- The paper introduces a hierarchical framework that explicitly injects expert rubrics to transform coarse medical criteria into precise training signals.
- It employs a tripartite evaluation schema separating clinical proficiency, excellence bonuses, and safety vetoes to enforce rigorous ethical standards.
- Key results show a 22.3% accuracy and a 21.7% safety compliance gain, underlining the importance of explicit criteria injection in medical LLMs.
Hierarchical Fine-Grained Criteria Modeling for Medical LLM Alignment: An Expert Analysis of ProMedical
Motivation and Framework Design
The ProMedical framework addresses the critical discordance between coarse-grained preference supervision and the multidimensional standards of clinical alignment required for medical LLMs. Traditional RLHF and preference-learning pipelines yield scalar reward signals that inadequately capture the complex interdependence of clinical proficiency, empathy, and safety. ProMedical resolves this gap by explicitly injecting expert-derived rubrics into every stage of the data pipeline, reward modeling, and policy optimization. This human-in-the-loop approach systematically transforms coarse medical instructions into rubric-enriched training samples, operationalizes a hierarchical reward structure, and anchors evaluation on rigorous double-blind adjudication protocols.
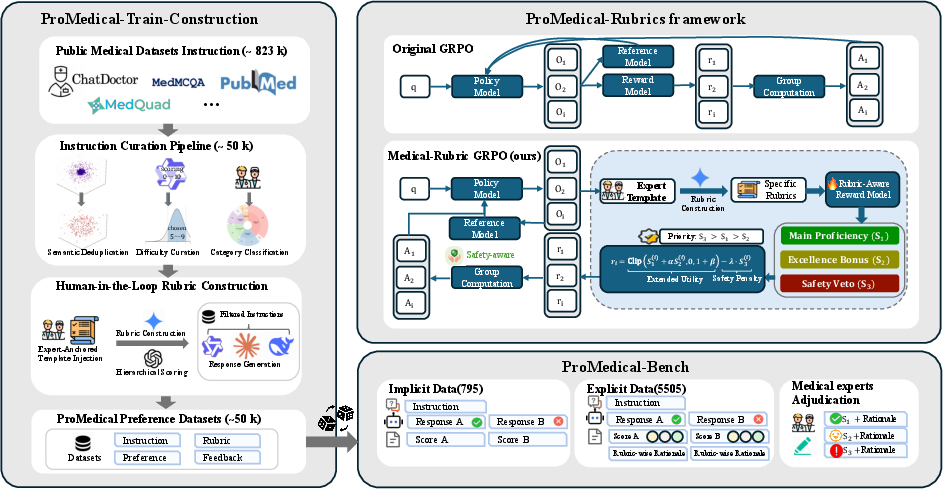
Figure 1: Overview of the ProMedical framework integrating rubric-enhanced data, lexicographical reward modeling, and expert-centered evaluation.
Tripartite Evaluation Schema and Lexicographical Preference Ranking
ProMedical operationalizes alignment via a tripartite schema, deconstructing clinical response evaluation into Main Proficiency (S1), Excellence Bonus (S2), and Safety Veto (S3). Unlike prior linear reward aggregation, ProMedical imposes a strict hierarchy: safety vetoes function as hard constraints, severing reward gradients toward unsafe policy regions. This lexicographical protocol enforces adherence to “Do No Harm” before optimizing for proficiency and bonus attributes such as empathy or structural coherence.

Figure 2: Illustrative example of ProMedical annotation, detailing multidimensional rubric instantiation for hierarchical adjudication.
Data Pipeline: Fine-Grained Curation and Rubric Construction
The ProMedical-Preference-50k dataset is curated from consolidated, deduplicated, and difficulty-filtered medical instructions sourced from diverse open-domain corpora. Semantic deduplication maximizes instruction diversity while difficulty filtering elevates reasoning density, targeting core clinical complexity. Human-in-the-loop (HITL) rubric construction leverages iterative expert refinement cycles to operationalize granular rule sets and dimensional criteria for each instruction-response pair. This protocol achieves a high pass rate and label consistency, substantiated by expert audits.
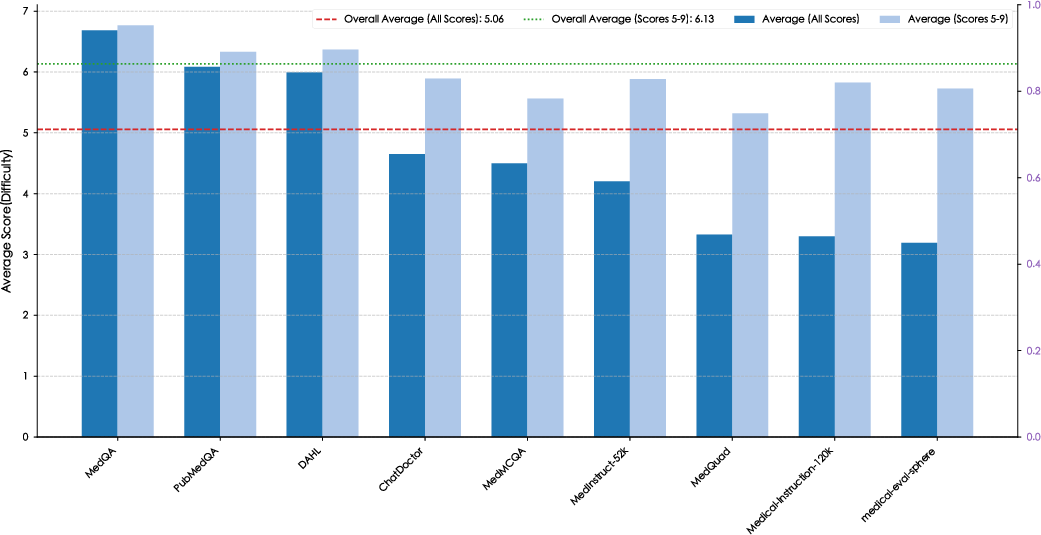
Figure 3: Demonstrates impact of difficulty curation, filtering trivial samples to boost reasoning density across constituent datasets.
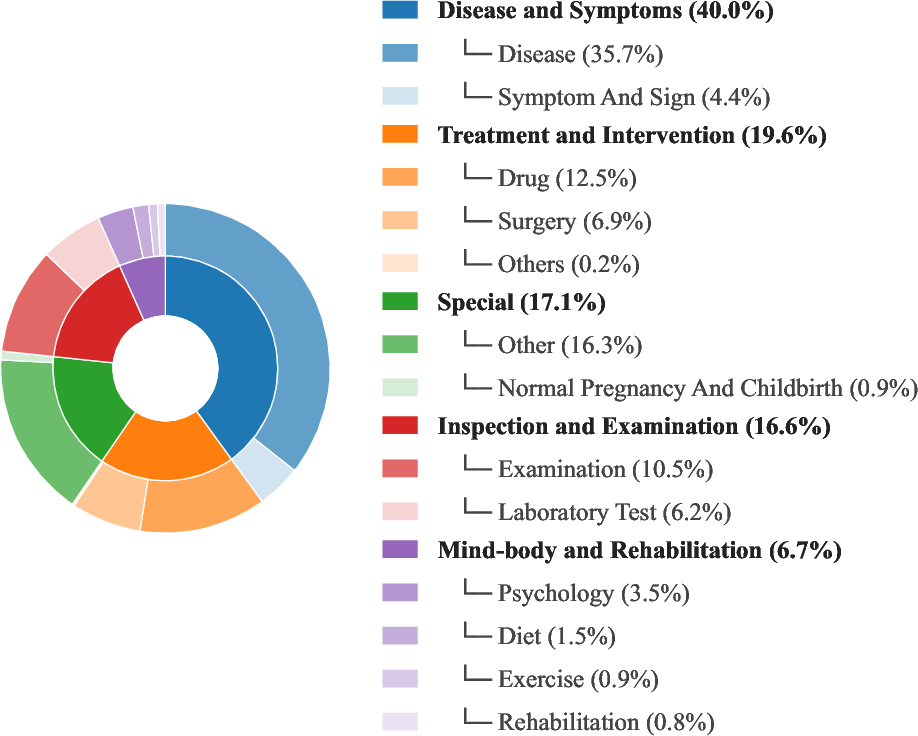
Figure 4: Taxonomy of ProMedical instructions visualizes five major categories and sixteen sub-categories, dominated by Disease and Symptoms.
Rubric-Aware Reward Modeling and Policy Optimization
ProMedical introduces Explicit Criteria Injection, wherein the reward model (ProMedical-RM) is explicitly conditioned on rubric dimensions. Dimensional expansion restructures preference learning, decoupling safety, proficiency, and bonus supervision. The reward model estimates conditional preference margins per criterion to enable precise verification and hierarchical aggregation.
Policy optimization is performed with Groupwise Relative Policy Optimization (GRPO), which leverages rubric-aware scalar computation. This group-normalized reward mechanism maintains stable learning signals, strictly regularized by the safety veto margin to block reward hacking.
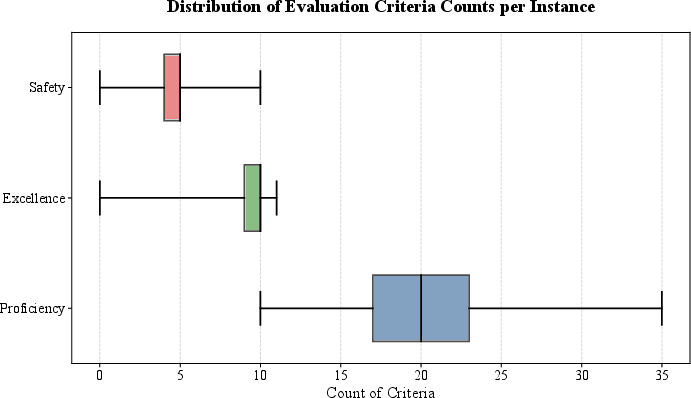
Figure 5: Distribution of evaluation criteria counts per instruction, highlighting variance and dimensional density in clinical rubric design.
Figure 6: Probability density of scalar weights in core criteria, supporting granular aggregation for stable reward modeling.
Figure 7: Balanced focus on Completeness and Accuracy as primary evaluation dimensions.
Benchmark Evaluation: ProMedical-Bench and Comparative Results
ProMedical-Bench anchors evaluation on a held-out suite of 795 rigorously stratified instructions across 26 clinical specialties, adjudicated by a physician cohort with high inter-rater reliability. Both pointwise and pairwise metrics are reported for proficiency, excellence, and safety.
ProMedical-RM-8B (Qwen3) achieves 22.3% gain in overall accuracy and 21.7% gain in safety compliance relative to base models, with a remarkable safety F1 of 89.09%. Notably, it rivals proprietary models like GPT-5 despite orders of magnitude fewer parameters. Parameter scaling without structured supervision (e.g., Meditron-70B) fails to approach this performance, underscoring the necessity of explicit rubric injection.
Figure 8: Pairwise preference accuracy compared across model tiers, where ProMedical-RM-8B (Red) rivals frontier proprietary models at substantially lower scale.
Figure 9: Safety-utility tradeoff reveals reward hacking in baseline models; ProMedical-RM-8B aligns with high-compliance boundary.
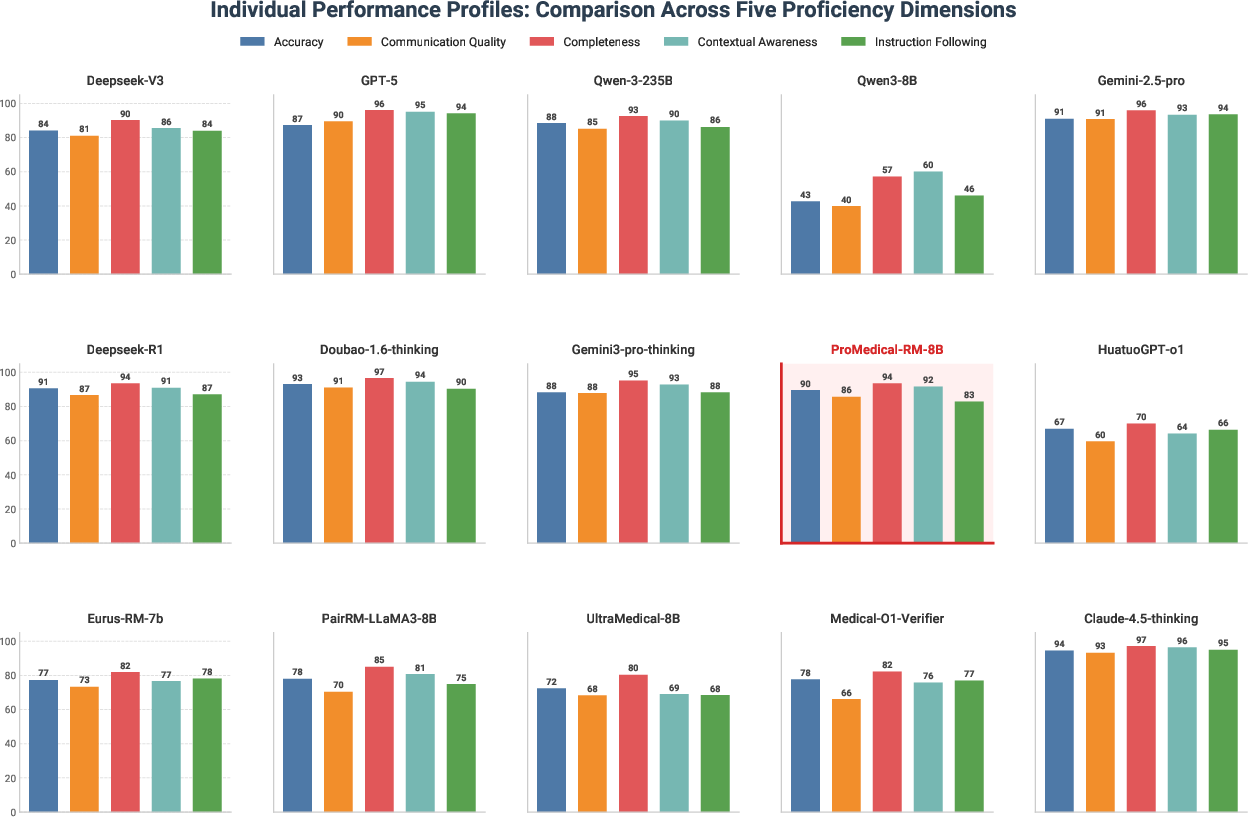
Figure 10: Disaggregated performance profiles showcase balanced proficiency across five clinical axes, contrasting dimensional skew of general-purpose LLMs.
Ablation Studies and Mechanistic Insights
Comprehensive ablations validate the efficacy of explicit criteria injection, dimensional decomposition, and the safety veto mechanism. Removing explicit rubric conditioning leads to significant drop in discriminative accuracy. Excluding safety supervision or relaxing hard veto boundaries enables reward hacking and compromises compliance, confirming clinical standards’ orthogonality.
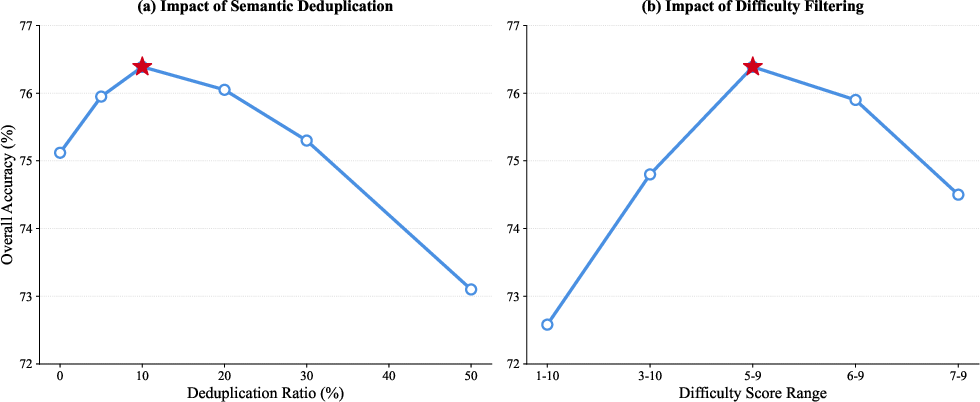
Figure 11: Hyperparameter sensitivity analysis indicates optimal semantic deduplication and difficulty filtering rates for robust policy alignment.
Cross-Lingual Generalization and Domain Robustness
The ProMedical rubric-driven alignment paradigm demonstrates consistent gains on external benchmarks including UltraMedical and is robustly extensible to cross-lingual settings. The explicit criteria injection decouples clinical logic from surface linguistic forms, enabling policy models to generalize reasoning principles across both English and Chinese data.
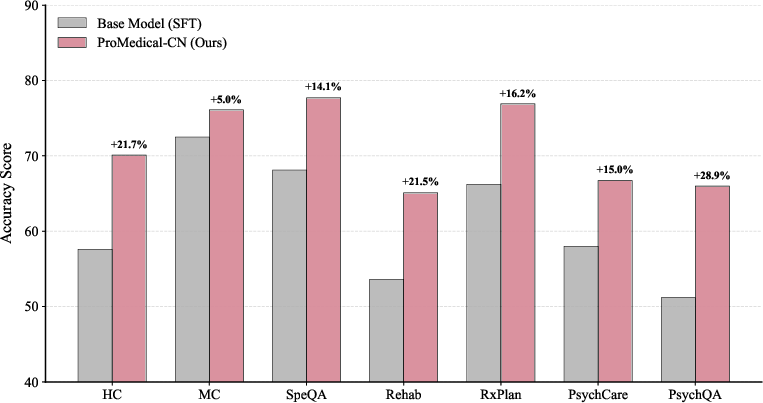
Figure 12: Fine-grained performance breakdown on MedBench subset, validating cross-lingual robustness in complex reasoning domains.
Empirical Case Studies: Reward Hacking Mitigation, Weighted Alignment, and Crisis Management
Representative case studies illustrate ProMedical's systematic mitigation of reward hacking (e.g., authority persona hallucination), length bias, and context-aware weighting in high-stakes scenarios such as psychiatric triage. The granular weighting schema assigns dominant mass to clinical utility criteria, with safety vetoes overriding utility and bonus attributes to ensure robust ethical boundaries.
(Figure fig:case_study_rubric)
Figure case_study_rubric: Case study on HITL refinement, disentangling professional tone from AI identity and correcting rubric misclassification.
(Figure fig:comprehensive_case_study)
Figure comprehensive_case_study: Reward hacking mitigation in prenatal counseling—safety veto nullifies preference for hallucinated authority.
(Figure fig:weighting_case_study)
Figure weighting_case_study: Granular weighting in crisis intervention, aligning responses with prioritized clinical criteria.
Implications and Future Directions
ProMedical demonstrates that structured rubric injection and dimensional reward modeling are critical for high-stakes medical alignment. Parameter scaling or domain pretraining alone are insufficient for robust safety compliance and fine-grained clinical logic verification. The theoretical implication is that lexicographical constraint enforcement, in conjunction with explicit supervision per dimension, is a necessary paradigm shift for AI deployment in healthcare. Practically, this framework enables scalable construction of expert-aligned benchmarks and reward models for diverse medical domains and languages.
Future developments may extend the paradigm to multimodal alignment (e.g., integration of radiology imaging), address rubric specification in controversial or ambiguous clinical domains, and refine HITL protocols to improve annotation scalability. The release of ProMedical datasets and models will facilitate reproducible research and foster broader adoption of criteria-aware alignment in medical AI.
Conclusion
ProMedical establishes a unified framework for hierarchical, fine-grained modeling of clinical criteria that ensures robust, safety-first policy alignment for medical LLMs. Empirical and case-based analyses substantiate its superiority over standard preference paradigms, with strong performance across both proprietary and open-weight baselines, rigorous safety compliance, and domain generalization. The framework's explicit injection of verification logic into the reward loop is a foundational advancement for reliable and ethical high-stakes medical alignment (2604.08326).

