Reward Models in Medical Reasoning" (2604.17282) introduces a comprehensive framework and dataset for process-level reward model evaluation tailored to the complexities of medical reasoning.
Construction Pipeline and Methodology
MedPRMBench’s construction is designed as a multi-phase pipeline to ensure dataset rigor, diversity, and annotation precision:
- Phase 1: Data Curation. Seven established medical QA datasets are aggregated and subjected to difficulty-aware filtering, ensuring contemporary LLMs fail a majority of items (e.g., p(x)≤0.5 with GPT-4o-mini). For datasets lacking expert-authored reasoning chains, rejection sampling from strong LLMs is employed until correct chains are produced, guaranteeing high-quality yet diverse clinical reasoning traces.
- Phase 2: Clinical Reasoning Blueprint Construction. Raw reasoning is transformed into explicit, causal graphs—"Clinical Reasoning Blueprints" (CRBs)—using multi-model evidence extraction fused by semantic voting to enhance entity/edge fidelity. Node criticality, safety annotations, and prerequisite dependencies are computed to inform subsequent manipulations.
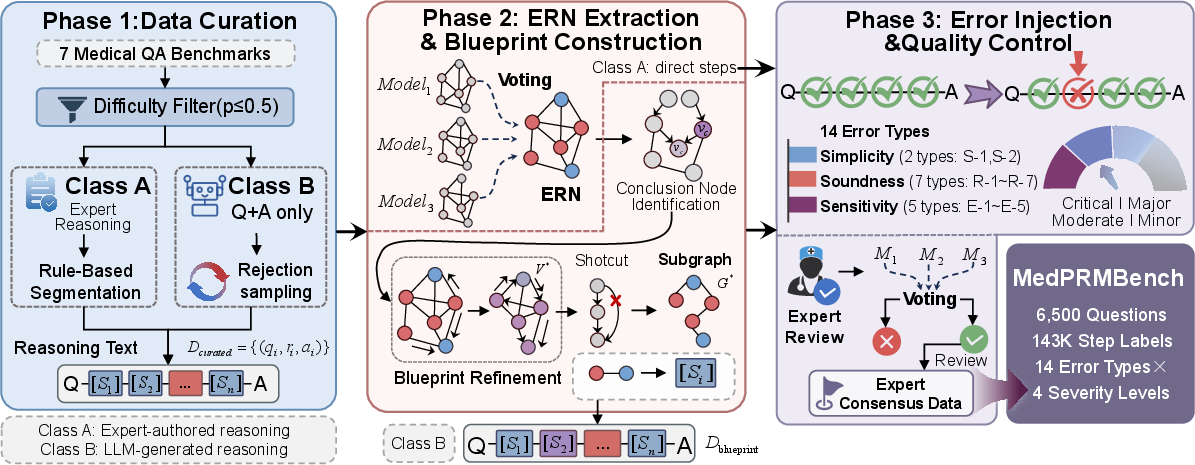
Figure 1: MedPRMBench’s construction pipeline. Evidence Reasoning Networks are distilled into Clinical Reasoning Blueprints, which then drive targeted error injection and annotation.
- Phase 3: Blueprint-Guided Error Injection. Errors are injected into reasoning chains according to a fine-grained 14-type taxonomy (detailed below), guided by CRBs to enforce control and clinical plausibility. Injected errors are annotated not only by type but also by 4-level severity gradings quantifying potential clinical harm, and are subjected to deterministic diff-based verification and expert review supported by multi-model voting for maximal annotation accuracy.
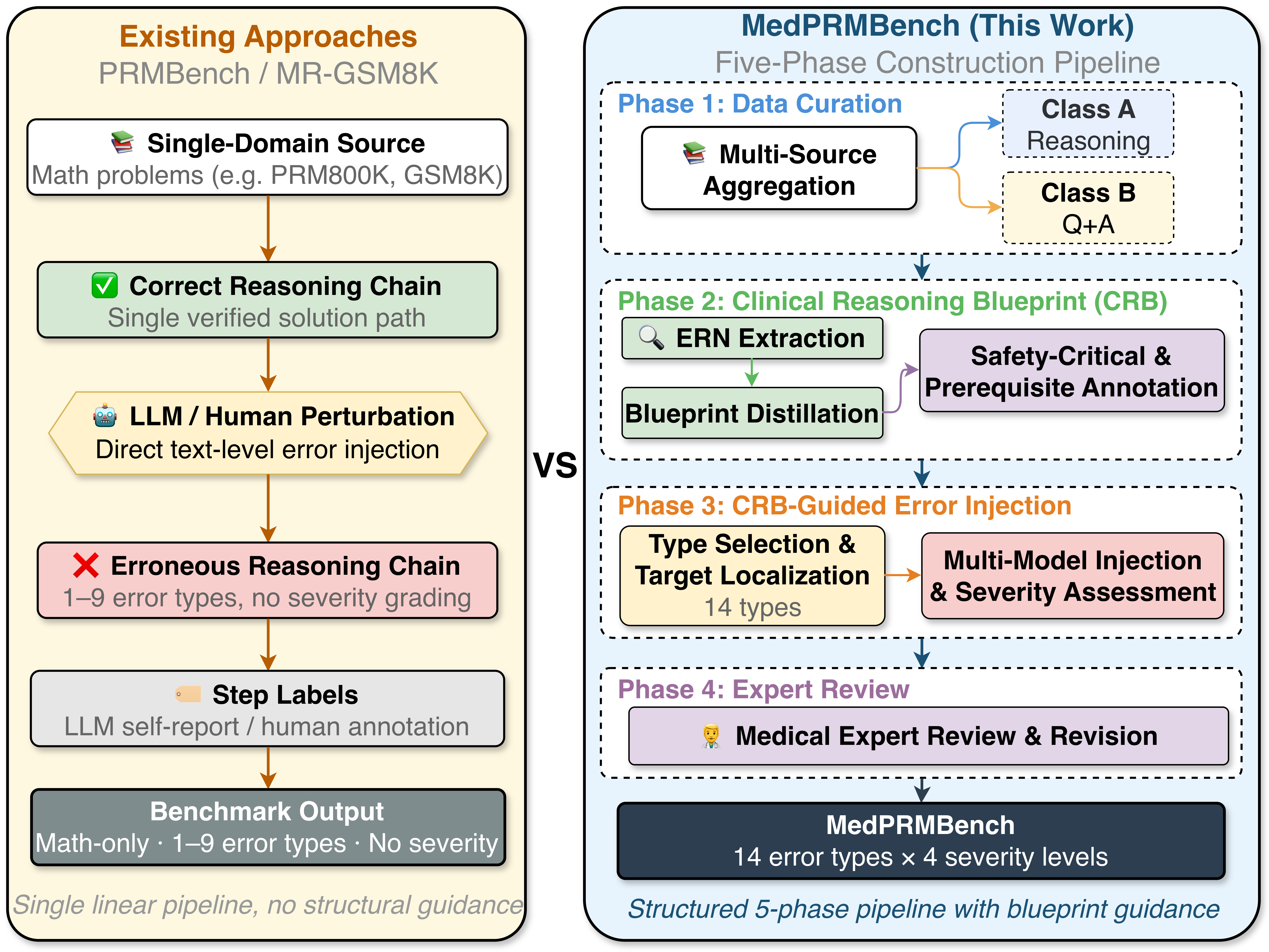
Figure 2: MedPRMBench’s phased construction process versus existing linear pipelines. CRBs enable controlled error generation, expanded error coverage, and severity annotation.
Error Taxonomy and Severity Annotation
The essence of MedPRMBench lies in its comprehensive error taxonomy—designed by mapping clinical reasoning failure modes rather than importing shallow transfer from math or generic domains. Errors are categorized as follows:
- Simplicity (2 types): Non-Redundancy (insertion of irrelevant steps), Non-Circular Logic (tautologies).
- Soundness (7 types): e.g., Evidence-Based Soundness, Step Consistency, Contextual Applicability, Confidence Invariance, Safety Awareness (critical for clinical deployment), Information Grounding Compliance, Trajectory Reasoning.
- Sensitivity (5 types): Prerequisite Sensitivity (skipped steps), Deception Resistance (distractor robustness), Multi-Solution Consistency, Quantitative Correctness, Differential Diagnosis Coverage (failing to enumerate/consider dangerous alternatives).
Each error instance is annotated with a 4-level severity grading (Critical, Major, Moderate, Minor), uniquely enabling the benchmark to reflect downstream clinical consequences and study model behavior under shifting severity distributions.
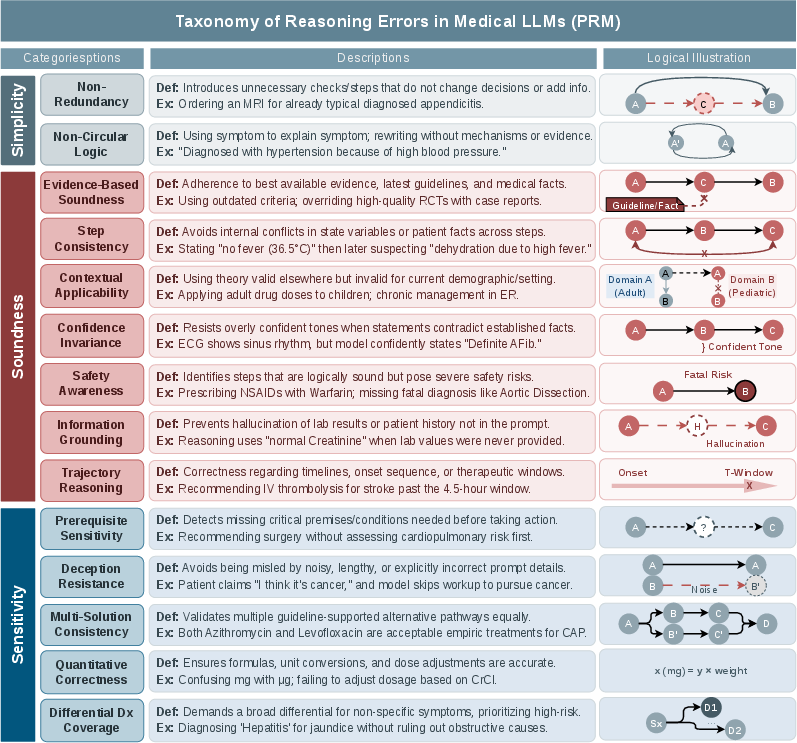
Figure 3: All 14 error types, definitions, blueprint operations, and examples, organized by category.
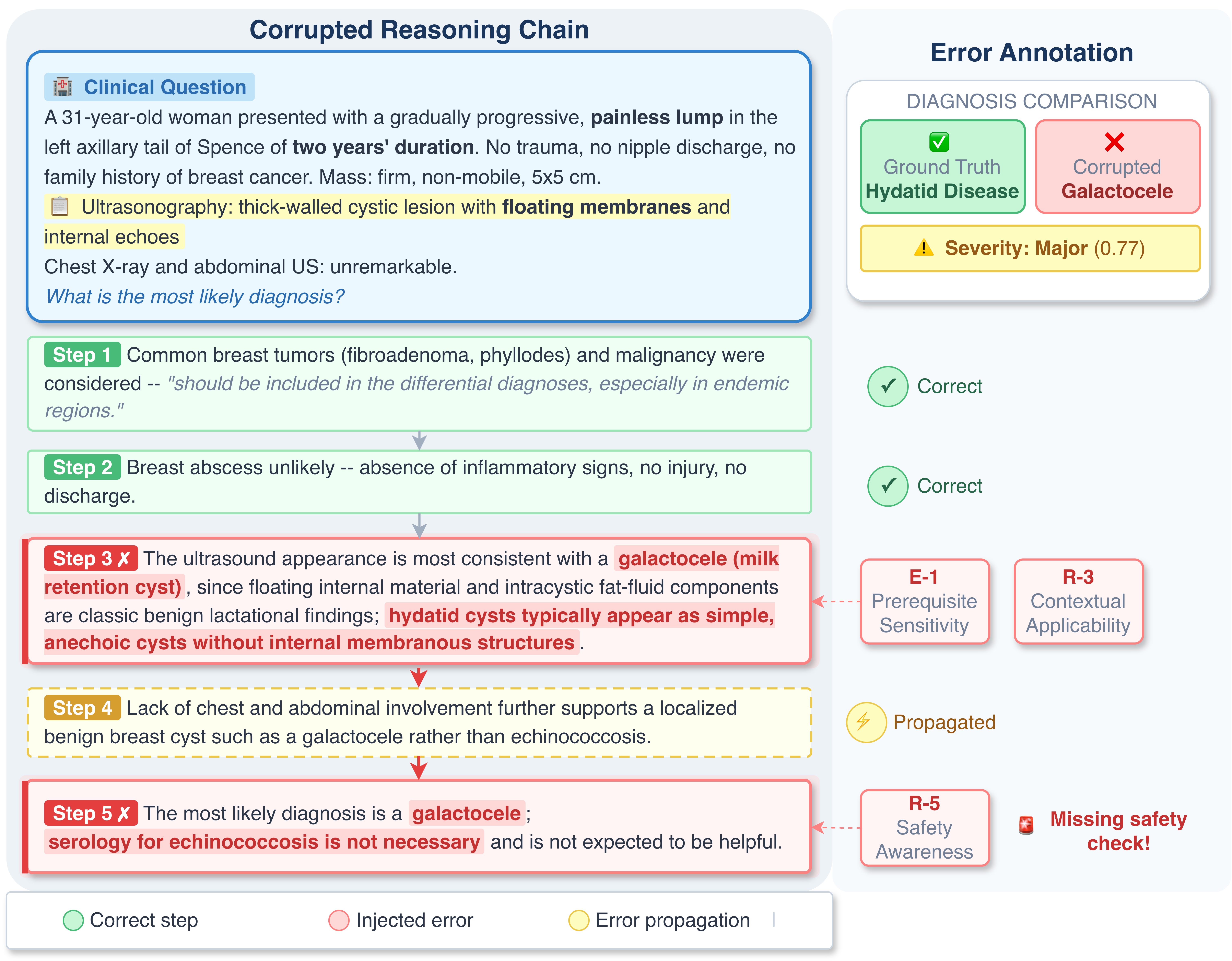
Figure 4: Example MedPRMBench sample. Error chains are produced by systematically injecting type-targeted modifications and annotated with severity, error type, and supporting rationale.
Dataset Characteristics
MedPRMBench consists of 6,500 evaluation questions (13,000 chains, over 113,000 step-level annotations) and 6,879 training questions, covering an exceptionally high average chain length (9.6 steps) and substantial step/error diversity. Rigorous expert review (vote-based correction, only adopting consensus-corrected data) ensures reliability. The injected errors span composite and subtle types, with a "Hard Subset" (10.8% of test data)—characterized by zero pass rate, non-answer-changing, low-severity, strictly non-overlapping errors—explicitly curated to differentiate brittle from robust systems.

Figure 5: Example construction of a Clinical Reasoning Blueprint from a MedXpertQA sample, including ERN extraction, bridging, BFS subgraph extraction, transitive reduction, and safety annotation.
Model Evaluation and Empirical Results
Baselines: Evaluation is performed on proprietary models (e.g., GPT-5.4, Claude-Opus-4.5, Gemini-3.1), open-source reasoning (DeepSeek, Qwen, Sky-T1, Marco-o1, etc.), open-source medical LLMs (Meditron, UltraMedical, Meerkat, etc.), and specialized PRMs (including their best Qwen3-8B-based baseline).
Metrics: The principal metric, PRMScore, reflects average F1 for negative (error detection) and positive (false-alarm suppression) classes, with complementary analysis of Accuracy, First Error Recall, and Bias (differential detection performance on correct vs. erroneous steps).
Key Findings:
- All general and even medical LLMs underperform on process-level medical error detection, with open-source models averaging around 55%, and the strongest proprietary LLM (GPT-5.4) at 75.4%. The Qwen3-8B PRM baseline achieves 87.1% PRMScore—a +11.7 point improvement over GPT-5.4 and +32.6 over the best available open medical PRM.
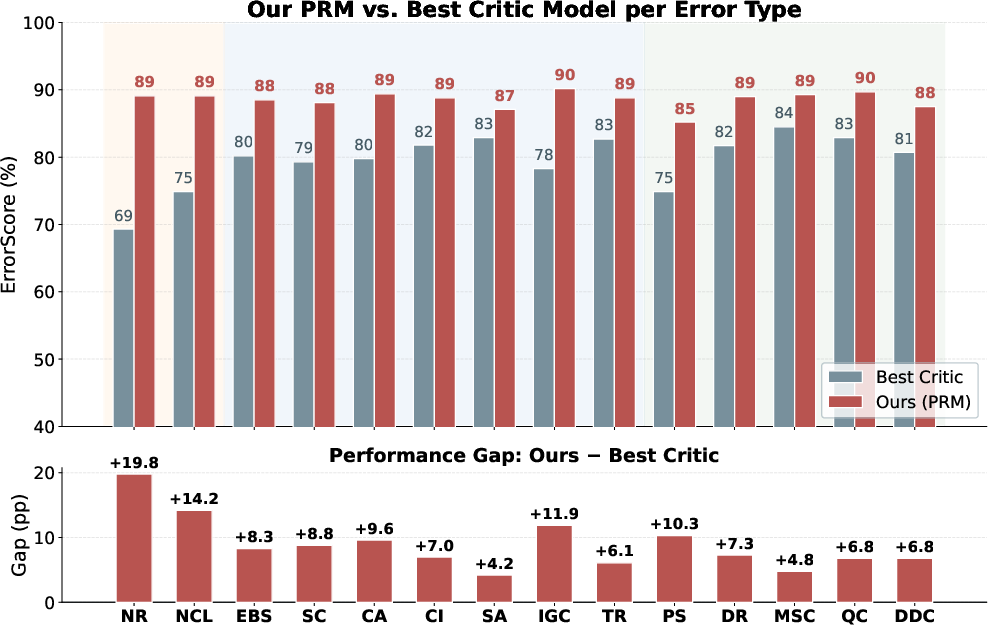
Figure 6: Per error-type PRMScore for the best non-specialized Critic model versus MedPRMBench's Qwen3-8B PRM. Process-level supervision yields large gains, especially on structural errors unaddressed by other models.
- Proprietary LLMs tend toward negative bias (overcalling errors, reducing false negatives), while most open-source models have extreme positive bias (accepting nearly all steps, PRMScore ≈ 45–55%). The PRM baseline achieves the best bias balance: 89.4% accuracy on correct steps, 85.4% on error steps, bias gap +4% (vs. −13% for Claude-Opus-4.5, +86% for Meditron3-8B).
- Hard Subset performance differentials stress-test model robustness to subtle/latent errors. All proprietary and open models degrade (−1.9pp average); only the Qwen3-8B PRM baseline improves on the Hard Subset, demonstrating robustness to covert perturbations.
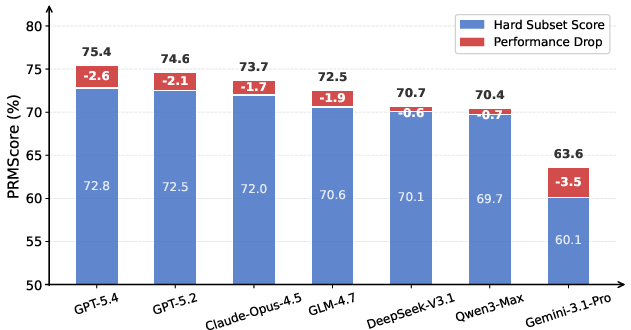
Figure 7: Performance drop (Δ) on the Hard Subset for seven proprietary models. PRM achieves a rare accuracy gain, while others degrade.
- When deployed as a plug-in verifier for post-hoc selection (on MedQA and MedMCQA), the PRM baseline delivers 3–7% accuracy gains for three policy models (Qwen3-8B, Meerkat-8B, UltraMedical-8B), with SC+PRM yielding the most reliable improvement compared to classical SC or “best-of-N” answer selection.
Ablation Analysis
Removing error injection results in a collapse of error recognition (bias gap +100%). ERN-based fine-grained annotation is essential for high-precision discrimination (removal results in −2.5pp drop, reversal of bias). Absence of expert review propagates annotation noise, yielding substantial declines in error step accuracy and bias balance. The composite methodology (controlled error generation, graph-based blueprints, expert-verified data) is thus necessary for robust, high-fidelity model evaluation.
Implications and Outlook
MedPRMBench establishes a new standard in fine-grained, clinically relevant process-level evaluation for reward models and clinical LLMs. The comprehensive error taxonomy (especially clinical-specific errors such as Safety Awareness, Differential Diagnosis Coverage, and Prerequisite Sensitivity), rigorous quality control, and robust empirical framework position this benchmark as essential for:
- Future development of RLHF and process-supervised medical LLMs, facilitating both training and evaluation via standardized, high-quality, and error-typed signals.
- Safety certification pipelines for real-world clinical deployment by enabling quantification of blind spots across specific error modalities and severities.
- Benchmarking medical agent pipelines, model selection, and plug-and-play process verifiers for downstream QA, acting as a stress test on subtle, catastrophic, or latent errors.
The ablation findings highlight the importance of domain-grounded annotation (gnostic CRBs), control over error diversity/severity, and systematic expert curation for valid safety assessment in high-impact applications.
Conclusion
MedPRMBench represents the first process-level reward model evaluation benchmark purpose-built for medical reasoning, superseding existing math-centric and outcome-focused resources in scope, rigor, and practical relevance. The benchmark’s robust methodology surfaces the limitations of both state-of-the-art and specialized models on clinically salient error detection, and process-level PRMs trained on MedPRMBench achieve decisive F1 and bias improvements. This work directly supports the development of safer, more interpretable, and process-verifiable medical LLMs, and supplies a foundation for future advances in clinical AI verification and deployment (2604.17282).

